Sidastrum golden leaf spot virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002823485.1 |
| Isolate | Brazil |
| Release date | 2018/8/25 |
| Submitter | Fonseca,M.E.N., Boiteux,L.S., Fernandes,N.A.N., Costa,A.F. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
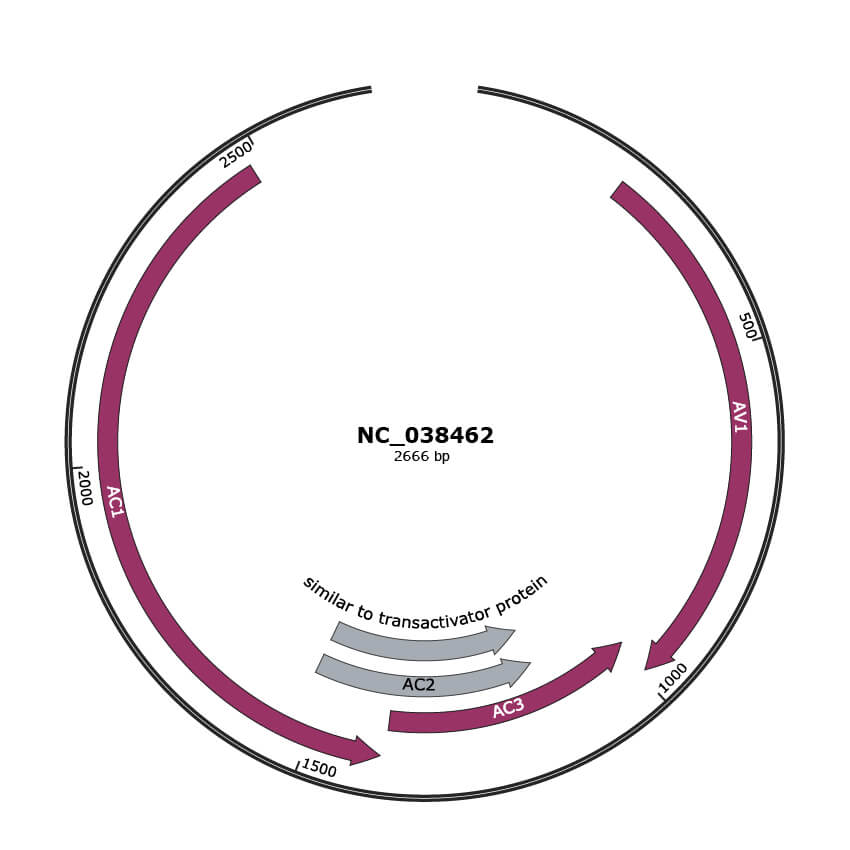
JBrowse
Genome
NC_038462
ACCGGATGGCCGCGCGATTTTTCCCCCCCTCGCGTGGCGCATTGCTGACCGCTCGATCTAGGCGCGATTGTTTAGGCCCATGCGCTTAGGCCCAGTCCATTTGAATTAAAGATGAAATCTTTAATAAAGACCAATCAAAATGCGTCTGGGAAGCCTAGATATTTGTTCCAATACTTCGGCCCTAAGTTTTATGACGTTATAAAAGTAAAGCAAGCATGACGTCATGATATACTTGAAAATGCCGAAGCGGGATCCCTCATGGCGCTCGATGGCGGGAACCTCAAAGGTAAGCCGCTCCTCCAATTTCTCCCCCCGTGGAGGCCCAAAGGTCAATAAGGCCTCTGAATGGGTTAACAGGCCAATGTACAGGAAGCCCAGGATATACAGGACGCTAAGAACTCCTGATGTTCCTAGAGGCTGTGAAGGGCCATGTAAGGTCCAGTCGTACGAGCAGCGTAACGATATCTCACATGCTGGAAAGGTGATCTGTATCTCCGACGTCACTCGCGGTAGCGGTATCACCCATCGTGTCGGTAAGCGGTTTTGTGTTAAGTCTGTGTATATTTTAGGTAAGATCTGGATGGACGAGAACATCAAGTTGAAGAACCACACGAACAGTGTTATGTTCTGGCTGGTCCGGGATCGGAGACCCAACGGCACATCCCCATGGACTTTGGTCATCTGTTCAACATGTTCGACAATGAGCCTAGTACTGCAACTGTTAAGAATGATCTCCGAGATCGTTATCAGGTTCAACACAGATTCTATGCCAAGGTCACTGGTGGTCAATATGCCAGCAATGAGCAGGCCCTGGTCAGGCGGTTTTGGAAGGTCAATACTCATGTCGTGTATAACAACCAGGAAGCTGCTAGATACGAGAACCATACGGAGAATGCCTAGTGTTGTACATGGGCATGTACTCATGCCTCTAATCCCGTGTATGCAACTCTTCAAGATCCGGATCTATTTTTACGATTCGATCTCAATTTAATAAATTTTGAATTTTATTGAATGATCTTCCGAGTACATCAGAGACATACGATCTGTCCTGTTGCGAAATCGAACTGCTTCGGATGACATTATAAAGCGCAGAATACACCTCATTGTTGTAAGTACAGCATGACTTACATGCCTCGACCAACTTGAATAAGTCGTCCCAGAAGCTCTCATCGATGTCGTCCAGACTTGGAAGTTCAGGAATGCCTTGTGGAGACCCAACGCTCTCCTGAGGTTGTGGTTGAACCGGATCTGGATGTGATACACTCTGGTCCCTGTGAACAGGATGTCTTCTACTCGGTGCATCTTGAAATACAGGGGATTTGTTATCTCCCAGATATATACGCCATTCTCTGCCTGATGTGCAGTGATGAGTTCCCCGGATGCGTGCATCCATGACCTATGCAGTTGATGTGGACGTATATGGAGCAGCCGCACTCGATGTGAATCCGTCGCCGTCTGAGTTGCTCTCTTTTTCGCAATCCTGTGTTGATGTTTGATAGAGGGGGGAGTCGAGAAAGATGAATTTAGCATTATGGAGGGTCCACGATTTCAAGCGCAGCATTTTCCTCTTTGTCAAGGAAATCTTTATAGCTGGCCCCCTCGCCTGGATTGCAGAGCACGATTGATGGGATCCCTCCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGACTGCCAGTCTTTTTGGGCCCCAATAAATTCTTTCCAGTGCTTAATCTTAAGATATTGCGGTGTGACATCATCGATGACGTTATATTCCGCTTTGTCTGAGTAAACCCTAGAATTGAAGTCCAGGTGTCCGCTAAAATAATTATGTGGGCCAAACGCACGAGCCCACATTGTCTTCCCCGTCCGACTATCACCCTTCGACGATGATACTCATCGGTCTTTCCAGGCCGCGCAGCGGCACCCCTCCCAAAATAATCATCTGCCCACTCTTGCATCTCGTCCGGAACTCTAGTGAACGAGGAGAGTTGAAACGGAGGAGTCCATGGTTCCGGAGCCTTTTGAAACAGTCGTTCGATGTTAGCCTTTATGTTATGGTAGCTTGACAATGTACGCCTCCGGATCTCCGGCTTTGATGATTTCAAGAGCGTCTCCTCGTACAATGCTGCGTTCAACGGCGCTGTGGTAGCATCGTCGTCTGTCTGTTGCCCTCCTTCTAGCAGATCTTCCGTCGATCTGAAAACTACCCCATTCGCAGTAATCTCCGTCCTTCTCGATATATGTCTTGGCGTCTGAGGAGGACTTGCATGATTCGTATTTTCCATGACATACATTGGAATTGCAGGGATGTTTAAGATCGAAGAATCTGCAATTCGTACATGTGAACTTCCCTTCGAACTGAAGCAGGACGTGTAGATGAGGTTCCCCATTTTCATGGAGCTCTCTACATACTCTGATATATTTTTTATTAACTGGGGTTTCGAGGGCAAATAATTGGGAAAGTGCTTCTTCCTTTGAAATAGAGCACTTGGCATAAGTGAGGAAATAATTTCTGGATTGTATTTTAAAACGTTTTGCTGGTGGCATTTTTGTAAATAAGGGAGTGTCTCCAATTGAGCTCCTCTCAAACTTGCGATATGTATTGGAGACTACAGACAATATATAGTAGAGAAGTTCTCTAGGACCTCGAGACAAGTGGCGGCCCATCCGTTTAATATT
Gene Information
| NCBI Accession | YP_009506486.1 |
|---|---|
| Location | 224-991 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGATATACTTGAAAATGCCGAAGCGGGATCCCTCATGGCGCTCGATGGCGGGAACCTCAAAGGTAAGCCGCTCCTCCAATTTCTCCCCCCGTGGAGGCCCAAAGGTCAATAAGGCCTCTGAATGGGTTAACAGGCCAATGTACAGGAAGCCCAGGATATACAGGACGCTAAGAACTCCTGATGTTCCTAGAGGCTGTGAAGGGCCATGTAAGGTCCAGTCGTACGAGCAGCGTAACGATATCTCACATGCTGGAAAGGTGATCTGTATCTCCGACGTCACTCGCGGTAGCGGTATCACCCATCGTGTCGGTAAGCGGTTTTGTGTTAAGTCTGTGTATATTTTAGGTAAGATCTGGATGGACGAGAACATCAAGTTGAAGAACCACACGAACAGTGTTATGTTCTGGCTGGTCCGGGATCGGAGACCCAACGGCACATCCCCATGGACTTTGGTCATCTGTTCAACATGTTCGACAATGAGCCTAGTACTGCAACTGTTAAGAATGATCTCCGAGATCGTTATCAGGTTCAACACAGATTCTATGCCAAGGTCACTGGTGGTCAATATGCCAGCAATGAGCAGGCCCTGGTCAGGCGGTTTTGGAAGGTCAATACTCATGTCGTGTATAACAACCAGGAAGCTGCTAGATACGAGAACCATACGGAGAATGCCTAGTGTTGTACATGGGCATGTACTCATGCCTCTAATCCCGTGTATGCAACTCTTCAAGATCCGGATCTATTTTTACGATTCGATCTCAATTTAA |
| Protein Sequence | MIYLKMPKRDPSWRSMAGTSKVSRSSNFSPRGGPKVNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRNDISHAGKVICISDVTRGSGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPNGTSPWTLVICSTCSTMSLVLQLLRMISEIVIRFNTDSMPRSLVVNMPAMSRPWSGGFGRSILMSCITTRKLLDTRTIRRMPSVVHGHVLMPLIPCMQLFKIRIYFYDSISI |
| NCBI Accession | YP_009506487.1 |
|---|---|
