Squash mild leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000844565.1 |
| Isolate | USA: California |
| Release date | 2015/2/12 |
| Submitter | Brown,J.K., Idris,A.M., Alteri,C., Stenger,D.C. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
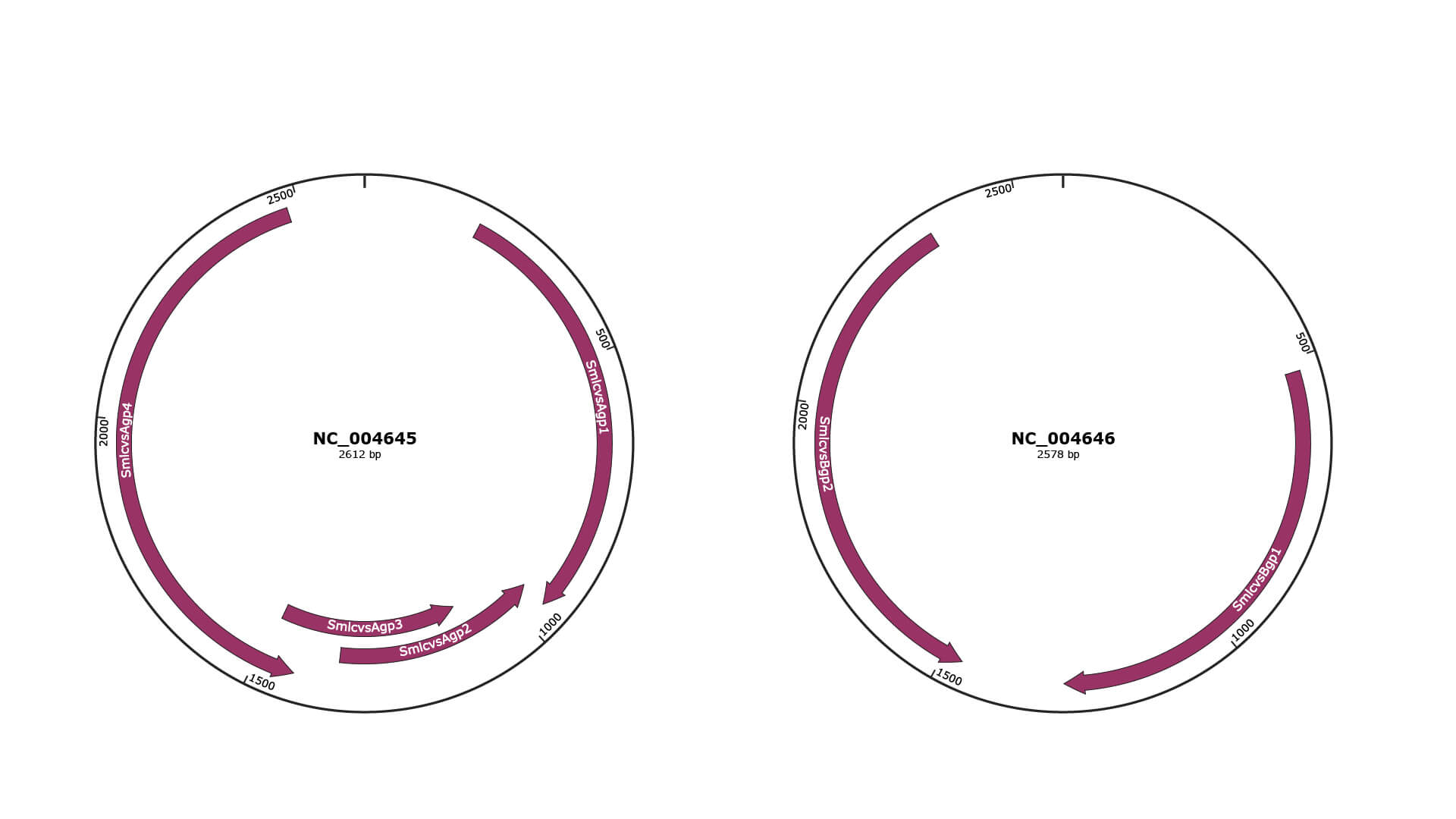
JBrowse
Genome
NC_004645
ACCGGATGGCCGCAAATTTTTTGGTGTCCTACTTTTCCAAGGCCCAAGCCCAACTCAACCACAACCTTTTACTTTAATTGGGACCACTACAAGTATTTCGACCAATCACATGTTTTCTGTGGTGACTAGTTATTATAGCTTGGTGCATAAGTGTGGTCCCTATAAATTAAAGCTGATACCGCCCATACGTCTTTAACTTAAAATGCCTAAGCGTGATGCCCCATCGCGTTTAATGGCGGGGACCTCGAAAGTCTCCCGCTCTGCTAACTATTCGCCTCGTGGAGGTATGGGCCCTAAATTCAATAAGGCCGCTGCGTGGGTGAACAGGCCCATGTATAGGAAGCCCAGGATCTATCGGACGTTCAGAAGTCCCGATGTTCCCAAGGGGTGTGAAGGACCTTGTAAGGTCCAGTCTTACGAGCAGCGGCATGATGTCTCTCATGTTGGCAAGGTAATGTGTATATCTGACGTGACCCGTGGTAACGGTATTACACACCGTGTCGGGAAACGTTTTTGTGTCAAGTCTGTATATATATTAGGGAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCACACTAACAGCGTTATGTTTTGGTTGGTACGAGACCGTAGACCGTATGGGACTCCTATGGAGTTCGGCCAAGTGTTCAACATGTTCGACAATGAGCCCAGTACGGCGACTGTTAAGAACGATCTCCGTGATCGTTTTCAAGTTATGCACAAGTTCTATGCTAAGGTCACTGGTGGTCAATATGCTAGCAACGAGCAAGCGTTGGTTAAAAGATTTTGGAAGGTCAACAACCATGTCGTCTATAACCACCAGGAAGCTGGGAAGTACGAGAATCATACAGAGAATGCTTTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCGACATTGAAAATACGGATCTATTTTTATGATTCAATAACAAATTAATAAAGATTAAATTTTATTTCATGCTTCTCGTGTACATAATATACATAAGAACGATCAGTTGCCCAGGAAACAGCTCTAACAACGTTATTGAGACCAATAACTCCTAACCTATCTAAGTACAATAGCACTAAATGTTTAAATCTATTTAAATAAGTCGTCCCAGAAGCTCGAATCGACTCCGTCCAGACTTGGTAGTTCAGGAACGCTTTGTGAAGATTTAGTGCTCTCCTCAGGTTGTGGTTGAACCGGATTTGGATATGATATATCCGCATGTGAGAGTGGACGGTATCCTCCACTTCTGTTATCTTGAAATACAGGGGATTTGGAACCTCCCAGATAAAAACGGAATTCTCTGCCTGATACACAGTGATGCTCTCCCCGGTGCGTAAATCCATGGTTCGTGCAGTTGATATGGAAAAATATGGAACAGCCGCAGTTTAGATCGATTCGTCGTCGACGTACAGCCCTTCTTTTAGCAATCTTGTGCTGTGCTTTGATAGAGGGGGCTCTCGAGGAAGATGAATTTAGCATTTTTTAATGTCCAGGCCTTTAGTGCGGTATTTTCCGCTTTGTCCAGGAAATCTTTATAGCTGGCCCCCTCGCCTGGATTGCACAGCACGATTGACGGGATCCCACCTTTAATTTGAACCGGCTTTCCATATTTACAGTTGGATTGCCAGTCTCTCTGGGCCCCAATCAATTCTTTCCAATGCTTTAGCTTTAGGTATTGCGGAGCGACGTCATCGATGACGTTATACTCGGCATCGTTCGAGAAAACCCTAGAATTGAAATCAAGGTGCCCACTGATATAGTTATGACGCCCTAGGGCACGAGCCCACATTGTCTTGCCGGTTCTAGAATCACCCTCTACTATTATACTTATATTTCTATATGGCCGCGCAGCGGAACCCTTATTAAAATAATCATCAGCCCATTCCTGTAACTCTTCTGGAACTAGTGTGAACGACGAGAGTGGAAACGGAGGGACCCATGGTTCAGGAGGCTGATGAAAGAGGCGCTCGATGTTAGCCTTCAAATTGTGATAACTAACAAGAAATGTTTTAGGATCTCCGGCCTTTATAATGTCGAGAGCCTCTCCCGCACTTCCTGCATTGACGGCGTTGTGATATACGTCGTCTTTGCTAGATTTTGTACCCCCAGACACTTTATATTTCCCGGACTCACAATAATCACCTTCTTTGGTGATGTAATTCTTGACGGCGTTGGTGTCTTTGGCTGCCTGAATGTTCGGGTGAAAACAGGCAGCCCTTCTGGGGTGAGTAAGGTCGAAAAATCTAGCATTCTTGATGTTAGTCTTACCGGATAACTGTATGAGGCAGTGTAAGTGCGGGAACCCGTCGGAATGTTCCTCTCGTGCGACTCTGATATATGTTGGTTTGACGACCGACCATTGCAGATGCTCAAGCATCTGAATAGCTTCATCTTTGGGGATGTCGCACTGAGGATATGTTAAGAAAATGTTCCTGGCTGTAAAACGAAATGAATTAGGGTTCCGTGGCATTTTCGTAATAAAAACCCAGGACACCAGGGAGAGCTCTCTCTAAAACCTATTATTGCTGGTGTCCTGGTGTCCCATTTATACAACTCTCTGGGGAGGACACCAGGGGCAAAATCGGCCATCCGCAATAATATT
NC_004646
ACCGGATGGCCGCAAATTTTTTGGTGTCCTACTTTTACAAGGCCCAGTCCCATACTATACACAAGTGGGCCGGTGTTTTAATCAAAGTAGCAGCCCATCAGTGTTTCACGGGGACCACACAGCACTATTGACCAATCATATTTAACCTGTCAAGTCATTATAATGTATCGTCGTACGAACATTCTGGCCCATTTCACATGGTGCTGTGTCAGATGATCTATCTTTAATACAAATTGCCAAAGTGACTAGTCGTTCTTTAATTTGAAATCTCAAATAAGGCTGGTCCATTGCTTTAATATATGTACGATCATCTTTTGTTAGCACCCACATGTGAGCAATTTGAATTAACTTTAATGTAACCAATTACATTTCAGGCAAGGAGTCTAGCTATATATATCCATATATGGGTCGTGTCTATTAATACGACGGAGGGTAATTGGTTATCACGTCGAATACATGTATAGATATATTGTCTAACGTGTATATTGTTGACTCCTCAGAGCAACCAGAGCACTGTCGAGCATGTATTCGTCTAGACGCGGTCGACCCAATGTTCAACGAGTAAGTCATCTACGGCGTACTTATTTCAAACGTCCATATTATCAGACACGTGGTGATGAGAAGCGTCGACCGACTGCTGTTAATAAGACTCATGACGACACAAAGATGTCACTACAACGTCTACACGAGGATCAGTTTGGTCCAGATTTCGTTTTAGGTCATAATACAGCTTTGTCCACGTTTATCACCTACCCAAGTATTGTTAAGACTGAACCCAATCGGACGCGGTCGTATATCAAGTTGAAACGACTGCGTTTTAAAGGCACATTGAAAATTGAACGTGGACATGGTGGTACGGTGATGGAAGATCCAACGTCTAAGATTGAAGGGGTTTTCTCTATGGTTGTTGTGGTTGATCGTAAACCACATGTAAACCCTTCTGGACGACTACATACATTCGACGAACTATTTGGCGCGCGGATCCATAGTCACGGTAATCTAGCTATCGTTCCCGCGCTCAAGGATCGTTTTTACATTAAACATGTAATGAAACGCGTTTTATCGGTCGAGAAGGATACATTAATGGTTGATCTACAGGGATCGACAACGTTTTCCAACAAGCGTTTCAATTGCTGGTCTGCGTTTAATGATCTTGAACGGGATTCATGTAACGGGGTTTACGCAAACATAAGCAAGAACGCCATTCTAGTTTATTATTGTTGGATGTCGGATACGCCTTCTAAGGCATCCACATATGTATCATTTGACCTTGAATATGTTGGATGAATAAGAATAATATATTCCACAATACTATCTCCACAGGACCCAGGATCATCTATAAAACAAGCCCCAATTTTCTTATTTTAAAATTGGGAGCGCAGCGGGACACTCTTCAAAATCATGTTCAACCCATAAATTTAATCTGTCAAGTCAACTACAAGATAAGTTTATATAATAAAGAAACGCTAATTTAGAGATTTTGGAGTACTCGGAATACAACTGGTCTTAATGCATTCATGAACAGTCGACTTAACTAACTCGTTCAGCTGCGACATCGACATGGTTATGGTAGATTGCGACCGTTGTATTCCGACGATGGATGCTGATTCCCCGGGGTCTAATACAGTCGTCCCTAACCTGTTTAGTTCCCTGTATGGAAGCATCTCATCGTCCATCTCTAAATCCGCATTTGTAGGACCTGGACCAATCATACTTCTAGTGGCCCAAGATTCACCAGGATTAATTTCTATTGGGCCTCTAAGCCCATATCTGGAAAGTGATGCGGATTTGACCAGTCTTCTCTCCCATTTGCCGTATCCAACGTGCCAGAAATCTATATCCTTTTCGCTAAATTGTTTGGTAAGTATCTTTACGGTTGGTGCCCGGAATGGGATGTCGACGGAGTGCTTTGCCGACGATAGCTTTAGCTTGCCCTTGAATTTAGCGAAATGCGTCATCTGATGAACATTCGATTCTGACACTCTATAGTATAATTTCCATGGAATTGGGTCTTTGAGAGAGAAGAATGATGATGAGAAATAGTGGAGATCTATGTTGCATCTAATCGGAAACGTCCAGGATGCTTGCAGCGACTCATTGTCCGTCATGCGTTTGTCGTGGATCTCCACTATTACGGTACCGGAGGCGTTTATAGGTACCTGCTGTCTGTATTCTATGACACAATGGTCGATCTTCATACAACTACGACTCAGGCGCGCAGTTAATTGAGATGCAGTCGACGGAAATTGCAGAACAATTTCTGTTAGGTCGTGAGACAGTTGAAATTCATCCCGATGAGATTCTATATAATTAAATGCGCTTGGAGGAGGAACTAATTGTGAACCCATCTTACTATTAGCTCGATCTAACAATTCTGGATGTGTACCAGTGACCTTAAATAAATTTATAGATGAGGAACGAAGTGAGTTAGGGTTTCAGTGGCATATTTGGTAAATATGAACCGGGACACCAGGGGGAGCTCTCTCTAAAACCTATTATTGCTGGTGTCCTGGTGTCCCATTTATACAACTCTCTGGGGAGGACACCAGGGGCAAAATCGGCCATCCGCAATAATATT
