Sida golden mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000888355.1 |
| Isolate | USA: Bradenton, Florida |
| Release date | 2015/2/22 |
| Submitter | Al-Aqeel,H.A., Polston,J.E. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
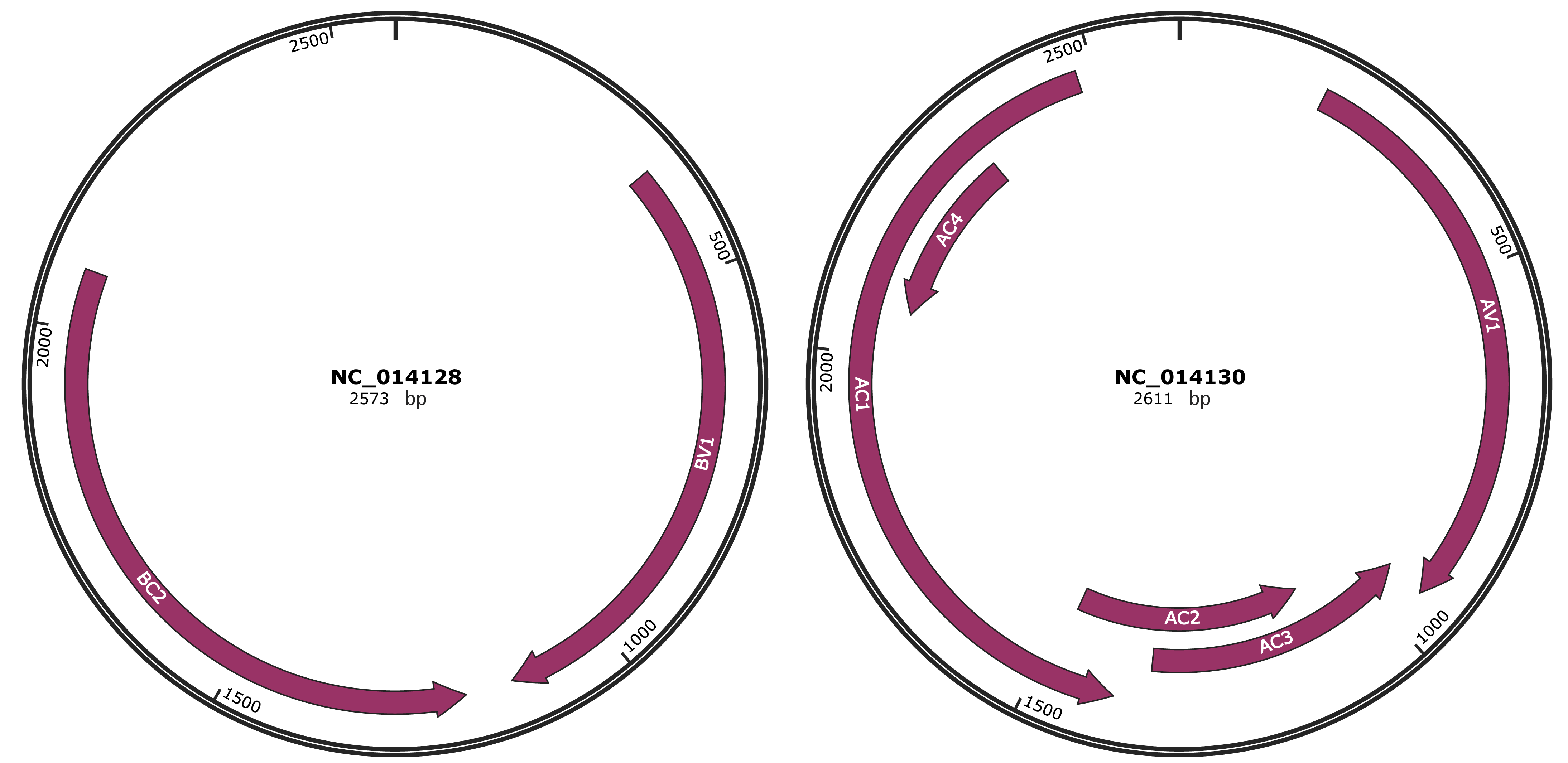
Genomic Organization
JBrowse
Genome
NC_014128
NC_014130
Gene Information
| NCBI Accession | YP_003620403.1 |
|---|---|
| Location | 357-1133 |
| Gene Name | BV1 |
| Protein Name | NSP |
| Coding Region | ATGATAATGTATCCTTCTAAGATTAAACGTGGTTTTTATTATCCTTATCGACGATTTAATACACGTAGCAATTTGTTTAACCGTTCAACCGCTGTGAAACGACATGATGCGAGACGTCGAAGAGGTCGATCTGTCAAGCCCACTGATGAGCCCAAGATGTCGGCCCAATCCATACATGAGAATCAGTATGGCTCTGATTTTGTCATGGCCCATAATTCAGCTATCTCTACGTTCATCAGTTTCCCAGACTTGGGCAAGATGGAACCGGGTCGAAGTAGGTCATATATCAAGTTGAAACGACTTCGTTTCAAAGGGACTGTGAAGATTGAACGTGTGCAATCGGATCTGAACATGGACGGGACTGTCCCCAAAATTGAAGGAGTTTTCTCCCTTGTTGTTGTTGTGGATCGTAAACCCCACTTGGGTCCAAGTGGTTGTCTGCATACATTTGACGAGTTGTTCGGAGCAATCATTCACAGTCATGGCAATCTCAGCATTGTCCCTTCTCTGAAAGACCGTTATTATATTCGCCACGTGTTCAAACGTGTATTGTCATTGGAAAATGACACGCTGATGGTCGACGTCGAAGGATCTACTTCTCTATCTGACAGGCGTTTTAATTGTTGGTCCACTTTTAAAGACGTGGATCGTGATTCATGCAAGGGTGTTTATGATAATATAAGCAAGAACGCTCTGCTAATTTATTATTGCTGGGTGTCCGAAACGCCTTCAAAGGCCTCTAATTATGTATCTTTTGATCTTGACTATGTTGGCTAA |
| Protein Sequence | MIMYPSKIKRGFYYPYRRFNTRSNLFNRSTAVKRHDARRRRGRSVKPTDEPKMSAQSIHENQYGSDFVMAHNSAISTFISFPDLGKMEPGRSRSYIKLKRLRFKGTVKIERVQSDLNMDGTVPKIEGVFSLVVVVDRKPHLGPSGCLHTFDELFGAIIHSHGNLSIVPSLKDRYYIRHVFKRVLSLENDTLMVDVEGSTSLSDRRFNCWSTFKDVDRDSCKGVYDNISKNALLIYYCWVSETPSKASNYVSFDLDYVG |
| NCBI Accession | YP_003620404.1 |
|---|---|
| Location | 1195-2076 |
| Gene Name | BC2 |
| Protein Name | MP |
| Coding Region | ATGGATTCTCAGTTGGTCAATCCTCCGAACGCTTTCAATTACATAGAATCTCACCGAGACGAGTATCAACTTTCTCATGACCTAACTGAGATAATACTGCAATTTCCTTCAACGGCGTCGCAATTAACAGCTAGACTCAGTCGTAGCTGCATGAAGATAGACCATTGCGTCATAGAATACAGACAACAAGTTCCGATCAACGCCACAGGGTCAGTAATCGTGGAGATTCACGACAAAAGAATGACAGACAATGAGTCTTTACAGGCGTCGTGGACTTTTCCGATCAGGTGCAACATAGATCTCCACTATTTCTCGGCTTCGTTCTTCTCATTAAAAGACCCAATTCCATGGAAGTTGTACTATCGCGTTTGCGATACAAATGTTCATCAACGGACTCACTTCGCCAAATTCAAAGGGAAACTGAAATTGTCCACAGCAAAACACTCGGTCGACATCCCCTTCCGGGCACCAACAGTGAAGATCCTGTCCAAACAGTTCACAGACAAAGATGTGGACTTTTCTCATGTGGACTATGGGAAATGGGAGAGGAAGCCCATCAGATGCGCGTCCATGTCCAGGGTTGGGTTACGCGGCCCAATCGAGATCAGGCCTGGTGAATCATGGGCTTCCAGAAGTACAATAGGAACGGCCCAGTCAGATGCGGAATCAGAAGTGGAGAACGAACTCTATCCATACAGACACCTAAACAGACTGGGGACCAGCGTTCTAGACCCAGGAGAGTCTGCTTCCATTGTGGGAGCCCAGAGAGCGGAGTCAAACATCACAATGTCAATGGGCCAGTTGAATGAGATAGTCAGAACTACAGTCCGGGAATGTATTAATAGTAATTGTCAGGTTAATCAGGCCAAATCACTGAAATAA |
