Sida mosaic Bolivia virus 1
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000893095.1 |
| Isolate |
Bolivia |
| Release date |
2015/2/22 |
| Submitter |
Wyant,P.S., Gotthardt,D., Schafer,B., Krenz,B., Jeske,H. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
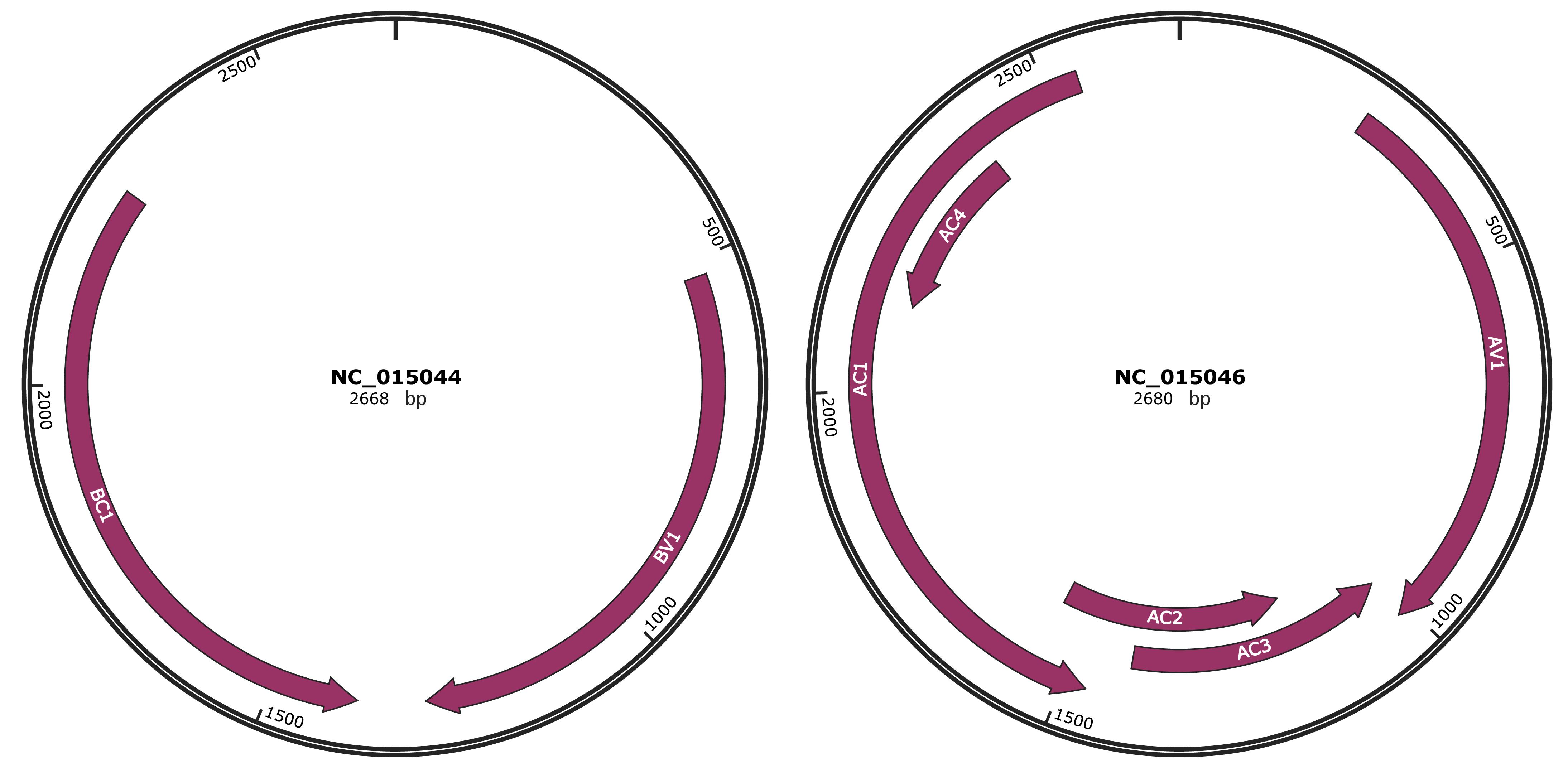
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTCCCCCCCCCCTACGTGGCGCTCTGGTGGCCGCTCGATTTCCCTTCCTCCGCACGTGTCTAGTTGCTGCTCGCGCGATTTCCCCCTTGCTGAATTTAGTTTAGCGCTTTTTTCACGTCCGCGAAATGGGTTAACCGCATTTTTTGAGTTCCGCCAGTACAGTCAGTCACTTTAATTCAAATTAAAGTGGAACTATTTAGTTTAGCCAATCATTTTGCTTCTTTGGAGTTTATTTAATTTTTATGGTACTTGGCGCCGAAGTTGTTGACCGACCGTTGGAAATTTAACATGTATTGGTTTAACGTAATCTGAATTTGGAATTAAATGGGCCTGTGGATTGGGTCAATCGTACAATAACTATGAACTGGACCAGTTAAATTTCTCCTGTGGCGTCTATATAACTTGCAATTGTTTTACGGAGTTGTCTATTTAAGTTATATGTTGTTCGATCTGGATATCACGACTATTGGCTTAGAATAGTCTTATTGTCACATATTTTGAACATGTTCCCTTTGAAATACAGACGTGGCTCGTTGACTAGCAATCGTCGAAGTTATACAGGGACTCCGGTGTTTAGACGTCCATATGCTGGTAAACGGTCTGCTTGGAAACGTCGACCGACAAGTGCACCCAAAGCACATGAAGAGAAGAAACTTTCAGCTCAGCGTATTCATGAGAATCAGTTTGGGCCGGAATTTGTCATGGCCCATAATTCAGCCATATCGACCTTCATCACCTTTCCTGAGCTTGGTAAGACGGAGCCCAATAGGTCTAGGTCATATATTAAGTTGAAACGTTTACGTTTCAAAGGAACAGTCAAGATTGAACGTGTGCATGCCGACGTGAACATGGATGGTTCATTGCCGAAGATTGAAGGAGTCTTCTCCCTCGTTGTGGTGGTCGATCGGAAACCCCATTTGAGTCAATCTGGCTGCCTCCATACATTCGACGAGCTCTTTGGTGCACGGATTCATAGCCATGGTAATTTGGCCATTACTCCCTCTTTGAAGGACCGCTTTTACATACGGCACGTGTTGAAGCGGGTTTTGTCAGTCGAGAAGGATTCCTTGATGGTGGATCTGGAGGGAACGACCGCATTATCTAATAGGCGTTTTAACTGCTGGTCCTCGTTTAAGGACCTTGACCGTGATACATGTAACGGGGTTTATGCTAACATAGGCAAGAACGCCCTCCTAGTTTATTACTGTTGGATGTCGGATACCATGTCCAAGGCGTCGACATTTGTATCGTTTGACCTTGATTATATTGGTTGAATAATAAGAATATTTGCTTTATTTGAATTATTTAATTCCCAATTAAATAGAACATTCTCTCTTGCAAAAAAAGAATTAAAGAACTTGCTATCTATTGCAACGATTTGGGCTGTGAAGGAGTGCAGTTTGTTTTAATGCACTCTTGGACCGTCGTTCTCACAAGCTCGTTCAATTGGGCCACTGACATCGTTATGTTGGACTGTGCCCTCTGGGCCCCAACTATCGAAGCAGATTCACCCGGGTCTAAGATGGTGGTGCCCAATCTGTTGAGCTCTCGGTACGGATGTTGGGCCTCTCCCATTTCCGATTCCGCATCTGAATTGCTAGGGCCTATGGTGCTCCTGGCAGCCCACGACTCTCCGGGCCTAATTTCTATTGGGCCGGGAAGCCCAATTCTAGATATGGATGCGGATCTGACCATCCTCCTCTCCCACTTGCCGTACCCCACGTGGCAGAAATCTATGTCCTTATCGGTGAACTGTTTGGATAAGATCTTGACCGTCGGAGCTCGGAAGGGGATATCAACGGAATGTTTCGCCGTTGACAGCTTGAGTTTGCCTTTGAACTTGGCGAAATGCGTCCTTTGGTGTACATTCGAGTCGCAAACCTTGTAATACAGTTTCCATGGGATTGGGTCTTTGAGCGAGAAGAACGATGACGAGAAATAGTGGAGATCTATGTTGCACCTGATCGGAAACGTCCACGCCGCCTGCAAGGATTCGTTGTCCGTCATCCTCTTGTCATGGATCTCCACCACTACGGATCCCGTGGCGTTGATCGGTACCTGTTGCCTGTATTCTATGACGCAGTGGTCGATTTTCATACAGCTACGACTGAGTCTTGCGCTTAATTGAGACGCCGTCGACGGGAATTGCAGAACGATCTCCGTTAGATCATGAGACAGCTGATATTCGTCACGGTGAGATTCTATATAATTAAATGCGTTCGGAGGATGCATCAACTGAGATTCCATTATAGAAATAAGGTCGCGCAGCGACAGCGTCTGGGTGAAGAGAACCGGCAAGAGAATATTTGAAGGAAAGTCTTTGGTTAAATTGTAACAGGCTGAGAATATTGCTGAGAGATGTGATTTACTGAGATTAATTGGTGTGCTGTTTATATGGACATTTAACAGGGAAAATGCGTAATTTATCTAAACATTCTTCCCTGTTCATCAGTGGAATATTGTTCTCTTTCTTTGGTAAGTGGCATTTTGGGAAAAGAACCCTTCCGTGGCATTTTTGTAAATAAGGCCGTGTACCCCCGATTGTTCTGGCTCTCAAACCTCTCATGAATTGGGGGTACTGGGGGTACATTAATACCTATGAGTTCCATAAGCTCCAAAGGGGCACGTGGCGGCCATCCGAATAATATT
ACCGGATGGCCGCGCGATTTTCTCCCCCCCCCTACGTGGCGCTCTGGTGTCCGTGCGATTTCCCCCTCCCCGACCCGCTCCCGCAAATCGCGCCGCATTGTCGGCCATTATGTGTGGTCCCAGTCAGTAAACGACAAATTTAATGGCCCAATAAAATTGGGCCCTCAGCGCTTATTTAATTTGAAAATACTTGGGCGCTAAGTTGTTAGGCTTTATAAATGGATCCCATGTCATGTGGGCTCACCAGGCTTTAATTCAGAATGTCGAAGCGGGAAGCCCCTTGGCGTTCGATGGCGGGAACTTCCAAAGTGAGCCGGTCTCTCAATTTTTCCCCTCGTGGTGGTGTGGGCTCAAGGTCCAACAAGGCCAGCGCTTGGGTGAACAGGCCCATGTACAGGAAGCCCAAGTTTTATCGGGTTTTTAGATCCCCCGATGTTCCCAAAGGGTGTGAAGGCCCATGCAAGGTCCAGTCATATGAGCAGCGTCATGACATCTCTCATACCGGCAAGGTGATGTGTATATCTGATGTCACACGTGGCAGTGGTATAACCCACCGTGTTGGTAAGCGTTTCTGCGTTAAGTCTGTTTACATTTTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACCAACAGTGTCATGTTCTGGCTGGTCAGAGATCGTAGACCGACCGGTACTCCTATGGATTTTGGCCATTTGTTCAACATGTTCGACAACGAGCCTAGCACAGCTACGATCAAGAACGATCTCCGCGATCGTTTCCAGGTTTTGCACAGGTTTCACGCCAAGGTCACAGGTGGACAGTATGCGAGCAACGAGCAGGCCCTGGTCAAACGTTTCTGGAAGGTCAACAACCATGTGGTGTACAACAACCAGGAAGCCGCTAGATACGAGAATCATACGGAGAACGCTTTGATGTTATACATGGCATGTACTCATGCCTCTAACCCCGTGTATGCTACGTTAAAAATTCGGATCTATTTTTACGATTCGATAACAAATTAATAAATTTTGAATTTTATTGAATGCTTTTCGAGTACATGGTTTACATAGGATCTGTCTGTTGCGAAACGAACAGCTCTAATTACATTGTTAATGCAAATAACCCCTAGTCGATCTAGGTACAAGGAAACTAAATATTTAAATCTATTTAAATAACTCCTCCCAGAAGCTGTCGTCAATGTCGTCCAAACTTGGAAATTGAGAAATGCCTTGTGGAGATCCAATGCTTTCCTCAGGTTGTGGTTGAACCGGATTTGGATGTGGTAGATCCTCGTGTTGGTGTAGATTATGTCCTCTACGCTGGTTATCTTGAAATACAGGGGATTTGTTACCTCCCAGATATAGACGCCACTCTCTGCTTGATGCGCAGTGATGATTTCCCCTGTGCGTGAATCCATGGTTGCTGCAGTTGATGTGGACGTATATTGAGCAGCCGCAGTTAAGATCGATCCGTCTACGGCGAGTTGCCCTGCGTTTCGCCGCCCTGTGTTGAGGTTTGATAGAGGGGGGCGTCGAGGAAGATGAATTTCGCATTATGAAGGGTCCAGTTTTTGAGCGATGCGTTTTCCTCTTTGTCGAGGAAATCTTTATAGCTGGCCCCTTCACCTGGATTGCAGAGCACGATTGATGGGATCCCGCCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGACTGCCAGTCTTTTTGGGCCCCAATTAGCTCTTTCCAGTGCTTCATCTTTAGATATTGCGGACTGACATCATCGATGACGTTGTACTCCGCTTTATTCGAGTAAACCCTAGAATTGAAGTCCAGGTGTCCGCTCAAATAATTATGTGGGCCTAACGCACGAGCCCACATCGTCTTCCCCGTCCGACTATCACCCTCGACGATCAAACTGATAGGTCTCTCCGGCCGCGCAGCGGCACCCCTCCCAAAATAATCATCGGCCCATTCTTGCATCTCGTCCGGGACGGCAGTGAAGGAGGAGAGTTGAAACGGAGGAACCCACGGCTCCGGAGCCTTCGAGAAAATCCGATCTAAATTGCTATTTAGATTATGAAATTGAAATAAATATTTCTCCGGCAATTTCTCTCTGACTATTTGGAGCGCCGCTTCTTTTGAAGGGGCGTTTAAAGCCTCTGCGGCAACGTCGTTAGCTGTTTGGCAACCTCCTCTAGCACTTCTCCCGTCGATCTGGAATTCTCCCCATTCGAGGGTATCGCCGTCTTTGTCGATGTAGGACTTGACGTCGGACGATGATTTAGCTCCCTGAATGTTCGGATGGAAATGCGTTGACCGGGTTTGGGAGACCAAGTCGAAGAGTCTGTTATTCGTGCATTGGAACTTCCCTTCGAACTGGAGGAGGACGTGGAGATGAGGCTCCCCATCTTCGTGAAGCTCTCTGCAAATTTTGATGAATTTTTTGTTGACTGGTGTTTGTAAGGCTTGTAATTGGGAAAGTGTTTCTTCTTTGGTTAATGAGCATCGTGGATACGTAATGAAATAATTTTTGGCTTTAATACAAAAAGAACCCTTCCGTGGCATTTTTGTAAATAAGGCCGTGTACCCCCGATTGCTCTGGCTCTCAAAACTCTCATGAATTGGGGGTACTGGGGGTACATTTATACCTATGAGTTCCATAAGCTCCAAAGGGGCACGTGGCGGCCATCCGAATAATATT
