Bean golden mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000841845.1 |
| Release date | 2015/2/12 |
| Submitter | Gilbertson,R.L., Faria,J.C., Hanson,S.F., Morales,F.J., Ahlquist,P.G., Maxwell,D.P., Russell,D.R., Hidayat,S.H., Martinez,R.T., Leong,S.A. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
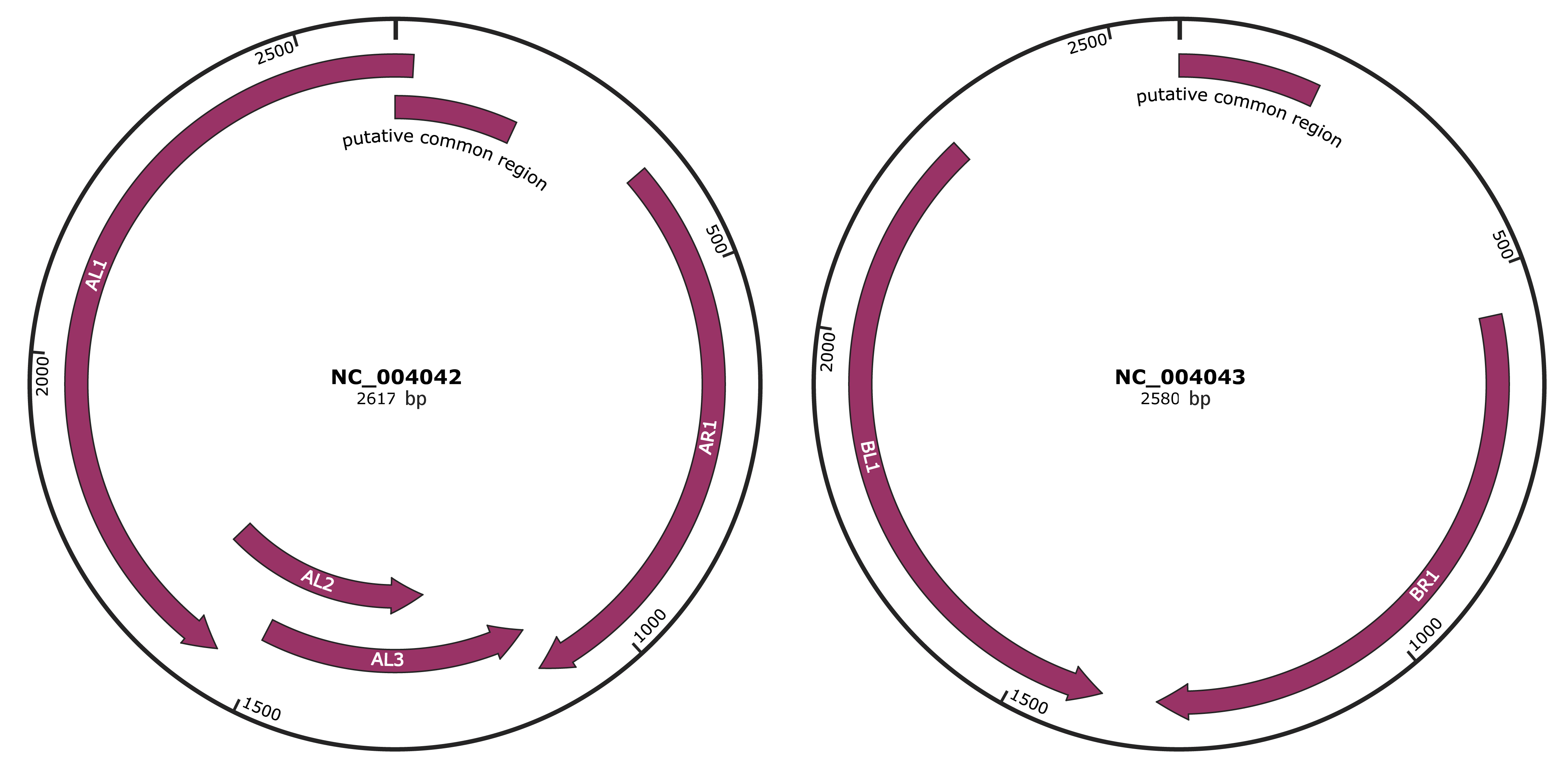
JBrowse
Genome
NC_004042
NC_004043
Gene Information
| NCBI Accession | NP_660081.1 |
|---|---|
| Location | 1556-2617,1-24 |
| Gene Name | AL1 |
| Protein Name | putative replicative protein |
| Coding Region | ATGCCACCACCAAAGCGTTTTAAAATAAACGCAAAGAATTATTTCCTCACATACCCACAATGTTCAATTACAAAAGAGAGTGCAATTGAACAACTTCAAAACCTACAAACACCGGTGAACAAGAAATACATCAGAATTTGCAGAGAAATTCACGAGAATGGGGAACCACATCTGCATGCTCTTATCCAATTCGAAGGCAAGTTCCAGTGCACGAATTGCAGAGTGTTCGACCTCAAACACCCAACAACATCTTCCGTCTCCCATGCCAATATACAGAGTGCAAAATCATCCTCTGATGTCAAGTCCTACATCGAGAAAGACGGTGATTACATCGAATGGGGTCATTTTCAAGTCGACGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGCGGCATCCGAAGCATTGAATGCTTCTTCAAAGGAAGAAGCCATGCAAATAATCAAAGAGAAACTACCGGAAAAGTTTCTCTTCCAATATCACAATTTATCCAGTAACCTGGATAGAATATTCACAAAAGCTCCGGATCCGTGGTCACCTCCGTATCACCTCTCCTCTTTTACTAACGTACCGAGAGAGATGCAAGAATGGGCAGATGATTATTTCGGGAGAGGTGCCGCTGCGCGGCCGGAGAGACCTATTAGTATCATCATCGAAGGTGATTCACGAACGGGGAAGACAATGTGGGCACGTGCATTAGGGACCCACAATTATTTAAGTGGTCACCTGGATTTCAACTCAAAGGTGTTTTCAAATCATGCTGAGTATAACGTCATTGATGACATCGCACCGCACTATCTAAAGTTAAAGCACTGGAAGGAATTGATGGGAGCTCAAAAGGACTGGCAATCAAACTGCAAATACGGGAAACCCGTTCAAATTAAAGGTGGAATCCCATCAATCGTGCTTTGCAATCCAGGTGAAGGAGCCAGTTATAAATGTTTCCTCGACAAAGAGGAAAACGCAGCTCTTAAAAACTGGACAATCCATAATGCGAAATTCATCTTCCTCAACTCCCCCCTCTATCAAAGTTCAACACAGAGCTGCGAAGAAACGAGCAATCAGACGACGTCGCGTTGA |
