Sida golden mosaic Buckup virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000889555.1 |
| Isolate | Jamaica |
| Release date | 2015/2/22 |
| Submitter | Stewart,C.S., Kon,T., Gilbertson,R.L., Roye,M.E., Gilbertson,B.L. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
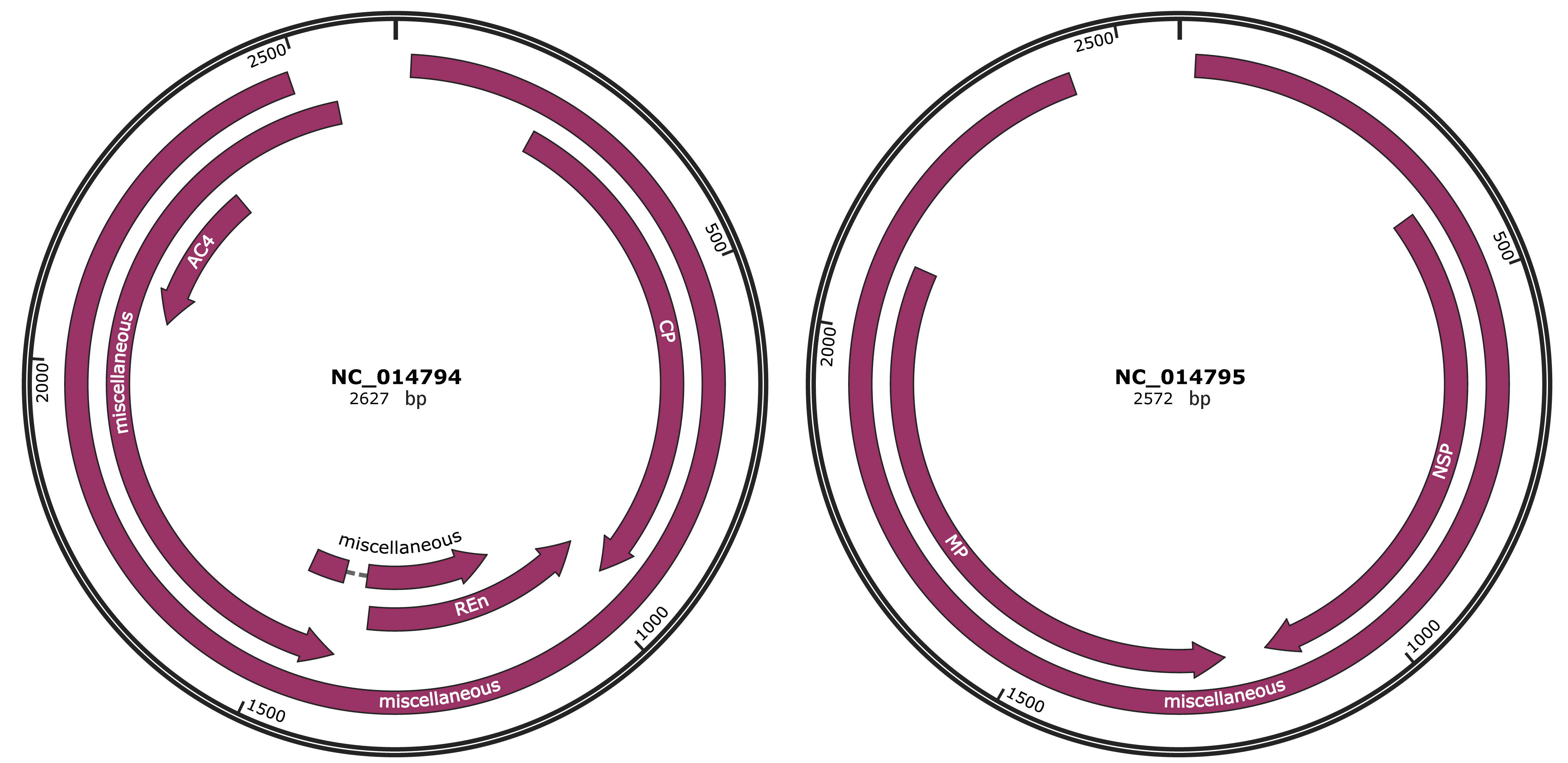
JBrowse
Genome
NC_014794
NC_014795
Gene Information
| NCBI Accession | YP_004063987.1 |
|---|---|
| Location | 211-966 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGTCTAAGCGCGATGGCTCTTGGCGCTCTATCGCGGGAATGTCAAAAGTGAAACGCACTTTGAATTTCTCCCCTCGTGGAGGTGGTGGGCCGACAAGTTCAAGGGCCGCTGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATACCGGACGCTAAAAACACCCGGAGTGCCCAGAGGCTGTGAAGGCCCGTGTAAGGTCCAGTCGTATGAGCAACGCCACGACATCTCTCATGTGGGAAAGGTCATGTGCATCTCCGATGTGACACGTGGTAATGGCATTACCCATCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATCCTTGGTAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGACCGTAGACCCTATGGCACGCCAATGGATTTTGGCCAAGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCTACGGTGAAGAACGATCTTCGTGATCGTTATCAAGTGATGCACAAGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTCAAACGATTCTGGAAGGTCTACAATCATGTGGTCTACAACCATCAAGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCGTCTAATCCCGTGTATGCAACTTTGAAGATCAGAATCTATTTCTACGATTCGATCACTAATTAA |
| Protein Sequence | MSKRDGSWRSIAGMSKVKRTLNFSPRGGGGPTSSRAAEWVNRPMYRKPRIYRTLKTPGVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVYNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_004063988.1 |
|---|---|
| Location | 963-1361 |
| Gene Name | REn |
| Protein Name | replication enhancer |
| Coding Region | ATGGATTCACGCACCGGGGAACTCATCACTGTACCTCAGGCAGAGAATGGCGTATATACCTGGGAGATAGAAAATCCCCTACATTTCAGGATGTACCAAGTAGAGGACCCGTTGTACACGAACACCAGGATATACACCATACAAATACGGTTCAACCACAACCTGAGGAAAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGATATCGATGACAGCTTCTGGGTCGACTTATTTAGCTAGATTTAGTCGCTTAGTTAATTTATATTTAGATAGATTAGGCGTGATTTCAATTAACAATGTAATTAGAGCTGTACGATTCGCGACAAACAGATCGTATATCGAACATGTACTGGAAAATCATTCAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MDSRTGELITVPQAENGVYTWEIENPLHFRMYQVEDPLYTNTRIYTIQIRFNHNLRKALHLHKAFLNFQVWTISMTASGSTYLARFSRLVNLYLDRLGVISINNVIRAVRFATNRSYIEHVLENHSIKFKIY |
