South African cassava mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000838365.1 |
| Release date | 2015/2/12 |
| Submitter | Berrie,L.C., Rybicki,E.P., Rey,M.E., Rey,M.E.C. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
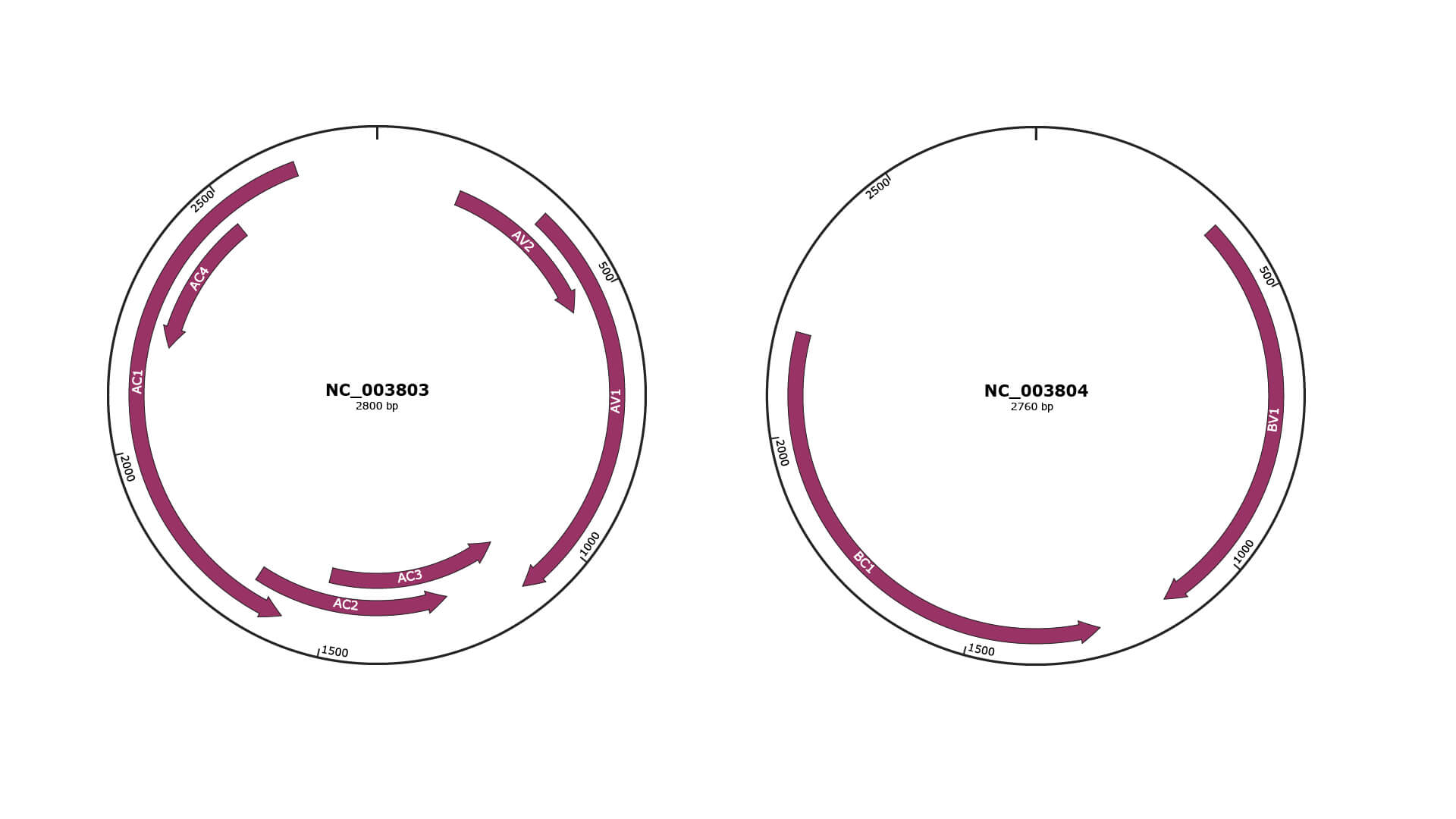
JBrowse
Genome
NC_003803
NC_003804
Gene Information
| NCBI Accession | NP_620661.1 |
|---|---|
| Location | 174-524 |
| Gene Name | AV2 |
| Protein Name | AV2 |
| Coding Region | ATGTGGGATCCATTGTTGAATGAGTTCCCCGAGTCTGTGCACGGTTTTCGCTGTATGCTTGCTATTAAATATTTGCAGGCCTTGGAGGAAACCTACGAGCCCAATACTTTGGGCCACGATCTAGTCCGTGATCTCATCGGTGTGATCCGAGCCCGTGATTATGTCGAAGCGTCCCGCCGATATAATCATTTCCACTCCCGTCTCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCGTTCAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGTCGATCATGGACGTTCCGGCCCATGTACCGAAAGCCCAGAATGTACAGAATGTTCAAAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPESVHGFRCMLAIKYLQALEETYEPNTLGHDLVRDLIGVIRARDYVEASRRYNHFHSRLEGASKAELRQPVQQPCCCPHCPRHKQASIMDVPAHVPKAQNVQNVQKP |
| NCBI Accession | NP_620662.1 |
|---|---|
| Location | 334-1110 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGTCCCGCCGATATAATCATTTCCACTCCCGTCTCGAAGGTGCGTCGAAGGCTGAACTTCGACAGCCCGTTCAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCACAAACAAGCGTCGATCATGGACGTTCCGGCCCATGTACCGAAAGCCCAGAATGTACAGAATGTTCAAAAGCCCTGATGTTCCGCGTGGCTGTGAAGGCCCATGTAAGGTTCAATCTTATGAACAGCGAGATGACGTTAAGCATACTGGCAGTGTTCGTTGTGTTAGTGATGTCACGCGTGGTTCGGGAATTACACATAGAGTAGGTAAAAGGTTCTGTATCAAGTCTATATATGTGTTAGGTAAGATATGGATGGATGAAAACATCAAGAAGCAGAACCATACAAACCAGGTCATGTTCTTCTTAGTCCGTGACAGAAGGCCCTATGGCAATAGCCCCATGGACTTTGGACAGGTTTTTAATATGTTTGATAATGAGCCCAGTACAGCCACTGTGAAGAACGATCTTAGGGATAGGTATCGAGTTATGCGGAAGTTTCATGCCACCGTTGTTGGGGGTCCTTCTGGAATGAAGGAGCAGGCTTTGGTGAGGAGATTTTTTAGGATAAATAATCATGTTGTGTATAATCACCAGGAGGCAGCTAAGTATGAGAATCATACAGAGAATGCGTTATTGTTGTATATGGCATGTACGCATGCCTCTAATCCAGTGTATGCTACGCTTAAAATACGCATCTATTTTTATGATGCAGTAACAAATTAA |