| Protein Sequence | MPPPKRFKINAKNYFLTYPQCSITKESAIEQLQNLQTPVNKKYIRICREIHENGEPHLHALIQFEGKFQCTNCRVFDLKHPTTSSVSHANIQSAKSSSDVKSYIEKDGDYIEWGHFQVDGRSARGGQQTANDAASEALNASSKEEAMQIIKEKLPEKFLFQYHNLSSNLDRIFTKAPDPWSPPYHLSSFTNVPREMQEWADDYFGRGAAARPERPISIIIEGDSRTGKTMWARALGTHNYLSGHLDFNSKVFSNHAEYNVIDDIAPHYLKLKHWKELMGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKCFLDKEENAALKNWTIHNAKFIFLNSPLYQSSTQSCEETSNQTTSR |
| NCBI Accession | NP_660082.1 |
|---|---|
| Location | 358-1113 |
| Gene Name | AR1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGTGATGCTCAATGGCGCCATATGGGAGGTACGTCAAAAATTAGCCGTTCTGCTAATTTTTCTCCTCGTGGGGGTAATGGGCCTAAATACAACAAGGCCGCCGAATGGGTAAATAGGCCTATGTACAGGAAGCCCAGGATATATCGAACGTTACGAGGCCCTGACGTTCCACGGGGCTGTGAAGGCCCGTGTAAGGTACAGTCCTATGAACAACGACATGATGTCTCTCATGTTGGGAAGGTTATGTGTGTATCTGATGTGACGAGAGGTAATGGTATTACCCATCGTGTAGGAAAACGTTTTTGTGTTAAGTCTGTTTATATTTTAGGTAAGATATGGATGGACGAAAATATCAAGTTGAAGAATCACACGAACAGTGTGATGTTTTGGTTAGTGAGAGATCGTAGACCGTATGGTACTCCTATGGACTTTGGTCAAGTTTTTAATATGTTTGACAATGAACCCAGTACTGCTACTGTTAAGAACGATCTTCGTGATCGTTTTCAAGTTATGCATAAGTTCTATGGAAAGGTAACAGGTGGACAATATGCTAGCAACGAGCAGGCATTGGTCAAGCGTTTTTGGAAGGTGAATAACTATGTAGTTTACAATCATCAAGAAGCAGGGAAGTACGAGAATCATACGGAGAACGCTTTATTATTGTATATGGCATGTACTCATGCCTCAAATCCCGTGTATGCTACTCTAAAAATTCGGATCTATTTTTATGATTCGATCACCAATTAA |
| Protein Sequence | MPKRDAQWRHMGGTSKISRSANFSPRGGNGPKYNKAAEWVNRPMYRKPRIYRTLRGPDVPRGCEGPCKVQSYEQRHDVSHVGKVMCVSDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYGKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | NP_660083.1 |
|---|---|
| Location | 1110-1508 |
| Gene Name | AL3 |
| Protein Name | AL3 protein |
