Sida yellow mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000896395.1 |
| Isolate | Cuba |
| Release date | 2015/2/22 |
| Submitter | Fiallo-Olive,E., Navas-Castillo,J., Moriones,E., Martinez-Zubiaur,Y. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
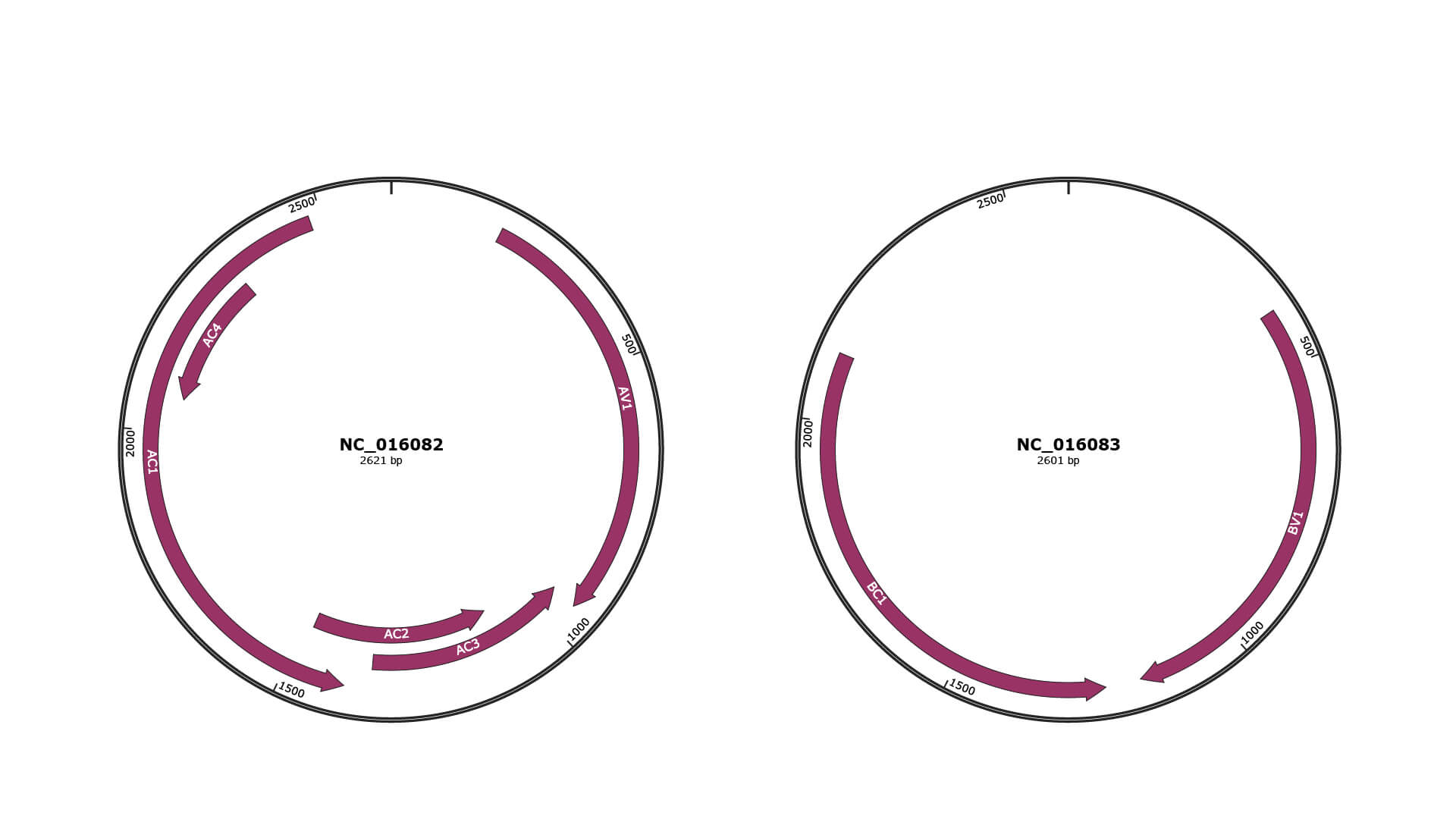
JBrowse
Genome
NC_016082
NC_016083
Gene Information
| NCBI Accession | YP_004901693.1 |
|---|---|
| Location | 196-951 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGATCTGCCATGGCGCTCGATGGCGGGAACCTCAAAGGTTAGCCGCAATGCTAACTATTCTCCTCGTGCAGGTAGTGGGCCAAGAGGAAACAAGGCCTCTGAATGGGTGAACAGGCCAATGTACAGGAAGCCCAGGATCTACCGGACGCTGAGGACCCCCGATGTGCCCAGAGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTATGAACAGCGCCATGACATCTCACATGTCGGGAAGGTCATGTGCATCTCGGATGTGACACGTGGTAATGGCATCACCCATCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATCTTAGGGAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCGTATGGCACGCCTATGGATTTTGGTCAGGTGTTTAACATGTTCGACAACGAGCCAAGCACTGCCACGGTGAAGAACGATCTCCGCGATCGTTACCAGGTTATGCACAAGTTCTATGGCAAGGTGACTGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTCAAGAGGTTCTGGAAGGTCAACAATTATGTGGTGTACAACCACCAAGAGGCTGGCAAGTACGAGAATCACACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCATCTAACCCTGTGTATGCAACTCTGAAGATTCGGATCTATTTTTACGATTCGATTATGAATTAA |
| Protein Sequence | MPKRDLPWRSMAGTSKVSRNANYSPRAGSGPRGNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_004901694.1 |
|---|---|
| Location | 948-1346 |
| Gene Name | AC3 |
| Protein Name | replication enhancement protein |
| Coding Region | ATGGATTCACGCACAGGGGAATTCATCACTGCACGTCAGGCGGAGAATGGCGTGTATATCTGGGAGATCGAAAATCCCCTGTATTTCAAGATGTACAGAGTAGAGGACCCGTTGTACACCAGAACGAGGGTGTATCACGTACAGATACGGTTCAATCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAGATTTAGGCATTTAGTCAACATGTATTTAGATCAGTTAGGCGTCATTTCGTTAAACAATGTAATCAGAGCTGTTCGATTCGCGACAGACAGATCGTATGTAAATCATGTACTGGAAAATCATTCAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTGEFITARQAENGVYIWEIENPLYFKMYRVEDPLYTRTRVYHVQIRFNHNLRRALHLHKAYLNFQVWTTSMTASGSTYLARFRHLVNMYLDQLGVISLNNVIRAVRFATDRSYVNHVLENHSIKFKFY |
| NCBI Accession | YP_004901695.1 |
|---|---|
| Location | 1093-1482 |
