Soybean mild mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000888375.1 |
| Isolate | Nigeria |
| Release date | 2015/2/22 |
| Submitter | Alabi,O.J., Kumar,P.L., Mgbechi-Ezeri,J.U., Naidu,R.A. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
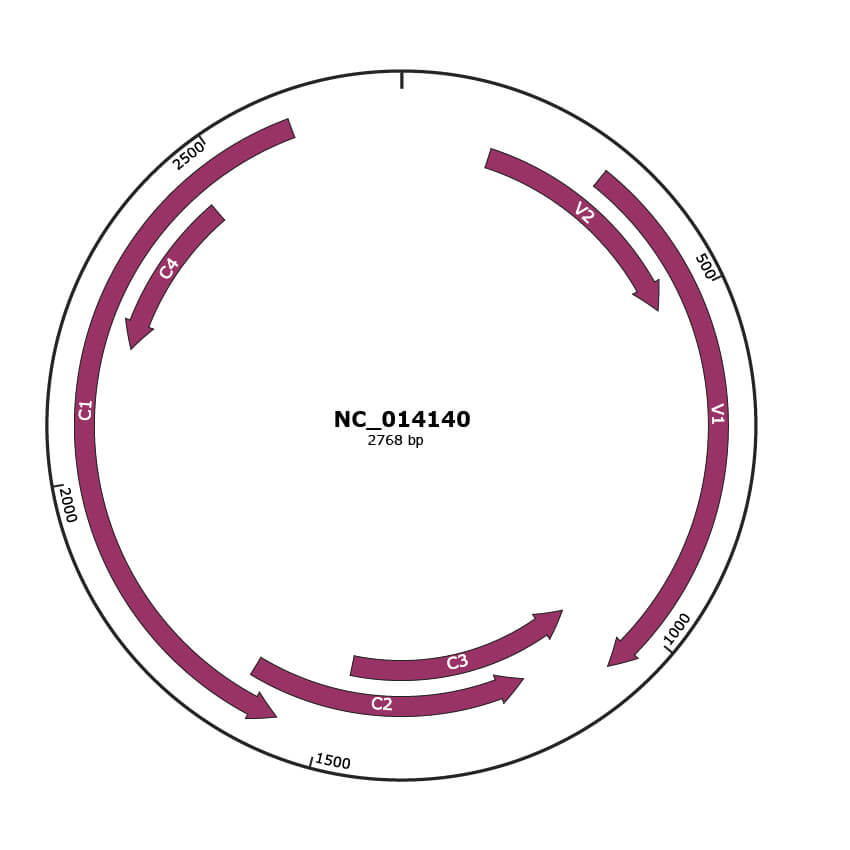
JBrowse
Genome
NC_014140
Gene Information
| NCBI Accession | YP_003622548.1 |
|---|---|
| Location | 139-507 |
| Gene Name | V2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCTCTGCAGAACCCGTTTCCCCATACCGTACACGGTCTTCGATGTATGCTTGCGATAAAGTACGTGCAATTGGTGATTGACACGTACCCCCAAGACAGTATAGGCGAGGATCTATTGCGCCAGATTATTCAGATATTGAGGTGCAGGAACCATGACCAAGCGGAGTTTCGATACAGCATTCTCTTCGCCGATGTCGAACGTACGGAGAAGACTCAGCTTCGCAACCCCTATGGCACTACCTGCACCTGCCGTTTCTGTCCCAAACACGTACAAGCGAAGAGCTTGGAGGAACCGACCCATGTACAGGAAGCCCAGAATTTACAGGATGTATCGTTCGAGAGATGTTCCAAAGGGGTGTGA |
| Protein Sequence | MWDPLQNPFPHTVHGLRCMLAIKYVQLVIDTYPQDSIGEDLLRQIIQILRCRNHDQAEFRYSILFADVERTEKTQLRNPYGTTCTCRFCPKHVQAKSLEEPTHVQEAQNLQDVSFERCSKGV |
| NCBI Accession | YP_003622549.1 |
|---|---|
| Location | 299-1072 |
| Gene Name | V1 |
| Protein Name | coat protein |
| Coding Region | ATGACCAAGCGGAGTTTCGATACAGCATTCTCTTCGCCGATGTCGAACGTACGGAGAAGACTCAGCTTCGCAACCCCTATGGCACTACCTGCACCTGCCGTTTCTGTCCCAAACACGTACAAGCGAAGAGCTTGGAGGAACCGACCCATGTACAGGAAGCCCAGAATTTACAGGATGTATCGTTCGAGAGATGTTCCAAAGGGGTGTGAAGGTCCTTGTAAGGTTCAGTCTTACGATCAGCGGTTCGACTGTAAGCACACGGGCAGTGTGCTGTGTGTTTCAGATATTACTCGCGGAACTGGTCTTACCCATCGTGTTGGTAAGCGTTTCTGCATAAAATCCATGATGTTCAAAGGTAAAGTCTGGATGGACGACAACATCAAGGCTAAGAGCCATACGAATCACGTAATGTTTTTCTTGGTACGTGATAGAAGGCCTTATGGCTCCCCCATGGATTTTGGTCAGGTGTTCAACATGTTTGACAATGAGCCCAGTACTGCTACAGTTAAGCAGGATTATCGAGACCGTTTTCAGGTCATGAGACGATGGTACGTAGGAGTCACCGGTGGTCAGTATGCGTCGAAGGAACAGGCGTTAGTTAATAAGTTTTTTTATTGTAACAATTATGTTGTTTACAATCACCAGGAGGCTGGAAAGTACGAGAACCACACTGAGAACGCATTGTTATTGTATATGGCATGTACTCATGCCTCAAATCCAGTGTATGCAACTCTAAAAATACGGGTCTATTTTTATGACTCAATCAGCAATTAA |
| Protein Sequence | MTKRSFDTAFSSPMSNVRRRLSFATPMALPAPAVSVPNTYKRRAWRNRPMYRKPRIYRMYRSRDVPKGCEGPCKVQSYDQRFDCKHTGSVLCVSDITRGTGLTHRVGKRFCIKSMMFKGKVWMDDNIKAKSHTNHVMFFLVRDRRPYGSPMDFGQVFNMFDNEPSTATVKQDYRDRFQVMRRWYVGVTGGQYASKEQALVNKFFYCNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRVYFYDSISN |
| NCBI Accession | YP_003622550.1 |
|---|---|
| Location | 1069-1473 |
| Gene Name | C3 |
| Protein Name | replication enhancer |