| Protein Sequence | MDSQLVNPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRVGLRGPIEIRPGESWASRSTIGTAQSDAESEVENELYPYRHLNRLGTSVLDPGESASIVGAQRAESNITMSMGQLNEIVRTTVRECINSNCQVNQAKSLK |
| NCBI Accession | YP_003620405.1 |
|---|---|
| Location | 195-950 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCTAAGCGCGATGGCTCTTGGCGCTCTATGGAGGGAATTTCAAAAGTGAAACGTACTCTGAATTTCTCCCCTCGTGGAGGAGGTGGGCCAAAAATGTCAAGGGCCGCCGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTAAAGACACCTGGTGTGCCCAGAGGATGTGAAGGCCCGTGCAAGGTCCAGTCTTATGAACAGCGCCACGACATATCCCATGTGGGTAAGGTCATGTGCATCTCTGACGTGACACGTGGTAATGGCATTACCCATCGCGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATCCTTGGTAAGATCTGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCCTATGGAACTCCAATGGATTTCGGCCAGGTGTTCAACATGTTCGACAACGAGCCAAGCACTGCTACGGTGAAGAATGATCTACGCGATCGTTACCAGGTCATGCACAAGTTCTATGGCAAGGTGACCGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTTAAGAGGTTCTGGAAGGTCTACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTACGAGAATCATACAGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCATCTAACCCCGTGTATGCAACGCTTAAGATCCGAATCTATTTCTACGATTCGATCACAAATTAA |
| Protein Sequence | MSKRDGSWRSMEGISKVKRTLNFSPRGGGGPKMSRAAEWVNRPMYRKPRIYRTLKTPGVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVYNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_003620406.1 |
|---|---|
| Location | 947-1345 |
| Gene Name | AC3 |
| Protein Name | REn |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGTACCTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCACGATGTACCAAATAGAAGACCCGTTGTACACGAACACCAGAATATACACGCTACAAATACGATTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGATATCGATGACAGCTTCTGGGTCGACTTATTTAGCTAGATTTAAGCGCTTAGTTAATTTGTATTTAGATAGGTTAGGCGTGATTTCAATTAACAATGTAATCAGAGCTGTACGATTCGCGACAGACAGATCGTATGTAACTTATGTTCCAGAAAATCATGTAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MDSRTGELITVPQAENGVYIWEIENPLYFTMYQIEDPLYTNTRIYTLQIRFNHNLRKALHLHKAFLNFQVWTISMTASGSTYLARFKRLVNLYLDRLGVISINNVIRAVRFATDRSYVTYVPENHVIKFKIY |
| NCBI Accession | YP_003620407.1 |
