Sida leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000866845.1 |
| Isolate | China:Hainan |
| Release date | 2015/2/13 |
| Submitter | Guo,X., Zhou,X. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
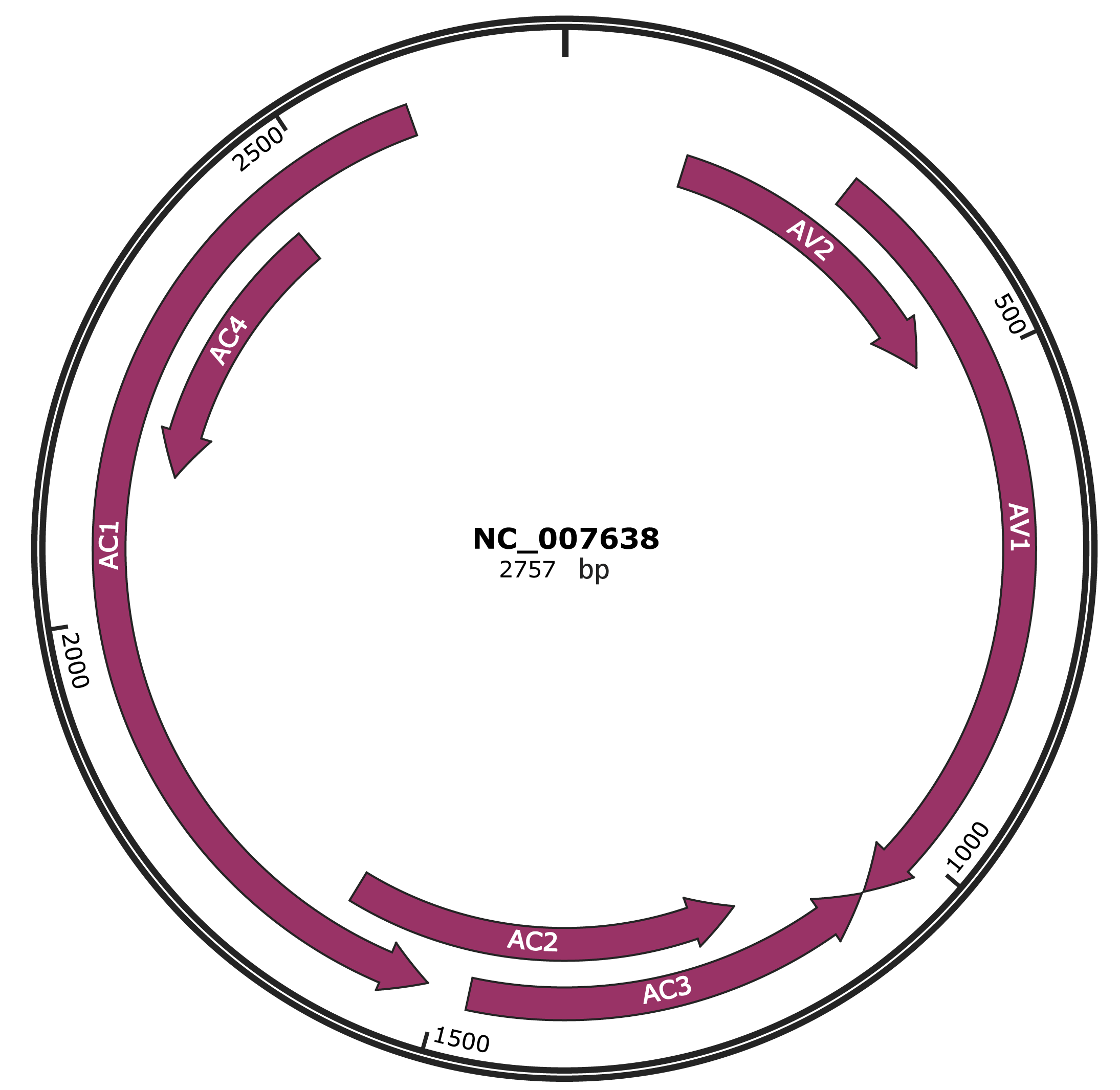
JBrowse
Genome
NC_007638
Gene Information
| NCBI Accession | YP_425029.1 |
|---|---|
| Location | 134-481 |
| Gene Name | AV2 |
| Protein Name | AV2 protein |
| Coding Region | ATGTGGGACCCTTTAGAGAACGAATTCCCTGAAACCGTTCACGGTTTCCGTTCTATGCTTGCGGTGAAGTATATGCAGGAGATTGCGAAGAGCTACGAACCTAGCACATTGGGTTTTGAATACGTCCGTGATCTTATCTCCGTTCTGAGGTGTAAGGATTATGTCCAAGCGTCCTGCAAGTATGGCGTATTCCTCTCCAATTTCTTCCGCGCGTCGAAGGCTGAACTTCGACAGTCCTCGCCCATCAGTTGCTGCTGCCCTTACTGCCCCAGGCATAAGGAGAAGAAGATGGACCAACAGGCCCATGAACAGAAAGCCCAGGTTCTACAGAATGTATCGAACCCCTGA |
| Protein Sequence | MWDPLENEFPETVHGFRSMLAVKYMQEIAKSYEPSTLGFEYVRDLISVLRCKDYVQASCKYGVFLSNFFRASKAELRQSSPISCCCPYCPRHKEKKMDQQAHEQKAQVLQNVSNP |
| NCBI Accession | YP_425030.1 |
|---|---|
| Location | 294-1064 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCCAAGCGTCCTGCAAGTATGGCGTATTCCTCTCCAATTTCTTCCGCGCGTCGAAGGCTGAACTTCGACAGTCCTCGCCCATCAGTTGCTGCTGCCCTTACTGCCCCAGGCATAAGGAGAAGAAGATGGACCAACAGGCCCATGAACAGAAAGCCCAGGTTCTACAGAATGTATCGAACCCCTGATGTTCCTAAGGGCTGTGAGGGCCCATGTAAGGTGCAATCGTTCGATGCCAAAGACGATATTGGGCACATGGGTAAGGTTATTTGTTTGTCTGATGTTACAAGAGGTATTGGGCTGACCCACCGAGTGGGTAAGCGTTTCTGTGTGAAATCATTGTATTTCGTAGGGAAAATATGGATGGACGAGAATATCAAGGTGAAAAACCACACGAACACCGTTATGTTTTGGATTGTTAGGGATCGGCGACCTACGGGAACTCCATTGGATTTCCAGCAGGTGTTTAATGTCTACGATAACGAGCCCGCCACTGCTACAGTCAAGAACGACAAACGTGATCGTTTCCAGGTTTTAAGGAGGTTCCATGCAACGGTGACCGGAGGGCAATATGCAGCTAAGGAGTCTGCTATTATTAGGAAGTTCTATCGTGTGAACAATTATGTTGTTTACAACCACCAGGAGGCCGGAAAATACGAGAACCATACTGAGAATGCTTTGCTCTTGTACATGGCATGTACGCATGCCTCTAATCCTGTGTATGCTACTTTGAAATGTAGGAGTTATTTCTACGATACTGTAACGAATTAA |
