Sida yellow net virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000905775.1 |
| Isolate |
Brazil |
| Release date |
2015/2/22 |
| Submitter |
Tavares,S.S., Ramos-Sobrinho,R., Gonzales-Aguilera,J., Lima,G.S.A., Assuncao,I.P., Zerbini,F.M. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
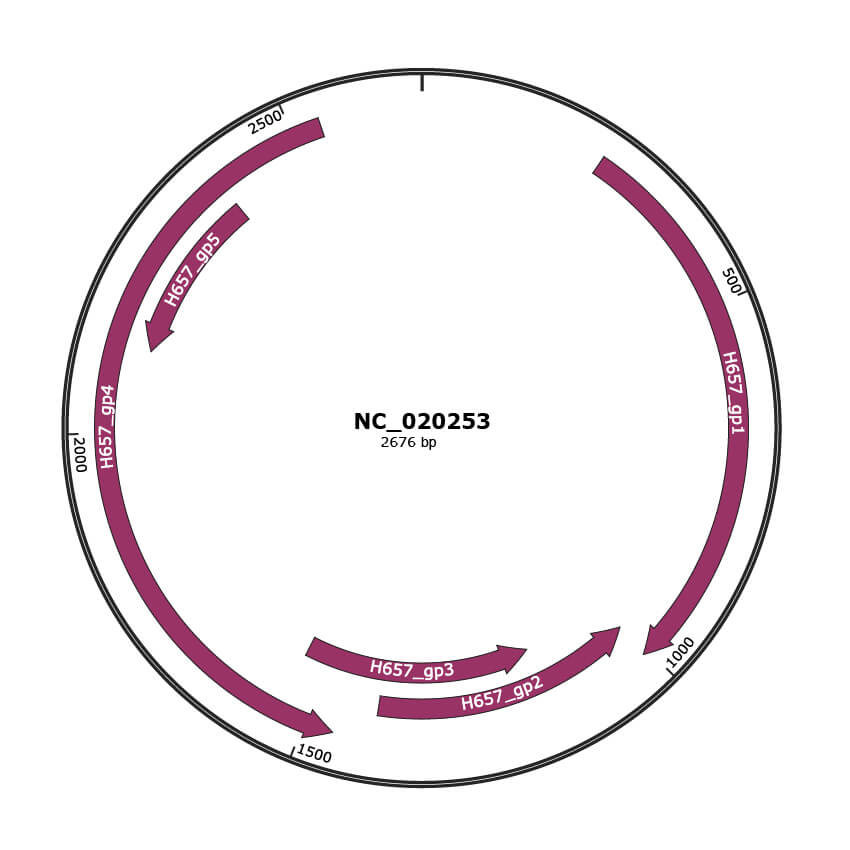
JBrowse
Genome
ACCGGATGGCCGCGCGATTTCTCCCCCCCCCCTACGTGGCGCTCTGGTGGCCGCTCGATCCCCCCACCCGCTCGCGTGGAGTCCCCCCGTACCCGCGCGCTCATCAAATTTAATTTGAATTAAAGGTTTTATCTTTTGTTTAGCCAATGATATTGCGCCTGAGAAGCTTAGATATCTGTGTAATACTTCGTCCCCAAGTTTTATAACCCCTATAAAACTAAAGCATTAATGACGTCATACTTTAATTCAGGAATGCCTAAGCGGGATCCCTCATGGCGCCAGATGGCGGGAACCTCAAAGGTTAGCCGCACTTCCAATTTCTCACCTCGTGGAGGTGGAGGCCCAAAATTCAACAAGGCCTCAGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGGACGCTGAGAACACCTGATGTGCCTAGAGGCTGTGAAGGACCCTGTAAGGTCCAGTCGTACGAGCAACGTCACGATATCTCCCATGTTGGGAAGGTGATGTGTATATCTGATATTACTCGCGGTAACGGTATTACCCACCGTGTAGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATTCTAGGTAAGGTGTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTTGCATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGCACACCTATGGATTTTGGCCAGGTATTCAACATGTTCGACAACGAGCCTAGCACTGCAACCGTGAAGAACGATCTGCGTGATCGTTTCCAAGTCATGCATAAGTTCTATGCCAAGGTCACTGGTGGACAGTATGCCAGCAACGAGCAGGCGCTGGTCAAGCGTTTCTGGAAGGTCAACAATCATGTAGTTTATAATCACCAGGAAGCTGGGAAGTACGAGAATCATACAGAGAACGCTTTATTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTCAAGATTCGAATCTATTTCTACGATTCGATCACCAATTAATAAAGCTTAAATTTTATTGAATGATTTTCCAGTACATATCTGACGTAAGATCTGTCAGTCGCATAACGAACAGCTCTAATTACATTGTTTATCGTAATAACACCTAATCGGTCTAAATACATCATGACTAAATGTCTAAATCTAATCAAATAAGTCGTTCCAGAAGCTGTCAGAGATGTCGTCCAGACTTGGAAGTTCAGGAATGCCTTGTGGAGATCCAATGCTTTCCTGAGGTTGTGGTTGAACCGTATCTGTACGTGGTACACTCTGGTCGTCGTGTACAACATGTCCTCTACGTGGTATATCTTGAAATACAGGGGATTTGTTATCTCCCAGATATAGACGCCATTCTCTGCCTGAGGCGCAGTGATGAGTTCCCCGGTGCGTGAATCCATGATTGCTGCAGTTGATGTGGACGTAGACGGTGCACCCGCACTGTATATCAATTCTTCTACGGCGAGTTCCTCTCCTCTTCGCCGCTCTGTGTTGCACTTTGATACAGGGGGGAGTCGAGGAAGATGAATTTTGCATTGTGGAGTGTCCACGACTTTAATGCTGCATTCTCCTCTTTGTCTAGGTACTCTTTATAACTGACTCCCTCCCCCTGGATTGCAGAGCACGATTGATGGTATCCCACCTTTAATTTTGAACTGGCTTTTCCGTACTTGCAATTTGACTGCCAGTCTTTTTGAGCACCAATCAACTCCTTCCAGTGCTTTAACTTTAGATATTGCGGGTTGACGTCATCAATGACGTTGTATTCCACTTCGTTCGAGTAAACCCTAGAATTGAAGTCGAGATGACCACTCAAGTAATTATGTGGGCCTAACGCACGAGCCCACATCGTCTTCCCTGTTCGACTATCACCTTCGACTATCAAACTCATAGGTCTCAATGGCCGCGCAGCGGAACCCCTTCCAAAATACTCATCCGCCCACTCTTGCATCTCGTCGGGAACGTTAGTGAAGGAGGATAGGGGAAACGGAGGAACCCACGGCTCCGGAGCCTTTGTGAAAATTCTATTTAAATTAGAATTTAAATTGTGAAATTGAAAAAGAAATTTTTCCGGCAATTTCTCCCTAATTATTTGCAGAGCCGTCTGTTTATCCGGAGCATTTAACGCCTCAGCTGCAGCATCATTAGCTGTCTGTTGGCCTCCTCTAGCACTTCTTCCGTCGACCTGGAACTGTCCCCATTCAATTGTATCTCCGTCTTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTTGTTGGGGATACCAGGTCGAACAATCTATTATTCGTGCACTGGAATTTCCCTTCGAACTGGAGAAGGACGTGGAGATGAGGCTCCCCATTTTCATGAAGCTCTCTGCATATTTTGATGAATTTCTTGTTGACCGGTGTTTGAATGTCAAGAAATTGGGAAAGTGTTTCTTCTTTGGTTAACGAACACCGGGGATATGTTATGAAATAGTTTTTGGCTTTTATACAGAAAGAACCCTTCCGTGGCATTTTTGTAAATAAGGCTGTGTACCCCCGATTGCTCTCCGCTCTAAAACTCCTATGAATTGGGGGTACTGGGGGTACATTTATACTAGAAGTTCCTATAGGACTTAAAGGGGTACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_007438865.1
|
|
Location
|
253-1008 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATCCCTCATGGCGCCAGATGGCGGGAACCTCAAAGGTTAGCCGCACTTCCAATTTCTCACCTCGTGGAGGTGGAGGCCCAAAATTCAACAAGGCCTCAGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGGACGCTGAGAACACCTGATGTGCCTAGAGGCTGTGAAGGACCCTGTAAGGTCCAGTCGTACGAGCAACGTCACGATATCTCCCATGTTGGGAAGGTGATGTGTATATCTGATATTACTCGCGGTAACGGTATTACCCACCGTGTAGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATTCTAGGTAAGGTGTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTTGCATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGCACACCTATGGATTTTGGCCAGGTATTCAACATGTTCGACAACGAGCCTAGCACTGCAACCGTGAAGAACGATCTGCGTGATCGTTTCCAAGTCATGCATAAGTTCTATGCCAAGGTCACTGGTGGACAGTATGCCAGCAACGAGCAGGCGCTGGTCAAGCGTTTCTGGAAGGTCAACAATCATGTAGTTTATAATCACCAGGAAGCTGGGAAGTACGAGAATCATACAGAGAACGCTTTATTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTCAAGATTCGAATCTATTTCTACGATTCGATCACCAATTAA |
|
Protein Sequence
|
MPKRDPSWRQMAGTSKVSRTSNFSPRGGGGPKFNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDITRGNGITHRVGKRFCVKSVYILGKVWMDENIKLKNHTNSCMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_007438866.1
|
|
Location
|
1005-1403 |
|
Protein Name
|
replication-enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACTCATCACTGCGCCTCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATATACCACGTAGAGGACATGTTGTACACGACGACCAGAGTGTACCACGTACAGATACGGTTCAACCACAACCTCAGGAAAGCATTGGATCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACATCTCTGACAGCTTCTGGAACGACTTATTTGATTAGATTTAGACATTTAGTCATGATGTATTTAGACCGATTAGGTGTTATTACGATAAACAATGTAATTAGAGCTGTTCGTTATGCGACTGACAGATCTTACGTCAGATATGTACTGGAAAATCATTCAATAAAATTTAAGCTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAENGVYIWEITNPLYFKIYHVEDMLYTTTRVYHVQIRFNHNLRKALDLHKAFLNFQVWTTSLTASGTTYLIRFRHLVMMYLDRLGVITINNVIRAVRYATDRSYVRYVLENHSIKFKLY |
|
NCBI Accession
|
YP_007438867.1
|
|
Location
|
1150-1539 |
|
Protein Name
|
transactivating protein |
|
Coding Region
|
