Squash leaf curl Philippines virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000843565.1 |
| Isolate | Philippines |
| Release date | 2015/2/12 |
| Submitter | Kon,T., Dolores,L.M., Bajet,N.B., Hase,S., Takahashi,H., Ikegami,M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
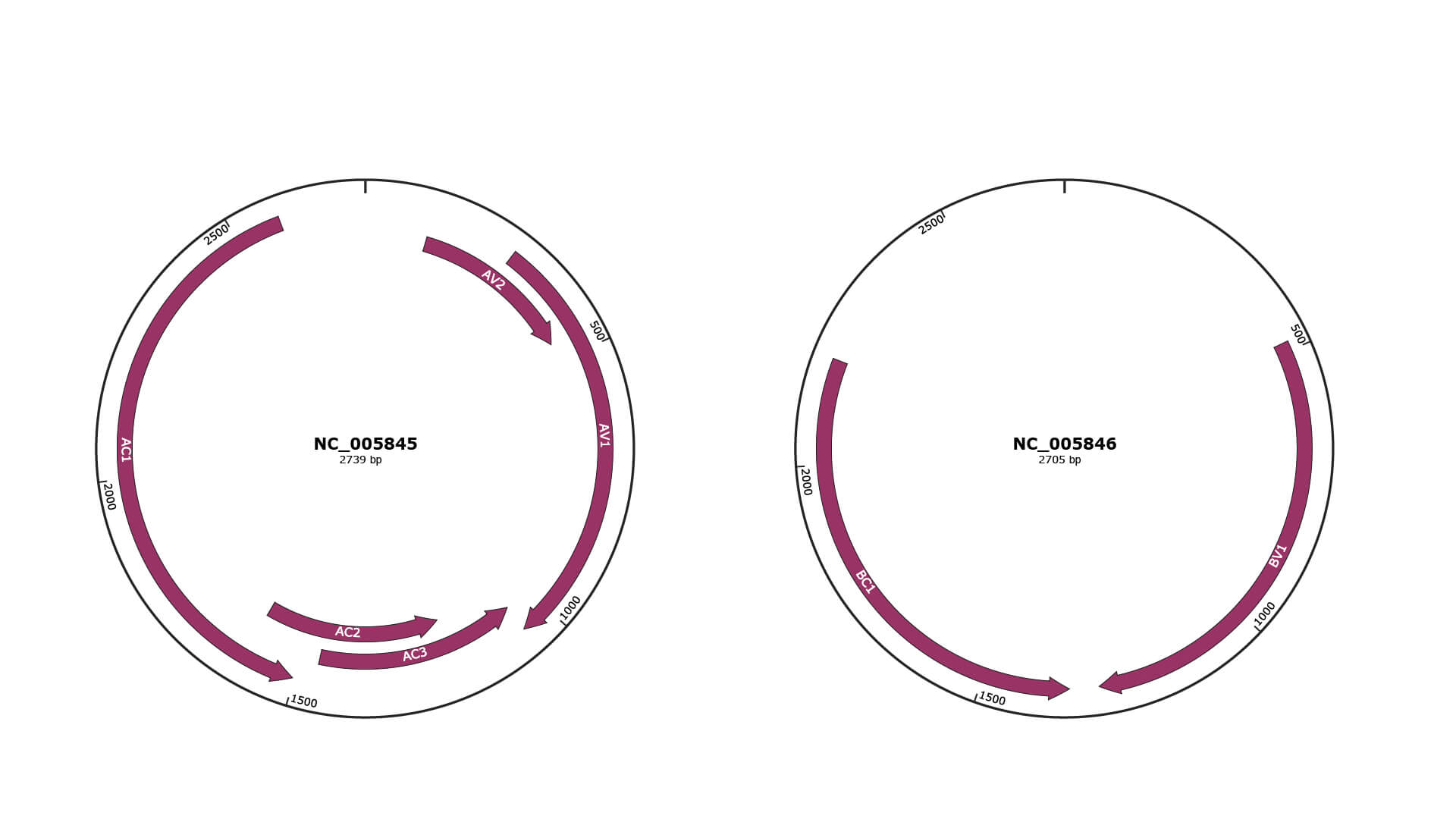
JBrowse
Genome
NC_005845
NC_005846
Gene Information
| NCBI Accession | YP_006439.1 |
|---|---|
| Location | 125-463 |
| Gene Name | AV2 |
| Protein Name | hypothetical protein |
| Coding Region | ATGTGGGATCCACTTATGCACGAATTCCCTGAAAGTGTTCATGGTCTACGGTGCATGCTAGCTGTGAAATATCTTCAGGAGGTGGAAAAAACATATTCTCCGGACACAGTCGGCTACGATCTTGTTCGCGATCTTATTCTTGTTCTCCGCGCAAGGAACTATGTCGAAGCGACCAGCCGATATTATCATTTCAACTCCCGCGTCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCCTATGTTTCCCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAGGGAAAGGCCTGGACAAACAGGCCCATGAACAGAAAACCCAAGATGTACAGGATGTATAG |
| Protein Sequence | MWDPLMHEFPESVHGLRCMLAVKYLQEVEKTYSPDTVGYDLVRDLILVLRARNYVEATSRYYHFNSRVEGTPTSQLRQPLCFPCSCPHCPRHKGKGLDKQAHEQKTQDVQDV |
| NCBI Accession | YP_006440.1 |
|---|---|
| Location | 285-1055 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCAGCCGATATTATCATTTCAACTCCCGCGTCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCCTATGTTTCCCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAGGGAAAGGCCTGGACAAACAGGCCCATGAACAGAAAACCCAAGATGTACAGGATGTATAGAAGTCCCGACGTGCCAAGGGGCTGTGAAGGCCCTTGTAAAGTTCAATCGTTCGAATCTAGGCACGATGTCTCTCATATTGGGAAGGTAATGTGTATCAGCGATGTTACACGAGGAACCGGACTCACACATCGCGTTGGGAAGCGATTTTGTGTGAAATCTGTTTATGTTTTGGGAAAGATATGGATGGATGAAAATATCAAGACTAAAAATCATACTAATAGTGTCATATTTTTTCTGGTTCGAGACCGTCGTCCTACAGGGACCCCTCAGGATTTTGGGGAGGTTTTTAATATGTTCGACAATGAACCGAGCACTGCAACGGTGAAGAACATGCATCGTGATCGATACCAAGTTCTGCGCAAATGGCATGCTACTGTGACGGGAGGAGCATACGCATCAAGGGAGCAAGCATTAGTTAGGAAGTTTGTTAGAGTTAATAGTTATATTGTCTACAATCAACAAGAGGCCGGCAAGTATGAGAATCATACTGAAAATGCATTAATGTTGTATATGGCCTGTACTCATGCATCGAACCCTGTATACGCGACTTTGAAAATCCGGATCTATTTTTATGATTCGGTAACAAATTAA |