|---|---|
| Location | 1092-1481 |
| Gene Name | AC2 |
| Protein Name | TrAP |
| Coding Region | ATGCGCTCTTCATCACCCTCACATCCGCCCTCTATCAAACAGAAACACAAGCAAGCCAAGAAGAGGGCCATCAGGAGACGGCGGATTGATCTAGAGTGCGGTTGCTCCATTTACTTCCACATAGGCTGCACCGGGCATGGATTCACGCACAGGGGAACTCATCACTGTACCTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCACGATGTACCAAATAGAAGACCCGTTGTACACGAACACCAGAATATACACGCTACAAATACGATTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGATATCGATGACAGCTTCTGGGTCGACTTATTTAGCTAG |
| Protein Sequence | MRSSSPSHPPSIKQKHKQAKKRAIRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSGREWRVYLGDRKSPLFHDVPNRRPVVHEHQNIHATNTIQPQPEESVASPQSLPELPSLDDIDDSFWVDLFS |
| NCBI Accession | YP_003620408.1 |
|---|---|
| Location | 1393-2478 |
| Gene Name | AC1 |
| Protein Name | REP protein |
| Coding Region | ATGCCACGAAAGGGTTCTTTCTCAGTTAAAGCCAAAAACTATTTCCTCACATATCCGCAGTGCTCCATCACCAAAGAGGAAGCACTTTCCCAATTACAAACATTAAATACTCCGGTGAACAAGAAGTTCATCAAAATTTGCAGAGAGCTTCACGAAAATGGGGAGCCTCATATCCATGTGCTCATCCAGTTCGAGGGGAAGTACAACTGCACGAATAACAGATTCTTCGATCTGGTGTCCCCAACCAGTTCAGTACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAAGACGGGGACACCATTGAATGGGGAGTGTTCCAGATCGACGGAAGAAGTGCTCGCGGAGGTCAGCAAACATCTAATGATGCAGCCGCCGAGGCATTGAATTCTGGAACAAAGGAGGCGGCACTGAAAATCATCAGAGAAAAGTTGCCGGAAAAATATCTTTTCCAATATCACAACCTATCCAGTAACCTCGATAGGATTTTCAGTAAGTCTCCGGATCCATGGTCTCCTCCGTTTCCCCTCTCCTCTTTCACTGCCGTTCCTGAAGAAATGCAAGACTGGGCGGACAGTTATTTTGGGAGAGGTTCCGCTGCGCGGCCAGATAGACCAGTAAGTATCATAGTGGAAGGTGACTCAAGGACAGGTAAGACAATGTGGGCTCGTGCGTTAGGCCCACATAATTATCTCAGTGGACATCTGGACTTCAATCCCCGGGTATATTCAAATGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGTTGAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAGTCAAATTGCAAATACGGCAAACCAGTTCAAATTAAAGGCGGGATTCCATCAATCGTGCTTTGCAATCCGGGTGAGGGTGCCAGCTATAAAGACTTCCTAGACAAAGAGGAAAACACAGGTCTAAAGAATTGGACCCTGAAGAATGCGCTCTTCATCACCCTCACATCCGCCCTCTATCAAACAGAAACACAAGCAAGCCAAGAAGAGGGCCATCAGGAGACGGCGGATTGA |
| Protein Sequence | MPRKGSFSVKAKNYFLTYPQCSITKEEALSQLQTLNTPVNKKFIKICRELHENGEPHIHVLIQFEGKYNCTNNRFFDLVSPTSSVHFHPNIQGAKSSSDVKSYVEKDGDTIEWGVFQIDGRSARGGQQTSNDAAAEALNSGTKEAALKIIREKLPEKYLFQYHNLSSNLDRIFSKSPDPWSPPFPLSSFTAVPEEMQDWADSYFGRGSAARPDRPVSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNPRVYSNEVEYNVIDDVAPHYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENTGLKNWTLKNALFITLTSALYQTETQASQEEGHQETAD |
