Bean latent virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_018587735.1 |
| Isolate | Mexico: Ruiz, Nayarit |
| Release date | 2021/6/1 |
| Submitter | Martinez-Marrero,N., Avalos-Calleros,J.A., Chiquito-Almanza,E., Acosta-Gallegos,J.A., Ambriz-Granados,S., Arguello-Astorga,G.R., Anaya-Lopez,J.L. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
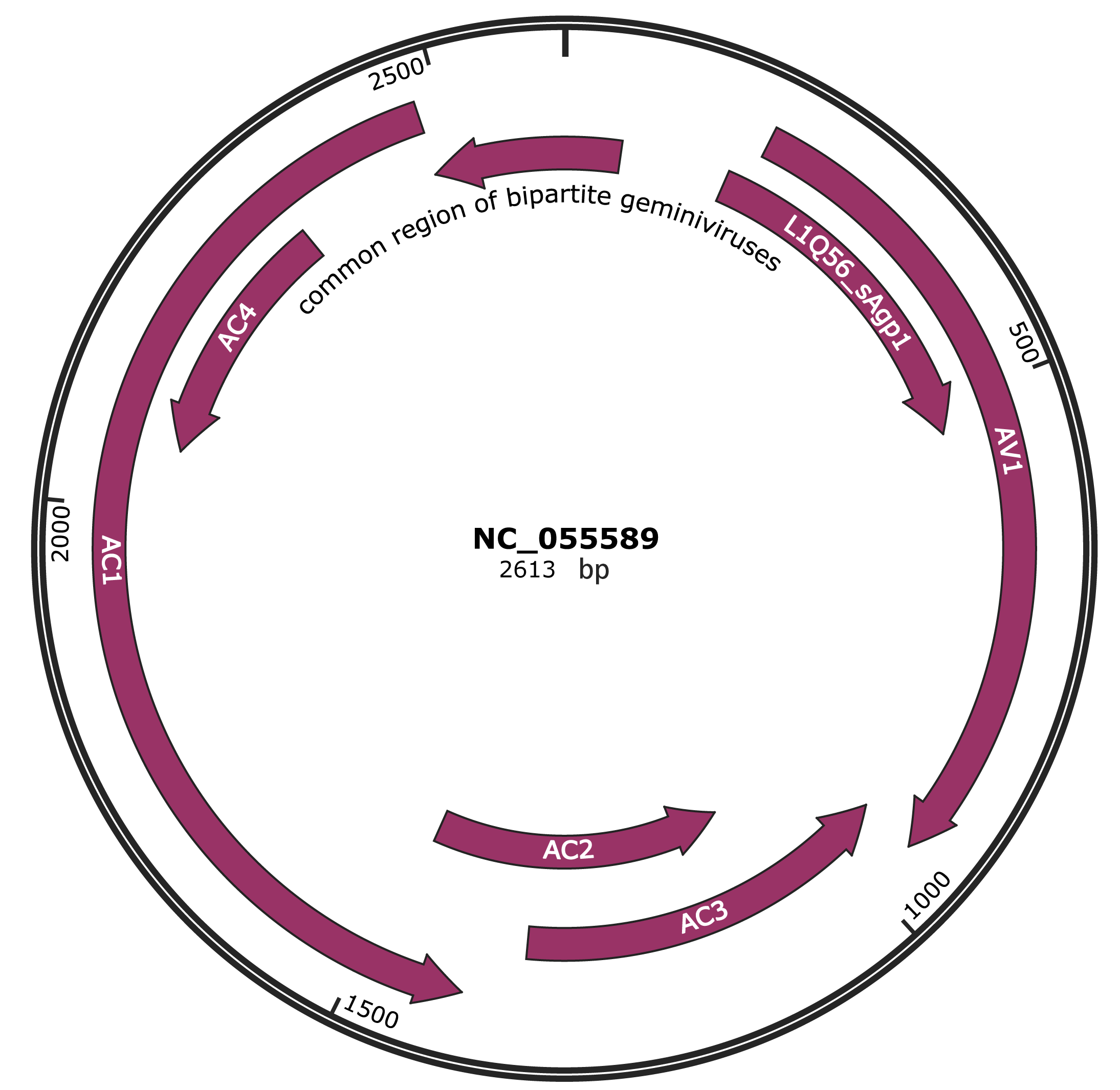
JBrowse
Genome
NC_055589
Gene Information
| NCBI Accession | YP_010087810.1 |
|---|---|
| Location | 172-531 |
| Protein Name | hypothetical protein |
| Coding Region | ATGCTTATCCTCTTTAATTCAAAATGCCTAAGCGCGATGCCCCGTGGCGCACAATGGCGGGGACCTCCAAGGTCAGCCGCTCCGCGAATTATTCGCCTCGTGGAGGTATGGGTCCAAAGATGGACAAGGCCTCTGCTTGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATATATCGGGTCCAAAGAGGACCTGACGTCCCTAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCATTTGAACAGCGTCATGATATTTCTCATGTTGGTAAGGTCATTTGTATATCTGATGTCACACGTGGTAACGGTATTACTCATCGTGTGGGAAAACGTTTTTGTGTTAAGTCTGTGTATATTTTAG |
| Protein Sequence | MLILFNSKCLSAMPRGAQWRGPPRSAAPRIIRLVEVWVQRWTRPLLGLTGPCIGSPGYIGSKEDLTSLEAVKGLVRSSHLNSVMIFLMLVRSFVYLMSHVVTVLLIVWENVFVLSLCIF |
| NCBI Accession | YP_010087811.1 |
|---|---|
| Location | 195-950 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGATGCCCCGTGGCGCACAATGGCGGGGACCTCCAAGGTCAGCCGCTCCGCGAATTATTCGCCTCGTGGAGGTATGGGTCCAAAGATGGACAAGGCCTCTGCTTGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATATATCGGGTCCAAAGAGGACCTGACGTCCCTAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCATTTGAACAGCGTCATGATATTTCTCATGTTGGTAAGGTCATTTGTATATCTGATGTCACACGTGGTAACGGTATTACTCATCGTGTGGGAAAACGTTTTTGTGTTAAGTCTGTGTATATTTTAGGTAAGATATGGATGGACGAGAATATTAAATTGAAGAACCACACGAACAGCGTCATGTTCTGGTTGGTCAGAGACAGAAGACCATATGGCACGCCTATGGATTTTGGTCAAGTCTTTAACATGTATGACAATGAGCCCAGTACTGCCACTGTCAAGAACGATCTTCGTGATCGTTTTCAAGTTTTACACAGGTTCTATGCGAAGGTGACTGGTGGTCAGTATGCTAGCAACGAGCAGGCTATTGTTAGGCGATTTTGGAAGGTGAATAATCATGTCGTGTACAATCATCAAGAAGCAGCCAAGTACGAGAATCACACGGAGAATGCGTTACTATTGTATATGGCATGTACGCATGCCTCCAATCCTGTATATGCTACGTTGAAAATACGTAGTTATTTCTATGACTCGATTTCCAATTAA |