| Coding Region | ATGGATTCACGCACAGGGGAACGCATCACTGCACGTCAAGCGGAGAATGGCGTGTATATCTGGGAGATATCAAATCCCCTTTATTTCAAGATGTACAACGTAGAGGATCTACAATACACAACGACCAGAGTATACCACCTCCAAATACGGTTCAACCACAACCTCAGGAACAAACTGGGTCTACACAAGGCTTTCCTGAATTTCCAAGTCTGGACGATATCTCTTCAAGCTTCTGGGACGACATATTTAAATAGATTTAAATATTTAGTGCTATTGTATTTAGATAGAATAGGTGTCATTTCGCTTAACAATGTAATCAGAGCTGTACGTTTCGCAACAGATAAATCATATGTAAATTATGTACTTGAGAATCATGAAATAAAATATAAATTTTATTAA |
| Protein Sequence | MDSRTGERITARQAENGVYIWEISNPLYFKMYNVEDLQYTTTRVYHLQIRFNHNLRNKLGLHKAFLNFQVWTISLQASGTTYLNRFKYLVLLYLDRIGVISLNNVIRAVRFATDKSYVNYVLENHEIKYKFY |
| NCBI Accession | NP_660084.1 |
|---|---|
| Location | 1255-1644 |
| Gene Name | AL2 |
| Protein Name | AL2 protein |
| Coding Region | ATGCGAAATTCATCTTCCTCAACTCCCCCCTCTATCAAAGTTCAACACAGAGCTGCGAAGAAACGAGCAATCAGACGACGTCGCGTTGATTTAGAGTGCGGCTGCACAATTTACGTACACATAAATTGCTCAGGACATGGATTCACGCACAGGGGAACGCATCACTGCACGTCAAGCGGAGAATGGCGTGTATATCTGGGAGATATCAAATCCCCTTTATTTCAAGATGTACAACGTAGAGGATCTACAATACACAACGACCAGAGTATACCACCTCCAAATACGGTTCAACCACAACCTCAGGAACAAACTGGGTCTACACAAGGCTTTCCTGAATTTCCAAGTCTGGACGATATCTCTTCAAGCTTCTGGGACGACATATTTAAATAG |
| Protein Sequence | MRNSSSSTPPSIKVQHRAAKKRAIRRRRVDLECGCTIYVHINCSGHGFTHRGTHHCTSSGEWRVYLGDIKSPLFQDVQRRGSTIHNDQSIPPPNTVQPQPQEQTGSTQGFPEFPSLDDISSSFWDDIFK |
| NCBI Accession | NP_660085.1 |
|---|---|
| Location | 558-1319 |
| Gene Name | BR1 |
| Protein Name | BR1 protein |
| Coding Region | ATGTATTTTTCGCGAAACAAACGTGGTGCCACTACTACTTCGAGACGAAGCTATTCAAGGTATCCCTTGTCTAGGCGTTCGTATAGTGTGAATAGAATCAATGGCAAACGTGGATCGAATATTCATAGAAAGGCCCATGATGATGGTAAAATGTTAGCCCAACGTTTACATGAGAATCAGTTTGGGCCTGAATTTGTCATGGCCCATAATTCAGCGATATCAACGTTTATTAATTTCCCTAGTCTTGGTAAGACTGAACCGAATCGATCAAAGAGCTTTATTAAGTTAAAACGTTTACGTTTTAAGGGTACTGTTAAAATTGAACGTGTTTTGAATATGGATGGTTCAACTCCTAAGATTGAAGGCGTATTTTCCATGGTCCTTGTTGTTGACCGAAAACCTCACTTGGGATCATCTGGATGTCTCCATACATTTGATGAATTGTTCGGTGCAAGGATTCATAGTCACGGTAATTTAGCCATTACTGCCACATTGAAAGAGCGATTCTATATACGTCATGTTTATAAGCGTGTGCTTTCAGTTGAGAAGGATAGCATGATGGTCGACGTCGAAGGAAGCACATACTTATCTAGTAGGCGTTTTAATTGTTGGGCTACATTTAAAGATGATGAACGTGACTCTTGTAATGGCGTTTATGCTAACATAAGCAAGAATGCTCTTTTAGTCTATTATTGTTGGATGTCGGATGCTATGTCCAAGGCATCTACGTTTGTATCATTTGATCTTGATTATGTTGGATGA |
