Soybean chlorotic blotch virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000889935.1 |
| Isolate | Nigeria |
| Release date | 2015/2/22 |
| Submitter | Alabi,O.J., Kumar,P.L., Mgbechi-Ezeri,J.U., Naidu,R.A. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
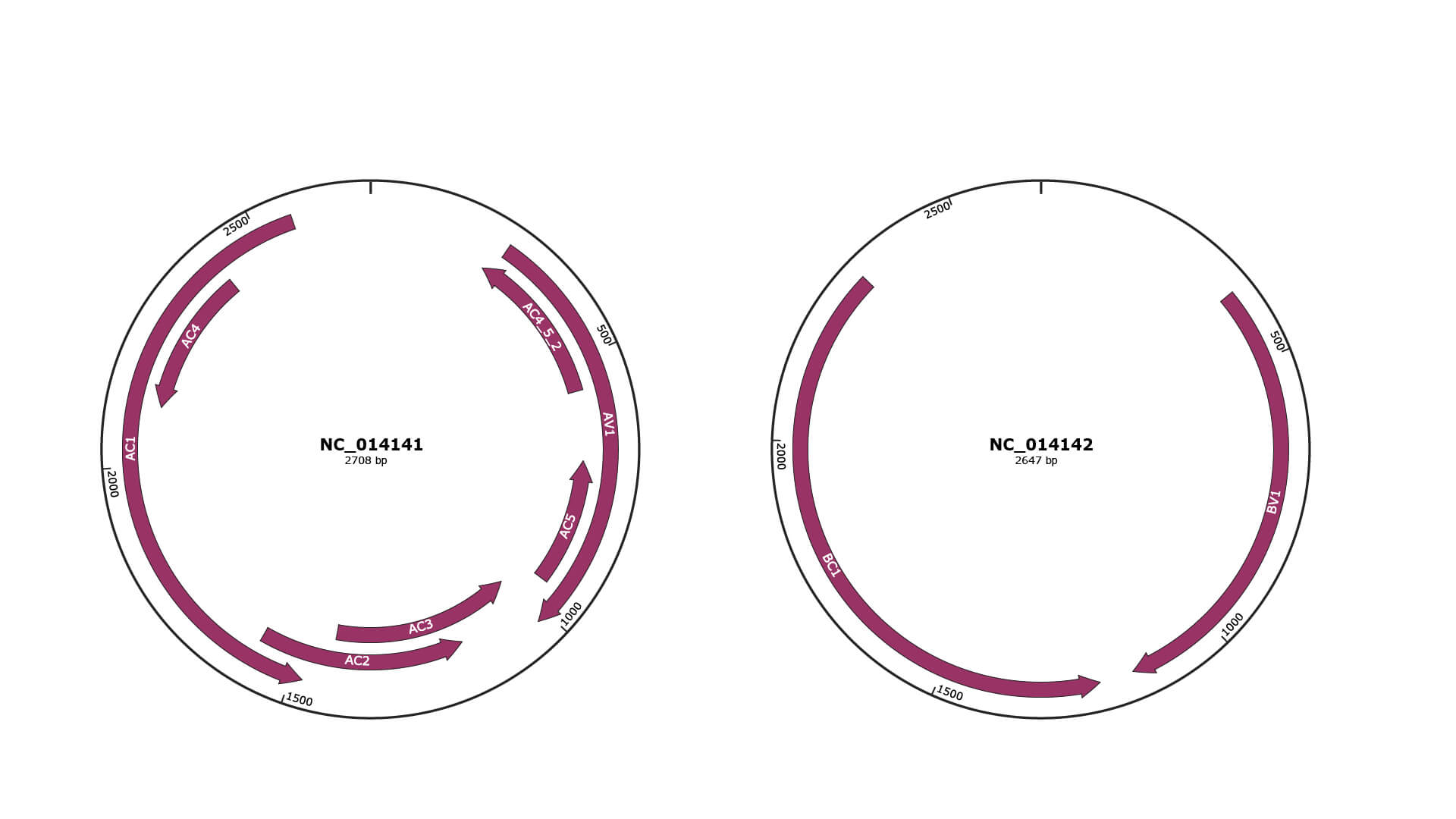
JBrowse
Genome
NC_014141
NC_014142
Gene Information
| NCBI Accession | YP_003622554.1 |
|---|---|
| Location | 239-559 |
| Gene Name | AC4_5_2 |
| Protein Name | hypothetical protein |
| Coding Region | ATGTGTCAATCCGGACCCACGAGTAATATCGGAACAGCAGAGAACTGTACCCGTGTGACTAACGTCATGCTTGGCGTCATACGACTGGACCTTACAAGGCCCTTCACAGCCGAAGGGCACATCTGGACTCCTCCACATCCTGTACATCATGGGCTTCCGATACATGGGCCGATTCTCCCAGGCCCTCTTCTTGTTGGTCCTGGGGATGGCAGTGGGCATGGCACGTGGACTGTCGAAGTTCAACCTCCTCCGAACCTTCGACAAAGGTGTAGAAATTACGATATCGGCGTTTCGCTTCATGATATTTCCTTCCGTGAATAA |
| Protein Sequence | MCQSGPTSNIGTAENCTRVTNVMLGVIRLDLTRPFTAEGHIWTPPHPVHHGLPIHGPILPGPLLVGPGDGSGHGTWTVEVQPPPNLRQRCRNYDIGVSLHDISFRE |
| NCBI Accession | YP_003622555.1 |
|---|---|
| Location | 260-1021 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGAAGCGAAACGCCGATATCGTAATTTCTACACCTTTGTCGAAGGTTCGGAGGAGGTTGAACTTCGACAGTCCACGTGCCATGCCCACTGCCATCCCCAGGACCAACAAGAAGAGGGCCTGGGAGAATCGGCCCATGTATCGGAAGCCCATGATGTACAGGATGTGGAGGAGTCCAGATGTGCCCTTCGGCTGTGAAGGGCCTTGTAAGGTCCAGTCGTATGACGCCAAGCATGACGTTAGTCACACGGGTACAGTTCTCTGCTGTTCCGATATTACTCGTGGGTCCGGATTGACACATCGTGTCGGCAAAAGGTTTACCATCAAGTCCATTCTTTTGATGGGCAAGATTTGGATGGACGACAATATCAAATTAAAGAACCACACTAATATCGTCACCTTTTTTTTAGTGCGCGATAGGCGCCCATCTGACAAGCCATATTCATTTGGCAGTGTGTTCAACATGTTCGACAATGAACCCACGACAGCGACAGTTAAACAAGATAACCGCGATCGATCCCAAGTTATTCGTAAGTTTCATGCCACAGTTACTGGTGGCCAATATGCTTCTAAGGAGCAGGCATTGGTGAAGAAATTTTTTAAAATTAATCACAAGGTCGTCTACAACAATCAGGAAGGTGCGGAGTACAAGAACCACCAGGAGAATGCTTTGCTTCTCTATATGGCATGTAGTCATGCTTCTAACCCAGTGTATGCTACTATTAAGGCTCGTGTGTATTTTTATGATTCAGTCACAAATTAA |
| Protein Sequence | MKRNADIVISTPLSKVRRRLNFDSPRAMPTAIPRTNKKRAWENRPMYRKPMMYRMWRSPDVPFGCEGPCKVQSYDAKHDVSHTGTVLCCSDITRGSGLTHRVGKRFTIKSILLMGKIWMDDNIKLKNHTNIVTFFLVRDRRPSDKPYSFGSVFNMFDNEPTTATVKQDNRDRSQVIRKFHATVTGGQYASKEQALVKKFFKINHKVVYNNQEGAEYKNHQENALLLYMACSHASNPVYATIKARVYFYDSVTN |