| Protein Sequence | MSKRPADIIISTPASKVRRRLNFDSPYVSRAVVPIARVTKGKAWTNRPMNRKPKMYRMYRSPDVPRGCEGPCKVQSFESRHDVSHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVIFFLVRDRRPTGTPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGAYASREQALVRKFVRVNSYIVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | YP_006441.1 |
|---|---|
| Location | 1052-1462 |
| Gene Name | AC3 |
| Protein Name | replication enhancer |
| Coding Region | ATGATCACGGATTCACGCACAGGGGAGTACATCACTGCGGATCGAGCAGAGAGTGGCGTGTATATCTGGGACGTTCCAAATCCCCTCTATTTCAAAATAATGAAACACGACATCAGACCTTGCCTGGAAGAACACGACATAATCAAAGTGCACATCATGTTCAACCACAACCTGCGGAAAGCACTGGGGCTTCACAAATGTGTTCTAATGTTCCAGATCTGGACGGGCTTACGCCCGCAGACTGGGATTTTCTTGAGAGTCTTTAAAACCCAAGTCCTTAAGTACTTGGACATGTTAGGGGTGATTAGTATTTACAATGTAATAAGAGCTGTTTATCATGTTCTGGACAATGTGTTGGAAAAGACAATTGATGTATGGATAACGTATGATGTGAAATTGAATATATATTAA |
| Protein Sequence | MITDSRTGEYITADRAESGVYIWDVPNPLYFKIMKHDIRPCLEEHDIIKVHIMFNHNLRKALGLHKCVLMFQIWTGLRPQTGIFLRVFKTQVLKYLDMLGVISIYNVIRAVYHVLDNVLEKTIDVWITYDVKLNIY |
| NCBI Accession | YP_006442.1 |
|---|---|
| Location | 1197-1601 |
| Gene Name | AC2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCAATCTTTATCACACTCGAAGAACCACTCTATTCCGGTCGCGAAAGAATCGCAACCGCAGAGGAAGAAGAAGAACATCAGGCGCAGACGAATTGATCTACCGTGCGGATGCTCGTATTACATGTCAATAAATTGCCATGATCACGGATTCACGCACAGGGGAGTACATCACTGCGGATCGAGCAGAGAGTGGCGTGTATATCTGGGACGTTCCAAATCCCCTCTATTTCAAAATAATGAAACACGACATCAGACCTTGCCTGGAAGAACACGACATAATCAAAGTGCACATCATGTTCAACCACAACCTGCGGAAAGCACTGGGGCTTCACAAATGTGTTCTAATGTTCCAGATCTGGACGGGCTTACGCCCGCAGACTGGGATTTTCTTGAGAGTCTTTAA |