Gene Information
|
NCBI Accession
|
YP_004207817.1
|
|
Location
|
523-1293 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTTCCCTTTGAAATACAGACGTGGCTCGTTGACTAGCAATCGTCGAAGTTATACAGGGACTCCGGTGTTTAGACGTCCATATGCTGGTAAACGGTCTGCTTGGAAACGTCGACCGACAAGTGCACCCAAAGCACATGAAGAGAAGAAACTTTCAGCTCAGCGTATTCATGAGAATCAGTTTGGGCCGGAATTTGTCATGGCCCATAATTCAGCCATATCGACCTTCATCACCTTTCCTGAGCTTGGTAAGACGGAGCCCAATAGGTCTAGGTCATATATTAAGTTGAAACGTTTACGTTTCAAAGGAACAGTCAAGATTGAACGTGTGCATGCCGACGTGAACATGGATGGTTCATTGCCGAAGATTGAAGGAGTCTTCTCCCTCGTTGTGGTGGTCGATCGGAAACCCCATTTGAGTCAATCTGGCTGCCTCCATACATTCGACGAGCTCTTTGGTGCACGGATTCATAGCCATGGTAATTTGGCCATTACTCCCTCTTTGAAGGACCGCTTTTACATACGGCACGTGTTGAAGCGGGTTTTGTCAGTCGAGAAGGATTCCTTGATGGTGGATCTGGAGGGAACGACCGCATTATCTAATAGGCGTTTTAACTGCTGGTCCTCGTTTAAGGACCTTGACCGTGATACATGTAACGGGGTTTATGCTAACATAGGCAAGAACGCCCTCCTAGTTTATTACTGTTGGATGTCGGATACCATGTCCAAGGCGTCGACATTTGTATCGTTTGACCTTGATTATATTGGTTGA |
|
Protein Sequence
|
MFPLKYRRGSLTSNRRSYTGTPVFRRPYAGKRSAWKRRPTSAPKAHEEKKLSAQRIHENQFGPEFVMAHNSAISTFITFPELGKTEPNRSRSYIKLKRLRFKGTVKIERVHADVNMDGSLPKIEGVFSLVVVVDRKPHLSQSGCLHTFDELFGARIHSHGNLAITPSLKDRFYIRHVLKRVLSVEKDSLMVDLEGTTALSNRRFNCWSSFKDLDRDTCNGVYANIGKNALLVYYCWMSDTMSKASTFVSFDLDYIG |
|
NCBI Accession
|
YP_004207818.1
|
|
Location
|
1385-2266 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAGTTGATGCATCCTCCGAACGCATTTAATTATATAGAATCTCACCGTGACGAATATCAGCTGTCTCATGATCTAACGGAGATCGTTCTGCAATTCCCGTCGACGGCGTCTCAATTAAGCGCAAGACTCAGTCGTAGCTGTATGAAAATCGACCACTGCGTCATAGAATACAGGCAACAGGTACCGATCAACGCCACGGGATCCGTAGTGGTGGAGATCCATGACAAGAGGATGACGGACAACGAATCCTTGCAGGCGGCGTGGACGTTTCCGATCAGGTGCAACATAGATCTCCACTATTTCTCGTCATCGTTCTTCTCGCTCAAAGACCCAATCCCATGGAAACTGTATTACAAGGTTTGCGACTCGAATGTACACCAAAGGACGCATTTCGCCAAGTTCAAAGGCAAACTCAAGCTGTCAACGGCGAAACATTCCGTTGATATCCCCTTCCGAGCTCCGACGGTCAAGATCTTATCCAAACAGTTCACCGATAAGGACATAGATTTCTGCCACGTGGGGTACGGCAAGTGGGAGAGGAGGATGGTCAGATCCGCATCCATATCTAGAATTGGGCTTCCCGGCCCAATAGAAATTAGGCCCGGAGAGTCGTGGGCTGCCAGGAGCACCATAGGCCCTAGCAATTCAGATGCGGAATCGGAAATGGGAGAGGCCCAACATCCGTACCGAGAGCTCAACAGATTGGGCACCACCATCTTAGACCCGGGTGAATCTGCTTCGATAGTTGGGGCCCAGAGGGCACAGTCCAACATAACGATGTCAGTGGCCCAATTGAACGAGCTTGTGAGAACGACGGTCCAAGAGTGCATTAAAACAAACTGCACTCCTTCACAGCCCAAATCGTTGCAATAG |
|
Protein Sequence
|
MESQLMHPPNAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLSARLSRSCMKIDHCVIEYRQQVPINATGSVVVEIHDKRMTDNESLQAAWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVCDSNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDIDFCHVGYGKWERRMVRSASISRIGLPGPIEIRPGESWAARSTIGPSNSDAESEMGEAQHPYRELNRLGTTILDPGESASIVGAQRAQSNITMSVAQLNELVRTTVQECIKTNCTPSQPKSLQ |
|
NCBI Accession
|
YP_004207824.1
|
|
Location
|
261-1016 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGGGAAGCCCCTTGGCGTTCGATGGCGGGAACTTCCAAAGTGAGCCGGTCTCTCAATTTTTCCCCTCGTGGTGGTGTGGGCTCAAGGTCCAACAAGGCCAGCGCTTGGGTGAACAGGCCCATGTACAGGAAGCCCAAGTTTTATCGGGTTTTTAGATCCCCCGATGTTCCCAAAGGGTGTGAAGGCCCATGCAAGGTCCAGTCATATGAGCAGCGTCATGACATCTCTCATACCGGCAAGGTGATGTGTATATCTGATGTCACACGTGGCAGTGGTATAACCCACCGTGTTGGTAAGCGTTTCTGCGTTAAGTCTGTTTACATTTTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACCAACAGTGTCATGTTCTGGCTGGTCAGAGATCGTAGACCGACCGGTACTCCTATGGATTTTGGCCATTTGTTCAACATGTTCGACAACGAGCCTAGCACAGCTACGATCAAGAACGATCTCCGCGATCGTTTCCAGGTTTTGCACAGGTTTCACGCCAAGGTCACAGGTGGACAGTATGCGAGCAACGAGCAGGCCCTGGTCAAACGTTTCTGGAAGGTCAACAACCATGTGGTGTACAACAACCAGGAAGCCGCTAGATACGAGAATCATACGGAGAACGCTTTGATGTTATACATGGCATGTACTCATGCCTCTAACCCCGTGTATGCTACGTTAAAAATTCGGATCTATTTTTACGATTCGATAACAAATTAA |
|
Protein Sequence
|