| NCBI Accession | YP_003622556.1 |
|---|---|
| Location | 701-955 |
| Gene Name | AC5 |
| Protein Name | hypothetical protein |
| Coding Region | ATGACTACATGCCATATAGAGAAGCAAAGCATTCTCCTGGTGGTTCTTGTACTCCGCACCTTCCTGATTGTTGTAGACGACCTTGTGATTAATTTTAAAAAATTTCTTCACCAATGCCTGCTCCTTAGAAGCATATTGGCCACCAGTAACTGTGGCATGAAACTTACGAATAACTTGGGATCGATCGCGGTTATCTTGTTTAACTGTCGCTGTCGTGGGTTCATTGTCGAACATGTTGAACACACTGCCAAATGA |
| Protein Sequence | MTTCHIEKQSILLVVLVLRTFLIVVDDLVINFKKFLHQCLLLRSILATSNCGMKLTNNLGSIAVILFNCRCRGFIVEHVEHTAK |
| NCBI Accession | YP_003622557.1 |
|---|---|
| Location | 1018-1431 |
| Gene Name | AC3 |
| Protein Name | replication enhancer |
| Coding Region | ATGGATTTACGCACAGGGGAATCCATCACTGCAGTTCAAGCCGGGAATGGCGTCTATATCTGGGCGGTCCCAAATCCTCTGCACTTCAAAGTGATCGAGCATCACATGAATATTCCGGGGTTGCCATACAACATAATCAAGCTTCGAGTGCAGTTCAACCACAACCTCCGGAGAGCATTAGGACTCCACAAGTGCTGGATAACCTTGACGATATTAACGCGATTGACCCGCTCTACCAATCCGACTGGGATTTTCTTGAGGGTCTTTAAGACTCAAGTGTTGCGTTATTTAGATTCAATTCATGTAATTTCGATTAATGGAGTTATAAGAGCCATTAATCATTGTTTGTACGATGTACTTGTTGGCACTGAAGAAGTGCGTACCAAATATGAAATAAAATTCAATCTTTATTAA |
| Protein Sequence | MDLRTGESITAVQAGNGVYIWAVPNPLHFKVIEHHMNIPGLPYNIIKLRVQFNHNLRRALGLHKCWITLTILTRLTRSTNPTGIFLRVFKTQVLRYLDSIHVISINGVIRAINHCLYDVLVGTEEVRTKYEIKFNLY |
| NCBI Accession | YP_003622558.1 |
|---|---|
| Location | 1163-1579 |
| Gene Name | AC2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCGATCTTCGTCAGCATCGCCTTCCCACTCTACAGCAGTCCCGATCAAGGTAAGACATCGCCAGGCGAAGAAGAGGCAAATCCGACGCCGCCGTGTTGATCTACGCTGTGGCTGTTCCTATTTCGTCTCAATTAATTGCGCAAACCATGGATTTACGCACAGGGGAATCCATCACTGCAGTTCAAGCCGGGAATGGCGTCTATATCTGGGCGGTCCCAAATCCTCTGCACTTCAAAGTGATCGAGCATCACATGAATATTCCGGGGTTGCCATACAACATAATCAAGCTTCGAGTGCAGTTCAACCACAACCTCCGGAGAGCATTAGGACTCCACAAGTGCTGGATAACCTTGACGATATTAACGCGATTGACCCGCTCTACCAATCCGACTGGGATTTTCTTGAGGGTCTTTAA |
| Protein Sequence | MRSSSASPSHSTAVPIKVRHRQAKKRQIRRRRVDLRCGCSYFVSINCANHGFTHRGIHHCSSSREWRLYLGGPKSSALQSDRASHEYSGVAIQHNQASSAVQPQPPESIRTPQVLDNLDDINAIDPLYQSDWDFLEGL |