| Protein Sequence | MSKRPASMAYSSPISSARRRLNFDSPRPSVAAALTAPGIRRRRWTNRPMNRKPRFYRMYRTPDVPKGCEGPCKVQSFDAKDDIGHMGKVICLSDVTRGIGLTHRVGKRFCVKSLYFVGKIWMDENIKVKNHTNTVMFWIVRDRRPTGTPLDFQQVFNVYDNEPATATVKNDKRDRFQVLRRFHATVTGGQYAAKESAIIRKFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKCRSYFYDTVTN |
| NCBI Accession | YP_425031.1 |
|---|---|
| Location | 1067-1471 |
| Gene Name | AC3 |
| Protein Name | AC3 protein |
| Coding Region | ATGGATTCACGCACAGGGGAATACATCACTGCAGCTCAAGCGACGAGTGGCGTATATACCTGGGATATGGCAAATCCCCTGTATTTCAAGATCCTAGACCACCTGGACAGGCCGTTCCTCCGCAACCACGACATCATAACCGTCCAAGTGAGGTTCAACCACAACCTGAGGAAAGCCTTGGGGATTCACAAATGTTTCATAACCTTCCGGATCTGGACTCGTTTACATCCTCAGACATGGCGTTTCTTGAGGGTCTTACGCAATCAAGTTCTTGGGTACTTAGATAGATTAGGAGTTATTAGTATTAATAATGTAATTAGGGCTTTTGATCATGTATTATACAATGTAATTCAAGGCACAATTCAGGTGCAACAAACTGAGTCAATAAAATTCAACCTTTATTAA |
| Protein Sequence | MDSRTGEYITAAQATSGVYTWDMANPLYFKILDHLDRPFLRNHDIITVQVRFNHNLRKALGIHKCFITFRIWTRLHPQTWRFLRVLRNQVLGYLDRLGVISINNVIRAFDHVLYNVIQGTIQVQQTESIKFNLY |
| NCBI Accession | YP_425032.1 |
|---|---|
| Location | 1185-1619 |
| Gene Name | AC2 |
| Protein Name | AC2 protein |
| Coding Region | ATGCGTCGTTCGTCACCCTCACAGAGCCATTGTACTCAGGTGCCCATCAAAATCGAGCATCAGAAGGTGAGGAAGAAGTACAATCGCAGGAAGAGGGTGGACCTTGAATGCGGGTGCACATACTTCCGCAGTCTCAACTGTCACAACCATGGATTCACGCACAGGGGAATACATCACTGCAGCTCAAGCGACGAGTGGCGTATATACCTGGGATATGGCAAATCCCCTGTATTTCAAGATCCTAGACCACCTGGACAGGCCGTTCCTCCGCAACCACGACATCATAACCGTCCAAGTGAGGTTCAACCACAACCTGAGGAAAGCCTTGGGGATTCACAAATGTTTCATAACCTTCCGGATCTGGACTCGTTTACATCCTCAGACATGGCGTTTCTTGAGGGTCTTACGCAATCAAGTTCTTGGGTACTTAGATAG |
| Protein Sequence | MRRSSPSQSHCTQVPIKIEHQKVRKKYNRRKRVDLECGCTYFRSLNCHNHGFTHRGIHHCSSSDEWRIYLGYGKSPVFQDPRPPGQAVPPQPRHHNRPSEVQPQPEESLGDSQMFHNLPDLDSFTSSDMAFLEGLTQSSSWVLR |
| NCBI Accession | YP_425033.1 |
|---|---|
