Sida yellow golden mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_018582795.1 |
| Isolate | Brazil |
| Release date | 2021/6/1 |
| Submitter | Macedo,M., Moraes,C., Gilbertson,R., Inoue Nagata,A. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
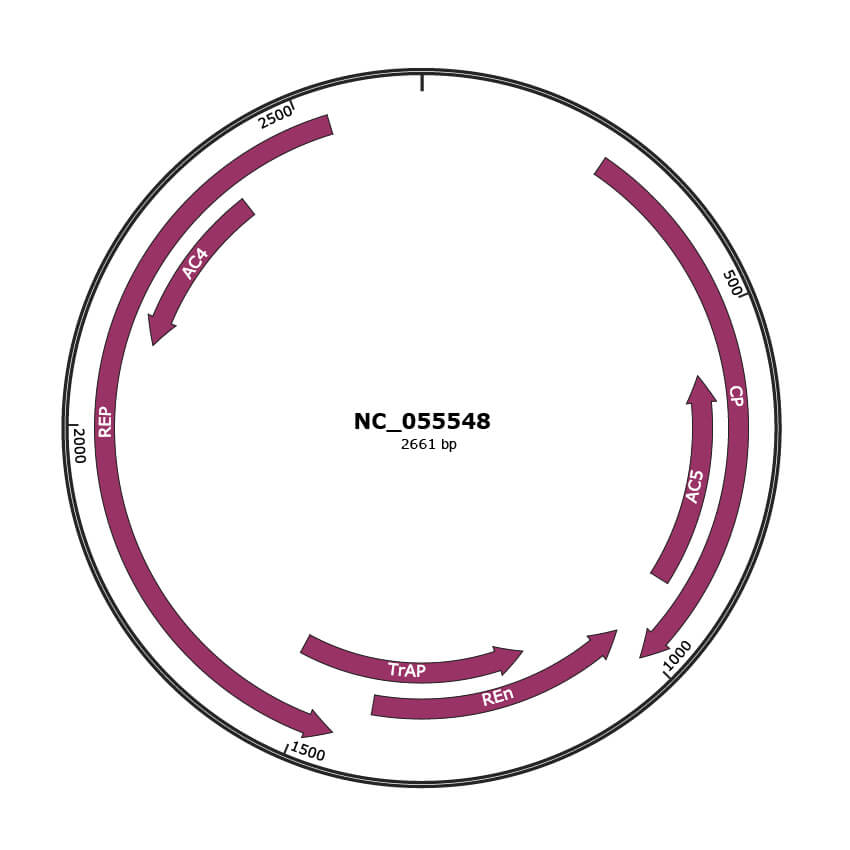
JBrowse
Genome
NC_055548
Gene Information
| NCBI Accession | YP_010087357.1 |
|---|---|
| Location | 254-1009 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCGTGGCGACTTATGGCTGGTACCTCAAAGGTAAGCCGTTCTTCCAATTCTGGGCCTCGTGGGAGTTCTGGGCCTAAATACAGCAAGTCAGCGGAATGGGTTAACAGGCCTATGTACAGAAAGCCCAGGATCTATCGAGCCTACAGAACTCCCGATGTCCCTCGAGGGTGCGAAGGACCTTGCAAGGTCCAGTCCTATGAACAGCGGCACGACATCTCACATGTCGGCAAGGTCATGTGTATATCTGACGTCACCCGAGGTAATGGCATTACTCATCGTGTTGGTAAGCGTTTTTGTGTTAAGTCTGTATATATTTTAGGCAAGATTTGGATGGACGAGAATATCAAGCTCAAGAACCACACAAACAGCGTTATGTTCTGGCTGGTCAGAGATCGTAGACCCTATGGCACACCTATGGACTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCTAGCACTGCAACTGTTAAGAACGATCTCCGTGACCGTTACCAGGTAATGCACAAGTTCTACGGCAAGGTGACAGGTGGCCAATATGCCAGCAATGAACAGGCGATAGTCAAACGCTTCTGGAAGGTCAACAATCATGTGGTGTACAACCACCAAGAAGCTGGCAAGTACGAGAATCATACGGAGAACGCATTACTACTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTCAAGATTCGAATCTATTTTTACGATTCGATTATGAATTAA |
| Protein Sequence | MPKRDAPWRLMAGTSKVSRSSNSGPRGSSGPKYSKSAEWVNRPMYRKPRIYRAYRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_010087358.1 |
|---|---|
| Location | 587-904 |
| Gene Name | AC5 |
| Protein Name | AC5 |
| Coding Region | ATGATTCTCGTACTTGCCAGCTTCTTGGTGGTTGTACACCACATGATTGTTGACCTTCCAGAAGCGTTTGACTATCGCCTGTTCATTGCTGGCATATTGGCCACCTGTCACCTTGCCGTAGAACTTGTGCATTACCTGGTAACGGTCACGGAGATCGTTCTTAACAGTTGCAGTGCTAGGCTCGTTGTCGAACATGTTGAACACCTGGCCAAAGTCCATAGGTGTGCCATAGGGTCTACGATCTCTGACCAGCCAGAACATAACGCTGTTTGTGTGGTTCTTGAGCTTGATATTCTCGTCCATCCAAATCTTGCCTAA |
| Protein Sequence | MILVLASFLVVVHHMIVDLPEAFDYRLFIAGILATCHLAVELVHYLVTVTEIVLNSCSARLVVEHVEHLAKVHRCAIGSTISDQPEHNAVCVVLELDILVHPNLA |
| NCBI Accession | YP_010087359.1 |
|---|---|
| Location | 1006-1404 |
| Gene Name | REn |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAGGATATACAGGGTCGAGGACATGCTGTACACGACGACACGTGTGTACCACGTGCAGATACGGTTCAACCACAACCTCAGGAAAGCACTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACTTCTCTGAGAGCTTCTGGAACGACTTATTTGACTAGGTTCCAGGATTTAGTTATGCTGTATTTAGATAGATTAGGCGTTATTTGTCTTAACAATGTAATTAGAGCTGTTCGTTTCGCAACGGACAAAAAATATGTGAGCCATGTGCTGGAAAATCATTCAATAAAATTTAAATTTTATTAA |