MSKREAPWRSMAGTSKVSRSLNFSPRGGVGSRSNKASAWVNRPMYRKPKFYRVFRSPDVPKGCEGPCKVQSYEQRHDISHTGKVMCISDVTRGSGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPTGTPMDFGHLFNMFDNEPSTATIKNDLRDRFQVLHRFHAKVTGGQYASNEQALVKRFWKVNNHVVYNNQEAARYENHTENALMLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_004207825.1
|
|
Location
|
1013-1411 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACAGGGGAAATCATCACTGCGCATCAAGCAGAGAGTGGCGTCTATATCTGGGAGGTAACAAATCCCCTGTATTTCAAGATAACCAGCGTAGAGGACATAATCTACACCAACACGAGGATCTACCACATCCAAATCCGGTTCAACCACAACCTGAGGAAAGCATTGGATCTCCACAAGGCATTTCTCAATTTCCAAGTTTGGACGACATTGACGACAGCTTCTGGGAGGAGTTATTTAAATAGATTTAAATATTTAGTTTCCTTGTACCTAGATCGACTAGGGGTTATTTGCATTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAGATCCTATGTAAACCATGTACTCGAAAAGCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGEIITAHQAESGVYIWEVTNPLYFKITSVEDIIYTNTRIYHIQIRFNHNLRKALDLHKAFLNFQVWTTLTTASGRSYLNRFKYLVSLYLDRLGVICINNVIRAVRFATDRSYVNHVLEKHSIKFKIY |
|
NCBI Accession
|
YP_004207826.1
|
|
Location
|
1158-1547 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional regulator |
|
Coding Region
|
ATGCGAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACCTCAACACAGGGCGGCGAAACGCAGGGCAACTCGCCGTAGACGGATCGATCTTAACTGCGGCTGCTCAATATACGTCCACATCAACTGCAGCAACCATGGATTCACGCACAGGGGAAATCATCACTGCGCATCAAGCAGAGAGTGGCGTCTATATCTGGGAGGTAACAAATCCCCTGTATTTCAAGATAACCAGCGTAGAGGACATAATCTACACCAACACGAGGATCTACCACATCCAAATCCGGTTCAACCACAACCTGAGGAAAGCATTGGATCTCCACAAGGCATTTCTCAATTTCCAAGTTTGGACGACATTGACGACAGCTTCTGGGAGGAGTTATTTAAATAG |
|
Protein Sequence
|
MRNSSSSTPPSIKPQHRAAKRRATRRRRIDLNCGCSIYVHINCSNHGFTHRGNHHCASSREWRLYLGGNKSPVFQDNQRRGHNLHQHEDLPHPNPVQPQPEESIGSPQGISQFPSLDDIDDSFWEELFK |
|
NCBI Accession
|
YP_004207827.1
|
|
Location
|