| Protein Sequence | MSKRPADIIISTPVSKVRRRLNFDSPFSSRAAVPIVQGTNKRRSWTFRPMYRKPRMYRMFKSPDVPRGCEGPCKVQSYEQRDDVKHTGSVRCVSDVTRGSGITHRVGKRFCIKSIYVLGKIWMDENIKKQNHTNQVMFFLVRDRRPYGNSPMDFGQVFNMFDNEPSTATVKNDLRDRYRVMRKFHATVVGGPSGMKEQALVRRFFRINNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
| NCBI Accession | NP_620663.1 |
|---|---|
| Location | 1107-1511 |
| Gene Name | AC3 |
| Protein Name | AC3 |
| Coding Region | ATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAAGAATGGCGTTTTTACCTGGGAAATAACAAATCCCCTCTATTTCGACATCACCAACCACGACAAGCGGCCAGGGAACATGAACCACGACATCATCACCCTCCAGATACGGTTCAACCACAACATCAGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCCGACTGGTCTTTTCTTAAGAGTATTTAAATATCAAGTGCTCAAGTATTTAAATATGATAGGCGTTATTTCCATTAACACTGTACTCAGAGCTGTTGATCATGTTCTGTACGATGTATTACTAAACACACTCCAAGTTACGGAGCAACATGCAATAAAATTCAACCTTTATTAA |
| Protein Sequence | MDSRTGELITAPQAKNGVFTWEITNPLYFDITNHDKRPGNMNHDIITLQIRFNHNIRKALGIHKCFLNFKVWTTLRPPTGLFLRVFKYQVLKYLNMIGVISINTVLRAVDHVLYDVLLNTLQVTEQHAIKFNLY |
| NCBI Accession | NP_620664.1 |
|---|---|
| Location | 1252-1659 |
| Gene Name | AC2 |
| Protein Name | AC2 |
| Coding Region | ATGCAACCTTCATCACCCTCCACGAGCCATTGTTCTCAAGTGCCCATCAAAGTCCAACACCGCACCGCGAAGACTAGGGCCCTCAGACGTAGGAGGGTAGACCTCGAATGCGGCTGCTCGTTCTATCTCCATATCGACTGCATCAACCATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAAGAATGGCGTTTTTACCTGGGAAATAACAAATCCCCTCTATTTCGACATCACCAACCACGACAAGCGGCCAGGGAACATGAACCACGACATCATCACCCTCCAGATACGGTTCAACCACAACATCAGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCCGACTGGTCTTTTCTTAAGAGTATTTAA |
| Protein Sequence | MQPSSPSTSHCSQVPIKVQHRTAKTRALRRRRVDLECGCSFYLHIDCINHGFSHRGTHHCASSKEWRFYLGNNKSPLFRHHQPRQAAREHEPRHHHPPDTVQPQHQEGIGDSQVFSQLQGLDDLTASDWSFLKSI |
| NCBI Accession | NP_620665.1 |
|---|---|
| Location | 1583-2647 |
| Gene Name | AC1 |
| Protein Name | replicase |