ATGCAAAATTCATCTTCCTCGACTCCCCCCTGTATCAAAGTGCAACACAGAGCGGCGAAGAGGAGAGGAACTCGCCGTAGAAGAATTGATATACAGTGCGGGTGCACCGTCTACGTCCACATCAACTGCAGCAATCATGGATTCACGCACCGGGGAACTCATCACTGCGCCTCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATATACCACGTAGAGGACATGTTGTACACGACGACCAGAGTGTACCACGTACAGATACGGTTCAACCACAACCTCAGGAAAGCATTGGATCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACATCTCTGACAGCTTCTGGAACGACTTATTTGATTAG |
|
Protein Sequence
|
MQNSSSSTPPCIKVQHRAAKRRGTRRRRIDIQCGCTVYVHINCSNHGFTHRGTHHCASGREWRLYLGDNKSPVFQDIPRRGHVVHDDQSVPRTDTVQPQPQESIGSPQGIPELPSLDDISDSFWNDLFD |
|
NCBI Accession
|
YP_007438868.1
|
|
Location
|
1460-2539 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGGAAGGGTTCTTTCTGTATAAAAGCCAAAAACTATTTCATAACATATCCCCGGTGTTCGTTAACCAAAGAAGAAACACTTTCCCAATTTCTTGACATTCAAACACCGGTCAACAAGAAATTCATCAAAATATGCAGAGAGCTTCATGAAAATGGGGAGCCTCATCTCCACGTCCTTCTCCAGTTCGAAGGGAAATTCCAGTGCACGAATAATAGATTGTTCGACCTGGTATCCCCAACAAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGACGGAGATACAATTGAATGGGGACAGTTCCAGGTCGACGGAAGAAGTGCTAGAGGAGGCCAACAGACAGCTAATGATGCTGCAGCTGAGGCGTTAAATGCTCCGGATAAACAGACGGCTCTGCAAATAATTAGGGAGAAATTGCCGGAAAAATTTCTTTTTCAATTTCACAATTTAAATTCTAATTTAAATAGAATTTTCACAAAGGCTCCGGAGCCGTGGGTTCCTCCGTTTCCCCTATCCTCCTTCACTAACGTTCCCGACGAGATGCAAGAGTGGGCGGATGAGTATTTTGGAAGGGGTTCCGCTGCGCGGCCATTGAGACCTATGAGTTTGATAGTCGAAGGTGATAGTCGAACAGGGAAGACGATGTGGGCTCGTGCGTTAGGCCCACATAATTACTTGAGTGGTCATCTCGACTTCAATTCTAGGGTTTACTCGAACGAAGTGGAATACAACGTCATTGATGACGTCAACCCGCAATATCTAAAGTTAAAGCACTGGAAGGAGTTGATTGGTGCTCAAAAAGACTGGCAGTCAAATTGCAAGTACGGAAAAGCCAGTTCAAAATTAAAGGTGGGATACCATCAATCGTGCTCTGCAATCCAGGGGGAGGGAGTCAGTTATAAAGAGTACCTAGACAAAGAGGAGAATGCAGCATTAAAGTCGTGGACACTCCACAATGCAAAATTCATCTTCCTCGACTCCCCCCTGTATCAAAGTGCAACACAGAGCGGCGAAGAGGAGAGGAACTCGCCGTAG |
|
Protein Sequence
|
MPRKGSFCIKAKNYFITYPRCSLTKEETLSQFLDIQTPVNKKFIKICRELHENGEPHLHVLLQFEGKFQCTNNRLFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGQFQVDGRSARGGQQTANDAAAEALNAPDKQTALQIIREKLPEKFLFQFHNLNSNLNRIFTKAPEPWVPPFPLSSFTNVPDEMQEWADEYFGRGSAARPLRPMSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNEVEYNVIDDVNPQYLKLKHWKELIGAQKDWQSNCKYGKASSKLKVGYHQSCSAIQGEGVSYKEYLDKEENAALKSWTLHNAKFIFLDSPLYQSATQSGEEERNSP |
|
NCBI Accession
|
YP_007438869.1
|
|
Location
|
2125-2382 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCACGTCCTTCTCCAGTTCGAAGGGAAATTCCAGTGCACGAATAATAGATTGTTCGACCTGGTATCCCCAACAAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGACGGAGATACAATTGAATGGGGACAGTTCCAGGTCGACGGAAGAAGTGCTAGAGGAGGCCAACAGACAGCTAATGATGCTGCAGCTGAGGCGTTAA |
|
Protein Sequence
|
MGSLISTSFSSSKGNSSARIIDCSTWYPQQGQHISIRTFRELNPAPTSSPTSTKTEIQLNGDSSRSTEEVLEEANRQLMMLQLRR |