Sida golden yellow vein virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000840485.1 |
| Isolate | Jamaica |
| Release date | 2015/2/12 |
| Submitter | Stewart,C.S., Kon,T., Gilbertson,R.L., Roye,M.E., Gilbertson,B.L. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
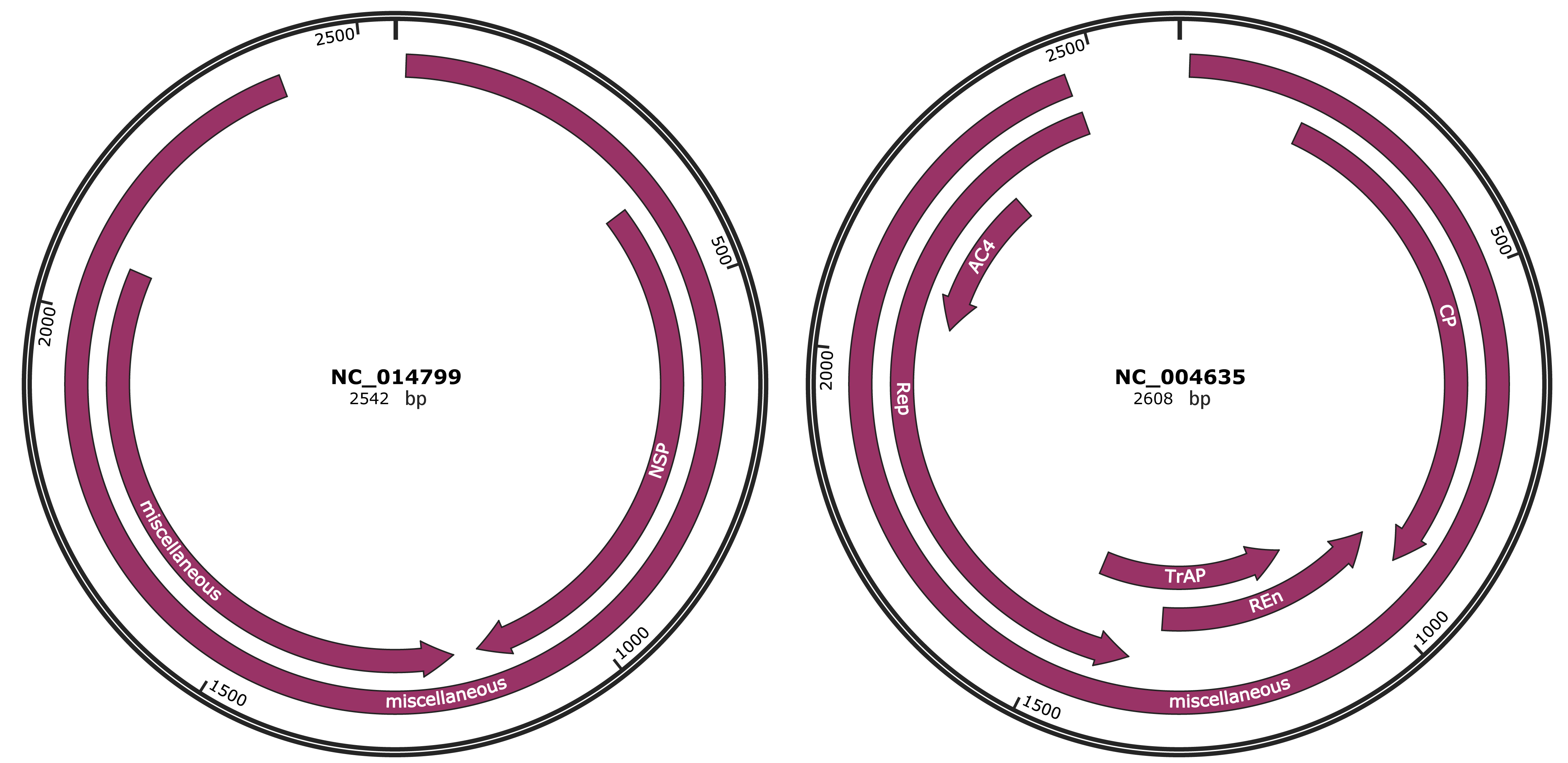
JBrowse
Genome
NC_014799
NC_004635
Gene Information
| NCBI Accession | YP_004064949.1 |
|---|---|
| Location | 374-1150 |
| Gene Name | NSP |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGAATATGTATCCTTTTAGGAATAAACGTGGGTCCTCATTCACTCAACGTCGTTATTATCCACGCAATACTGTGTTTAACCGTTTAACCGCCTCTAAGAGACATGATGTGAAACTACGACTGGGTCATATGAACAAGCCCACTGACGAGCCCAAGATGTCAGCCCAACGCATACATGAGAATCAATATAGTCCAGAGTTTGTTATGTCACAAAACTCCGCCATATCAACCTTTATCAGCTATCCTAATCTGGGTAAGACAGAACCCAATCGAAGCAGGTCTTATATAAAGTTGAAACGACTCCGTTTCAGAGGGACTGTGAAGATTGAGCGTGTTCAATCGGATGTGAATATGGATGGTTCTGTTCCTAAATTAGAAGGAGTTTTTTCTATCGTTGTAGTCGTGGATCGTAAACCCCACTTGGGTCCGACTGGTAGTCTTCATACATTCGACGAACTATTTGGTGCAATGATCCATAGTCATGGTAATCTTAGCATAACCCCGTCTCTGAAAGATCGGTTCTATATTCGACACGTGTTCAAACGTGTGATATCTGTTGATAAGGATACGACAATGTTTGACGTGGGAGGGTCTACTACGCTCTCTAATAGGCGATTCAATTGTTGGGCATCGTTTAAGGATTTTGATTGTGACTCAAGCAAGGGTGTATATGACAATATCAGCAAGAACGCTCTATTAGTTTATTATTGTTGGATGTCAGATACTATGTCTAAGGCATCGAATTTTGTATCGTTTGAACTCGATTATATCGGATGA |
| Protein Sequence | MNMYPFRNKRGSSFTQRRYYPRNTVFNRLTASKRHDVKLRLGHMNKPTDEPKMSAQRIHENQYSPEFVMSQNSAISTFISYPNLGKTEPNRSRSYIKLKRLRFRGTVKIERVQSDVNMDGSVPKLEGVFSIVVVVDRKPHLGPTGSLHTFDELFGAMIHSHGNLSITPSLKDRFYIRHVFKRVISVDKDTTMFDVGGSTTLSNRRFNCWASFKDFDCDSSKGVYDNISKNALLVYYCWMSDTMSKASNFVSFELDYIG |
| NCBI Accession | YP_004064944.1 |
|---|---|
| Location | 183-938 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGACTAAGCGCGATTCATCTTGGCGCTCGATTGGTGGAACCTCAAAGGTTCGTCGCACGTTGAATTTCTCCCCACGTGGAGGTGGTGGCCCAAAACAGACACGGGCCTCAGAATGGGTTAACAGGCCTATGTACAGGAAGCCCTTGATCTATCGGACTATACGAACGCCCGACGTTCCCAGAGGTTGTGAAGGCCCGTGCAAGGTCCAGTCCTATGAACAGCGTCATGATATCTCTCACGTCGGGAAGGTGATGTGTATTTCTGATGTCACTCGTGGTAATGGTATTACCCACCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTCTATATTTTAGGGAAGATATGGATGGATGAGAACATCAAGCTTAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGGGACCGTCGACCCTATGGCACTCCTATGGATTTCGGTCAGGTGTTCAACATGTATGACAATGAGCCTAGTACAGCTACGATCAAGAACGATCTCCGTGATCGTCATCAGGTTATGCACAGGTTCTATGGTAAGGTCACAGGTGGTCAATATGCCAGCAACGAGCAAGCTTTGGTTAGGCGATTCTGGAAGGTCAACAATCATGTAGAGTACAACCATCAAGAAGCTGGGAAATACGAGAATCATACGGAGAACGCCTTATTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MTKRDSSWRSIGGTSKVRRTLNFSPRGGGGPKQTRASEWVNRPMYRKPLIYRTIRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATIKNDLRDRHQVMHRFYGKVTGGQYASNEQALVRRFWKVNNHVEYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_004064945.1 |