| Coding Region | ATGCCGAGGGCTGGTCGTTTTAGCATAAAAGCCAAAAATTATTTCCTCACGTATCCGAAATGCACTCTCTCGAAAGAAGCGGCATTAGATCAACTCCGACAACTCCAAACCCCAACAAATAAATTGTTCATCAAGATCTGCAGAGAACTCCATGAAAATGGGGAACCTCATTTGCATGCCCTCATTCAGTTCGAGGGCAAGTACAATTGTACCAACCAACGATTCTTCGACCTCATATCCCCTTCCAGGTCAACACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGTTCTGACGTCAAGTCCTATTTGGACAAGGACGGAGACACCATCCAATGGGGCGAGTTTCAGATCGACGGACGATCTGCTCGCGGCGGACAACAATCCGCCAATGACGCTTACGCCAAGGCTCTTAACGCAGCAAGTAAAACAGAGGCTCTTAATGTAATCCGGGAACTAGCCCCAAAGGATTTTGTTTTACAGTTTCATAATTTAAATAGCAATTTAGATAGGATTTTTCAGGAGCCTCCGATTCCTTATATTTCTCCCTTTCTTTCTTCTTCTTTCACTCATGTTCCTGAGGAACTTGAAGACTGGGTTTCCGAGAACGTGATGGGTTTCGCTGCGCGGCCATGGAGACCGAGTAGTATCGTCATCGAGGGCGATAGTAGGACAGGGAAGACGATGTGGGCCCGATCTCTGGGACCACACAACTACTTATGTGGACATTTGGATCTCAGTCCAAAGGTTTACAGCAACGACGCATGGTACAACGTCATTGATGACGTCGACCCCCATTACCTCAAGCACTTCAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAATACCAAGTACGGGAAGCCGATTCAAATTAAAGGCGGCATTCCCACTATCTTCCTATGCAATCCAGGACCGACATCATCATATAAAGAGTTTCTGGACGAGGAAAAGAACCAGTCCCTTAAAGCCTGGGCTTTAAAGAATGCAACCTTCATCACCCTCCACGAGCCATTGTTCTCAAGTGCCCATCAAAGTCCAACACCGCACCGCGAAGACTAG |
| Protein Sequence | MPRAGRFSIKAKNYFLTYPKCTLSKEAALDQLRQLQTPTNKLFIKICRELHENGEPHLHALIQFEGKYNCTNQRFFDLISPSRSTHFHPNIQGAKSSSDVKSYLDKDGDTIQWGEFQIDGRSARGGQQSANDAYAKALNAASKTEALNVIRELAPKDFVLQFHNLNSNLDRIFQEPPIPYISPFLSSSFTHVPEELEDWVSENVMGFAARPWRPSSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEEKNQSLKAWALKNATFITLHEPLFSSAHQSPTPHRED |
| NCBI Accession | NP_620666.1 |
|---|---|
| Location | 2200-2496 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGAAAATGGGGAACCTCATTTGCATGCCCTCATTCAGTTCGAGGGCAAGTACAATTGTACCAACCAACGATTCTTCGACCTCATATCCCCTTCCAGGTCAACACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGTTCTGACGTCAAGTCCTATTTGGACAAGGACGGAGACACCATCCAATGGGGCGAGTTTCAGATCGACGGACGATCTGCTCGCGGCGGACAACAATCCGCCAATGACGCTTACGCCAAGGCTCTTAACGCAGCAAGTAAAACAGAGGCTCTTAATGTAA |
| Protein Sequence | MKMGNLICMPSFSSRASTIVPTNDSSTSYPLPGQHISIQTFRELNPVLTSSPIWTRTETPSNGASFRSTDDLLAADNNPPMTLTPRLLTQQVKQRLLM |
| NCBI Accession | NP_620667.1 |
|---|---|
