Sida interveinal bright yellow virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_018591025.1 |
| Isolate |
Mexico: Queretaro |
| Release date |
2021/6/1 |
| Submitter |
Sanchez-Luna,S., Martinez-Marrero,N., Avalos-Calleros,J.A., Ambriz-Granados,S., Arguello-Astorga,G.R. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
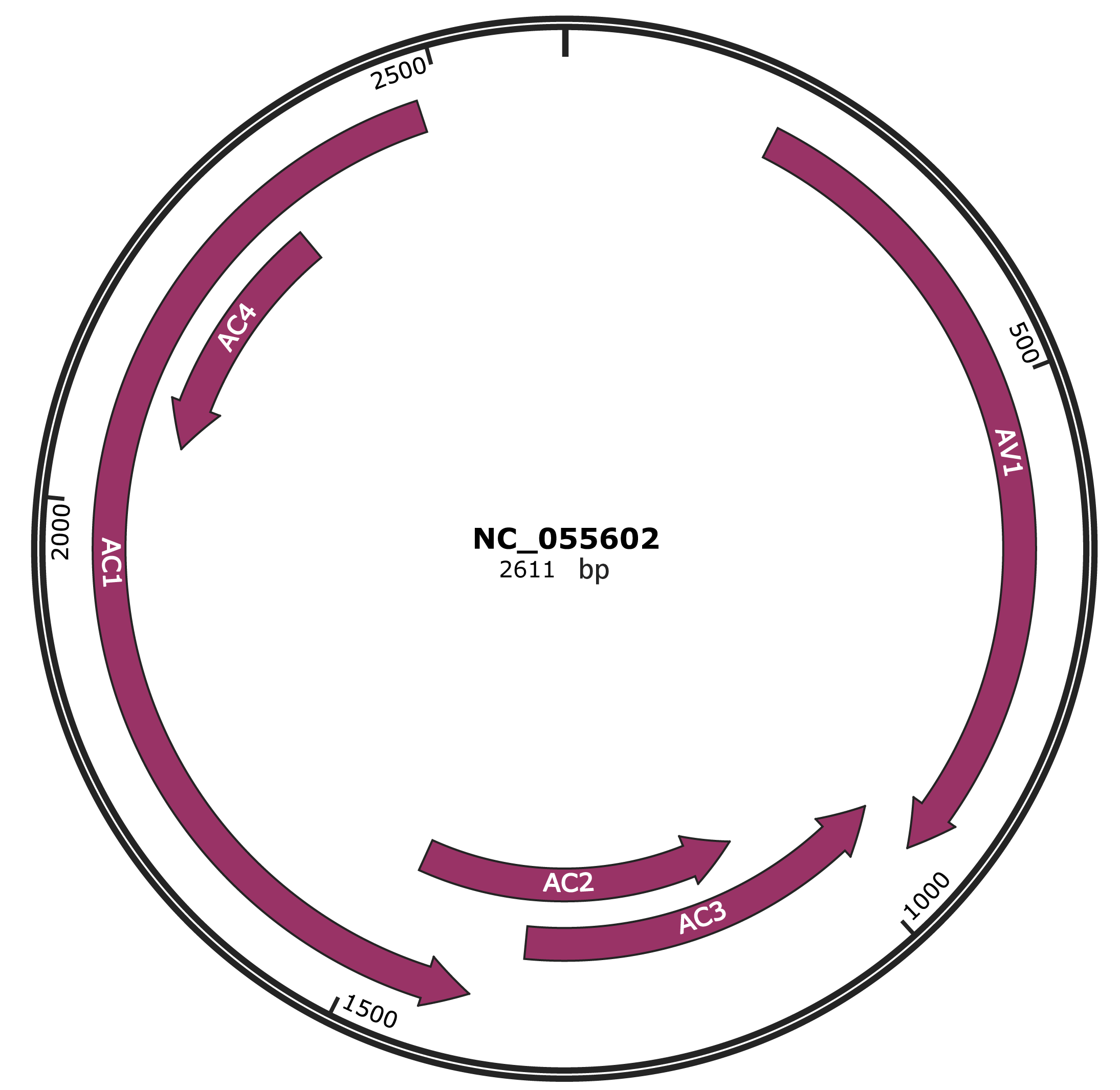
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTCCCCCCATACGCGCGCACGCTCCTCTTTAATTTGAATTAAAGCGTCTCTGACGCGATGTCGTCCAATGATATTACGCCTGACGAGCCTAGATATTTTCAACAACTTGGGCGCTAAGTTGTTGGGTGTCGGTTATAAAATTAAAGAGGCTTTGGCCCACTGTCTTTAATTCAAAATGCCTAAGCGCGATCTCCCATGGCGCTCGATCGCGGGAACCTCAAAGGTTAGCCGCAATGCTAACTATTCTCCTCGCGGAGGGAGTGGGCCAAGGGTGAACAAGGCCTCTGAATGGGTGAACAGGCCCATATACAGGAAGCCCAGGATCTACAGGATCATGAGAGGCCCTGATGTTCCAAAGGGTTGTGAAGGCCCGTGTAAGGTCCAGTCCTACGAGCAGCGTCATGATATCTCCCATGTGGGTAAGGTTATGTGTGTGTCTGATATCACACGTGGTAATGGGCTTACTCATCGAGTCGGTAAGCGTTTTTGTGTTAAGTCCATTTATATTTTAGGTGAGGTGTGGATGGATGATAATATTAAGTTGAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTTAGGGATCGTAGACCGTATGGCATTCCTATGGACTTTGGACAGGTGTTCAACATGTTTGACAACGAGCCCAGTACTGCGACGATCAAGAACGACCTTCGAGATCGTTTCCAGGTGATGCACAAGTTCTACGCCAAGGTTACCGGTGGTCAATATGCAAGCAACGAGCAGGCAATTGTTAGGCGTTTCTGGAAGATTAATAACTACGTTGTGTATAACCACCAGGAAGCTGGGAAATACGATAACCATACGGAGAACGCCCTTTTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCAACGCTGAAGATTCGGATTTACTTCTACGATTCGATTCAAAATTAATAAAGTTTGAATTTTATTGAATGGTCTTCCAGTACATAATTTACATACGATCTGTCCGTCGCGAAACGAACGGCTCTGATTACATTATTTAATGAAATTACGCCTAACATATCTAAATACATATTAACTAAATGCCTAAACCTATTTAAATAACTCGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAAGCTTTGTGGAGATGCAACGCTTTCCTCAGGTTGTGGTTGAACCGTATTTGTACGTTGTATACTCTGGTATTCGTGTATATTAGGTCCTCTACTCGGTACATCTTGAAATATAGGGGATTTTCTATCTCCCAGATATAGACGCCATCCTCTGCCTGAGGTGCAGTGATGAGCTCCCCTGTGCGTGAATCCATGCCCTGTGCAGCCTATGTGGAAGTAGATGGAGCACCCGCACTCTAGATCAATCCGCCTTCTCCTGATGGCCCTCTTCTTGGCTTGTCTGTGTGCTGTCTTGATAGAGGGCGGATGTGAGGGTGATGAAGATCGCATTCTTGATGGTCCAGTTTCTGAGGCCTATGTTTTCCTCTTTGTTCAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATCCCTCCTTTAATTTGAACTGGCTTGCCGTATTTGCAATTTGACTGCCAGTCCTTCTGGGCCCCCAGAAGTTCTTTCCAGTGCTTCATCTTTAGATAATGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCGTTTGAGAACACTTTGGAATTGAAGTCCAGATGTCCACTGAGATAATTATGTGGGCCTAATGCACGAGCCCACATCGTCTTCCCTGTTCTTGAATCACCTTCTACTATGATACTAACAGGTCGTTCTGGCCGCGCAGCGGCACCCCTTCCAAAATAATCATCGGCCCACTCTTGCATTTCGTCCGGCACATTAGTGAAAGAGGAGAGTTGAAAAGGAGGAACCCACCGTTCCGGAGCTTTTTGGAATATCTTGGTTGCGTTGGCGACTAGGTTATGATGTTGAAGGAAGAAATGCTGTGGTTGCTCTTCCCTGATTATTCGCAGAGCCTCCTCTGCGCATGTTGCATTCAACGCCTTGGCATATGAGTCGTTAGCAGATTGCTGACCTCCTCTAGCAGATCTGCCGTCGACCTGGAATTTGCCCCATTCGAGTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAGACCAGATCGAAGAATCTGTTATTCGTGCATTGGTATTTGCCTTCGAACTGAATGAGGACGTGGAGATGAGGCTCCCCATTCTCGTGTAGCTCTCTGCAGATTTTGATGAATTTCTTGTCAACTGGGGTTGTTAGGTTCTGTAATTGGGAAAGTGCTTCTTCTTTAGTAAGAGAGCACTGGGGATAAGTGAGGAAATAGTTTTTAGCTGAGACTTTGAAACGCTTAACTGATGGCATTTTTGTAATAAGAAGGGTGTACCCCGGTTGAGCTCTCAAACATCTGTGCTATCAATTGGGGTAATGGGTTACAATATATACTACAACTCTCTTTAGTGGTTTTGAACACGTGGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010087869.1
|
|
Location
|
196-951 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATCTCCCATGGCGCTCGATCGCGGGAACCTCAAAGGTTAGCCGCAATGCTAACTATTCTCCTCGCGGAGGGAGTGGGCCAAGGGTGAACAAGGCCTCTGAATGGGTGAACAGGCCCATATACAGGAAGCCCAGGATCTACAGGATCATGAGAGGCCCTGATGTTCCAAAGGGTTGTGAAGGCCCGTGTAAGGTCCAGTCCTACGAGCAGCGTCATGATATCTCCCATGTGGGTAAGGTTATGTGTGTGTCTGATATCACACGTGGTAATGGGCTTACTCATCGAGTCGGTAAGCGTTTTTGTGTTAAGTCCATTTATATTTTAGGTGAGGTGTGGATGGATGATAATATTAAGTTGAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTTAGGGATCGTAGACCGTATGGCATTCCTATGGACTTTGGACAGGTGTTCAACATGTTTGACAACGAGCCCAGTACTGCGACGATCAAGAACGACCTTCGAGATCGTTTCCAGGTGATGCACAAGTTCTACGCCAAGGTTACCGGTGGTCAATATGCAAGCAACGAGCAGGCAATTGTTAGGCGTTTCTGGAAGATTAATAACTACGTTGTGTATAACCACCAGGAAGCTGGGAAATACGATAACCATACGGAGAACGCCCTTTTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCAACGCTGAAGATTCGGATTTACTTCTACGATTCGATTCAAAATTAA |