| Gene Name | AC2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCGATCTTCATCACCCTCACAGCCGCCCTCTATCAAGATAGCACACAGACAGGCCAAGAAAAGGGCGATCAGGAGGCGCAGGATTGATCTCCAGTGCGGGTGCTCCATCTACTTCCACATAGACTGTACGGGACATGGATTCACGCACAGGGGAATTCATCACTGCACGTCAGGCGGAGAATGGCGTGTATATCTGGGAGATCGAAAATCCCCTGTATTTCAAGATGTACAGAGTAGAGGACCCGTTGTACACCAGAACGAGGGTGTATCACGTACAGATACGGTTCAATCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAG |
| Protein Sequence | MRSSSPSQPPSIKIAHRQAKKRAIRRRRIDLQCGCSIYFHIDCTGHGFTHRGIHHCTSGGEWRVYLGDRKSPVFQDVQSRGPVVHQNEGVSRTDTVQSQPEESVASPQSLPELPSLDDIDDSFWVNLFS |
| NCBI Accession | YP_004901696.1 |
|---|---|
| Location | 1394-2479 |
| Gene Name | AC1 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCATCGGTTAAGCGTTTTAAAGTCTCAGCCAAAAACTATTTCCTCACTTATCCACAGTGCTCTCTGTCAAAAGAAGAGGCACTTTCCCAATTACAAAACCTAGCAACTCCAGTTAACAAGAAGTTCATCAAAATTTGCAGAGAGCTTCATGAGAATGGGGAGCCTCATCTCCATGTGCTTGTACAATTCGAGGGAAAATACCAGTGCAAGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCTAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGGGAATTCCAGATCGACGGTAGAAGTGCTAGAGGAGGCTGCCAATCGACTAACGACACGTATGCCAAGGCATTGAATGCCTCTTCTGTAGAAGAGGCGCTGCAAATAATCAAGGAAGAGCAGCCTCAACATTTCTTCCTTCAACATCACAATTTAGTTGCCAATGCTCATCGGATATTTCAGAAGGCTCCGGAACCGTGGGTACCTCCGTTTCAACTCTCCTCATTCACTAACGTTCCGGACGAGATGCAAGAATGGGCCGATGAGTATTTTGGTAGGGGTTCCGCTGCGCGGCCAGATAGACCATTAAGTCTCATAGTAGAAGGTGATTCAAGAACAGGGAAGACGATGTGGGCACGTGCGTTAGGCCCACATAACTATCTCAGTGGACACCTGGACTTCAATGGTCGAGTCTATTCAAACGCGGTGGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAAAAAGATTGGCAGTCAAATTGCAAATACGGTAAGCCTGTTCAAATTAAAGGTGGAATCCCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTTCCAGCTATAAAGAGTTCCTGGACAAAGAGGAAAATGCAGGACTAAGAAACTGGACTATCAAGAATGCGATCTTCATCACCCTCACAGCCGCCCTCTATCAAGATAGCACACAGACAGGCCAAGAAAAGGGCGATCAGGAGGCGCAGGATTGA |
| Protein Sequence | MPSVKRFKVSAKNYFLTYPQCSLSKEEALSQLQNLATPVNKKFIKICRELHENGEPHLHVLVQFEGKYQCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGCQSTNDTYAKALNASSVEEALQIIKEEQPQHFFLQHHNLVANAHRIFQKAPEPWVPPFQLSSFTNVPDEMQEWADEYFGRGSAARPDRPLSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNGRVYSNAVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGSSYKEFLDKEENAGLRNWTIKNAIFITLTAALYQDSTQTGQEKGDQEAQD |
| NCBI Accession | YP_004901697.1 |
|---|---|
| Location | 2065-2322 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGGAGCCTCATCTCCATGTGCTTGTACAATTCGAGGGAAAATACCAGTGCAAGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCTAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGGGAATTCCAGATCGACGGTAGAAGTGCTAGAGGAGGCTGCCAATCGACTAACGACACGTATGCCAAGGCATTGA |