Gene Information
| NCBI Accession | NP_808801.1 |
|---|---|
| Location | 203-958 |
| Protein Name | AV1 coat protein |
| Coding Region | ATGCCTAAGCGTGATGCCCCATCGCGTTTAATGGCGGGGACCTCGAAAGTCTCCCGCTCTGCTAACTATTCGCCTCGTGGAGGTATGGGCCCTAAATTCAATAAGGCCGCTGCGTGGGTGAACAGGCCCATGTATAGGAAGCCCAGGATCTATCGGACGTTCAGAAGTCCCGATGTTCCCAAGGGGTGTGAAGGACCTTGTAAGGTCCAGTCTTACGAGCAGCGGCATGATGTCTCTCATGTTGGCAAGGTAATGTGTATATCTGACGTGACCCGTGGTAACGGTATTACACACCGTGTCGGGAAACGTTTTTGTGTCAAGTCTGTATATATATTAGGGAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCACACTAACAGCGTTATGTTTTGGTTGGTACGAGACCGTAGACCGTATGGGACTCCTATGGAGTTCGGCCAAGTGTTCAACATGTTCGACAATGAGCCCAGTACGGCGACTGTTAAGAACGATCTCCGTGATCGTTTTCAAGTTATGCACAAGTTCTATGCTAAGGTCACTGGTGGTCAATATGCTAGCAACGAGCAAGCGTTGGTTAAAAGATTTTGGAAGGTCAACAACCATGTCGTCTATAACCACCAGGAAGCTGGGAAGTACGAGAATCATACAGAGAATGCTTTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCGACATTGAAAATACGGATCTATTTTTATGATTCAATAACAAATTAA |
| Protein Sequence | MPKRDAPSRLMAGTSKVSRSANYSPRGGMGPKFNKAAAWVNRPMYRKPRIYRTFRSPDVPKGCEGPCKVQSYEQRHDVSHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMEFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | NP_808802.1 |
|---|---|
| Location | 955-1353 |
| Protein Name | AC3 |
| Coding Region | ATGGATTTACGCACCGGGGAGAGCATCACTGTGTATCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTGTATTTCAAGATAACAGAAGTGGAGGATACCGTCCACTCTCACATGCGGATATATCATATCCAAATCCGGTTCAACCACAACCTGAGGAGAGCACTAAATCTTCACAAAGCGTTCCTGAACTACCAAGTCTGGACGGAGTCGATTCGAGCTTCTGGGACGACTTATTTAAATAGATTTAAACATTTAGTGCTATTGTACTTAGATAGGTTAGGAGTTATTGGTCTCAATAACGTTGTTAGAGCTGTTTCCTGGGCAACTGATCGTTCTTATGTATATTATGTACACGAGAAGCATGAAATAAAATTTAATCTTTATTAA |