| Protein Sequence | MDSRTGELITARQAENGVYIWEITNPLYFRIYRVEDMLYTTTRVYHVQIRFNHNLRKALGLHKAFLNFQVWTTSLRASGTTYLTRFQDLVMLYLDRLGVICLNNVIRAVRFATDKKYVSHVLENHSIKFKFY |
| NCBI Accession | YP_010087360.1 |
|---|---|
| Location | 1151-1540 |
| Gene Name | TrAP |
| Protein Name | trans-activating protein |
| Coding Region | ATGCTAAATTCTTCTTCCTCGACGCCCCCCTCTATCAAAGCGAAACACAGGATTACCAAGAAGAGGGCCATCAGGAGGCGGCGAATTGACTTGGACTGCGGCTGCTCCATTTACGTCCACATAGCTTGCACCGGGCATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAGGATATACAGGGTCGAGGACATGCTGTACACGACGACACGTGTGTACCACGTGCAGATACGGTTCAACCACAACCTCAGGAAAGCACTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACTTCTCTGAGAGCTTCTGGAACGACTTATTTGACTAG |
| Protein Sequence | MLNSSSSTPPSIKAKHRITKKRAIRRRRIDLDCGCSIYVHIACTGHGFTHRGAHHCTSGREWRLYLGDNKSPVFQDIQGRGHAVHDDTCVPRADTVQPQPQESTGSPQGIPELPSLDDFSESFWNDLFD |
| NCBI Accession | YP_010087361.1 |
|---|---|
| Location | 1452-2537 |
| Gene Name | REP |
| Protein Name | replication associated protein |
| Coding Region | ATGCCACGGAAGGGTTCTTTCTCTATTAAAGCCAAAAATTATTTCCTCACTTATCCACAATGCTCTCTGGCCAAAGAAGAAGCCCTAGAACAAATTAGGAATATTCCGACGCCGACGAACAAGAAGTTCGTTAAAATCGCCAGAGAGCTTCACGAAGATGGGCAGCCACATCTCCACGTGCTTATCCAGTTCGAAGGGAAGTTTAACTGCACAAATAGCAGACTGTTCGACCTGGTCTCCCCAAGTAGGTCAACACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATGTCGAGAAGGATGGAGACACAGTCGAATGGGGGCAGTTCCAGATCGACGGCCGAAGTGCTAGAGGCGGTCAGCAAACAGCTAACGACGCAGCCGCCGAGGCGTTGAACGCAGCGTCGAAGGAGGAGGCTTTGAAGATCATCAAAGAGAAGTTGCCGGAAAAGTTCCTGTTCCAGTACCACAACTTGACGAGCAACCTGGACAAGATCTTCAAAAAGCCTTCCGAACCGTGGGTCCCTCCGTTTCCCCTGTCGTCGTTCACTAACGTTCCAGATGAGTTGCAAGAGTGGGCTGATGATTATTTTGGGAGAGGTTCCGCTGCGCGGCCCATCAGGCCTGTTAGTATAATTGTTGAAGGTGATAGTAGAACGGGGAAAACGATGTGGGCTCGTGCTTTAGGGGCCCATAACTATCTAAGTGGACACCTGGACTTCAATTCCAGGGTGTATTCAAATGACGTCGAGTATAACGTCATTGATGACGTTAGTCCGCAATATCTAAAGCTAAAGCACTGGAAAGAATTGATGGGTGCTCAAAAAGACTGGCAGTCAAATTGTAAATATGGAAAGCCGGTTCAAATTAAAGGCGGTATCCCATCAATCGTGCTCTGCAATCCTGGAGAGGGGGCCAGCTATAAAGATTTCCTCGAGAAAGAGGAAAACTCATCACTCAGAGCCTGGACATTAAAAAATGCTAAATTCTTCTTCCTCGACGCCCCCCTCTATCAAAGCGAAACACAGGATTACCAAGAAGAGGGCCATCAGGAGGCGGCGAATTGA |
| Protein Sequence | MPRKGSFSIKAKNYFLTYPQCSLAKEEALEQIRNIPTPTNKKFVKIARELHEDGQPHLHVLIQFEGKFNCTNSRLFDLVSPSRSTHFHPNIQGAKSSSDVKSYVEKDGDTVEWGQFQIDGRSARGGQQTANDAAAEALNAASKEEALKIIKEKLPEKFLFQYHNLTSNLDKIFKKPSEPWVPPFPLSSFTNVPDELQEWADDYFGRGSAARPIRPVSIIVEGDSRTGKTMWARALGAHNYLSGHLDFNSRVYSNDVEYNVIDDVSPQYLKLKHWKELMGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLEKEENSSLRAWTLKNAKFFFLDAPLYQSETQDYQEEGHQEAAN |
