Sida golden mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000837905.1 |
| Release date | 2015/2/12 |
| Submitter | Abouzid,A.M., Polston,J.E., Hiebert,E. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
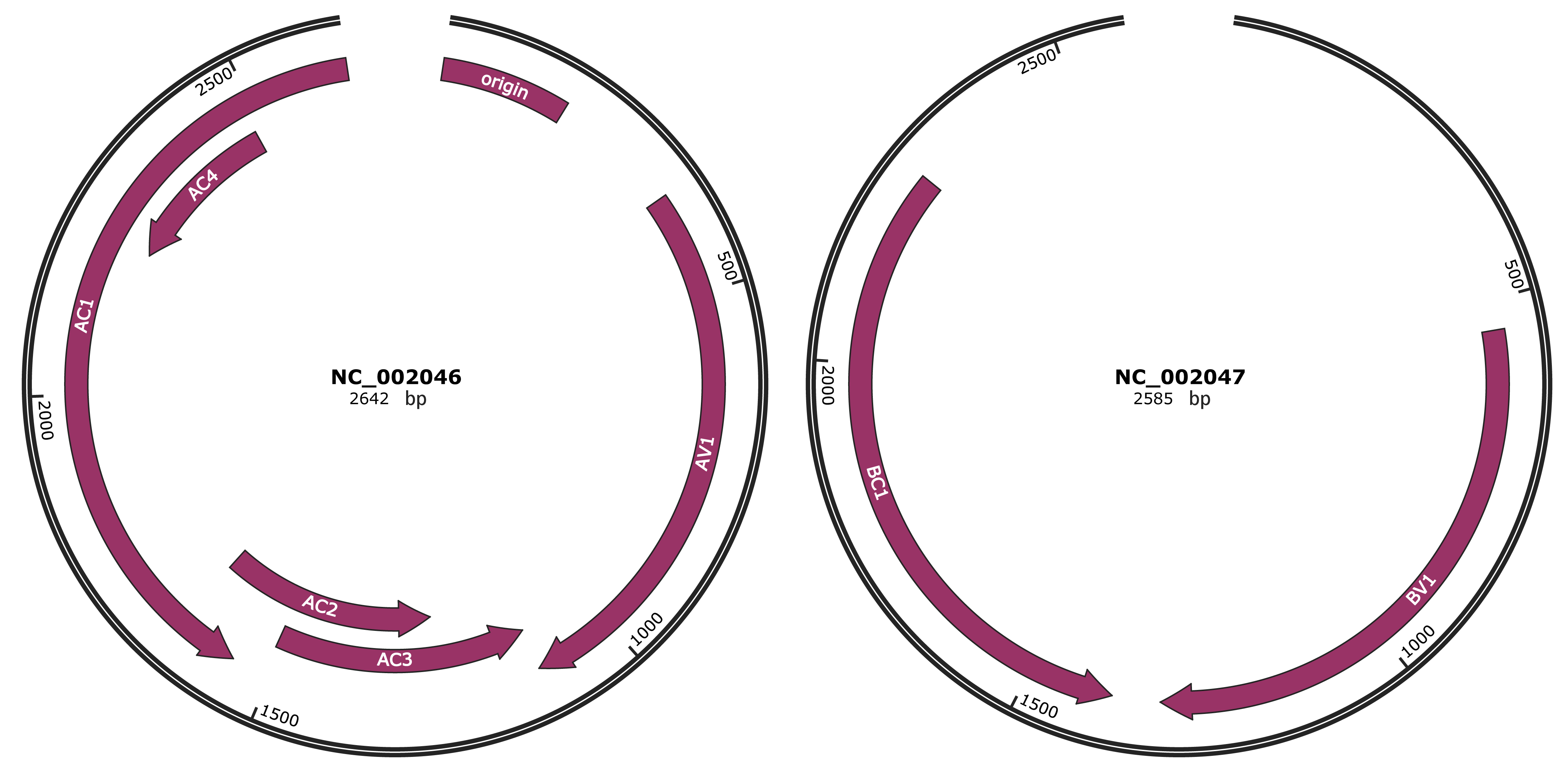
JBrowse
Genome
NC_002046
NC_002047
Gene Information
| NCBI Accession | NP_049345.1 |
|---|---|
| Location | 359-1114 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGAATTGCCATGGCGCTCTATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTATTCTCCTCGTGCAGGTAGTGGGCCAAGAGTTCACAAGGCCTCTGAATGGGTAAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGATGGTGAGGACCCCCGATGTGCCCAGAGGCTGTGAAGGCCCTTGCAAGGTCCAGTCTTATGAACAGCGTCACGACATCTCCCATGTCGGGAAGGTCATGTGCATTTCCGATGTGACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTCTAGGGAAGATTTGGATGGACGAGAACATTAAGCTGAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCGTATGGCACGCCTATGGATTTCGGTCAGGTGTTCAACATGTTCGATAACGAGCCTAGTACTGCCACGGTGAAGAACGATCTCCGTGATCGTTACCAGGTCATGCATAAGTTCTATGGCAAGGTCACTGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTGAAGAGATTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTATGAGAATCACACTGAGAACGCCCTGTTATTGTATATGGCATGTACCCATGCCTCTAATCCTGTGTATGCAACTCTGAAGATCCGAATCTATTTCTATGATTCGCTTATGAATTAA |
| Protein Sequence | MPKRELPWRSMAGTSKVSRNANYSPRAGSGPRVHKASEWVNRPMYRKPRIYRMVRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSLMN |
| NCBI Accession | NP_049346.1 |
|---|---|
| Location | 1111-1509 |
| Gene Name | AC3 |
| Protein Name | AC3 |
| Coding Region | ATGGATTCACGCACAGGGGAATTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATATACAGTGTAGAGGACCCGCTATACACCAGAACGAGGATATACCACGTACAGATAAGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTTTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAGGTTTCTGCGTTTGGTCAACATGTACTTAGATCAATTAGGCATTATCTCCTTAAACAATGTAATTAGAGCTGTACGTTTCGCGACAGACAGAGCGTATGTAAATCATGTACTGGAAAATCATTCAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTGEFITAHQAENGVYIWEIENPLYFRIYSVEDPLYTRTRIYHVQIRFNHNLRRALHLHKAFLNFQVWTTSMTASGSTYLARFLRLVNMYLDQLGIISLNNVIRAVRFATDRAYVNHVLENHSIKFKFY |
| NCBI Accession | NP_049347.1 |
|---|---|
| Location | 1256-1645 |