| Location | 1513-2607 |
| Gene Name | AC1 |
| Protein Name | replication protein |
| Coding Region | ATGGCTCCCTCTAAACGCTTTAACATTTATTGCAAAAATTATTTCCTTACTTATCCCAAATGCTCTCTTACTAAAGAGGAAACACTTTCCCAAATCCAAAACCTAAACACCCCAACCAACAAAAAATACATTAAGGTCTGCAGAGAACTCCACGAGAATGGGGAACCTCATATTCACGTGCTCATCCAGTTCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAACCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCAGATGTCAAGTCCTACATCGACAAGGACGGCGACACCATCGAATGGGGAGAGTTTCAGATCGACGGAAGATCTGCCAGAGGGGGACAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACACAGGCAGTAAGCCGGAGGCTCTTAGAGTACTTAGGGAACTAGCCCCTAAAGATTATGTTTTACAATTTCATAATTTAAATGCTAACTTAGATAGGATTTTTACACCTCCAATGGAGGTTTATGTTTCTCCTTTTTCTGTCTCTTCTTTTGATCGAGTTCCGGAAGAACTCGAAGAGTGGGCGTGCGAGAATGTAGTGGCGGCCGCTGCGCGGCCTCTGAGACCCTTAAGTTTAGTGGTAGAAGGTGACAGTAGAACAGGGAAGACGATGTGGGCCAGGTCATTAGGTCCACATAATTACTTGTGTGGGCATCTAGACCTAAGCCCAAAGGTGTACAGCAACGACGCATGGTACAACGTCATCGATGACGTTGATCCCCATTTTCTCAAACACTTTAAAGAGTTTATGGGGGCCCAGAGGGACTGGCAAAGCAATACCAAGTACGGCAAGCCAGTTCAAATTAAAGGCGGGATCCCAACAATCTTCCTTTGCAATCCAGGGCCCAATTCCAGCTATAAAGAGTACCTGGACGAGGAAAAGAATTCCGCTTTAAAGACGTGGGCTTTAAAAAATGCGTCGTTCGTCACCCTCACAGAGCCATTGTACTCAGGTGCCCATCAAAATCGAGCATCAGAAGGTGAGGAAGAAGTACAATCGCAGGAAGAGGGTGGACCTTGA |
| Protein Sequence | MAPSKRFNIYCKNYFLTYPKCSLTKEETLSQIQNLNTPTNKKYIKVCRELHENGEPHIHVLIQFEGKYKCQNQRFFDLVSPNRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGEFQIDGRSARGGQQTANDAYAAALNTGSKPEALRVLRELAPKDYVLQFHNLNANLDRIFTPPMEVYVSPFSVSSFDRVPEELEEWACENVVAAAARPLRPLSLVVEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEYLDEEKNSALKTWALKNASFVTLTEPLYSGAHQNRASEGEEEVQSQEEGGP |
| NCBI Accession | YP_425034.1 |
|---|---|