| Location | 988-1389 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGCACGCATCCGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTATATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATGCACCGAGTAGAAGACATCCTGTTCACAGGGACCAGAGTGTATCACATCCAGATCCGGTTCAACCACAACCTCAGGAGAGCGTTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACATCGATGAGAGCTTCTGGGACGACTTATTCAAGTTGGTCGAGGCATGTAAGTCATGCTGTACTTACAACAATGAGGTGTATTCTGCGCTTTATAATGTCATCCGAAGCAGTTCGATTTCGCAACAGGACAGATCGTATGTCTCTGATGTACTCGGAAGATCATTCAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MHASGELITAHQAENGVYIWEITNPLYFKMHRVEDILFTGTRVYHIQIRFNHNLRRALGLHKAFLNFQVWTTSMRASGTTYSSWSRHVSHAVLTTMRCILRFIMSSEAVRFRNRTDRMSLMYSEDHSIKFKIY |
| NCBI Accession | YP_009506488.1 |
|---|---|
| Location | 1397-2482 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCAAGTGCTCTATTTCAAAGGAAGAAGCACTTTCCCAATTATTTGCCCTCGAAACCCCAGTTAATAAAAAATATATCAGAGTATGTAGAGAGCTCCATGAAAATGGGGAACCTCATCTACACGTCCTGCTTCAGTTCGAAGGGAAGTTCACATGTACGAATTGCAGATTCTTCGATCTTAAACATCCCTGCAATTCCAATGTATGTCATGGAAAATACGAATCATGCAAGTCCTCCTCAGACGCCAAGACATATATCGAGAAGGACGGAGATTACTGCGAATGGGGTAGTTTTCAGATCGACGGAAGATCTGCTAGAAGGAGGGCAACAGACAGACGACGATGCTACCACAGCGCCGTTGAACGCAGCATTGTACGAGGAGACGCTCTTGAAATCATCAAAGCCGGAGATCCGGAGGCGTACATTGTCAAGCTACCATAACATAAAGGCTAACATCGAACGACTGTTTCAAAAGGCTCCGGAACCATGGACTCCTCCGTTTCAACTCTCCTCGTTCACTAGAGTTCCGGACGAGATGCAAGAGTGGGCAGATGATTATTTTGGGAGGGGTGCCGCTGCGCGGCCTGGAAAGACCGATGAGTATCATCGTCGAAGGGTGATAGTCGGACGGGGAAGACAATGTGGGCTCGTGCGTTTGGCCCACATAATTATTTTAGCGGACACCTGGACTTCAATTCTAGGGTTTACTCAGACAAAGCGGAATATAACGTCATCGATGATGTCACACCGCAATATCTTAAGATTAAGCACTGGAAAGAATTTATTGGGGCCCAAAAAGACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTCTGCAATCCAGGCGAGGGGGCCAGCTATAAAGATTTCCTTGACAAAGAGGAAAATGCTGCGCTTGAAATCGTGGACCCTCCATAATGCTAAATTCATCTTTCTCGACTCCCCCCTCTATCAAACATCAACACAGGATTGCGAAAAAGAGAGCAACTCAGACGGCGACGGATTCACATCGAGTGCGGCTGCTCCATATACGTCCACATCAACTGCATAG |
| Protein Sequence | MPSALFQRKKHFPNYLPSKPQLIKNISEYVESSMKMGNLIYTSCFSSKGSSHVRIADSSILNIPAIPMYVMENTNHASPPQTPRHISRRTEITANGVVFRSTEDLLEGGQQTDDDATTAPLNAALYEETLLKSSKPEIRRRTLSSYHNIKANIERLFQKAPEPWTPPFQLSSFTRVPDEMQEWADDYFGRGAAARPGKTDEYHRRRVIVGRGRQCGLVRLAHIIILADTWTSILGFTQTKRNITSSMMSHRNILRLSTGKNLLGPKKTGSQIANTESQFKLKEGSHQSCSAIQARGPAIKISLTKRKMLRLKSWTLHNAKFIFLDSPLYQTSTQDCEKESNSDGDGFTSSAAAPYTSTSTA |
References More References in PubMed
| 1 |
First Report of Moroccan watermelon mosaic virus in Zucchini Crops in Greece. Malandraki I, et al. Plant Dis. 2014 May;98(5):702. doi: 10.1094/PDIS-10-13-1100-PDN. PMID: 30708553 |
|---|---|
| 2 |
Chiquito-Almanza E, et al. Viruses. 2017 Mar 30;9(4):63. doi: 10.3390/v9040063. PMID: 28358318 |