Sida yellow mosaic China virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000897235.1 |
| Isolate |
China |
| Release date |
2015/2/22 |
| Submitter |
Xiong,Q., Zhou,X.P. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
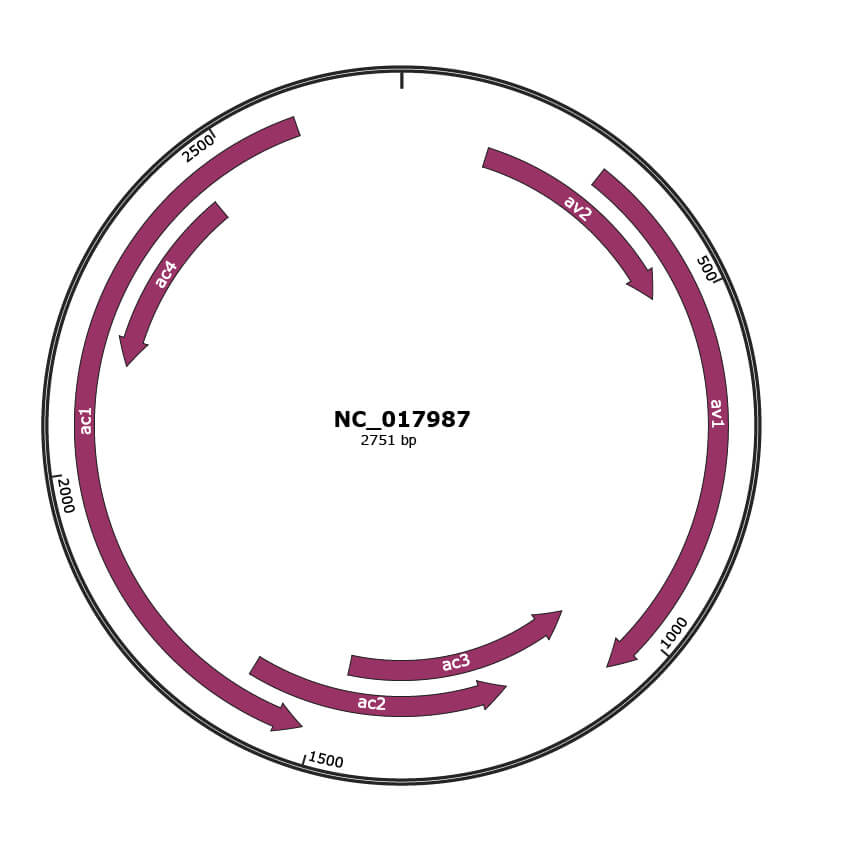
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTAGGGTGGACCCCCGCCTGCGCTTTTGTCCCCCAATCAAAACGCTCCCTCAAAACTAATTTAAAAAAAACCCGCTATAAATACTTAGTGGGCAAGTAATGAAGGAAATAAAATGTGGGATCCACTGCTGAATGAGTTTCCAGAAACCGTTCACGGTCTGCGGTGTATGCTTGCGGTTAAATACTGTCAACTATTGGAGCAGACATACGCACCTGATACGGTGGGATACGATCTTCTCCGAGATTTAATTTCAGTCATCCGATCTCGTGACTATGTCGAAGCGACCCGCCGATATAGTCATTTCAACTCCCGCATCCAAGGTACGCCGACGGCTGAACTTCGACAGCCCAGGCATGACTCGTGTTGCTGCCCCCACTGTCCTCGTCACAAATCGAAAGCGTTCGTGGACTTACAGGCCCACGAATCGCAAACCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCTCGTGGATGTGAAGGCCCGTGTAAGGTCCAATCTTATGAAGCCCGTCATGATGTAGCCCATGTAGGTAAGGTATTGTGTGTGTCCGACGTTACTCGTGGTAATGGGCTGACTCATCGTGTTGGTAAGAGGTTCTGTATCAAGTCGATTTACGTTCTGGGTAAGGTCTGGATGGATGAGAACATTAAGAAGAAAAATCACACTAACACTGTTATGTTTTTTTTAGTTCGTGATCGGAGACCGTTTGGGACTCCTCAAGATTTCGGTCAGGTGTTTAGTATGTATGATAATGAGCCTAGTACTGCCACTGTGAAGAACGATAATAGAGATCGTTTCCAGGTATTGCGTCGATTTCAGGCAACGGTCACTGGTGGAGACTATGCGTGTAAGGAGCAAGCTTTAGTTAGGAAGTTTATGAAAGTTAACAATCATGTCACCTATAATCATCAGGAGGCAGCGAAGTATGACAATCATACTGAGAATGCGTTGTTGTTGTATATGGCATGTACTCATGCCAGTAACCCTGTGTATGCTACTTTGAAAATCAGGATCTACTTCTATGATTCTGTTCAGAATTAATAAAGTTTGAATTTTATTATATATGAAAACTGGGCCTCAATAGTGCCTTCGAGTTTATCCCACAATACATGATTAATTGCTCTAATTACATTATTAATACTAATCACTCCCAATCGGTCTAGATATTTCATACATTGGTATTTAAATACTCTTAAGAAACGCCAGGTCTGAGGATGTAAACGAGTCCAGATTCGGCAGATTAGAAAACATTTGTGTATCCCCAACGCTTTCCTCAGGTTGTAATTGAACTGGACTTGGACTGTGATGACGTCGTGGTTCGTCGAGAACGGTCTCTCGTGGTGCTGGGTTATCTTGAAATACAGGGGATTGTTGACCGTCCAGATATATACGCCATTCTCTGCCTGAGTTGCAGTGATGGGTTCCCCGGTGCGAAAATCCATGGTTTGCGCAATTGAGCCCAAAATAATAAGAGCAGCCGCAGGGTAGATCAACGCGACGTCTCCGAATGGGCCTCTTCTTGGCTTCCCTGTGTTGGACTTTGATGGGAACCGGAATAGAGTGGCACTTCGAGGGTGACAAAGGTCGCATTTTTTAAAGCCCAATTTTTGAGTGCGGAGTTCTTTTCCTCATCCAAGTACTCTTTATAGCTGGAATTTGGTCCTGGATTGCAGAGGAAGATTGTTGGTATCCCGCCTTTAATTTGAACTGGCTTCCCGTACTTTGTGTTTGATTGCCAGTCCCTTTGGGCACCCATGAACTCCTTAAAGTGCTTTAGGTAATGCGGGTCTACGTCATCAATGACGTTATACCACGCCTCATTACTGTATATCTTTGGACTCAGATCCAGGTGTCCACATAAATAGTTATGTGGTCCTAATGATCTGGCCCACATTGTTTTACCTGTGCGACTATCTCCCTCTATCACTATACTGAGAGGTCTCAAAGGCCGCGCAGCGGCAGCCACCACGTTCTCCGCCGCCCACTCTTCGAGTTCGTCCGGAACTCGATCAAAAGAAGAAGAAGAAAAAGGCGAAACATAAACCCCCATCGGAGGTGTAAAAATCCTATCTAAATTAGCGTTTAAATTATGAAATTGTAAAACATAATCTTTAGGAGCTAACTCCTTTATTACATTAAGAGCCTCCGACTTACTTCCGCTGTTAAGTGCCTGGGCGTAAGCGTCGTTGGCTGATTGTTGACCCCCTCTAGCAGATCTTCCGTCGACCTGAAACTCTCCCCAGTCGAGGGTGTCTCCGTCCTTGTCGATATAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTTGGATGGAAATGTACTGACCGGGTTGGGGATACCAGATCGAAGAATCTGTTATTTTGGCACTTGTATTTTCCCTCGAACTGAATGAGCACGTGGAGATGAGGGCTCCCATCTTCGTGAAGCTCTCTGCAGATTTTGATGAATTTTTTGTTTGTTGGGGTTTTGAGGTTTTGTAATTGGGAAAGTGTCTCTTCTTTGGTGAGAGAGCATTGGGGATAAGTAAGAAAGAAATTTTTGGCATTTATTAAAAACCGTTTTGGGGGTGCCATTTGACTTGGTCAATTGGGTCTCAAAAAACTTGCTCATGCAATCGGGGAATGGGTCTCAATATATAGTAGAGGACCTTAATGGCATAATTGTAAATAGCAAAAAGAAATTCAAATTCAAAATCCCAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_006390084.1
|
|
Location
|
134-484 |
|
Gene Name
|
av2 |
|
Protein Name
|
putative AV2 protein |
|
Coding Region
|
ATGTGGGATCCACTGCTGAATGAGTTTCCAGAAACCGTTCACGGTCTGCGGTGTATGCTTGCGGTTAAATACTGTCAACTATTGGAGCAGACATACGCACCTGATACGGTGGGATACGATCTTCTCCGAGATTTAATTTCAGTCATCCGATCTCGTGACTATGTCGAAGCGACCCGCCGATATAGTCATTTCAACTCCCGCATCCAAGGTACGCCGACGGCTGAACTTCGACAGCCCAGGCATGACTCGTGTTGCTGCCCCCACTGTCCTCGTCACAAATCGAAAGCGTTCGTGGACTTACAGGCCCACGAATCGCAAACCCAGAATGTACAGGATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGLRCMLAVKYCQLLEQTYAPDTVGYDLLRDLISVIRSRDYVEATRRYSHFNSRIQGTPTAELRQPRHDSCCCPHCPRHKSKAFVDLQAHESQTQNVQDVQKP |
|
NCBI Accession
|
YP_006390085.1
|
|
Location
|
294-1067 |
|
Gene Name
|
av1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCCGCCGATATAGTCATTTCAACTCCCGCATCCAAGGTACGCCGACGGCTGAACTTCGACAGCCCAGGCATGACTCGTGTTGCTGCCCCCACTGTCCTCGTCACAAATCGAAAGCGTTCGTGGACTTACAGGCCCACGAATCGCAAACCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCTCGTGGATGTGAAGGCCCGTGTAAGGTCCAATCTTATGAAGCCCGTCATGATGTAGCCCATGTAGGTAAGGTATTGTGTGTGTCCGACGTTACTCGTGGTAATGGGCTGACTCATCGTGTTGGTAAGAGGTTCTGTATCAAGTCGATTTACGTTCTGGGTAAGGTCTGGATGGATGAGAACATTAAGAAGAAAAATCACACTAACACTGTTATGTTTTTTTTAGTTCGTGATCGGAGACCGTTTGGGACTCCTCAAGATTTCGGTCAGGTGTTTAGTATGTATGATAATGAGCCTAGTACTGCCACTGTGAAGAACGATAATAGAGATCGTTTCCAGGTATTGCGTCGATTTCAGGCAACGGTCACTGGTGGAGACTATGCGTGTAAGGAGCAAGCTTTAGTTAGGAAGTTTATGAAAGTTAACAATCATGTCACCTATAATCATCAGGAGGCAGCGAAGTATGACAATCATACTGAGAATGCGTTGTTGTTGTATATGGCATGTACTCATGCCAGTAACCCTGTGTATGCTACTTTGAAAATCAGGATCTACTTCTATGATTCTGTTCAGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPGMTRVAAPTVLVTNRKRSWTYRPTNRKPRMYRMYRSPDVPRGCEGPCKVQSYEARHDVAHVGKVLCVSDVTRGNGLTHRVGKRFCIKSIYVLGKVWMDENIKKKNHTNTVMFFLVRDRRPFGTPQDFGQVFSMYDNEPSTATVKNDNRDRFQVLRRFQATVTGGDYACKEQALVRKFMKVNNHVTYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSVQN |
|
NCBI Accession
|
YP_006390086.1
|
|
Location
|
1064-1468 |
|
Gene Name
|
ac3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTTTCGCACCGGGGAACCCATCACTGCAACTCAGGCAGAGAATGGCGTATATATCTGGACGGTCAACAATCCCCTGTATTTCAAGATAACCCAGCACCACGAGAGACCGTTCTCGACGAACCACGACGTCATCACAGTCCAAGTCCAGTTCAATTACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAATCTGCCGAATCTGGACTCGTTTACATCCTCAGACCTGGCGTTTCTTAAGAGTATTTAAATACCAATGTATGAAATATCTAGACCGATTGGGAGTGATTAGTATTAATAATGTAATTAGAGCAATTAATCATGTATTGTGGGATAAACTCGAAGGCACTATTGAGGCCCAGTTTTCATATATAATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDFRTGEPITATQAENGVYIWTVNNPLYFKITQHHERPFSTNHDVITVQVQFNYNLRKALGIHKCFLICRIWTRLHPQTWRFLRVFKYQCMKYLDRLGVISINNVIRAINHVLWDKLEGTIEAQFSYIIKFKLY |
|
NCBI Accession
|
YP_006390087.1
|
|
Location
|
1209-1616 |
|
Gene Name
|
ac2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGACCTTTGTCACCCTCGAAGTGCCACTCTATTCCGGTTCCCATCAAAGTCCAACACAGGGAAGCCAAGAAGAGGCCCATTCGGAGACGTCGCGTTGATCTACCCTGCGGCTGCTCTTATTATTTTGGGCTCAATTGCGCAAACCATGGATTTTCGCACCGGGGAACCCATCACTGCAACTCAGGCAGAGAATGGCGTATATATCTGGACGGTCAACAATCCCCTGTATTTCAAGATAACCCAGCACCACGAGAGACCGTTCTCGACGAACCACGACGTCATCACAGTCCAAGTCCAGTTCAATTACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAATCTGCCGAATCTGGACTCGTTTACATCCTCAGACCTGGCGTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MRPLSPSKCHSIPVPIKVQHREAKKRPIRRRRVDLPCGCSYYFGLNCANHGFSHRGTHHCNSGREWRIYLDGQQSPVFQDNPAPRETVLDEPRRHHSPSPVQLQPEESVGDTQMFSNLPNLDSFTSSDLAFLKSI |
|
NCBI Accession
|
YP_006390088.1
|
|
Location