| Protein Sequence | MDLRTGESITVYQAENSVFIWEVPNPLYFKITEVEDTVHSHMRIYHIQIRFNHNLRRALNLHKAFLNYQVWTESIRASGTTYLNRFKHLVLLYLDRLGVIGLNNVVRAVSWATDRSYVYYVHEKHEIKFNLY |
| NCBI Accession | NP_808803.1 |
|---|---|
| Location | 1100-1489 |
| Protein Name | AC2 |
| Coding Region | ATGCTAAATTCATCTTCCTCGAGAGCCCCCTCTATCAAAGCACAGCACAAGATTGCTAAAAGAAGGGCTGTACGTCGACGACGAATCGATCTAAACTGCGGCTGTTCCATATTTTTCCATATCAACTGCACGAACCATGGATTTACGCACCGGGGAGAGCATCACTGTGTATCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTGTATTTCAAGATAACAGAAGTGGAGGATACCGTCCACTCTCACATGCGGATATATCATATCCAAATCCGGTTCAACCACAACCTGAGGAGAGCACTAAATCTTCACAAAGCGTTCCTGAACTACCAAGTCTGGACGGAGTCGATTCGAGCTTCTGGGACGACTTATTTAAATAG |
| Protein Sequence | MLNSSSSRAPSIKAQHKIAKRRAVRRRRIDLNCGCSIFFHINCTNHGFTHRGEHHCVSGREFRFYLGGSKSPVFQDNRSGGYRPLSHADISYPNPVQPQPEESTKSSQSVPELPSLDGVDSSFWDDLFK |
| NCBI Accession | NP_808804.1 |
|---|---|
| Location | 1431-2480 |
| Protein Name | Rep associated protein |
| Coding Region | ATGCCACGGAACCCTAATTCATTTCGTTTTACAGCCAGGAACATTTTCTTAACATATCCTCAGTGCGACATCCCCAAAGATGAAGCTATTCAGATGCTTGAGCATCTGCAATGGTCGGTCGTCAAACCAACATATATCAGAGTCGCACGAGAGGAACATTCCGACGGGTTCCCGCACTTACACTGCCTCATACAGTTATCCGGTAAGACTAACATCAAGAATGCTAGATTTTTCGACCTTACTCACCCCAGAAGGGCTGCCTGTTTTCACCCGAACATTCAGGCAGCCAAAGACACCAACGCCGTCAAGAATTACATCACCAAAGAAGGTGATTATTGTGAGTCCGGGAAATATAAAGTGTCTGGGGGTACAAAATCTAGCAAAGACGACGTATATCACAACGCCGTCAATGCAGGAAGTGCGGGAGAGGCTCTCGACATTATAAAGGCCGGAGATCCTAAAACATTTCTTGTTAGTTATCACAATTTGAAGGCTAACATCGAGCGCCTCTTTCATCAGCCTCCTGAACCATGGGTCCCTCCGTTTCCACTCTCGTCGTTCACACTAGTTCCAGAAGAGTTACAGGAATGGGCTGATGATTATTTTAATAAGGGTTCCGCTGCGCGGCCATATAGAAATATAAGTATAATAGTAGAGGGTGATTCTAGAACCGGCAAGACAATGTGGGCTCGTGCCCTAGGGCGTCATAACTATATCAGTGGGCACCTTGATTTCAATTCTAGGGTTTTCTCGAACGATGCCGAGTATAACGTCATCGATGACGTCGCTCCGCAATACCTAAAGCTAAAGCATTGGAAAGAATTGATTGGGGCCCAGAGAGACTGGCAATCCAACTGTAAATATGGAAAGCCGGTTCAAATTAAAGGTGGGATCCCGTCAATCGTGCTGTGCAATCCAGGCGAGGGGGCCAGCTATAAAGATTTCCTGGACAAAGCGGAAAATACCGCACTAAAGGCCTGGACATTAAAAAATGCTAAATTCATCTTCCTCGAGAGCCCCCTCTATCAAAGCACAGCACAAGATTGCTAA |
| Protein Sequence | MPRNPNSFRFTARNIFLTYPQCDIPKDEAIQMLEHLQWSVVKPTYIRVAREEHSDGFPHLHCLIQLSGKTNIKNARFFDLTHPRRAACFHPNIQAAKDTNAVKNYITKEGDYCESGKYKVSGGTKSSKDDVYHNAVNAGSAGEALDIIKAGDPKTFLVSYHNLKANIERLFHQPPEPWVPPFPLSSFTLVPEELQEWADDYFNKGSAARPYRNISIIVEGDSRTGKTMWARALGRHNYISGHLDFNSRVFSNDAEYNVIDDVAPQYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKAENTALKAWTLKNAKFIFLESPLYQSTAQDC |
| NCBI Accession | NP_808805.1 |
|---|---|
| Location | 523-1287 |
| Protein Name | BV1 |
| Coding Region | ATGTATTCGTCTAGACGCGGTCGACCCAATGTTCAACGAGTAAGTCATCTACGGCGTACTTATTTCAAACGTCCATATTATCAGACACGTGGTGATGAGAAGCGTCGACCGACTGCTGTTAATAAGACTCATGACGACACAAAGATGTCACTACAACGTCTACACGAGGATCAGTTTGGTCCAGATTTCGTTTTAGGTCATAATACAGCTTTGTCCACGTTTATCACCTACCCAAGTATTGTTAAGACTGAACCCAATCGGACGCGGTCGTATATCAAGTTGAAACGACTGCGTTTTAAAGGCACATTGAAAATTGAACGTGGACATGGTGGTACGGTGATGGAAGATCCAACGTCTAAGATTGAAGGGGTTTTCTCTATGGTTGTTGTGGTTGATCGTAAACCACATGTAAACCCTTCTGGACGACTACATACATTCGACGAACTATTTGGCGCGCGGATCCATAGTCACGGTAATCTAGCTATCGTTCCCGCGCTCAAGGATCGTTTTTACATTAAACATGTAATGAAACGCGTTTTATCGGTCGAGAAGGATACATTAATGGTTGATCTACAGGGATCGACAACGTTTTCCAACAAGCGTTTCAATTGCTGGTCTGCGTTTAATGATCTTGAACGGGATTCATGTAACGGGGTTTACGCAAACATAAGCAAGAACGCCATTCTAGTTTATTATTGTTGGATGTCGGATACGCCTTCTAAGGCATCCACATATGTATCATTTGACCTTGAATATGTTGGATGA |
| Protein Sequence | MYSSRRGRPNVQRVSHLRRTYFKRPYYQTRGDEKRRPTAVNKTHDDTKMSLQRLHEDQFGPDFVLGHNTALSTFITYPSIVKTEPNRTRSYIKLKRLRFKGTLKIERGHGGTVMEDPTSKIEGVFSMVVVVDRKPHVNPSGRLHTFDELFGARIHSHGNLAIVPALKDRFYIKHVMKRVLSVEKDTLMVDLQGSTTFSNKRFNCWSAFNDLERDSCNGVYANISKNAILVYYCWMSDTPSKASTYVSFDLEYVG |