| Location | 357-1133 |
| Gene Name | BV1 |
| Protein Name | BV1 |
| Coding Region | ATGTATTCAGTTTACAGACGTGGGTATAAGACTCCGTATAGGAGTCCGTATGGCGCTCGTGTAACACCATATGTATATCGTAAGACCTCTGGTAAACAGACGTCTAAATCTCGTGTACCGCGAAAGTTGGTGTATGAATCGCCAAAAGGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTGAAGTTGTCTCAACAGGGGGATTATACGTCCTACGTGTCACTCCCTTGTCGAGGTATCGAAGGTAATGGGGGTAGGTCTGTTGATCACATAAAATTATTAAACTTGAGGGTTTCTGGGACCGTCAACGTCAGTCAAGTCGGTGGTGATGATAATATGGGAGAGAGAACGACCATGAGGGGTATCTTCTTCATGGCTTGTCTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTCAGTATATTGCCGACGTTCAATGAGTTGTTCGGGGAATATGAATCCGTGTACGGCATGCCTAGGTTGAAGGAAAACGTCCGTCACCGGTATCGCGTTATTGGGACATCGAAATTATATATAACGACGGATGAAGATCACATCCAAAAGCCCTTTAGTTTACGTCGAAGACTAAGTGGAGGGAAATATCCTATTTGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGTAACTATAAAAATATAAATAAGAACGCTATACTAGTGAGTTATGTGTGGGTATCGCTATGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTGAATTACGTCGGTTGA |
| Protein Sequence | MYSVYRRGYKTPYRSPYGARVTPYVYRKTSGKQTSKSRVPRKLVYESPKGLYTRRSLEDIHNGASLKLSQQGDYTSYVSLPCRGIEGNGGRSVDHIKLLNLRVSGTVNVSQVGGDDNMGERTTMRGIFFMACLVDKKPFVPEGVSILPTFNELFGEYESVYGMPRLKENVRHRYRVIGTSKLYITTDEDHIQKPFSLRRRLSGGKYPIWSSFKDVDNSSTGGNYKNINKNAILVSYVWVSLCRTTCDVYSQFVLNYVG |
| NCBI Accession | NP_620668.1 |
|---|---|
| Location | 1262-2185 |
| Gene Name | BC1 |
| Protein Name | BC1 |
| Coding Region | ATGGACGCCCAATTTACCGTCACAGACAATAATTACATCAACAGCAAACGCACCGAGTACGCATTAACAAACGATGCTGCACCAATCAATCTCCAATTCCCAGGCTCATTCGAGCAGGCTACCATGCGACTCAAAGGCCGATGTATGAAAATCGACCACATTATAATTGAATACCGAAACCAGGTCCCATTTAACGCAACTGGGTCGGTTATCGTAGAAATCAGAGACAATCGCGTCAGCCTTGACGACGCAGCTCAGGCAGCATTCACTTTCCCCATCGCTTGCAACGTGGACCTCCACTACTTCTCTTCTACATATTTTTCGATTTCTGAACCTTCCCCTTGGAGAATCATGTACAGAGTCGAAGACTCAAACGTCATAGAAGGCGTGAAATTCGCATCCATCAAGGCCAAGCTCCGATTATCATCGGCCAAACATTCCACGGACATACGTTTCAAACCCCCAACAATTAACATCTTATCCAAGGGATACACAAAAGACTGCATAGACTTCTGGTCCGTGGAAAAAGGAGAAACAAGACGACGATTATTAAATCCCACTCCAACTGCTCGTAGTCAACAACCCATAACCCACAGGCCCATCACCATCCATCCAGGCGAAACATGGGCCACAAGGTCTCAGATTGGGCTACCAAGCTCATTAGGCCCAGCACAGCTGGAACACTTTCGTTCACAGTCCATGAGAATGGACCCATCGACAACACCAACGGACTTAGACAACGACTCCACAGAATATCCTTACCAGAAACTACACAGATTACACACACCCGATTTGGACCCAGGGGACTCGATATCACAGGCCCAATCCGACTCCGTCTCCAGAAAGGACCTCGAGACACTGCTTGAGAGTACCATAAACAAGTGTCTCTACAAAATAAAATCCGACGCACCAAGGCAATTGTAA |
| Protein Sequence | MDAQFTVTDNNYINSKRTEYALTNDAAPINLQFPGSFEQATMRLKGRCMKIDHIIIEYRNQVPFNATGSVIVEIRDNRVSLDDAAQAAFTFPIACNVDLHYFSSTYFSISEPSPWRIMYRVEDSNVIEGVKFASIKAKLRLSSAKHSTDIRFKPPTINILSKGYTKDCIDFWSVEKGETRRRLLNPTPTARSQQPITHRPITIHPGETWATRSQIGLPSSLGPAQLEHFRSQSMRMDPSTTPTDLDNDSTEYPYQKLHRLHTPDLDPGDSISQAQSDSVSRKDLETLLESTINKCLYKIKSDAPRQL |
References More References in PubMed
| 1 |
Ramulifho E, et al. Proteomes. 2021 Oct 23;9(4):41. doi: 10.3390/proteomes9040041. PMID: 34842800 |
|---|---|
| 2 |
Nankoo N, et al. Curr Issues Mol Biol. 2022 Jun 15;44(6):2717-2729. doi: 10.3390/cimb44060186. PMID: 35735627 |
| 3 |
Walsh HA, et al. Biotechnol Rep (Amst). 2019 Oct 30;24:e00383. doi: 10.1016/j.btre.2019.e00383. eCollection 2019 Dec. PMID: 31763196 |
| 4 |
Bizabani C, et al. Virus Res. 2021 Oct 2;303:198400. doi: 10.1016/j.virusres.2021.198400. Epub 2021 Mar 19. PMID: 33753179 |
| 5 |
Chatukuta P, et al. Virol J. 2020 Nov 23;17(1):184. doi: 10.1186/s12985-020-01453-4. PMID: 33228712 |
| 6 |
Allie F, et al. BMC Genomics. 2014 Nov 20;15:1006. doi: 10.1186/1471-2164-15-1006. PMID: 25412561 |
| 7 |
Maredza AT, et al. Mol Genet Genomics. 2016 Jun;291(3):1467-85. doi: 10.1007/s00438-015-1049-z. Epub 2015 Apr 29. PMID: 25920485 |
| 8 |
Mwaba I, et al. Virus Res. 2017 Jun 15;238:75-83. doi: 10.1016/j.virusres.2017.05.022. Epub 2017 May 31. PMID: 28577889 |
| 9 |
Rogans SJ, et al. Virus Res. 2016 Oct 2;225:10-22. doi: 10.1016/j.virusres.2016.08.011. Epub 2016 Aug 29. PMID: 27586073 |
| 10 |
Berrie LC, et al. J Gen Virol. 2001 Jan;82(Pt 1):53-58. doi: 10.1099/0022-1317-82-1-53. PMID: 11125158 |