1468-2544 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGGAAGGGTTCTTTTTGTATTAAAGCCAAAAATTATTTCATTACGTATCCACGATGCTCATTAACCAAAGAAGAAACACTTTCCCAATTACAAGCCTTACAAACACCAGTCAACAAAAAATTCATCAAAATTTGCAGAGAGCTTCACGAAGATGGGGAGCCTCATCTCCACGTCCTCCTCCAGTTCGAAGGGAAGTTCCAATGCACGAATAACAGACTCTTCGACTTGGTCTCCCAAACCCGGTCAACGCATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATCGACAAAGACGGCGATACCCTCGAATGGGGAGAATTCCAGATCGACGGGAGAAGTGCTAGAGGAGGTTGCCAAACAGCTAACGACGTTGCCGCAGAGGCTTTAAACGCCCCTTCAAAAGAAGCGGCGCTCCAAATAGTCAGAGAGAAATTGCCGGAGAAATATTTATTTCAATTTCATAATCTAAATAGCAATTTAGATCGGATTTTCTCGAAGGCTCCGGAGCCGTGGGTTCCTCCGTTTCAACTCTCCTCCTTCACTGCCGTCCCGGACGAGATGCAAGAATGGGCCGATGATTATTTTGGGAGGGGTGCCGCTGCGCGGCCGGAGAGACCTATCAGTTTGATCGTCGAGGGTGATAGTCGGACGGGGAAGACGATGTGGGCTCGTGCGTTAGGCCCACATAATTATTTGAGCGGACACCTGGACTTCAATTCTAGGGTTTACTCGAATAAAGCGGAGTACAACGTCATCGATGATGTCAGTCCGCAATATCTAAAGATGAAGCACTGGAAAGAGCTAATTGGGGCCCAAAAAGACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGCGGGATCCCATCAATCGTGCTCTGCAATCCAGGTGAAGGGGCCAGCTATAAAGATTTCCTCGACAAAGAGGAAAACGCATCGCTCAAAAACTGGACCCTTCATAATGCGAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACCTCAACACAGGGCGGCGAAACGCAGGGCAACTCGCCGTAG |
|
Protein Sequence
|
MPRKGSFCIKAKNYFITYPRCSLTKEETLSQLQALQTPVNKKFIKICRELHEDGEPHLHVLLQFEGKFQCTNNRLFDLVSQTRSTHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGCQTANDVAAEALNAPSKEAALQIVREKLPEKYLFQFHNLNSNLDRIFSKAPEPWVPPFQLSSFTAVPDEMQEWADDYFGRGAAARPERPISLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNKAEYNVIDDVSPQYLKMKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENASLKNWTLHNAKFIFLDAPLYQTSTQGGETQGNSP |
|
NCBI Accession
|
YP_004207828.1
|
|
Location
|
2130-2387 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCACGTCCTCCTCCAGTTCGAAGGGAAGTTCCAATGCACGAATAACAGACTCTTCGACTTGGTCTCCCAAACCCGGTCAACGCATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATCGACAAAGACGGCGATACCCTCGAATGGGGAGAATTCCAGATCGACGGGAGAAGTGCTAGAGGAGGTTGCCAAACAGCTAACGACGTTGCCGCAGAGGCTTTAA |
|
Protein Sequence
|
MGSLISTSSSSSKGSSNARITDSSTWSPKPGQRISIRTFRELNHRPTSSPTSTKTAIPSNGENSRSTGEVLEEVAKQLTTLPQRL |