| NCBI Accession | NP_808806.1 |
|---|---|
| Location | 1467-2348 |
| Protein Name | BC1 |
| Coding Region | ATGGGTTCACAATTAGTTCCTCCTCCAAGCGCATTTAATTATATAGAATCTCATCGGGATGAATTTCAACTGTCTCACGACCTAACAGAAATTGTTCTGCAATTTCCGTCGACTGCATCTCAATTAACTGCGCGCCTGAGTCGTAGTTGTATGAAGATCGACCATTGTGTCATAGAATACAGACAGCAGGTACCTATAAACGCCTCCGGTACCGTAATAGTGGAGATCCACGACAAACGCATGACGGACAATGAGTCGCTGCAAGCATCCTGGACGTTTCCGATTAGATGCAACATAGATCTCCACTATTTCTCATCATCATTCTTCTCTCTCAAAGACCCAATTCCATGGAAATTATACTATAGAGTGTCAGAATCGAATGTTCATCAGATGACGCATTTCGCTAAATTCAAGGGCAAGCTAAAGCTATCGTCGGCAAAGCACTCCGTCGACATCCCATTCCGGGCACCAACCGTAAAGATACTTACCAAACAATTTAGCGAAAAGGATATAGATTTCTGGCACGTTGGATACGGCAAATGGGAGAGAAGACTGGTCAAATCCGCATCACTTTCCAGATATGGGCTTAGAGGCCCAATAGAAATTAATCCTGGTGAATCTTGGGCCACTAGAAGTATGATTGGTCCAGGTCCTACAAATGCGGATTTAGAGATGGACGATGAGATGCTTCCATACAGGGAACTAAACAGGTTAGGGACGACTGTATTAGACCCCGGGGAATCAGCATCCATCGTCGGAATACAACGGTCGCAATCTACCATAACCATGTCGATGTCGCAGCTGAACGAGTTAGTTAAGTCGACTGTTCATGAATGCATTAAGACCAGTTGTATTCCGAGTACTCCAAAATCTCTAAATTAG |
| Protein Sequence | MGSQLVPPPSAFNYIESHRDEFQLSHDLTEIVLQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINASGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSESNVHQMTHFAKFKGKLKLSSAKHSVDIPFRAPTVKILTKQFSEKDIDFWHVGYGKWERRLVKSASLSRYGLRGPIEINPGESWATRSMIGPGPTNADLEMDDEMLPYRELNRLGTTVLDPGESASIVGIQRSQSTITMSMSQLNELVKSTVHECIKTSCIPSTPKSLN |
References More References in PubMed
| 1 |
Maliano MR, et al. Plant Dis. 2021 Oct;105(10):3162-3170. doi: 10.1094/PDIS-08-20-1759-RE. Epub 2021 Nov 7. PMID: 33591835 |
|---|---|
| 2 |
Al-Musa A, et al. Virus Genes. 2011 Aug;43(1):79-89. doi: 10.1007/s11262-011-0594-8. Epub 2011 Mar 12. PMID: 21399920 |
| 3 |
Sufrin-Ringwald T, et al. Phytopathology. 2011 Feb;101(2):281-9. doi: 10.1094/PHYTO-06-10-0159. PMID: 21219130 |