Sri Lankan cassava mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000858725.1 |
| Isolate | Sri Lanka:Columbo |
| Release date | 2015/2/13 |
| Submitter | Saunders,K., Salim,N., Mali,V.R., Malathi,V.G., Briddon,R., Markham,P.G., Stanley,J. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
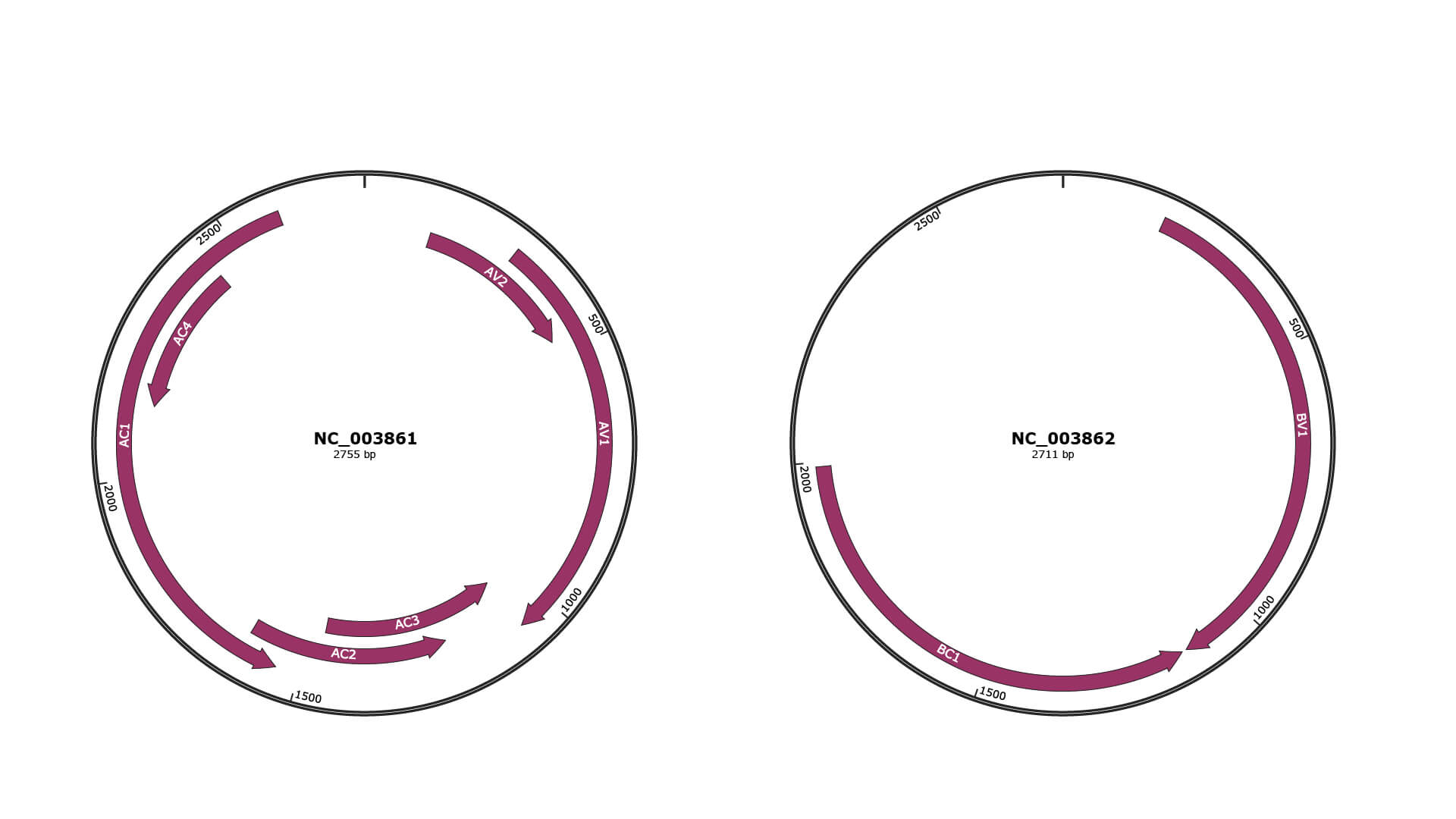
JBrowse
Genome
NC_003861
NC_003862
Gene Information
| NCBI Accession | NP_620863.1 |
|---|---|
| Location | 135-473 |
| Gene Name | AV2 |
| Protein Name | AV2 protein |
| Coding Region | ATGTGGGACCCTCTATTGAACGAGTTCCCAGAATCCGTCCACGGTTTCCGGTGTATGCTCGCCGTCAAATACCTTCAGCTGGTAGAAGGTACATATTCACCAGACACTCTGGGACACGAGTTAATCAGGGATCTCATATCCGTCATCAGGGCGAAGAATTATGTCGAAGCGACCAGCAGATATAATTATTTCTACTCCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGCCCCCACTGTCCGCGTCACAAAAAGACAGCTATGGGCAAACAGGCCCATGAATCGGAAGCCCAGGTGGTATCGGATGTATAG |
| Protein Sequence | MWDPLLNEFPESVHGFRCMLAVKYLQLVEGTYSPDTLGHELIRDLISVIRAKNYVEATSRYNYFYSRLEGSSPSELRQPIQQPCCCPHCPRHKKTAMGKQAHESEAQVVSDV |
| NCBI Accession | NP_620864.1 |
|---|---|
| Location | 295-1065 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCAGCAGATATAATTATTTCTACTCCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGCCCCCACTGTCCGCGTCACAAAAAGACAGCTATGGGCAAACAGGCCCATGAATCGGAAGCCCAGGTGGTATCGGATGTATAGGAGCCCAGATGTTCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCATTCGAGTCGAGACACGATGTGGTCCATATAGGTAAGGTCATGTGCATCTCTGATGTCACTCGTGGAATTGGGCTTACTCATCGGGTGGGTAAGAGATTTTGTGTTAAGTCCGTTTACATCCTGGGCAAGATATGGATGGATGAAAACATTAAGACCAAAAATCACACGAATAGCGTAATGTTCTTCCTTGTAAGGGATCGTAGGCCCGTTGATAAGCCTCAGGATTTTGGTGAAGTATTTAATATGTTTGATAATGAGCCCAGTACAGCTACTGTGAAGAACATGCATCGTGATCGCTATCAAGTTCTCAGGAAGTGGAGTGCCACTGTCACTGGTGGTCAGTATGCGAGCAAGGAGCAGGCTTTAGTCAGGCGTTTTTTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGGAAATATGAGAACCATACTGAGAATGCATTAATGTTGTACATGGCGTGTACTCATGCCTCTAATCCTGTATACGCTACGTTGAAGATTAGAATCTACTTCTATGATTCAGTGAGCAATTAA |