| Gene Name | AC2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGCAAGCACACAGGCAGGCCAAGAGGAGGGCCATACGGAGGCGGAGAATTGACCTAAATTGCGGGTGCTCCATCTACTTCCACATAGGCTGTACGGGACATGGATTCACGCACAGGGGAATTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAGGATATACAGTGTAGAGGACCCGCTATACACCAGAACGAGGATATACCACGTACAGATAAGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTTTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGCTAG |
| Protein Sequence | MRSSSPSQPPSIKQAHRQAKRRAIRRRRIDLNCGCSIYFHIGCTGHGFTHRGIHHCTSGGEWRVYLGDRKSPLFQDIQCRGPAIHQNEDIPRTDKVQPQPEESVASPQSLPELPSLDDIDDSFWVNLFS |
| NCBI Accession | NP_049348.1 |
|---|---|
| Location | 1557-2642 |
| Gene Name | AC1 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCACCGCCAAAGAAATTTAGAGTTCAGTCCAAAAACTATTTGGTCACTTATCCACAGTGCTCTCTGACCAAAGAAGAAGCACTTTCCCAATTACAAAGCCTAAATACCACAGTGAACAAGAAGTTCATCAAAATCTGCAGAGAGCTTCACGAAAATGGGGAGCCTCATCTCCATGTGCTCTTACAGTTCGAAGGGAAATACCAGTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCTTACATCGACAAGGACGGTGATACAGTGGAATGGGGAGAGTTCCAGATCGACGGCAGATCAGCTAGAGGAGGCCAGCAGACTGCTAATGATTCATATGCAAAGGCGTTAAATGCAGATTCTGTTCAATCTGCCTTAGCGGTTTTAAGGGAAGAACAGCCAAAAGATTTTGTCTTGCAGAATCATAACATCCGCTCCAACTTAGAGAGGATATTCGCCAAGGCTCCGGAACCGTGGGTTCCTCCATTTCAACTCTCCTCTTTCACTAACGTTCCCGACGAGATGCAAGAATGGGCGGATGAATTTTTTGGTTCGGGTTCCGCTGCGCGGCCAGACAGACCATTAAGTCTCATAGTAGAAGGTGATTCAAGAACAGGGAAGACGATGTGGGCACGTGCGTTAGGCCCACATAATTACCTCAGTGGACACCTGGACTTCAATGGTCGAGTCTATTCGAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAAAAAGATTGGCAGTCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGTGGAATCCCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGAGTTCCTAGACAAGGAGGAAAATACAGGTCTCAGGAACTGGACTATCAAGAATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGCAAGCACACAGGCAGGCCAAGAGGAGGGCCATACGGAGGCGGAGAATTGA |
| Protein Sequence | MPPPKKFRVQSKNYLVTYPQCSLTKEEALSQLQSLNTTVNKKFIKICRELHENGEPHLHVLLQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTVEWGEFQIDGRSARGGQQTANDSYAKALNADSVQSALAVLREEQPKDFVLQNHNIRSNLERIFAKAPEPWVPPFQLSSFTNVPDEMQEWADEFFGSGSAARPDRPLSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNGRVYSNEVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKEFLDKEENTGLRNWTIKNAIFITLTAPLYQASTQAGQEEGHTEAEN |
| NCBI Accession | NP_049349.1 |
|---|---|
| Location | 2228-2485 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGGAGCCTCATCTCCATGTGCTCTTACAGTTCGAAGGGAAATACCAGTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCTTACATCGACAAGGACGGTGATACAGTGGAATGGGGAGAGTTCCAGATCGACGGCAGATCAGCTAGAGGAGGCCAGCAGACTGCTAATGATTCATATGCAAAGGCGTTAA |
