Squash leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000837705.1 |
| Release date | 2015/2/12 |
| Submitter | Lazarowitz,S.G., Lazdins,I.B. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
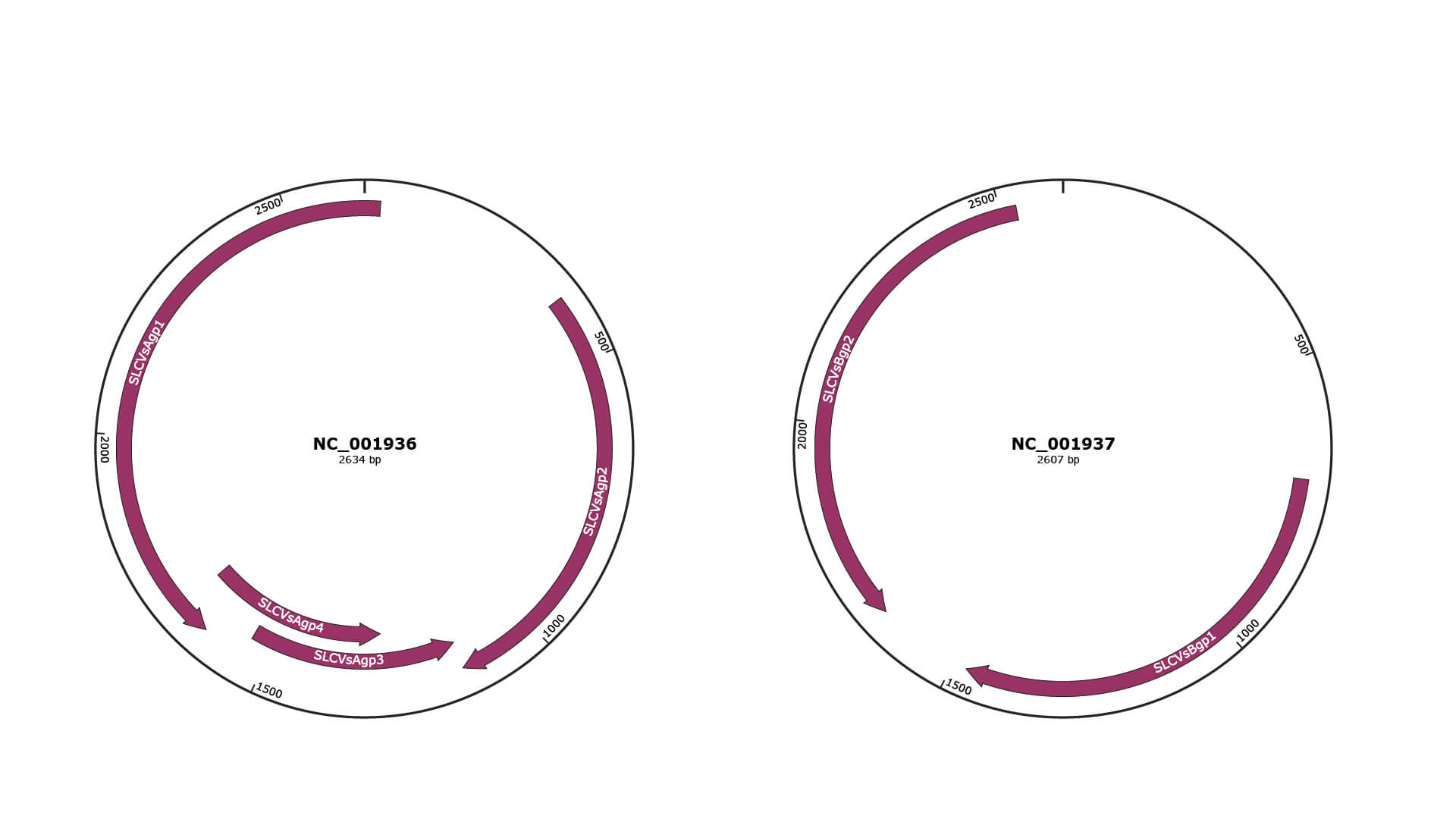
JBrowse
Genome
NC_001936
NC_001937
Gene Information
| NCBI Accession | NP_047243.2 |
|---|---|
| Location | 1619-2634,1->28 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCACGAAACCCTAATTCCTTTCGTTTAACTGCCAGAAACATATTCTTAACTTATCCAAGGTGCGATGTTCCCAAAGAAGAAGTTCTTGAGATGCTTCTGCATCTCTCGTGGTCGGTCGTCAAACCGAATTACGTTAGAGTCGCCAGAGAGGAACATTCCGACGGGTCTCCGCACTTACACTGCCTCATTCAATTATCTGGAAAATCCAACATCAAGGATGCTGGATTTTTCGACCTCACTCACCCCAGACGGTCTGCCCGATTTCACCCAAACATTCAGGCTGCCAAAGACACCAACGCCGTCAAGAACTACATCACCAAAGAAGGTGATTATTGTGAATCCGGGCAATATAAAGTGTCTGGGGGTTCAAAGTCAAACAAAGACGACGTATATCACAATGCCGTTAATGCAGGTAGTGCGGGAGAAGCTCTCGACATTATAAAAGCTGGTGATCCAAAGACGTTTATCGTTAATTATCACAATTTATTAGCTAACGTCGAGAGATTATTTCAGAAACCTCCGGAACCGTGGGTTCCTCCGTTTGAGCTCTCTTCGTTCACGTCAGTTCCAGAAGAGTTACAAGATTGGGCTGATGATTATTTTAATGAGTGTTCCGCTGCGGCAAGGCCAACTAGTATAATCATAGAAGGTGGTTCAAGAACGGGCAAGACAATGTGGGCTAGGTCGTTAGGCCCACATAATTACTTGAGCGGCCATCTTGATTTCAATTCTAGGGTTTTCTCAAATGACGTCAAGTATAACGTCATTGATGACGTCGCTCCGCATTACCTAAAGCTAAAGCACTGGAAGGAATTGATTGGGGCCCAAAGGGACTGGCAGTCCAACTGTAAATATGGAAAGCCGGTTCAAATTAAAGGTGGAATCCCATCAATCGTGCTGTGCAATCCTGGAGAGGGGTCCAGTTATAAAGATTTCCTCGACAAAGCCGAGAACTCGGCTCTAAGAGAGTGGACTGAAAAAAATGCCAAATTCATCTTCCTCGAAGGTCCCCTCTATCAAAGCACAGCACAGGATTGCTAA |
| Protein Sequence | MPRNPNSFRLTARNIFLTYPRCDVPKEEVLEMLLHLSWSVVKPNYVRVAREEHSDGSPHLHCLIQLSGKSNIKDAGFFDLTHPRRSARFHPNIQAAKDTNAVKNYITKEGDYCESGQYKVSGGSKSNKDDVYHNAVNAGSAGEALDIIKAGDPKTFIVNYHNLLANVERLFQKPPEPWVPPFELSSFTSVPEELQDWADDYFNECSAAARPTSIIIEGGSRTGKTMWARSLGPHNYLSGHLDFNSRVFSNDVKYNVIDDVAPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKDFLDKAENSALREWTEKNAKFIFLEGPLYQSTAQDC |
| NCBI Accession | NP_047244.1 |
|---|---|