|---|---|
| Location | 935-1333 |
| Gene Name | REn |
| Protein Name | replication enhancer |
| Coding Region | ATGGTTTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACTGGGTAGAGGACCAGATATACACCAGAACCAGAGTGTACCACATACAGATACGATTCAACCACAACCTGAGGAGAGCGTTGGGTCTCCACAAAGCCTACCTGAACTTCCAAGTTTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAGATTTGGACAATTAGTAAATGAGTACTTGTACCAATTAGGTGTAATTGGAATAAACAATGTAATTAGAGCTGTTCGTTTTGCAACAGCCAAACCATATGTAACTCATGTGCTTGAAAATCATGAAATAAAATTTAAATTTTATTAA |
| Protein Sequence | MVSRTGELITARQAENGVYIWEIENPLYFKIYWVEDQIYTRTRVYHIQIRFNHNLRRALGLHKAYLNFQVWTTSMTASGSTYLARFGQLVNEYLYQLGVIGINNVIRAVRFATAKPYVTHVLENHEIKFKFY |
| NCBI Accession | YP_004064946.1 |
|---|---|
| Location | 1080-1469 |
| Gene Name | TrAP |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCCAAATTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAATCCAAGAGGCGGGCAATCAGGAGGCGCAGGATTGATCTAAATTGCGGGTGCTCCATTTACTTCCACATCAACTGCACGGGACATGGTTTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACTGGGTAGAGGACCAGATATACACCAGAACCAGAGTGTACCACATACAGATACGATTCAACCACAACCTGAGGAGAGCGTTGGGTCTCCACAAAGCCTACCTGAACTTCCAAGTTTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAG |
| Protein Sequence | MPNSSPSQPPSIKKAHRQSKRRAIRRRRIDLNCGCSIYFHINCTGHGFTHRGTHHCTSGREWRVYLGDRKSPLFQDILGRGPDIHQNQSVPHTDTIQPQPEESVGSPQSLPELPSLDDIDDSFWVNLFS |
| NCBI Accession | YP_004064947.1 |
|---|---|
| Location | 1381-2466 |
| Gene Name | Rep |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCATCGATTAAACGTTTCAAAATAAATGCCAAAAACTATTTTATCACTTATCCAGGCTGCTCCCTCACCAAAGAAGAGGCACTTTCCCAATTGCTAAACCTCTCCACGCCAGTGAATAAGAAGTTCATCAAAATTTGCAGAGAGCTCCATCAAAATGGGAAGCCTCATCTCCATGTGCCCATGCAATTCGAGGGAAAATATGCATGCAAGAATAACAGATTCTTCGATCTGGCCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCAAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCAGTCTGCTAATGATTCATATGCCAAGGCGTTAAATGCAGATTCCGTTGAATCTGCCATGGCGGTTTTAAAAGAAGAACAGCCAAAAGATTTCGTTTTGCAGAATCATAACATCCGTGCCAACTTAGAAAGGATATTCGCTAAGGCTCCGGAGCCATGGTCTCCTCCGTTTCCCCTCTCCTCTTTCAATGCCGTTCCAGACGAGATGCAAGCATGGTCAGACGGTTATTTTGGAACAGATGCCGCTGCGCGGCCGGAGAGGCCTGTGAGTATCATAATTGAAGGCGACTCGAGGACAGGGAAGACGATGTGGGCTCGTGCCTTAGGCCCACACAATTATCTCAGTGGACACTTAGACTTCAATTCCCGGGTCTTTTCAAATGAAGTGGAATATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAGTCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAAGAGGAAAACACAGGTCTCAGGAACTGGACCATCAAGAATGCCAAATTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAATCCAAGAGGCGGGCAATCAGGAGGCGCAGGATTGA |