| Coding Region | ATGGATTCTCGCACAGGGGAGTTACTCACACAATCGGAACTAGAGCGTGGCGTGTATATCTGGGAGGTGAACAATCCCCTCTGTTTCAAACTCCTCCGGGAAGACTATGGGGTGATGGGTCTCCCATACGACGAGATGAACATTCGAATAATGTTCAACAACTGTGTCAAGAGGAAGTTGGAGATTCACAAATGCTTCCTGGATTTAAAGATCTTTCTCCACTCACAGAGTCAGAACTGGAGATTTTTTCGAGCTTTCAAGTTTTTAATGATGTCGTTCTTGAATAGTATAGGTTCAATTTCTATTTTAAGTGTCCAGACTGCTATCAACAAAGTATTGCTTGAGCAGTTCGTCATTGTATCCCATTTCGAGATTAAATATGATATAAAATTCAATCTTTATTAA |
| Protein Sequence | MDSRTGELLTQSELERGVYIWEVNNPLCFKLLREDYGVMGLPYDEMNIRIMFNNCVKRKLEIHKCFLDLKIFLHSQSQNWRFFRAFKFLMMSFLNSIGSISILSVQTAINKVLLEQFVIVSHFEIKYDIKFNLY |
| NCBI Accession | YP_003622551.1 |
|---|---|
| Location | 1187-1624 |
| Gene Name | C2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCGATCTTCTACACCCTCGAAGAGCCACTGTTCTCCACCGAACATCAAGGCTCAACATAGGGACGCAAAGCGTCATAGGGCGACTAGACGGCGTCGCATAGACTGTCCTTGTGGGTGTTCTATATACGTTCACCTCGACTGCACAGACCATGGATTCTCGCACAGGGGAGTTACTCACACAATCGGAACTAGAGCGTGGCGTGTATATCTGGGAGGTGAACAATCCCCTCTGTTTCAAACTCCTCCGGGAAGACTATGGGGTGATGGGTCTCCCATACGACGAGATGAACATTCGAATAATGTTCAACAACTGTGTCAAGAGGAAGTTGGAGATTCACAAATGCTTCCTGGATTTAAAGATCTTTCTCCACTCACAGAGTCAGAACTGGAGATTTTTTCGAGCTTTCAAGTTTTTAATGATGTCGTTCTTGAATAG |
| Protein Sequence | MRSSTPSKSHCSPPNIKAQHRDAKRHRATRRRRIDCPCGCSIYVHLDCTDHGFSHRGVTHTIGTRAWRVYLGGEQSPLFQTPPGRLWGDGSPIRRDEHSNNVQQLCQEEVGDSQMLPGFKDLSPLTESELEIFSSFQVFNDVVLE |
| NCBI Accession | YP_003622552.1 |
|---|---|
| Location | 1563-2612 |
| Gene Name | C1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCCCGGAGTGGTTATTTTTGTGTGAAGGCAAAGAACATTTTCCTCACATATCCCAGATGTTCTCTCACAAAAGAAGAAGCACTTTCACAATTGCAGAGCATTCAATGTCCATCTAACAAGAAGTTCATCAAGATAGCTCGTGAACTACACGAGAATGGGGAACCACATCTCCATGTGCTTATCCAGTTTGAAGGAAAGTGTCAAATTACGAACGAAAGACACTTCGACCTCACTTCCCCAAGAAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGTTCGGACGTCAAAACATACATCGACAAAGACGGAGACACCATACAATGGGGGTCTTTCCAGATTGATGGTCGAAGTGCCAGAGGAGGTTGCAAAAATGCTAACGACGCATGTGCGTCGGCATTAAATGCTGGTTCCGCTGAAGCTGCTTTACAGATCATCAAAGAGCAGCTTCCACGAGATTATGTTTTTCAGTATCATAATGTTATTAGCAACCTCAATAAGATTTTTACGCCTCCAACGACGATTTACAAATCGCCTTTTAAAGTTGAACAATTTAACAATGTGCCGGAAGTTCTGTCTCAATGGGCATCAGATAATGTGAAAGCTTCCGCTGCGCGGCCGATGAGACCCATAAGCATCGTCCTGGAAGGTGAATCCAGGACGGGGAAGACGATGTGGGCCAGAAGCCTTGGTAGGCACAATTACCTATGTGGTCATTTAGATCTCAGCGCCAAGGTCTATTCAAACGATGCCTGGTACAACGTCATCGATGACGTAGATCCCCACTATCTAAAGCATATGAAAGAATTCATGGGGTCCCAAAGAGACTGGCAAAGCAACGTGAAGTACGGCAAGCCCACTCAAATTAAAGGTGGAATACCAACAATTTTCCTCTGCAATCCTGGCCCCAGATCTTCCTATAAAGAATATATGGATGAGGAGTCGAATGCAGCGCTTAAGGAGTGGGCTTTAAAAAATGCGATCTTCTACACCCTCGAAGAGCCACTGTTCTCCACCGAACATCAAGGCTCAACATAG |