| Protein Sequence | MGSLISMCLYNSRENTSARITDSSIWSPQPGQHISIRTYRELNLAPTSSPTSTRTEIHWNGGNSRSTVEVLEEAANRLTTRMPRH |
| NCBI Accession | YP_004901698.1 |
|---|---|
| Location | 404-1174 |
| Gene Name | BV1 |
| Protein Name | nuclear shutting protein |
| Coding Region | ATGTATCCTGTTAAGAGTAAACGTGGTTCTTTTTATTACCAGCGACGATTTACGTCACGTAACACTGTGTATAACCGCTCAGCGTCTACCAAGAGACATGATGGGAAACGTCGAGGAGGTAATTCTGCTAAGCCCAACGATGAGCCCAAGATGTCAGCCCAACGCATACATGAGAATCAGTATGGGCCAGGTTATGTTATGGCCCATAATTCAGCTGTCTCGTCGTTCATCACTTATCCCAGCTTGGGCAAGTCGGACTCCAGCCGAAGCAGGTCCTATATCAAGTTGAAACGTCTCCGTTTTAAAGGGACTGTGAAGATCGAACGGGTACAATCGGAAGTGAACATGGACGGTTCCGCTCCGAAGGTCGAAGGAGTATTCTCGCTTGTTGTTGTTGTTGATCGTAAACCACACTTGGGTCCCTCTGGATGTCTGCATACATTCGACGAGCTATTCGGGGCAAGGATCAACAGTCATGGCAACCTCAGCATTGCCCCATCTCTGAAGGACCGATTCTACATAAGACACGTGTTCAAACGTGTACTGTCGGTTGAGAAGGACACGCTCATGGTGGATGTGGAAGGGTCCACATCACTCTCTAACAGGCGATACAACTGTTGGTCCACGTTTAAAGACCTTGAATGTGATTCATGCAAGGGAGTCTATGCCAACGTCAGCAAGAACGCCTTGTTAATTTATTATTGCTGGATGTCTGATACGCCTGCAAAGGCATCCTCATTTGTATCTTTCGATCTTGATTATATCGGTTAA |
| Protein Sequence | MYPVKSKRGSFYYQRRFTSRNTVYNRSASTKRHDGKRRGGNSAKPNDEPKMSAQRIHENQYGPGYVMAHNSAVSSFITYPSLGKSDSSRSRSYIKLKRLRFKGTVKIERVQSEVNMDGSAPKVEGVFSLVVVVDRKPHLGPSGCLHTFDELFGARINSHGNLSIAPSLKDRFYIRHVFKRVLSVEKDTLMVDVEGSTSLSNRRYNCWSTFKDLECDSCKGVYANVSKNALLIYYCWMSDTPAKASSFVSFDLDYIG |
| NCBI Accession | YP_004901699.1 |
|---|---|
| Location | 1236-2117 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGATTCTCAGTTAGTTAATCCTCCAAGTGCCTTCAATTACATAGAATCTCACCGGGACGAGTATCAGCTTTCCCATGACCTAACTGATATAATATTGCAATTCCCTTCCACGGCGTCTCAGTTGACAGCTAGGCTCAGCCGTAGCTGCATGAAGATCGACCACTGCGTCATTGAATATAGGCAACAGGTGCCGATCAACGCCACAGGGACGGTAATTGTGGAGATCCACGACAAAAGGATGACGGACAACGAGTCGTTACAGGCGTTATGGACATTTCCGATCAGATGCAACATAGATCTCCACTACTTCTCGGCTTCGTTCTTCTCGTTAAAGGACCCAATTCCATGGAAGTTGTACTACAGGGTGTGCGATACGAATGTTCATCAGCGGACCCACTTCGCCAAGTTCAAAGGGAAGCTGAAATTGTCCACAGCGAAACACTCCGTCGACATCCCGTTCCGGGCACCAACAGTGAAGATCTTGTCCAAACAGTTCACGGACAAAGATGTGGACTTTTCCCATGTGGGTTATGGGAAATGGGAAAGGAAGCCCATCAGATGTGCGTCCATGTCCAGACTTGGGTTACGTGGCCCAATTGAGATCAGGCCAGGTGAATCATGGGCTTCCAGGAGTACAATAGGCACGGCCCAGTCAGATGCGGACTCGGAGGTGGATAACGAACTCCATCCATACAGACATCTAAACAGGCTGGGGACCAGCGTCCTGGATCCTGGAGAGTCTGCCTCCATCGTGGGAGCCCAGAGAGCGGAGTCCAACATTACAATGTCAATGGGCCAGTTGAACGAGCTTGTTCGGACAACGGTCCAAGAATGTATCAATAGTAATTGTCAGCCTTCTCAGGCCAAATCATTGAAATAA |