| NCBI Accession | YP_003620409.1 |
|---|---|
| Location | 2064-2321 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGGAGCCTCATATCCATGTGCTCATCCAGTTCGAGGGGAAGTACAACTGCACGAATAACAGATTCTTCGATCTGGTGTCCCCAACCAGTTCAGTACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAAGACGGGGACACCATTGAATGGGGAGTGTTCCAGATCGACGGAAGAAGTGCTCGCGGAGGTCAGCAAACATCTAATGATGCAGCCGCCGAGGCATTGA |
| Protein Sequence | MGSLISMCSSSSRGSTTARITDSSIWCPQPVQYISIRTYRELNPAPTSSPTSRKTGTPLNGECSRSTEEVLAEVSKHLMMQPPRH |
References More References in PubMed
| 1 |
Characterization of sida golden mottle virus isolated from Sida santaremensis Monteiro in Florida. Al-Aqeel HA, et al. Arch Virol. 2018 Oct;163(10):2907-2911. doi: 10.1007/s00705-018-3903-x. Epub 2018 Jun 21. PMID: 29931396 |
|---|---|
| 2 |
First Report of Sida golden mosaic virus Infecting Snap Bean (Phaseolus vulgaris) in Florida. Durham TC, et al. Plant Dis. 2010 Apr;94(4):487. doi: 10.1094/PDIS-94-4-0487B. PMID: 30754495 |
| 3 |
De La Torre-Almaraz R, et al. Plant Dis. 2006 Mar;90(3):378. doi: 10.1094/PD-90-0378B. PMID: 30786574 |
| 4 |
Fiallo-Olivé E, et al. Arch Virol. 2012 Jan;157(1):141-6. doi: 10.1007/s00705-011-1123-8. Epub 2011 Oct 1. PMID: 21964921 |
| 5 |
Croton golden mosaic virus: a new bipartite begomovirus isolated from Croton hirtus in Colombia. Vaca-Vaca JC, et al. Arch Virol. 2018 Nov;163(11):3199-3202. doi: 10.1007/s00705-018-3989-1. Epub 2018 Aug 10. PMID: 30097742 |
| 6 |
Geminiviruses Infecting Tomato Crops in Nicaragua. Rojas A, et al. Plant Dis. 2000 Aug;84(8):843-846. doi: 10.1094/PDIS.2000.84.8.843. PMID: 30832136 |
| 7 |
Ramos PL, et al. Arch Virol. 2003 Sep;148(9):1697-712. doi: 10.1007/s00705-003-0136-3. PMID: 14505083 |
| 8 |
Collins AM, et al. Virus Genes. 2009 Dec;39(3):387-95. doi: 10.1007/s11262-009-0401-y. Epub 2009 Sep 20. PMID: 19768650 |
| 9 |
Two new begomoviruses infecting tomato and Hibiscus sp. in the Amazon region of Brazil. Quadros AFF, et al. Arch Virol. 2019 Jul;164(7):1897-1901. doi: 10.1007/s00705-019-04245-6. Epub 2019 Apr 10. PMID: 30972592 |
| 10 |
Complete sequence of a new bipartite begomovirus infecting Sida sp. in Northeastern Brazil. Macedo MA, et al. Arch Virol. 2020 Jan;165(1):253-256. doi: 10.1007/s00705-019-04458-9. Epub 2019 Nov 22. PMID: 31758274 |