| Protein Sequence | MPSIKRFKINAKNYFITYPGCSLTKEEALSQLLNLSTPVNKKFIKICRELHQNGKPHLHVPMQFEGKYACKNNRFFDLASPTRSAHFHPNIQGAKSSSDVKSYIAKDGDTLEWGEFQIDGRSARGGCQSANDSYAKALNADSVESAMAVLKEEQPKDFVLQNHNIRANLERIFAKAPEPWSPPFPLSSFNAVPDEMQAWSDGYFGTDAAARPERPVSIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSRVFSNEVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENTGLRNWTIKNAKFITLTAPLYQEGTQAIQEAGNQEAQD |
| NCBI Accession | YP_004064948.1 |
|---|---|
| Location | 2052-2309 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGAAGCCTCATCTCCATGTGCCCATGCAATTCGAGGGAAAATATGCATGCAAGAATAACAGATTCTTCGATCTGGCCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCAAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGCAGAAGTGCTAGAGGAGGCTGCCAGTCTGCTAATGATTCATATGCCAAGGCGTTAA |
| Protein Sequence | MGSLISMCPCNSRENMHARITDSSIWPPQPGQHISIQTYRELNPAPTSSPTSQRTEIHWNGENSRSTAEVLEEAASLLMIHMPRR |
References More References in PubMed
| 1 |
De La Torre-Almaraz R, et al. Plant Dis. 2006 Mar;90(3):378. doi: 10.1094/PD-90-0378B. PMID: 30786574 |
|---|---|
| 2 |
First report of the complete sequence of Sida golden yellow vein virus from Jamaica. Stewart CS, et al. Arch Virol. 2011 Aug;156(8):1481-4. doi: 10.1007/s00705-011-1030-z. Epub 2011 May 29. PMID: 21625977 |
| 3 |
Bornancini VA, et al. Viruses. 2020 Feb 11;12(2):202. doi: 10.3390/v12020202. PMID: 32054104 |
| 4 |
Fiallo-Olivé E, et al. Arch Virol. 2012 Jan;157(1):141-6. doi: 10.1007/s00705-011-1123-8. Epub 2011 Oct 1. PMID: 21964921 |
| 5 |
Complete sequence of a new bipartite begomovirus infecting Sida sp. in Northeastern Brazil. Macedo MA, et al. Arch Virol. 2020 Jan;165(1):253-256. doi: 10.1007/s00705-019-04458-9. Epub 2019 Nov 22. PMID: 31758274 |
| 6 |
Stewart C, et al. Arch Virol. 2014 Sep;159(9):2509-12. doi: 10.1007/s00705-014-2063-x. Epub 2014 Apr 1. PMID: 24687859 |
| 7 |
Ferro CG, et al. Microorganisms. 2021 May 10;9(5):1018. doi: 10.3390/microorganisms9051018. PMID: 34068583 |
| 8 |
Domínguez M, et al. Plant Dis. 2002 Sep;86(9):1050. doi: 10.1094/PDIS.2002.86.9.1050A. PMID: 30818540 |
| 9 |
Frischmuth T, et al. J Gen Virol. 1997 Oct;78 ( Pt 10):2675-82. doi: 10.1099/0022-1317-78-10-2675. PMID: 9349490 |