| Protein Sequence | MPKRDAPWRTMAGTSKVSRSANYSPRGGMGPKMDKASAWVNRPMYRKPRIYRVQRGPDVPRGCEGPCKVQSFEQRHDISHVGKVICISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRFQVLHRFYAKVTGGQYASNEQAIVRRFWKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRSYFYDSISN |
| NCBI Accession | YP_010087812.1 |
|---|---|
| Location | 947-1345 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACTCACAGGGGAACCCATCACTGCGCATCAAGCAGAGAGTGGCGTTTTTATCTGGGAGGTGCCAAATCCCCTTTATTTCAAGATAACAAGAGTAGAGGATCCACCGTTCTCCTTGACGAGGATATTCCACATCCAGATAAGGTTCAACCACAACCTGAGGAGGGCTCTGGATCTACACAAAGCGTATCTAAATTTCCAAGTCTGGACGACATTGATTCGAGTTTCTGGAACGACTTACTTAAATAGATTTAGGCATTTAGTCATGTTGTACTTAGACAATTTGGGCGTTATTTCAATTAATAATGTAATTCGAGCTGTTGCTTTCGCAACAGACAGACCATATGTAACTCATGTAATAGAAGATCATTCAATAAAATTTAACATTTATTAA |
| Protein Sequence | MDSLTGEPITAHQAESGVFIWEVPNPLYFKITRVEDPPFSLTRIFHIQIRFNHNLRRALDLHKAYLNFQVWTTLIRVSGTTYLNRFRHLVMLYLDNLGVISINNVIRAVAFATDRPYVTHVIEDHSIKFNIY |
| NCBI Accession | YP_010087813.1 |
|---|---|
| Location | 1092-1481 |
| Gene Name | AC2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCGAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCTCAGCACCGGTTTGCAAAACGCAGGGCAGTCCGACGTAGAAGAATCGACTTGGAGTGCGGCTGTTCGATCTTCCTACACATCAACTGCTTCAATCATGGATTCACTCACAGGGGAACCCATCACTGCGCATCAAGCAGAGAGTGGCGTTTTTATCTGGGAGGTGCCAAATCCCCTTTATTTCAAGATAACAAGAGTAGAGGATCCACCGTTCTCCTTGACGAGGATATTCCACATCCAGATAAGGTTCAACCACAACCTGAGGAGGGCTCTGGATCTACACAAAGCGTATCTAAATTTCCAAGTCTGGACGACATTGATTCGAGTTTCTGGAACGACTTACTTAAATAG |