| Protein Sequence | MQSLSHSKNHSIPVAKESQPQRKKKNIRRRRIDLPCGCSYYMSINCHDHGFTHRGVHHCGSSREWRVYLGRSKSPLFQNNETRHQTLPGRTRHNQSAHHVQPQPAESTGASQMCSNVPDLDGLTPADWDFLESL |
| NCBI Accession | YP_006443.1 |
|---|---|
| Location | 1504-2583 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGGCACCTCCAAAGCGTTTTAGAATACAAGCCAAAAACTATTTCCTCACTTATCCCAAATGCTCTCTTACTAAAGAAGAGGCACTTTCCCAATTACAAACCCTAGAAACTCCAACTTCAAAGAAATTTATCAAAATTTGTAGAGAGTTGCACGAAGATGGGTCTCCGCATATCCACGTTCTTATCCAGTTCGAAGGGAAGTTCGTCTGCACGAATAACAGATTCTTCGACTTGGTGTCCCCAAGTCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGACAAAGATGGGGACACACTGGAATGGGGAAAATTCCAGGTCGACGGCAGAAGCGCTAGAGGCGGTCAGCAGTCTGCTAACGACACTGCCGCAAAGGCATTAAATTCAGGTTCAGCCGAAGCAGCTTTAGCAATAATTAGGGAAGAACTACCAAAAGATTTTATTTTTCAATACCATAATATTAAAAATAATTTAGATAGGATTTTTGCACCTCCTGTAGAGGTGTATGTTTCTCCTTTTTCTATTTCATCCTTCGACAAAGTTCCGCAAGAACTCGTCGATTGGGTTTCAGGTAACGTGGTGTGTTCTGCGCGGCCGATTAGACCCATAGGAATAGTTTTAGAGGGTGATAGTAGAACGGGCAAAACTGCGTGGGCGCGTTCTTTGGGGACACAATTACTTGTGCGGCCACTTGACTTAAGTCCAAAGGTGTACAGTAATGATGCTTGGTACAACGTCATTGATGACGTAGACCCCCACTATCTAAAGCATTTTAAAGAATTCATGGGGGCCCAGAGAGACTGGCAAAGCAACACGAAGTACGGAAAGCCAGTCATGATTAAAGGTGGAATTCCCACCATCTTCCTCTGCAATCCGGGACCAAACAGCAGTTATAAAGAGTATCTCGATGAAGATAAGAATGCAGCACTTAAGCAGTGGGCATTAAAGAATGCAATCTTTATCACACTCGAAGAACCACTCTATTCCGGTCGCGAAAGAATCGCAACCGCAGAGGAAGAAGAAGAACATCAGGCGCAGACGAATTGA |
| Protein Sequence | MAPPKRFRIQAKNYFLTYPKCSLTKEEALSQLQTLETPTSKKFIKICRELHEDGSPHIHVLIQFEGKFVCTNNRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGKFQVDGRSARGGQQSANDTAAKALNSGSAEAALAIIREELPKDFIFQYHNIKNNLDRIFAPPVEVYVSPFSISSFDKVPQELVDWVSGNVVCSARPIRPIGIVLEGDSRTGKTAWARSLGTQLLVRPLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVMIKGGIPTIFLCNPGPNSSYKEYLDEDKNAALKQWALKNAIFITLEEPLYSGRERIATAEEEEEHQAQTN |