| Location | 2148-2450 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGGAACCTCATATTCACGTGCTCATCCAGTTCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAACCGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCAGATGTCAAGTCCTACATCGACAAGGACGGCGACACCATCGAATGGGGAGAGTTTCAGATCGACGGAAGATCTGCCAGAGGGGGACAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACACAGGCAGTAAGCCGGAGGCTCTTAGAGTACTTAGGGAACTAG |
| Protein Sequence | MGNLIFTCSSSSRGNTSARISDSSTWSPQTGQHISIRTFRELNQAQMSSPTSTRTATPSNGESFRSTEDLPEGDNRQPTTLTPQHLTQAVSRRLLEYLGN |
References More References in PubMed
| 1 |
First Report of Sida leaf curl virus and Associated Betasatellite from Tobacco. Wang D, et al. Plant Dis. 2022 Mar;106(3):1078. doi: 10.1094/PDIS-05-21-1044-PDN. Epub 2022 Feb 9. PMID: 34713725 |
|---|---|
| 2 |
García-Rodríguez DA, et al. PeerJ. 2023 Mar 22;11:e15047. doi: 10.7717/peerj.15047. eCollection 2023. PMID: 36974135 |
| 3 |
Wang D, et al. Plant Dis. 2024 Apr;108(4):877-886. doi: 10.1094/PDIS-07-23-1346-RE. Epub 2024 Apr 4. PMID: 37743589 |
| 4 |
Idris AM, et al. Virus Res. 2005 Apr;109(1):19-32. doi: 10.1016/j.virusres.2004.10.002. Epub 2004 Nov 23. PMID: 15826909 |
| 5 |
Shahid MS, et al. Viruses. 2014 Jan 14;6(1):189-200. doi: 10.3390/v6010189. PMID: 24424499 |
| 6 |
Molecular analysis of Cotton leaf curl virus-Sudan reveals an evolutionary history of recombination. Idris AM, et al. Virus Genes. 2002 Jun;24(3):249-56. doi: 10.1023/a:1015380600089. PMID: 12086146 |
| 7 |
Mugerwa H, et al. Cells. 2022 Jun 29;11(13):2060. doi: 10.3390/cells11132060. PMID: 35805143 |
| 8 |
Gautam S, et al. Viruses. 2022 May 20;14(5):1104. doi: 10.3390/v14051104. PMID: 35632844 |
| 9 |
Li P, et al. Arch Virol. 2018 Dec;163(12):3443-3446. doi: 10.1007/s00705-018-4004-6. Epub 2018 Aug 25. PMID: 30145682 |
| 10 |
Geminiviruses Infecting Tomato Crops in Nicaragua. Rojas A, et al. Plant Dis. 2000 Aug;84(8):843-846. doi: 10.1094/PDIS.2000.84.8.843. PMID: 30832136 |