| Protein Sequence | MGSLISMCSYSSKGNTSARITDSSIWSPQPGQHISIQTYRELNPAPTSSLTSTRTVIQWNGESSRSTADQLEEASRLLMIHMQRR |
| NCBI Accession | NP_049350.1 |
|---|---|
| Location | 542-1318 |
| Gene Name | BV1 |
| Protein Name | nuclear transport protein |
| Coding Region | ATGATAATGTATCCTGTGAGGGTTAAACGTGGTTATTACTTCCCTAACCGACGATTTACTACACGTAACACTGTGTTTAACCGTTCAACCGCTGGGAAACGACATGATGGGAGACGTCGAGGAGGTCGATCTGTCAAGACCAGTGATGAGCCCAAGATGTCAGCCCAATCCATACATGAGAATCAGTATGGCCCTGATTTTGTGATGTCTCACAATTCAGCCATTTCCACATTTATCAGTTATCCAGATCTGGGCAAGATAGAACCGGGTCGAAGTAGGTCCTATATCAAGTTGAAACGACTCCGTTTCAAAGGGACTGTTAAGATTGAACGTGTCACATCGGACGTGAACATGGACGGTTCTGCGCCAAAGGTCGAAGGAGTATTCTCACTGGTTGTGGTTGTGGATCGTAAACCCCACTTGACTGCATCTGGTGGTCTACATACATTCGACGAGCTGTTCGGTGCAAGGATCCACAGCCATGGTAATCTCAGCATAACCCCTTCCCTGAAAGACCGCTTTTACGTAAGACACGTGTTCAAACGTGTACTGTCCGTGGAGAAGGATACGCTTATGGTCGACGTGGAAGGCTCCACAGCACTCTCTAACAGGCGAATCAACTGCTGGTCCACGTTTAAGGATCTTGAACGTGATTCATGCAAGGGTGTCTATGGCAACGTCAGCAAGAACGCCCTCTTAGTTTATTATTGTTGGATGTCAGATACTGTGTCTAAGGCATCCTCATTTGTATCTTTCGACCTTGATTATGTCGGTTGA |
| Protein Sequence | MIMYPVRVKRGYYFPNRRFTTRNTVFNRSTAGKRHDGRRRGGRSVKTSDEPKMSAQSIHENQYGPDFVMSHNSAISTFISYPDLGKIEPGRSRSYIKLKRLRFKGTVKIERVTSDVNMDGSAPKVEGVFSLVVVVDRKPHLTASGGLHTFDELFGARIHSHGNLSITPSLKDRFYVRHVFKRVLSVEKDTLMVDVEGSTALSNRRINCWSTFKDLERDSCKGVYGNVSKNALLVYYCWMSDTVSKASSFVSFDLDYVG |
| NCBI Accession | NP_049351.1 |
|---|---|
| Location | 1385-2266 |
| Gene Name | BC1 |
| Protein Name | movement/pathogenicity protein |
| Coding Region | ATGGAATCTCAGTTAGTAAATCCTCCGAGTGCCTTCAACTACATAGAGTCTCACCGGGACGAGTATCAACTTTCACATGACCTAACTGAGATAATTCTGCAATTCCCGTCGACGGCGTCGCAGTTGACGGCGAGGCTCAGTCGTAGCTGTATGAAGATCGACCACTGCGTCATAGAGTACAGGCAGCAGGTACCCATCAACGCGACGGGTTCGGTGATAGTGGAGATCCACGACAAAAGGATGACGGACAACGAGTATTTGCAGGCGTCGTGGACTTTTCCGATCAGATGCAACATAGATCTCCACTACTTTTCAGCTTCGTTCTTCTCGCTCAAGGACCCAATTCCATGGAAATTGTACTACAGGGTCTGCGATACGAATGTTCATCAGAGGACCCACTTCGCGAAGTTCAAGGGGAAGCTGAAATTGTCGACGGCGAAGCACTCCGTAGATATACCCTTCCGGGCACCGACAGTGAAAATCCTGTCCAAACAGTTCACCGATAAAGATGTGGACTTCTCCCACGTCGACTACGGAAGATGGGAAAGGAAGCCCATCAGATGCGGGTCCATGTCCAGGGTTGGATTAAGAGGCCCAATTGAAATCAGGCCTGGTGAGTCGTGGGCTTCCAGAAGCACCATAGGCGTGGCCCAATCAGATGCGGATTCGGAGGTGGAGAACGAGATCCACCCATACAGACACCTGAACAGGCTGGGGACCAGCGTTCTGGACCCAGGAGAGTCTGCTTCTATTGTGGGAGCCCAGAGAGCGGTATCGAACATCACGATGTCGATGGGCCAATTAAACGAACTAGTTAGGACAACTGTCCAAGAGTGTATTAATAGTAATTGTAGGGCTTCTCAGCCAAAATCATTGCAATAA |