| Protein Sequence | MRNSSSSTPPSIKPQHRFAKRRAVRRRRIDLECGCSIFLHINCFNHGFTHRGTHHCASSREWRFYLGGAKSPLFQDNKSRGSTVLLDEDIPHPDKVQPQPEEGSGSTQSVSKFPSLDDIDSSFWNDLLK |
| NCBI Accession | YP_010087814.1 |
|---|---|
| Location | 1402-2478 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCACTCCCGAAACGCTTTCGCTTAAATGCCAAGAACTACTTCCTCACATATCCTCAGTGTTCCATATCCAAAGAAGAGGCATTATCACAATTACAACGTCTAACAACTCCAGTTAACAAGAAGTTTATCAAGATATGCAGAGAAACACATGAAGATGGGCAACCTCATCTACACGTGCTTATCCAGTTCGAAGGGAAATACCAATGTTCAAATAACAGATTCTTCGACCTGGTCTCCACAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATCGACAAGGATGGAGATACAATTGAATGGGGAGAGTTCCAAATCGACGGCAGATCTGCTAGAGGAGGTCAGCAATCTGCTAACGACACATACGCGAAGGCATTAAATGCAGGTTCTGCAGAAGCGGCTCTGCAGATAATCAAGGAAGAACAACCTCAACATTTCTTCCTTCAATATCATAATCTGGTCTCAAACGCAACAAGGATATTCCAAAAACCCCCGGAACCATGGGTTCCTCCATTTCCACAATCGTCGTTCAACAACGTTCCACTGGATATGCAACAATGGGCTGACGATTATTTCGGAAGGGGTGCCGCTGCGCGGACAGAGAGACCTATTAGTATCATCATTGAAGGTGATTCAAGAACTGGAAAAACAATGTGGGCACGTTCATTAGGTTCTCATAATTACTTGAGTGGACACCTGGATTTCAATTCTTTTGTCTATTCAAATAATGTAGATTACAACGTCATTGATGACGTCGCTCCACAATACTTAAAGATGAAGCACTGGAAAGAGCTTATCGGGGCCCAAAAGAATTGGCAAACAAATTGCAAGTACGGAAAGCCAGTTCAAATTAAAGGTGGTATCCCATCAATTGTGCTTTGCAATCCAGGAGAGGGGGCGAGTTATAAAGACTACTTGGATAGACAAGAGAATGCACATCTAAAAGCGTGGACGCTTCATAATGCGAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCTCAGCACCGGTTTGCAAAACGCAGGGCAGTCCGACGTAG |
| Protein Sequence | MPLPKRFRLNAKNYFLTYPQCSISKEEALSQLQRLTTPVNKKFIKICRETHEDGQPHLHVLIQFEGKYQCSNNRFFDLVSTTRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGEFQIDGRSARGGQQSANDTYAKALNAGSAEAALQIIKEEQPQHFFLQYHNLVSNATRIFQKPPEPWVPPFPQSSFNNVPLDMQQWADDYFGRGAAARTERPISIIIEGDSRTGKTMWARSLGSHNYLSGHLDFNSFVYSNNVDYNVIDDVAPQYLKMKHWKELIGAQKNWQTNCKYGKPVQIKGGIPSIVLCNPGEGASYKDYLDRQENAHLKAWTLHNAKFIFLNSPLYQTSAPVCKTQGSPT |
| NCBI Accession | YP_010087815.1 |
|---|---|