| Protein Sequence | MPRSGYFCVKAKNIFLTYPRCSLTKEEALSQLQSIQCPSNKKFIKIARELHENGEPHLHVLIQFEGKCQITNERHFDLTSPRRSTHFHPNIQGAKSSSDVKTYIDKDGDTIQWGSFQIDGRSARGGCKNANDACASALNAGSAEAALQIIKEQLPRDYVFQYHNVISNLNKIFTPPTTIYKSPFKVEQFNNVPEVLSQWASDNVKASAARPMRPISIVLEGESRTGKTMWARSLGRHNYLCGHLDLSAKVYSNDAWYNVIDDVDPHYLKHMKEFMGSQRDWQSNVKYGKPTQIKGGIPTIFLCNPGPRSSYKEYMDEESNAALKEWALKNAIFYTLEEPLFSTEHQGST |
| NCBI Accession | YP_003622553.1 |
|---|---|
| Location | 2198-2455 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGGAACCACATCTCCATGTGCTTATCCAGTTTGAAGGAAAGTGTCAAATTACGAACGAAAGACACTTCGACCTCACTTCCCCAAGAAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGTTCGGACGTCAAAACATACATCGACAAAGACGGAGACACCATACAATGGGGGTCTTTCCAGATTGATGGTCGAAGTGCCAGAGGAGGTTGCAAAAATGCTAACGACGCATGTGCGTCGGCATTAA |
| Protein Sequence | MGNHISMCLSSLKESVKLRTKDTSTSLPQEGQHISIRTFRELNQVRTSKHTSTKTETPYNGGLSRLMVEVPEEVAKMLTTHVRRH |
References More References in PubMed
| 1 |
Effects of cowpea mild mottle virus on soybean cultivars in Brazil. Barreto da Silva F, et al. PeerJ. 2020 Aug 31;8:e9828. doi: 10.7717/peerj.9828. eCollection 2020. PMID: 32944424 |
|---|---|
| 2 |
Barreto da Silva F, et al. Insects. 2024 Aug 19;15(8):624. doi: 10.3390/insects15080624. PMID: 39194828 |
| 3 |
Zanardo LG, et al. Virus Res. 2021 Oct 2;303:198389. doi: 10.1016/j.virusres.2021.198389. Epub 2021 Mar 11. PMID: 33716182 |
| 4 |
Wei Z, et al. Front Microbiol. 2021 Apr 8;12:650773. doi: 10.3389/fmicb.2021.650773. eCollection 2021. PMID: 33897664 |
| 5 |
Molecular variability of cowpea mild mottle virus infecting soybean in Brazil. Zanardo LG, et al. Arch Virol. 2014 Apr;159(4):727-37. doi: 10.1007/s00705-013-1879-0. Epub 2013 Oct 19. PMID: 24142270 |
| 6 |
Yang S, et al. Pathogens. 2022 Mar 30;11(4):419. doi: 10.3390/pathogens11040419. PMID: 35456094 |
| 7 |
Jiang C, et al. Front Microbiol. 2022 Apr 15;13:860695. doi: 10.3389/fmicb.2022.860695. eCollection 2022. PMID: 35495691 |
| 8 |
Srikant M, et al. Virusdisease. 2025 Mar;36(1):41-47. doi: 10.1007/s13337-024-00905-7. Epub 2025 Jan 23. PMID: 40290768 |
| 9 |
Construction of a full-length infectious cDNA clone of Cowpea mild mottle virus. Carvalho SL, et al. Virus Genes. 2017 Feb;53(1):137-140. doi: 10.1007/s11262-016-1395-x. Epub 2016 Oct 11. PMID: 27730428 |
| 10 |
Sandra N, et al. 3 Biotech. 2025 Jun;15(6):174. doi: 10.1007/s13205-025-04347-w. Epub 2025 May 16. PMID: 40386632 |