| Protein Sequence | MYFSRNKRGATTTSRRSYSRYPLSRRSYSVNRINGKRGSNIHRKAHDDGKMLAQRLHENQFGPEFVMAHNSAISTFINFPSLGKTEPNRSKSFIKLKRLRFKGTVKIERVLNMDGSTPKIEGVFSMVLVVDRKPHLGSSGCLHTFDELFGARIHSHGNLAITATLKERFYIRHVYKRVLSVEKDSMMVDVEGSTYLSSRRFNCWATFKDDERDSCNGVYANISKNALLVYYCWMSDAMSKASTFVSFDLDYVG |
| NCBI Accession | NP_660086.1 |
|---|---|
| Location | 1391-2272 |
| Gene Name | BL1 |
| Protein Name | BL1 protein |
| Coding Region | ATGGAGTCTCAATTAGTTAATCCACCAACAGCGTTCAATTATGTAGAATCTAACCGTGATGAATATCAACTGTCTCATGACTTGAATGAGATAGTATTACAATTTCCTTCAACAACAGCTCAAATAAGCGCCAGATTAAGTCGAAGCTGTATGAAGATAGATCATTGCGTCATTGAATACAGGCAACAAGTTCCTATCAACGCAACAGGAACTGTGATTGTGGAGATTCACGACAAAAGAATGACGGATAATGAGTCATTACAAGCATCATGGACATATCCCATAAGGTGTAACATAGATCTCCACTTTTTTTCATCTTCATTCTTCTCCCTTAAAGACCCAATTCCCTGGAAATTGTATTACAGAGTTAGCGACACAAATGTTCATCAACGAACACACTTCGCAAAATTTAAGGGGAAACTGAAGATATCCACTGCGAAACATTCGGTGGATATTCCTTTCAAGCCCCCAACCGTGAAAATATTATCTACACAATTCACTGAGAAAGATGTGGATTTCTCCCACGTTGGTTACGGGAAATGGGAGAGGAAATTAATAAAGTCCGCATCCACATCTCGATATGGGCTTCACAGCCCAATTACATTAAAACCCGGTGAGACATGGGCAACAAGAAGTACAATAGGAACCGGTACTTCAGATGCGGACTCTGAATTAGACAACGCAGTACATCCATATAGACAACTTCATAGATTGGACACAAGTATTCTAGACCCTGGAGATTCCGCATCTATAGTTGGAGCGCGAAGAACCGAGTCAAGTATCACCCTTTCAATGGCCCAATTAAACGAATTGGTTAAAACTGCGGCCCAAGAATGTATTAACAGTAATTGTACTCCTGCTCAACCAAAGTCGTTGAAATAA |
| Protein Sequence | MESQLVNPPTAFNYVESNRDEYQLSHDLNEIVLQFPSTTAQISARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDNESLQASWTYPIRCNIDLHFFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKISTAKHSVDIPFKPPTVKILSTQFTEKDVDFSHVGYGKWERKLIKSASTSRYGLHSPITLKPGETWATRSTIGTGTSDADSELDNAVHPYRQLHRLDTSILDPGDSASIVGARRTESSITLSMAQLNELVKTAAQECINSNCTPAQPKSLK |