| Location | 385-1140 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGTTAAGAGAGATGCCCCATGGCGTTTAATGGCGGGGACCTCAAAGGTCTCACGCTCTGCTAACTTTTCGCCTCGTGAAGGTATGGGCCCAAAATTCAACAAGGCCGCTGCATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTATCGCACAATGAGAGGCCCAGACATCCCCAAGGGATGTGAGGGGCCATGCAAGGTTCAGTCTTACGAGCAGCGGCATGATATCTCTCATCTTGGCAAGGTAATGTGTATTTCTGACGTGACGCGTGGTAATGGCATTACTCACCGCGTCGGCAAGCGCTTTTGTGTTAAGTCTGTATATATTTTAGGCAAGATATGGATGGACGAAAATATCAAGTTGAAGAATCACACGAACAGTGTGATGTTTTGGTTAGTTCGAGACCGTAGACCATATGGCACTCCTATGGATTTCGGCCAGGTGTTCAATATGTTCGACAACGAGCCCAGTACGGCAACTATCAAGAACGATCTACGTGATCGTTATCAAGTCATGCACAGGTTCTACGCGAAGGTCACTGGTGGTCAGTATGCGAGCAACGAACAAGCCTTGGTTAGGCGTTTCTGGAAGGTCAACAACCATGTTGTGTATAACCACCAGGAAGCCGGGAAATACGAGAATCATACGGAGAACGCTCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MVKRDAPWRLMAGTSKVSRSANFSPREGMGPKFNKAAAWVNRPMYRKPRIYRTMRGPDIPKGCEGPCKVQSYEQRHDISHLGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATIKNDLRDRYQVMHRFYAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | NP_047245.1 |
|---|---|
| Location | 1137-1541 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGTAATGGATTTACGCACATGGGACGACATCACTGTGCATCAGGCAGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATGTACAANGTGGAGGATCCACTCTACACGCACACAAGGATATACCACATACAAATCCGGTTCAACCACAACCTGAGGAGAGCACTAAATCTTCACAAAGCGTTCCTGAACTTCCAAGTCTGGACGGAATCGATTCGAGCTTCTGGGACGACATATTTGAATAGATTTAGGCATTTAGTTATGTTGTACTTAGATAGGTTAGGAGTTATTGGTCTCAATAACGTTATACGAGCTGTATCTTGGGCAACAGACCGTTCATATGTAAATTATGTACTCGAGAATCATGAAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MVMDLRTWDDITVHQAENSVFIWEVPNPLYFKMYXVEDPLYTHTRIYHIQIRFNHNLRRALNLHKAFLNFQVWTESIRASGTTYLNRFRHLVMLYLDRLGVIGLNNVIRAVSWATDRSYVNYVLENHEIKFKIY |
| NCBI Accession | NP_047246.1 |
|---|---|
| Location | 1282-1677 |
| Protein Name | hypothetical protein |
| Coding Region | ATGCCAAATTCATCTTCCTCGAAGGTCCCCTCTATCAAAGCACAGCACAGGATTGCTAAAAAGAGAGCTGTTCGTCGTCGAAGAATCGACTTAGACTGTGGCTGTTCCATATACATTCATATCAACTGCGCCAAAGATGGTAATGGATTTACGCACATGGGACGACATCACTGTGCATCAGGCAGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATGTACAANGTGGAGGATCCACTCTACACGCACACAAGGATATACCACATACAAATCCGGTTCAACCACAACCTGAGGAGAGCACTAAATCTTCACAAAGCGTTCCTGAACTTCCAAGTCTGGACGGAATCGATTCGAGCTTCTGGGACGACATATTTGAATAG |
| Protein Sequence | MPNSSSSKVPSIKAQHRIAKKRAVRRRRIDLDCGCSIYIHINCAKDGNGFTHMGRHHCASGREFRFYLGGSKSPLFQDVQXGGSTLHAHKDIPHTNPVQPQPEESTKSSQSVPELPSLDGIDSSFWDDIFE |