| Protein Sequence | MSKRPADIIISTPGSKVRRRLNFDSPYSSRAAAPTVRVTKRQLWANRPMNRKPRWYRMYRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGIGLTHRVGKRFCVKSVYILGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWSATVTGGQYASKEQALVRRFFRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
| NCBI Accession | NP_620865.1 |
|---|---|
| Location | 1062-1466 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATCCAGCACGACAGCCGGCCGTTCAGCATGCCGTGGGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGGGACTACACCAATGCTGGATGGATTTCAAGGTCTGGACGACCTTACAGCCTCAGACCTGGCGTTTCTTGAGGGTATTTAAGACCCAAGTATTGAAATACTTAGATCGCTTAGGAGTTATAAGTATTAATACTGTTGTAAACGCCGTAGAGCATGTATTGTACAATGTAATCCATGGGACTGACCGTGTTGAGCAGTCTAATTTAATAAAATTAAATATTTATTAA |
| Protein Sequence | MDSRTGELITAAQAMNGVYIWEVPNPLYFKIIQHDSRPFSMPWDIITVQIRFNHNLRRALGLHQCWMDFKVWTTLQPQTWRFLRVFKTQVLKYLDRLGVISINTVVNAVEHVLYNVIHGTDRVEQSNLIKLNIY |
| NCBI Accession | NP_620866.1 |
|---|---|
| Location | 1207-1614 |
| Gene Name | AC2 |
| Protein Name | transcriptional transactivator protein |
| Coding Region | ATGCGACCTTCATCTCCCTCAGCGAGCCGCTCTACTCAGGTTCCAATCAAGGTCCAACACAGAGCAGCTAAGCGTAAGGCCATCCGGCGACGGAGGGTAGACCTCAACTGCGGGTGCTCGTACTACGTGCACATAAACTGCCACAACCATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATCCAGCACGACAGCCGGCCGTTCAGCATGCCGTGGGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGGGACTACACCAATGCTGGATGGATTTCAAGGTCTGGACGACCTTACAGCCTCAGACCTGGCGTTTCTTGAGGGTATTTAA |
| Protein Sequence | MRPSSPSASRSTQVPIKVQHRAAKRKAIRRRRVDLNCGCSYYVHINCHNHGFTHRGTHHCSSGDEWRLYLGGSKSPLFQDHPARQPAVQHAVGHNNRPDTVQPQPEESVGTTPMLDGFQGLDDLTASDLAFLEGI |
| NCBI Accession | NP_620867.1 |
|---|---|
| Location | 1544-2599 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGAGAAACCCACGATTCCGAATTCAGTCCAAAAATATATTCCTCACATACCCTAAGTGTTCTCTCACCAAAGAACACTTACTCGACTTCTTCCGAAGCTTGAGTCTTCCGACAAACATCAAATTTATTAAAATTTGCAGAGAACTCCATCATAATGGGGAACCTCACCTCCATGCTCTGCTTCAGTTCGAAGGGAAGCTCACGATCACAAACAATCGGCAATTCGATTGTGTACACCCAAGCAGTAGCACCAGTTTCCACCCCAACATACAGAGCGCTAAGTCCAGCTCAGACGTCAAGTCCTACATCGACAAGGATGGAGACACCATCGACTGGGGTGAGTTTCAGATCGATGGAAGATCTGCAAGAGGGGGACAGCAGACAGCCAACGACGCTTACGCCGCAGCACTTAACACAGGCAGTAAGCCAGAGGCTCTTAGAGTCATTAAGGAGTTAGCACCCAAGGATTATGTTTTACAATTTCATAATCTAAATGCTAATTTAGATAGGATTTTTACACCTCCTCCCGAGGTGTATGTGTCTCCCTTCTCAGCCTCTTCATTTGACCAAGTTCCAGATGAACTTGAGGAGTGGGTGTCAGAGAATGTCATGGGTGCCTCTGCGAGGCCTTTGAGACCTAATAGTATAGTCATCGAGGGCGATAGTCGTACAGGCAAAACGATGTGGGCTAGGTCATTGGGTCCACACAACTATCTGTGTGGACATCTGGACTTGAGTCCTAGGGTTTACAGCAATGATGCATGGTACAACGTAATTGATGACGTAGATCCGCATTATCTAAAGCACTTTAAGGAATTCATGGGGGCCCAAAGGGACTGGCAGTCAAACACCAAGTACGGGAAACCAGTTCAAATTAAAGGGGGAATCCCCACTATCTTCCTGTGCAATCCTGGGCCCAATTCCAGCTATAAAGAATTCCTTGACGAGGCGAAGAATATCGCATTGAAGGCTTGGGCTCTGAAGAATGCGACCTTCATCTCCCTCAGCGAGCCGCTCTACTCAGGTTCCAATCAAGGTCCAACACAGAGCAGCTAA |
| Protein Sequence | MRNPRFRIQSKNIFLTYPKCSLTKEHLLDFFRSLSLPTNIKFIKICRELHHNGEPHLHALLQFEGKLTITNNRQFDCVHPSSSTSFHPNIQSAKSSSDVKSYIDKDGDTIDWGEFQIDGRSARGGQQTANDAYAAALNTGSKPEALRVIKELAPKDYVLQFHNLNANLDRIFTPPPEVYVSPFSASSFDQVPDELEEWVSENVMGASARPLRPNSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPRVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEAKNIALKAWALKNATFISLSEPLYSGSNQGPTQSS |
| NCBI Accession | NP_620868.1 |
|---|---|
| Location | 2143-2445 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGGAACCTCACCTCCATGCTCTGCTTCAGTTCGAAGGGAAGCTCACGATCACAAACAATCGGCAATTCGATTGTGTACACCCAAGCAGTAGCACCAGTTTCCACCCCAACATACAGAGCGCTAAGTCCAGCTCAGACGTCAAGTCCTACATCGACAAGGATGGAGACACCATCGACTGGGGTGAGTTTCAGATCGATGGAAGATCTGCAAGAGGGGGACAGCAGACAGCCAACGACGCTTACGCCGCAGCACTTAACACAGGCAGTAAGCCAGAGGCTCTTAGAGTCATTAAGGAGTTAG |
| Protein Sequence | MGNLTSMLCFSSKGSSRSQTIGNSIVYTQAVAPVSTPTYRALSPAQTSSPTSTRMETPSTGVSFRSMEDLQEGDSRQPTTLTPQHLTQAVSQRLLESLRS |
| NCBI Accession | NP_620869.1 |
|---|---|