| NCBI Accession | YP_010087362.1 |
|---|---|
| Location | 2123-2380 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGCAGCCACATCTCCACGTGCTTATCCAGTTCGAAGGGAAGTTTAACTGCACAAATAGCAGACTGTTCGACCTGGTCTCCCCAAGTAGGTCAACACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTATGTCGAGAAGGATGGAGACACAGTCGAATGGGGGCAGTTCCAGATCGACGGCCGAAGTGCTAGAGGCGGTCAGCAAACAGCTAACGACGCAGCCGCCGAGGCGTTGA |
| Protein Sequence | MGSHISTCLSSSKGSLTAQIADCSTWSPQVGQHISIRTYRELNPAPTSSPMSRRMETQSNGGSSRSTAEVLEAVSKQLTTQPPRR |
References More References in PubMed
| 1 |
Macroptilium yellow mosaic virus, a New Begomovirus Infecting Macroptilium lathyroides in Cuba. Ramos PL, et al. Plant Dis. 2002 Sep;86(9):1049. doi: 10.1094/PDIS.2002.86.9.1049B. PMID: 30818538 |
|---|---|
| 2 |
Characterization of sida golden mottle virus isolated from Sida santaremensis Monteiro in Florida. Al-Aqeel HA, et al. Arch Virol. 2018 Oct;163(10):2907-2911. doi: 10.1007/s00705-018-3903-x. Epub 2018 Jun 21. PMID: 29931396 |
| 3 |
Croton golden mosaic virus: a new bipartite begomovirus isolated from Croton hirtus in Colombia. Vaca-Vaca JC, et al. Arch Virol. 2018 Nov;163(11):3199-3202. doi: 10.1007/s00705-018-3989-1. Epub 2018 Aug 10. PMID: 30097742 |
| 4 |
First report of the complete sequence of Sida golden yellow vein virus from Jamaica. Stewart CS, et al. Arch Virol. 2011 Aug;156(8):1481-4. doi: 10.1007/s00705-011-1030-z. Epub 2011 May 29. PMID: 21625977 |
| 5 |
De La Torre-Almaraz R, et al. Plant Dis. 2006 Mar;90(3):378. doi: 10.1094/PD-90-0378B. PMID: 30786574 |
| 6 |
Collins AM, et al. Virus Genes. 2009 Dec;39(3):387-95. doi: 10.1007/s11262-009-0401-y. Epub 2009 Sep 20. PMID: 19768650 |
| 7 |
First Report of Okra yellow mosaic Mexico virus in Okra in the United States. Hernandez-Zepeda C, et al. Plant Dis. 2010 Jul;94(7):924. doi: 10.1094/PDIS-94-7-0924B. PMID: 30743573 |
| 8 |
Bornancini VA, et al. Viruses. 2020 Feb 11;12(2):202. doi: 10.3390/v12020202. PMID: 32054104 |
| 9 |
Gautam S, et al. Viruses. 2022 May 20;14(5):1104. doi: 10.3390/v14051104. PMID: 35632844 |
| 10 |
Mugerwa H, et al. Cells. 2022 Jun 29;11(13):2060. doi: 10.3390/cells11132060. PMID: 35805143 |