|
Protein Sequence
|
MPKRDLPWRSIAGTSKVSRNANYSPRGGSGPRVNKASEWVNRPIYRKPRIYRIMRGPDVPKGCEGPCKVQSYEQRHDISHVGKVMCVSDITRGNGLTHRVGKRFCVKSIYILGEVWMDDNIKLKNHTNSVMFWLVRDRRPYGIPMDFGQVFNMFDNEPSTATIKNDLRDRFQVMHKFYAKVTGGQYASNEQAIVRRFWKINNYVVYNHQEAGKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSIQN |
|
NCBI Accession
|
YP_010087870.1
|
|
Location
|
948-1346 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGCTCATCACTGCACCTCAGGCAGAGGATGGCGTCTATATCTGGGAGATAGAAAATCCCCTATATTTCAAGATGTACCGAGTAGAGGACCTAATATACACGAATACCAGAGTATACAACGTACAAATACGGTTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGAGTTATTTAAATAGGTTTAGGCATTTAGTTAATATGTATTTAGATATGTTAGGCGTAATTTCATTAAATAATGTAATCAGAGCCGTTCGTTTCGCGACGGACAGATCGTATGTAAATTATGTACTGGAAGACCATTCAATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAEDGVYIWEIENPLYFKMYRVEDLIYTNTRVYNVQIRFNHNLRKALHLHKAYLNFQVWTTSMTASGSSYLNRFRHLVNMYLDMLGVISLNNVIRAVRFATDRSYVNYVLEDHSIKFKLY |
|
NCBI Accession
|
YP_010087871.1
|
|
Location
|
1093-1482 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCACACAGACAAGCCAAGAAGAGGGCCATCAGGAGAAGGCGGATTGATCTAGAGTGCGGGTGCTCCATCTACTTCCACATAGGCTGCACAGGGCATGGATTCACGCACAGGGGAGCTCATCACTGCACCTCAGGCAGAGGATGGCGTCTATATCTGGGAGATAGAAAATCCCCTATATTTCAAGATGTACCGAGTAGAGGACCTAATATACACGAATACCAGAGTATACAACGTACAAATACGGTTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGAGTTATTTAAATAG |
|
Protein Sequence
|
MRSSSPSHPPSIKTAHRQAKKRAIRRRRIDLECGCSIYFHIGCTGHGFTHRGAHHCTSGRGWRLYLGDRKSPIFQDVPSRGPNIHEYQSIQRTNTVQPQPEESVASPQSLPELPSLDDIDDSFWVELFK |
|
NCBI Accession
|
YP_010087872.1
|
|
Location
|
1394-2479 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication protein |
|
Coding Region
|