| NCBI Accession | YP_003622559.1 |
|---|---|
| Location | 1479-2567 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCTAGAAGCGGAGCTTTTAGAGTGAATGCGAAGAATATCTTCCTCACATATCCCAGATGCTCATTATCAAAAGACGAAGCTCTGGAATTACTCAAGGGTATACCAACACCTGTGAACAAGAAGTTCATCAAGGTAGCTAGAGAGCTACACGAAGATGGGCAGCCACATCTCCATGTGCTGCTGCAATTCGAAGGTAAATTCTCCATCAAAAATCCTCGACTGTTCGACCTTGTCTCGAGAGCGTCTGCTCATGTGTTCCACCCAAACGTACAAGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGACGGCGACACCGTGTCATGGGGAGAGTTTCAGATCGATGGAAGATCGAGTCGTGGAGGTAAGCAATCTGCGAACGACGCTTACGCCGCAGCAATTAACACGGGCAGTCCGACTAAGGCTCTCCAGTTATTAAAGGAACCATGTCCAAAGGATTATGTATTACAGTTCCACCACCTTAAAGGTAATTTAGAAAGGATTTTCATGAAGGAGCCAACACCATGGGCTTGTCCTTATGATCCCCGTTCATTTAACAACGTCCCGGACGTTATGCTTGATTGGGTGTCTGTTAATGTGAAAGATCCCGCTGCGCGGCCTAACAGACCCATGAGTATCGTCGTTGAAGGTGATTCCAGAACGGGGAAGACGATGTGGGCGCGGTCTTTGGGGGTACACAATTACCTATGTGGTCATCTAGACCTGAGTCCAAAGGTGTACAGCAATAATGCATGGTACAACGTCATCGATGACGTAGATCCGCACTACCTAAAGCACTTCAAGGAATTCATGGGGGCCCAGCATGATTGGCAGAGCAACACGAAATACGGTAAACCGATTCAAATTAAAGGGGGAATTCCCACCATCTTTTTATGCAACCCGGGACACAGTAGCTCTTATAAGAGTTATTTGGATGAAGAGAAAAATTCATCCCTGAAACAGTGGGCATTAAAGAATGCGATCTTCGTCAGCATCGCCTTCCCACTCTACAGCAGTCCCGATCAAGGTAAGACATCGCCAGGCGAAGAAGAGGCAAATCCGACGCCGCCGTGTTGA |
| Protein Sequence | MPRSGAFRVNAKNIFLTYPRCSLSKDEALELLKGIPTPVNKKFIKVARELHEDGQPHLHVLLQFEGKFSIKNPRLFDLVSRASAHVFHPNVQGAKSSSDVKSYIDKDGDTVSWGEFQIDGRSSRGGKQSANDAYAAAINTGSPTKALQLLKEPCPKDYVLQFHHLKGNLERIFMKEPTPWACPYDPRSFNNVPDVMLDWVSVNVKDPAARPNRPMSIVVEGDSRTGKTMWARSLGVHNYLCGHLDLSPKVYSNNAWYNVIDDVDPHYLKHFKEFMGAQHDWQSNTKYGKPIQIKGGIPTIFLCNPGHSSSYKSYLDEEKNSSLKQWALKNAIFVSIAFPLYSSPDQGKTSPGEEEANPTPPC |
| NCBI Accession | YP_003622560.1 |
|---|---|
| Location | 2117-2410 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGCAGCCACATCTCCATGTGCTGCTGCAATTCGAAGGTAAATTCTCCATCAAAAATCCTCGACTGTTCGACCTTGTCTCGAGAGCGTCTGCTCATGTGTTCCACCCAAACGTACAAGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGACGGCGACACCGTGTCATGGGGAGAGTTTCAGATCGATGGAAGATCGAGTCGTGGAGGTAAGCAATCTGCGAACGACGCTTACGCCGCAGCAATTAACACGGGCAGTCCGACTAAGGCTCTCCAGTTATTAA |