| Location | 2064-2327 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAGATGGGCAACCTCATCTACACGTGCTTATCCAGTTCGAAGGGAAATACCAATGTTCAAATAACAGATTCTTCGACCTGGTCTCCACAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATCGACAAGGATGGAGATACAATTGAATGGGGAGAGTTCCAAATCGACGGCAGATCTGCTAGAGGAGGTCAGCAATCTGCTAACGACACATACGCGAAGGCATTAA |
| Protein Sequence | MKMGNLIYTCLSSSKGNTNVQITDSSTWSPQPGQHISIRTYRELNPAPMSSPTSTRMEIQLNGESSKSTADLLEEVSNLLTTHTRRH |
References More References in PubMed
| 1 |
Takahashi H, et al. Front Microbiol. 2025 Apr 9;16:1524787. doi: 10.3389/fmicb.2025.1524787. eCollection 2025. PMID: 40270808 |
|---|---|
| 2 |
Satoh N, et al. Viruses. 2014 Nov 7;6(11):4242-57. doi: 10.3390/v6114242. PMID: 25386843 |
| 3 |
Rubino L, et al. J Gen Virol. 2025 Jul;106(7):002114. doi: 10.1099/jgv.0.002114. PMID: 40711908 |
| 4 |
Li C, et al. Virus Genes. 2020 Feb;56(1):67-77. doi: 10.1007/s11262-019-01708-5. Epub 2019 Oct 23. PMID: 31646461 |
| 5 |
Social Determinants of Health and Pediatric Long COVID in the US. Rhee KE, et al. JAMA Pediatr. 2026 Mar 1;180(3):275-287. doi: 10.1001/jamapediatrics.2025.5485. PMID: 41490011 |
| 6 |
Ikegami M, et al. Virus Genes. 1988 Mar;1(2):191-203. doi: 10.1007/BF00555937. PMID: 3238924 |
| 7 |
Molecular Characterization of a Novel Polerovirus Infecting Soybean in China. Xu T, et al. Viruses. 2022 Jun 29;14(7):1428. doi: 10.3390/v14071428. PMID: 35891408 |
| 8 |
Tamura A, et al. Virology. 2013 Nov;446(1-2):314-24. doi: 10.1016/j.virol.2013.08.019. Epub 2013 Sep 8. PMID: 24074595 |
| 9 |
Wagner EK, et al. J Virol. 1988 Dec;62(12):4577-85. doi: 10.1128/JVI.62.12.4577-4585.1988. PMID: 2846871 |
| 10 |
Virus-vector relationship in the Citrus leprosis pathosystem. Tassi AD, et al. Exp Appl Acarol. 2017 Mar;71(3):227-241. doi: 10.1007/s10493-017-0123-0. Epub 2017 Apr 17. PMID: 28417249 |