| Protein Sequence | MDSQLVNPPSAFNYIESHRDEYQLSHDLTDIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDNESLQALWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVGYGKWERKPIRCASMSRLGLRGPIEIRPGESWASRSTIGTAQSDADSEVDNELHPYRHLNRLGTSVLDPGESASIVGAQRAESNITMSMGQLNELVRTTVQECINSNCQPSQAKSLK |
References More References in PubMed
| 1 |
Characterization of sida golden mottle virus isolated from Sida santaremensis Monteiro in Florida. Al-Aqeel HA, et al. Arch Virol. 2018 Oct;163(10):2907-2911. doi: 10.1007/s00705-018-3903-x. Epub 2018 Jun 21. PMID: 29931396 |
|---|---|
| 2 |
De La Torre-Almaraz R, et al. Plant Dis. 2006 Mar;90(3):378. doi: 10.1094/PD-90-0378B. PMID: 30786574 |
| 3 |
Macroptilium yellow mosaic virus, a New Begomovirus Infecting Macroptilium lathyroides in Cuba. Ramos PL, et al. Plant Dis. 2002 Sep;86(9):1049. doi: 10.1094/PDIS.2002.86.9.1049B. PMID: 30818538 |
| 4 |
Fiallo-Olivé E, et al. Arch Virol. 2012 Jan;157(1):141-6. doi: 10.1007/s00705-011-1123-8. Epub 2011 Oct 1. PMID: 21964921 |
| 5 |
Ramos PL, et al. Arch Virol. 2003 Sep;148(9):1697-712. doi: 10.1007/s00705-003-0136-3. PMID: 14505083 |
| 6 |
First Report of a Geminivirus Inducing Yellow Mottle in Okra (Abelmoschus esculentus) in Mexico. De La Torre-Almaráz R, et al. Plant Dis. 2003 Feb;87(2):202. doi: 10.1094/PDIS.2003.87.2.202B. PMID: 30812935 |
| 7 |
Two new begomoviruses infecting tomato and Hibiscus sp. in the Amazon region of Brazil. Quadros AFF, et al. Arch Virol. 2019 Jul;164(7):1897-1901. doi: 10.1007/s00705-019-04245-6. Epub 2019 Apr 10. PMID: 30972592 |
| 8 |
Complete sequence of a new bipartite begomovirus infecting Sida sp. in Northeastern Brazil. Macedo MA, et al. Arch Virol. 2020 Jan;165(1):253-256. doi: 10.1007/s00705-019-04458-9. Epub 2019 Nov 22. PMID: 31758274 |
| 9 |
Circomics of Cuban geminiviruses reveals the first alpha-satellite DNA in the Caribbean. Jeske H, et al. Virus Genes. 2014 Oct;49(2):312-24. doi: 10.1007/s11262-014-1090-8. Epub 2014 Jun 19. PMID: 24943118 |
| 10 |
A Bipartite Geminivirus Infecting Tomatoes in Cuba. Martinez Y, et al. Plant Dis. 1997 Oct;81(10):1215. doi: 10.1094/PDIS.1997.81.10.1215C. PMID: 30861720 |