| Protein Sequence | MGSHISMCCCNSKVNSPSKILDCSTLSRERLLMCSTQTYKELNPAPTSSPTSTKTATPCHGESFRSMEDRVVEVSNLRTTLTPQQLTRAVRLRLSSY |
| NCBI Accession | YP_003622561.1 |
|---|---|
| Location | 373-1158 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATACCCGCCATGGAAGACGTCTTTTACGGTCTTCCCCTTATTCACATTTGACGCCTTCAAGTTCATCAAGGCGTCATCAAGAATCGAAGTTCCGTCATGTTACTCGTAACCTAAATGTCTATAGACCATTATTCTCATCGTCTGACAGAGGTGTTTTTAAACGTCGTACATTGGGAGAGGTTCAACACGGTCCGGAGCTAGTGTTGAGAAATGCAACCCATGTGACAACCTATGTGACGTATCCGACTCGATACAGTAATGGTGATGGACGCTGCACTGATTACATCAAGATTTTGAATCTGAAAGTATCCGGACGCATCTGCATACGTGACAATGTTCCCACAGGTGACAAAACAATGGGCGTTTATTCGGGTATATTGGGCACATTCGTCATGTGTTTCATACGTGACAAACGACCGGACGTTCCGGACGGGGCAAATGCTCTGCCTTCATTTAAGGACCTCTTCGGGAACTACGAAGCAGCCTATGCCGATTTACGTATAGTGGATGTTTTACGAGAGCGATTTCGACTTATGTCTTCCATTAAAATTGACGTAACGTCAGATTTAGGTGAATGTCAAAGAACTCTCAAGCATTACTTGCCTGTAAGCTCTCGTAAATTCCCTATTTGGGCAACATTTCGGGACAAGGATCTCTCTATGGCCACTGGAAATTACAAGAACATTCCGAAGAACGCGACGTTAATAAGTTACGCTTGGGTGTCCGAGCGTGACAGCACATGTCAAATATATTCCCAAATGTTGCTTAGTTATTTAGGATAA |
| Protein Sequence | MYTRHGRRLLRSSPYSHLTPSSSSRRHQESKFRHVTRNLNVYRPLFSSSDRGVFKRRTLGEVQHGPELVLRNATHVTTYVTYPTRYSNGDGRCTDYIKILNLKVSGRICIRDNVPTGDKTMGVYSGILGTFVMCFIRDKRPDVPDGANALPSFKDLFGNYEAAYADLRIVDVLRERFRLMSSIKIDVTSDLGECQRTLKHYLPVSSRKFPIWATFRDKDLSMATGNYKNIPKNATLISYAWVSERDSTCQIYSQMLLSYLG |
| NCBI Accession | YP_003622562.1 |
|---|---|
| Location | 1219-2310 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGTTGAGATCGTTAATGTTAATTGAAAACTTTAAATGTTTTCATGTTGGTTCTTTGAACTTTTGTGAAGGTATATGTCTTTCTTCTCAGAAATTACTGTCTGATTTGTTCTGTTATTTGTTTCACATTTGGGTTCTGCTGAACTTCAGGGAAAATCGTGGCGCTGCGCGGCCAGATTTCGGAATGGAAGACTTCTCAGTCGTGTCGAACAAATACATTGAGTCACGCAGAAACGAGTATGCCCTTACCAATGATGCGACAACGATCAAACTAGAGTTTCCAACAACTCTAGAACAGGCGACTGTTCGTCTTAAGGGCAAGTGCATGAAAATAGATCACATAGTGATCGAGTATCGTAATCAGGTTCCGTTTAACGCCACAGGCTCGGTAGTCGTAGAAATAAGAGACCACAGACTACGACAAGATGAATGTGCCCAAGCACGGTTTTCATTCCCGATTACATGTAACGTGAACCTGCACTACTATTCTTCCTCGTTCTTCTCCCTGAAAGACAAGTCACCATGGGAATTGGTCTATATGGTAGAGGACTCGAATGTCAATGAAGGAACAATGTTTGCCATGATAAAGGCCAAGTTGAAACTGTCATCAGCTAAACACTCGACGGACATTCGATTCAAACCGCCCAACATACACATATTGTCTAAGGGCTTTAACAGCTCATGCGTCGATTTTTGGACAGTTAATCGACCCAAGTTAGAACGCAGATTGTTGGACCAAGGACCCAATTCCTCAAATGCTAACGAGCCCATGCTTGGAAGAATAGAGTTGTTACCAGGAGAGACATGGGCCTCACGAAGTACAATAAGCGCCCCAATGCAAAAGTCCGCTTCTATGCGGATAACAAGGCCCATTAACCTAATGGGCAACGACATTTCAGAAGAGGCCCATTCCGACGCGGACCACCCATACAGGACTCTAAACAGGTTGCCCACAACCGCACTAGAGCCGGGAGACTCGGTTTCCCAAGTCCAGAGTGACAACGTCTCAAGGAAAGAGTTAGAGTCCATTATAGAAGCGACGATTAATAAGTGTTTAATTAAGGAACGACCACAGGCGTTAAAAGAGTTGTAA |
| Protein Sequence | MLRSLMLIENFKCFHVGSLNFCEGICLSSQKLLSDLFCYLFHIWVLLNFRENRGAARPDFGMEDFSVVSNKYIESRRNEYALTNDATTIKLEFPTTLEQATVRLKGKCMKIDHIVIEYRNQVPFNATGSVVVEIRDHRLRQDECAQARFSFPITCNVNLHYYSSSFFSLKDKSPWELVYMVEDSNVNEGTMFAMIKAKLKLSSAKHSTDIRFKPPNIHILSKGFNSSCVDFWTVNRPKLERRLLDQGPNSSNANEPMLGRIELLPGETWASRSTISAPMQKSASMRITRPINLMGNDISEEAHSDADHPYRTLNRLPTTALEPGDSVSQVQSDNVSRKELESIIEATINKCLIKERPQALKEL |
References More References in PubMed
| 1 |
Leke WN, et al. Arch Virol. 2016 Aug;161(8):2347-50. doi: 10.1007/s00705-016-2915-7. Epub 2016 Jun 4. PMID: 27262944 |
|---|---|
| 2 |
Srikant M, et al. Virusdisease. 2025 Mar;36(1):41-47. doi: 10.1007/s13337-024-00905-7. Epub 2025 Jan 23. PMID: 40290768 |
| 3 |
Sandra N, et al. 3 Biotech. 2021 Aug;11(8):381. doi: 10.1007/s13205-021-02925-2. Epub 2021 Jul 25. PMID: 34458057 |
| 4 |
Aboughanem-Sabanadzovic N, et al. Viruses. 2023 Oct 25;15(11):2145. doi: 10.3390/v15112145. PMID: 38005823 |
| 5 |
Two new 'legumoviruses' (genus Begomovirus) naturally infecting soybean in Nigeria. Alabi OJ, et al. Arch Virol. 2010 May;155(5):643-56. doi: 10.1007/s00705-010-0630-3. Epub 2010 Mar 13. PMID: 20229118 |
| 6 |
Leke WN, et al. Arch Virol. 2016 Aug;161(8):2329-33. doi: 10.1007/s00705-016-2894-8. Epub 2016 May 25. PMID: 27224982 |
| 7 |
Yoboué AAN, et al. Front Plant Sci. 2025 Feb 26;16:1448189. doi: 10.3389/fpls.2025.1448189. eCollection 2025. PMID: 40078636 |