References More References in PubMed
| 1 |
Bonfim K, et al. Mol Plant Microbe Interact. 2007 Jun;20(6):717-26. doi: 10.1094/MPMI-20-6-0717. PMID: 17555279 |
|---|---|
| 2 |
Resistance to Bean Golden Mosaic Virus in Bean Genotypes. Bianchini A. Plant Dis. 1999 Jul;83(7):615-620. doi: 10.1094/PDIS.1999.83.7.615. PMID: 30845611 |
| 3 |
Alves-Freitas DMT, et al. Viruses. 2019 Jan 21;11(1):90. doi: 10.3390/v11010090. PMID: 30669683 |
| 4 |
de Paula NT, et al. Virus Res. 2015 Dec 2;210:245-7. doi: 10.1016/j.virusres.2015.08.012. Epub 2015 Aug 18. PMID: 26297125 |
| 5 |
Aragão FJ, et al. J Biotechnol. 2013 Jun 20;166(1-2):42-50. doi: 10.1016/j.jbiotec.2013.04.009. Epub 2013 Apr 29. PMID: 23639387 |
| 6 |
The composition of bean golden mosaic virus and its single-stranded DNA genome. Goodman RM, et al. Virology. 1980 Oct 15;106(1):168-72. doi: 10.1016/0042-6822(80)90236-6. PMID: 18631717 |
| 7 |
Nucleotide sequence of bean golden mosaic virus and a model for gene regulation in geminiviruses. Howarth AJ, et al. Proc Natl Acad Sci U S A. 1985 Jun;82(11):3572-6. doi: 10.1073/pnas.82.11.3572. PMID: 16593562 |
| 8 |
First Report and Characterization of Rhynchosia golden mosaic virus in Honduras. Potter JL, et al. Plant Dis. 2000 Sep;84(9):1045. doi: 10.1094/PDIS.2000.84.9.1045A. PMID: 30832009 |
| 9 |
Interactions between Common Bean Viruses and Their Whitefly Vector. Ferreira AL, et al. Viruses. 2024 Oct 2;16(10):1567. doi: 10.3390/v16101567. PMID: 39459901 |
| 10 |
Idris AM, et al. Plant Dis. 1999 Nov;83(11):1071. doi: 10.1094/PDIS.1999.83.11.1071C. PMID: 30841284 |