| NCBI Accession | NP_047247.2 |
|---|---|
| Location | 705-1475 |
| Protein Name | Nuclear shuttle protein |
| Coding Region | ATGTATTCGACGAGCAATAGACGGGGTCGATCGCAAACTCAGCGAGGTTCTCATGTACGCCGTACAGGTGTCAAGCGTTCATATGGTGCAGCCCGTGGTGATGATAGGCGTCGACCCAACGTGGTATCAAAGACTCAAGTTGAACCGAGAATGACTATTCAGCGTGTTCAAGAGAACCAGTTTGGCCCAGAATTTGTCTTGAGTCAAAACTCAGCGTTGTCCACGTTTGTAACATATCCTAGCTATGTTAAGACTGTTCCCAATCGCACTAGAACGTATATAAAATTGAAACGAGTGCGTTTTAAGGGAACTCTGAAAATTGAACGTGGACAAGGTGACACTATTATGGACGGGCCCAGTTCTAATATTGAAGGAGTATTTTCTATGGTCATCGTGGTTGATCGGAAACCACATGTTAGTCAATCTGGCCGTCTACATACATTTGATGAGTTGTTTGGCGCGCGTATCCATTGTCACGGTAATTTATCTGTCGTACCTGCATTGAAGGACCGTTACTACATTAGACACGTTACGAAGCGTGTGGTGTCTCTTGAAAAGGACACGTTACTGATTGATCTCCATGGTACGACACAACTGTCTAACAAGCGTTATAATTGTTGGGCATCGTTCAGCGATCTTGAACGGGATTCATGTAATGGCGTTTACGGTAACATAACCAAGAACGCTCTGTTAGTGTATTACTGTTGGCTGTCGGATGCCCAGTCCAAGGCATCAACATATGTATCGTTTGAACTGGACTATTTGGGATGA |
| Protein Sequence | MYSTSNRRGRSQTQRGSHVRRTGVKRSYGAARGDDRRRPNVVSKTQVEPRMTIQRVQENQFGPEFVLSQNSALSTFVTYPSYVKTVPNRTRTYIKLKRVRFKGTLKIERGQGDTIMDGPSSNIEGVFSMVIVVDRKPHVSQSGRLHTFDELFGARIHCHGNLSVVPALKDRYYIRHVTKRVVSLEKDTLLIDLHGTTQLSNKRYNCWASFSDLERDSCNGVYGNITKNALLVYYCWLSDAQSKASTYVSFELDYLG |
| NCBI Accession | NP_047248.1 |
|---|---|
| Location | 1647-2528 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGGTTCTCAATTAGTTCCACCCCCAAGCGCATTCAATTACATAGAATCGCAGAGGGACGAATTTCAGTTATCGCACGACCTAACGGAAATTGTTCTGCAATTTCCCTCGACGGCATCTCAGATAACAGCGAGGCTGAGTCGTAGTTGTATGAAAATCGACCACTGCGTCATAGAATATCGGCAACAGGTTCCGATCAACGCATCTGGTACGGTGATAGTGGAGATTCACGACAAACGCATGACGGACAATGAATCTCTGCAAGCGTCGTGGACTTTTCCGATAAGATGTAACATAGATCTCCACTATTTTTCATCATCGTTCTTCTCTCTAAAAGACCCAATCCCATGGAAGTTATACTATCGAGTCTCAGACTCGAATGTGCATCAAATGACGCATTTCGCTAAATTCAAGGGCAAACTGAAGCTATCGTCGGCGAAGCACTCCGTTGATATCCCTTTCCGGGCACCAACAGTAAAGATACTTGCAAAACAATTTAGCGAAAAGGACATTGATTTCTGGCACGTGGGATACGGCAAGTGGGAGAGAAGACTGGTCAAATCCGCATCATCATCTAGATTTGGGCTAAGAGGCCCAATTGAAATTAATCCAGGTGAATCTTGGGCCACAAAAAGTGCAATAGGCCCAACTAACAGAAATGCGGATTTGGATATTGAAGAAGAGCTGCTTCCATACAGGGAACTCAACAGATTGGGAACTAACATCTTAGATCCTGGGGAATCAGCTTCAATAGTCGGAATACAACGGTCGCAATCGAACATCACCATGTCAATGTCACAGTTGAACGAATTAGTTAGATCCACTGTACATGAATGCATTAAAACCAGTTGTATCCCGAGCACTCCAAAATCCCTAAGCTAA |