| Location | 185-1123 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGAGTGAGGGCCCTATGTGTGGATATCTAACCGCATATTGTGCGAATGGATTAAACGTGGCAAGATCATGCCGTTTATTGGGAACTATATTATTATGCTGTGGTCTATATATATGGGTATGTCGTGTATTGAGATCTGCACATGGTTGTTTCAGGATGAGAAGAGGTGCTTATACCCCCCGTTCTACGCCATTCCCTCGTGACCGGAGATCGTATAATGCCGGTAAGGGTAGATCCTTTCGTTCGTACCGTCGTCGTGGACCTGTTCGTCCATTAGCTCGTCGGAACCTGTTTGGTGATGACCATGCACGTGCATTCACGTATAAGACCTTATCGGAGGATCAATTTGGACCGGACTTTACCATACATAATAATAATTATAAGTCATCTTATATATCTATGCCTGCCAAAACACGTGCCCTTAGCGATAACAGGGTAGGTGATTATATCAAACTTGTAAATATATCATTTACAGGTACAGTGTGTATAAAAAACAGCCAGATGGAGTCTGACGGAAGCCCAATGTTGGGCCTGCATGGGCTGTTTACTTGTGTATTGGTCCGGGATAAGACCCCTCGTATATATTCTGCCACTGAGCCTTTGATACCTTTCCCACAGTTGTTTGGGTCCATAAACGCGAGCTATGCGGATTTGTCTATACAAGACCCATATAAGGATCGATTCACAGTTATCCGTCAGGTGTCTTACCCAGTTAATACGGAGAAGGGTGATCATATGTGTCGTTTCAAAGGCACTCGTCGTTTTGTTGGTAGATACCCTATCTGGACTAGTTTTAAAGATGATGGTGGCAGTGGAGATTCATCGGGATTATATAGTAATACGTATAAAAATGCCATACTTGTATATTATGTATGGCTCAGCGACGTATCGTCACAATTGGAAATGTATTGTAAATATGTAACTCGATATATTGGTTAA |
| Protein Sequence | MSEGPMCGYLTAYCANGLNVARSCRLLGTILLCCGLYIWVCRVLRSAHGCFRMRRGAYTPRSTPFPRDRRSYNAGKGRSFRSYRRRGPVRPLARRNLFGDDHARAFTYKTLSEDQFGPDFTIHNNNYKSSYISMPAKTRALSDNRVGDYIKLVNISFTGTVCIKNSQMESDGSPMLGLHGLFTCVLVRDKTPRIYSATEPLIPFPQLFGSINASYADLSIQDPYKDRFTVIRQVSYPVNTEKGDHMCRFKGTRRFVGRYPIWTSFKDDGGSGDSSGLYSNTYKNAILVYYVWLSDVSSQLEMYCKYVTRYIG |
| NCBI Accession | NP_620870.1 |
|---|---|
| Location | 1132-1992 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGAGAATAATAGTAGCAATGCAGCGTATCTTCGTTCCGAAAGAGTTGAATATGAGTTAACCAATGACTCAACAGACGTCAAGTTAAGCTTTCCATCTCTTCTGGATACCAAAATATCGCTCCTCAAGGGTCACTGCTGCAAAATAGACCACATCGTCCTAGAGTATAGAAACCAGGTACCCATTAACGCCACAGGGCATGTCATCATTGAAATTCACGACCAAAGACTGCATGACGGAGACTCAAAACAGGCTGAATTTACTATTCCCGTCCAATGCAATTGCAACCTTCACTACTATTCTTCATCGTTCTTCTCCATGAAGGACATAAACCCATGGAGGGTTATGTACAGAGTCGTAGACACAAACGTCATCAACGGGGTCCACTTCTGCCGTATACAGGGCAAACTCAAGCTGTCAACTGCAAAGCAGTCTAATGACATACAGTTCAGATCTCCCAAAATCGAGATACTGAGCAAGGCCTTCACTGAGAGGGACATTGATTTCTGGTCAGTGGGTCCAAAAGCCCAGCAGAGGAAACTGGTCCAAGGCCCAAGTCTAATAGGATCCCGCTCCAAGAGATATGCTCCATGTTCCATAGGCCCAAATGAATCATGGGCCGTTAGAAGCGAGATTGGGCTTAACGGGCCATGGGCCGTTACGAGCGAGGCTGGGCCATCATTTGAAAGGCCTTACAGCCAACTAAACCGGCTCAACCCAGACGCATTGGACCCAGGAAAGTCAGTATCACAAGTAGGATCGAACCACTTCACACGAGAGGACTTAAACGACATCATCAGCAAGACAGTAGATATGTGTTTAAATACGAGTATGCAAAGTCATGTATCCAAAAATGTATAA |