|
1516-2604 |
|
Gene Name
|
ac1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGGCACCCCCAAAACGGTTTTTAATAAATGCCAAAAATTTCTTTCTTACTTATCCCCAATGCTCTCTCACCAAAGAAGAGACACTTTCCCAATTACAAAACCTCAAAACCCCAACAAACAAAAAATTCATCAAAATCTGCAGAGAGCTTCACGAAGATGGGAGCCCTCATCTCCACGTGCTCATTCAGTTCGAGGGAAAATACAAGTGCCAAAATAACAGATTCTTCGATCTGGTATCCCCAACCCGGTCAGTACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGACACCCTCGACTGGGGAGAGTTTCAGGTCGACGGAAGATCTGCTAGAGGGGGTCAACAATCAGCCAACGACGCTTACGCCCAGGCACTTAACAGCGGAAGTAAGTCGGAGGCTCTTAATGTAATAAAGGAGTTAGCTCCTAAAGATTATGTTTTACAATTTCATAATTTAAACGCTAATTTAGATAGGATTTTTACACCTCCGATGGGGGTTTATGTTTCGCCTTTTTCTTCTTCTTCTTTTGATCGAGTTCCGGACGAACTCGAAGAGTGGGCGGCGGAGAACGTGGTGGCTGCCGCTGCGCGGCCTTTGAGACCTCTCAGTATAGTGATAGAGGGAGATAGTCGCACAGGTAAAACAATGTGGGCCAGATCATTAGGACCACATAACTATTTATGTGGACACCTGGATCTGAGTCCAAAGATATACAGTAATGAGGCGTGGTATAACGTCATTGATGACGTAGACCCGCATTACCTAAAGCACTTTAAGGAGTTCATGGGTGCCCAAAGGGACTGGCAATCAAACACAAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGGATACCAACAATCTTCCTCTGCAATCCAGGACCAAATTCCAGCTATAAAGAGTACTTGGATGAGGAAAAGAACTCCGCACTCAAAAATTGGGCTTTAAAAAATGCGACCTTTGTCACCCTCGAAGTGCCACTCTATTCCGGTTCCCATCAAAGTCCAACACAGGGAAGCCAAGAAGAGGCCCATTCGGAGACGTCGCGTTGA |
|
Protein Sequence
|
MAPPKRFLINAKNFFLTYPQCSLTKEETLSQLQNLKTPTNKKFIKICRELHEDGSPHLHVLIQFEGKYKCQNNRFFDLVSPTRSVHFHPNIQGAKSSSDVKSYIDKDGDTLDWGEFQVDGRSARGGQQSANDAYAQALNSGSKSEALNVIKELAPKDYVLQFHNLNANLDRIFTPPMGVYVSPFSSSSFDRVPDELEEWAAENVVAAAARPLRPLSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKIYSNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEYLDEEKNSALKNWALKNATFVTLEVPLYSGSHQSPTQGSQEEAHSETSR |
|
NCBI Accession
|
YP_006390089.1
|
|
Location
|
2157-2447 |
|
Gene Name
|
ac4 |
|
Protein Name
|
putative AC4 protein |
|
Coding Region
|
ATGGGAGCCCTCATCTCCACGTGCTCATTCAGTTCGAGGGAAAATACAAGTGCCAAAATAACAGATTCTTCGATCTGGTATCCCCAACCCGGTCAGTACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATATCGACAAGGACGGAGACACCCTCGACTGGGGAGAGTTTCAGGTCGACGGAAGATCTGCTAGAGGGGGTCAACAATCAGCCAACGACGCTTACGCCCAGGCACTTAACAGCGGAAGTAAGTCGGAGGCTCTTAATGTAA |
|
Protein Sequence
|
MGALISTCSFSSRENTSAKITDSSIWYPQPGQYISIQTFRELNPAPTSSPISTRTETPSTGESFRSTEDLLEGVNNQPTTLTPRHLTAEVSRRLLM |