ATGCCATCAGTTAAGCGTTTCAAAGTCTCAGCTAAAAACTATTTCCTCACTTATCCCCAGTGCTCTCTTACTAAAGAAGAAGCACTTTCCCAATTACAGAACCTAACAACCCCAGTTGACAAGAAATTCATCAAAATCTGCAGAGAGCTACACGAGAATGGGGAGCCTCATCTCCACGTCCTCATTCAGTTCGAAGGCAAATACCAATGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTCGAATGGGGCAAATTCCAGGTCGACGGCAGATCTGCTAGAGGAGGTCAGCAATCTGCTAACGACTCATATGCCAAGGCGTTGAATGCAACATGCGCAGAGGAGGCTCTGCGAATAATCAGGGAAGAGCAACCACAGCATTTCTTCCTTCAACATCATAACCTAGTCGCCAACGCAACCAAGATATTCCAAAAAGCTCCGGAACGGTGGGTTCCTCCTTTTCAACTCTCCTCTTTCACTAATGTGCCGGACGAAATGCAAGAGTGGGCCGATGATTATTTTGGAAGGGGTGCCGCTGCGCGGCCAGAACGACCTGTTAGTATCATAGTAGAAGGTGATTCAAGAACAGGGAAGACGATGTGGGCTCGTGCATTAGGCCCACATAATTATCTCAGTGGACATCTGGACTTCAATTCCAAAGTGTTCTCAAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCATTATCTAAAGATGAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAGTCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAAGAGGAAAACATAGGCCTCAGAAACTGGACCATCAAGAATGCGATCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCACACAGACAAGCCAAGAAGAGGGCCATCAGGAGAAGGCGGATTGA |
|
Protein Sequence
|
MPSVKRFKVSAKNYFLTYPQCSLTKEEALSQLQNLTTPVDKKFIKICRELHENGEPHLHVLIQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGKFQVDGRSARGGQQSANDSYAKALNATCAEEALRIIREEQPQHFFLQHHNLVANATKIFQKAPERWVPPFQLSSFTNVPDEMQEWADDYFGRGAAARPERPVSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVFSNEVEYNVIDDVAPHYLKMKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENIGLRNWTIKNAIFITLTSALYQDSTQTSQEEGHQEKAD |
|
NCBI Accession
|
YP_010087873.1
|
|
Location
|
2065-2322 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AL4 |
|
Coding Region
|
ATGGGGAGCCTCATCTCCACGTCCTCATTCAGTTCGAAGGCAAATACCAATGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTCGAATGGGGCAAATTCCAGGTCGACGGCAGATCTGCTAGAGGAGGTCAGCAATCTGCTAACGACTCATATGCCAAGGCGTTGA |
|
Protein Sequence
|
MGSLISTSSFSSKANTNARITDSSIWSPQPGQHISIRTYRELNPAPTSSPTSTRTEIHSNGANSRSTADLLEEVSNLLTTHMPRR |