| Protein Sequence | MENNSSNAAYLRSERVEYELTNDSTDVKLSFPSLLDTKISLLKGHCCKIDHIVLEYRNQVPINATGHVIIEIHDQRLHDGDSKQAEFTIPVQCNCNLHYYSSSFFSMKDINPWRVMYRVVDTNVINGVHFCRIQGKLKLSTAKQSNDIQFRSPKIEILSKAFTERDIDFWSVGPKAQQRKLVQGPSLIGSRSKRYAPCSIGPNESWAVRSEIGLNGPWAVTSEAGPSFERPYSQLNRLNPDALDPGKSVSQVGSNHFTREDLNDIISKTVDMCLNTSMQSHVSKNV |
References More References in PubMed
| 1 |
Uke A, et al. J Virol Methods. 2022 Jan;299:114336. doi: 10.1016/j.jviromet.2021.114336. Epub 2021 Oct 14. PMID: 34656701 |
|---|---|
| 2 |
Chaowongdee S, et al. BMC Plant Biol. 2023 Apr 5;23(1):178. doi: 10.1186/s12870-023-04181-3. PMID: 37020181 |
| 3 |
Enhancing Plant Resistance to Sri Lankan Cassava Mosaic Virus Using Salicylic Acid. Pattanavongsawat C, et al. Metabolites. 2025 Apr 10;15(4):261. doi: 10.3390/metabo15040261. PMID: 40278390 |
| 4 |
Siriwan W, et al. BMC Plant Biol. 2022 Dec 10;22(1):573. doi: 10.1186/s12870-022-03967-1. PMID: 36494781 |
| 5 |
Minato N, et al. PLoS One. 2019 Feb 22;14(2):e0212780. doi: 10.1371/journal.pone.0212780. eCollection 2019. PMID: 30794679 |
| 6 |
Chi Y, et al. Virology. 2020 Jan 15;540:141-149. doi: 10.1016/j.virol.2019.11.013. Epub 2019 Nov 24. PMID: 31794888 |
| 7 |
Survey and molecular detection of Sri Lankan cassava mosaic virus in Thailand. Saokham K, et al. PLoS One. 2021 Oct 11;16(10):e0252846. doi: 10.1371/journal.pone.0252846. eCollection 2021. PMID: 34634034 |
| 8 |
Charoenvilaisiri S, et al. Virol J. 2021 May 18;18(1):100. doi: 10.1186/s12985-021-01572-6. PMID: 34006310 |
| 9 |
Asha S, et al. 3 Biotech. 2023 Mar;13(3):95. doi: 10.1007/s13205-023-03494-2. Epub 2023 Feb 23. PMID: 36845076 |
| 10 |
Saunders K, et al. Virology. 2002 Feb 1;293(1):63-74. doi: 10.1006/viro.2001.1251. PMID: 11853400 |