| Protein Sequence | MGSQLVPPPSAFNYIESQRDEFQLSHDLTEIVLQFPSTASQITARLSRSCMKIDHCVIEYRQQVPINASGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDSNVHQMTHFAKFKGKLKLSSAKHSVDIPFRAPTVKILAKQFSEKDIDFWHVGYGKWERRLVKSASSSRFGLRGPIEINPGESWATKSAIGPTNRNADLDIEEELLPYRELNRLGTNILDPGESASIVGIQRSQSNITMSMSQLNELVRSTVHECIKTSCIPSTPKSLS |
References More References in PubMed
| 1 |
Xie Y, et al. Virology. 2024 Jun;594:110040. doi: 10.1016/j.virol.2024.110040. Epub 2024 Mar 5. PMID: 38471198 |
|---|---|
| 2 |
Tobacco leaf curl Puer virus: a novel monopartite begomovirus infecting Nicotiana tabacum in China. Jiang N, et al. Arch Virol. 2022 Jan;167(1):229-232. doi: 10.1007/s00705-021-05267-9. Epub 2021 Oct 15. PMID: 34652555 |
| 3 |
Cucurbit Leaf Crumple Virus Is Seed Transmitted in Yellow Squash (Cucurbita pepo). Dhadly DK, et al. Plant Dis. 2025 Jan;109(1):63-72. doi: 10.1094/PDIS-06-24-1330-RE. Epub 2025 Jan 4. PMID: 39151040 |
| 4 |
Zaidi SS, et al. Mol Plant Pathol. 2017 Sep;18(7):901-911. doi: 10.1111/mpp.12481. Epub 2016 Oct 17. PMID: 27553982 |
| 5 |
Schafleitner R, et al. Sci Rep. 2024 Mar 21;14(1):6793. doi: 10.1038/s41598-024-57348-9. PMID: 38514827 |
| 6 |
Tomato leaf curl Kunene virus: a novel tomato-infecting monopartite begomovirus from Namibia. Lett JM, et al. Arch Virol. 2020 Aug;165(8):1887-1889. doi: 10.1007/s00705-020-04666-8. Epub 2020 May 23. PMID: 32447622 |
| 7 |
Akbar A, et al. Virol J. 2024 Nov 27;21(1):308. doi: 10.1186/s12985-024-02540-6. PMID: 39605076 |
| 8 |
Detection of Tomato Leaf Curl New Delhi Virus-ES by Real-Time Quantitative PCR. Janssen D, et al. Methods Mol Biol. 2025;2912:145-156. doi: 10.1007/978-1-0716-4454-6_12. PMID: 40064778 |
| 9 |
Donati L, et al. Viruses. 2022 Mar 15;14(3):607. doi: 10.3390/v14030607. PMID: 35337014 |
| 10 |
Tomato leaf curl New Delhi virus: an emerging threat to cucurbit crops in China. Chen Y, et al. Virology. 2026 Jun;619:110901. doi: 10.1016/j.virol.2026.110901. Epub 2026 Apr 2. PMID: 41946284 |