| Protein Sequence | MESQLVNPPSAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNEYLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKPIRCGSMSRVGLRGPIEIRPGESWASRSTIGVAQSDADSEVENEIHPYRHLNRLGTSVLDPGESASIVGAQRAVSNITMSMGQLNELVRTTVQECINSNCRASQPKSLQ |
References More References in PubMed
| 1 |
Gautam S, et al. Viruses. 2023 Jan 26;15(2):357. doi: 10.3390/v15020357. PMID: 36851571 |
|---|---|
| 2 |
Codod CB, et al. Plant Dis. 2024 Jun;108(6):1776-1785. doi: 10.1094/PDIS-09-23-1901-RE. Epub 2024 Jun 6. PMID: 38243178 |
| 3 |
Characterization of sida golden mottle virus isolated from Sida santaremensis Monteiro in Florida. Al-Aqeel HA, et al. Arch Virol. 2018 Oct;163(10):2907-2911. doi: 10.1007/s00705-018-3903-x. Epub 2018 Jun 21. PMID: 29931396 |
| 4 |
First Report of Sida golden mosaic virus Infecting Snap Bean (Phaseolus vulgaris) in Florida. Durham TC, et al. Plant Dis. 2010 Apr;94(4):487. doi: 10.1094/PDIS-94-4-0487B. PMID: 30754495 |
| 5 |
Complete Genome Sequence of a New Strain of Sida Golden Mosaic Buckup Virus from Florida, USA. Iqbal Z, et al. Microbiol Resour Announc. 2020 Jan 9;9(2):e01115-19. doi: 10.1128/MRA.01115-19. PMID: 31919159 |
| 6 |
Fiallo-Olivé E, et al. Arch Virol. 2010 Sep;155(9):1535-7. doi: 10.1007/s00705-010-0761-6. Epub 2010 Jul 31. PMID: 20677027 |
| 7 |
Croton golden mosaic virus: a new bipartite begomovirus isolated from Croton hirtus in Colombia. Vaca-Vaca JC, et al. Arch Virol. 2018 Nov;163(11):3199-3202. doi: 10.1007/s00705-018-3989-1. Epub 2018 Aug 10. PMID: 30097742 |
| 8 |
Collins AM, et al. Virus Genes. 2009 Dec;39(3):387-95. doi: 10.1007/s11262-009-0401-y. Epub 2009 Sep 20. PMID: 19768650 |
| 9 |
First Report of Sida micrantha mosaic virus in Phaseolus vulgaris in Brazil. Fernandes-Acioli NAN, et al. Plant Dis. 2011 Sep;95(9):1196. doi: 10.1094/PDIS-05-10-0343. PMID: 30732032 |
| 10 |
First report of the complete sequence of Sida golden yellow vein virus from Jamaica. Stewart CS, et al. Arch Virol. 2011 Aug;156(8):1481-4. doi: 10.1007/s00705-011-1030-z. Epub 2011 May 29. PMID: 21625977 |