| NCBI Accession | YP_006444.1 |
|---|---|
| Location | 484-1290 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGGCCTTTACGACATCTTATACTCCTGCAAGACGATATTCATACTCAACAAATAGACAACCTAACGCAAGCAGGAGATGGAAATTTTGCAGATCTCGGAAATACCATGGATTGATGCGTTATCGGAATTTGTATTCCGCAAGCAAGACCTCAACTGACTTGTTCGGTGATCCTATCTCCAGGCAATACACGCGCAAGGAAATTTGTGAAACTCAACAGGGATCTGAATATGTTCTCCAGAACAATCGCTACATGACTACATATGTTACGTATCCTGCTAAAACCCGAACTGGAACGAATAACAGGGTTCGTTCATACATCAAGCTCACAGGCCTTACCATGTCCGGAACATTTGGCATTCGATGTTCCGAATTAATGACGGATGTGATCAACCCACTGGACTTTATGGCGTTGTATCGATTGTTATCGTCCGGGATAAATCACCAAAGATTTATTCAACTGTACAACCACTCATGCCTTTTGTTGATTTGTTTGGTTCTGTTAGTGCCTGTCGTGGGACTCTTAAGGTGGCAGAACGACAGACACGAGAAGGTTTGTGGTGCTCAATCAAACGTCCATACTGATAAATACGCCTCATTGCAACGCATGAAGAAATTCTCAATTCGAAACTGCATCCCGCGCACCTACTCTACCTGGGCTACGTTCAAGGACGAAGAAGAGGATAGTTCTACTGGGCTATACTCAAACACTCTGCGAAATGCTATACTTATATATTATGTATGGTTAAGCGATGTACCTTCTCAACTGGACATGTACAGCAATGTAATGTTAAATTACATTGGTTAG |
| Protein Sequence | MAFTTSYTPARRYSYSTNRQPNASRRWKFCRSRKYHGLMRYRNLYSASKTSTDLFGDPISRQYTRKEICETQQGSEYVLQNNRYMTTYVTYPAKTRTGTNNRVRSYIKLTGLTMSGTFGIRCSELMTDVINPLDFMALYRLLSSGINHQRFIQLYNHSCLLLICLVLLVPVVGLLRWQNDRHEKVCGAQSNVHTDKYASLQRMKKFSIRNCIPRTYSTWATFKDEEEDSSTGLYSNTLRNAILIYYVWLSDVPSQLDMYSNVMLNYIG |
| NCBI Accession | YP_006445.1 |
|---|---|
| Location | 1344-2189 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGTCAATAAGAAATGATAACATGGGTCTTGGAGTTGGGGGATACATAGAATCCGATCGCGTAGAATACGCTCTCACGAACGACGTTGCGGAGTTCACTCTGACGTTCCCTTCCATGTTCGAACAGAAGATCAGTCAATTGAGAAACAGATGCATGAAAATTGATCACGTCCTTCTTGAATATCGCAGCCAAGTACCAATAAATGCAGTCGGACATGTGGTCATTGAGATTCACGACATGAGATTGACAGAGGGAGACACAAAACAAGCTGAGTTCACGATTCCGATAAGATGCAACTGCAATTTGCATTACTACTCATCCACATACTTCTCCGTTAAGGATAGGAATCCTTGGAGAGTTGAGTACAGAGTTGAGAACACGAACGTAGTGAATGGAGTTCATTTCTGTAAGATGCTCGGTAAATTAAAACTATCCTCGGCCAAACATTCAACTGACGTCGAATTCCGAGCACCAAGAATAGAGATACAGAGCAAAGAATTCACTGTTAACGACATAGATTTCTGGTCTGTTGGCTCAAAACCACAAACAAGACGGCTCGTCGACGGGTCGAGACTCCTGGGTCACAGTTCAAGATCGTTGCGCGTCCCACATTTTGCAATCGGTCCGAACGAATCGTGGGCAAATAGATCGGAAATTGGGCTGGGTTCCGTGACCAGCAGACCGTATAAAAACCTGAGCGGATTGGACGAATCCGCAATAGATCCTGGTCCATCGGCATCACAGATAGGAAGCATCACGAAGGAGGAGATAACTGACATAATAACTAAAACGGTAGAACAATGTATAAAATCGAATGTAAACGCTTCATTAACTAAAGGAGTGTGA |
| Protein Sequence | MSIRNDNMGLGVGGYIESDRVEYALTNDVAEFTLTFPSMFEQKISQLRNRCMKIDHVLLEYRSQVPINAVGHVVIEIHDMRLTEGDTKQAEFTIPIRCNCNLHYYSSTYFSVKDRNPWRVEYRVENTNVVNGVHFCKMLGKLKLSSAKHSTDVEFRAPRIEIQSKEFTVNDIDFWSVGSKPQTRRLVDGSRLLGHSSRSLRVPHFAIGPNESWANRSEIGLGSVTSRPYKNLSGLDESAIDPGPSASQIGSITKEEITDIITKTVEQCIKSNVNASLTKGV |
References More References in PubMed
| 1 |
Emerging squash leaf curl Philippines virus on pumpkin in India: their lineage and recombination. Vignesh S, et al. Physiol Mol Biol Plants. 2025 Jan;31(1):119-129. doi: 10.1007/s12298-024-01542-6. Epub 2024 Dec 20. PMID: 39901954 |
|---|---|
| 2 |
Occurrence and Molecular Characterization of Squash leaf curl Phillipines virus in Taiwan. Tsai WS, et al. Plant Dis. 2007 Jul;91(7):907. doi: 10.1094/PDIS-91-7-0907A. PMID: 30780410 |
| 3 |
First Report of Squash leaf curl Philippines virus Infecting Chayote (Sechium edule) in Taiwan. Tsai WS, et al. Plant Dis. 2011 Sep;95(9):1197. doi: 10.1094/PDIS-04-11-0282. PMID: 30732043 |
| 4 |
Neoh ZY, et al. Plants (Basel). 2023 Jan 6;12(2):272. doi: 10.3390/plants12020272. PMID: 36678986 |
| 5 |
Identification of an emerging cucumber virus in Taiwan using Oxford nanopore sequencing technology. Dong ZX, et al. Plant Methods. 2022 Dec 22;18(1):143. doi: 10.1186/s13007-022-00976-x. PMID: 36550551 |