| NCBI Accession | YP_004063989.1 |
|---|---|
| Location | 2078-2335 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGGAGCCTCATCTCCACGTTCTCATACAGTTCGAAGGCAAGTACCAGTGCACGAATAACAGATTCTTCGATATGGTGTCCCCAACCAGGTCAGTACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAGGACGGAGACACCATCGAATGGGGGCAATTCCAAATCGACGGCAGATCTGCTAGAGGAGGTCAGCAGTCAGCTAACGATTCATATGCCAAGGCGTTGA |
| Protein Sequence | MGSLISTFSYSSKASTSARITDSSIWCPQPGQYISIRTYRELNPAPTSSPTSRRTETPSNGGNSKSTADLLEEVSSQLTIHMPRR |
| NCBI Accession | YP_004063990.1 |
|---|---|
| Location | 387-1157 |
| Gene Name | NSP |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATTATTTTAGAGGTAAACGTGGTGGTTATTTCCCTAATCGAAGATTTATCTCACGTAATAATATGTTTAATCGTTCAACCGCTGGGAAGCGATATGATGGGAAACGTCGAGGAGGTCGATCTGTCAGGCCCAGTGAGGAACCCAAGATGTCAGCCCAAACCATACATGAAAATCAGTACGGCACTGATTTTGTCATGGCCCATAATTCAGCTATCTCGACGTTCATCAGTTATCCAGACTTGGGCAAGATAGAACCGGGACGAAGCAGGTCATATATCAAGTTGAAACGACTCCGTTTCAAAGGGACTGTGAAGATTGAACGTGTTCAATCGGATTTGAACATGGACGGGACTGTCTCCAAAATAGAAGGAGTATTATCGCTTGTTGTTGTTGTGGATCGGAAACCCCACTTGGGTCCAAGTGGTTGTCTGCATACATTCGACGAGCTGTTTGGATCAATCATTCACAGTCATGGCAATCTTAGCATTGTCCCTTCTCTGAAAGACCGTTATTATATTCGCCACGTGTTCAAACGTGTTTTGTCATTGGAGAATGATACACATATGGTCGACATCGAAGGATCTACATGGTTATCTAACAGGCGTTTTACGTGTTGGTCCTCTTTCAAAGACGTGGATCGTGATTCATGCAAGGGTGTTTATGATAATATAAGCAAGAACGCCTTGTTAATCTATTATTGCTGGATGTCCGATACGCCCTCTAAGGCATCCAATTATGTATCTTTTGATCTTGATTATGTTGGTTAA |
| Protein Sequence | MYYFRGKRGGYFPNRRFISRNNMFNRSTAGKRYDGKRRGGRSVRPSEEPKMSAQTIHENQYGTDFVMAHNSAISTFISYPDLGKIEPGRSRSYIKLKRLRFKGTVKIERVQSDLNMDGTVSKIEGVLSLVVVVDRKPHLGPSGCLHTFDELFGSIIHSHGNLSIVPSLKDRYYIRHVFKRVLSLENDTHMVDIEGSTWLSNRRFTCWSSFKDVDRDSCKGVYDNISKNALLIYYCWMSDTPSKASNYVSFDLDYVG |
| NCBI Accession | YP_004063991.1 |
|---|---|
| Location | 1219-2100 |
| Gene Name | MP |
| Protein Name | movement protein |
| Coding Region | ATGGATTCTCAGTTAGTAAATCCTCCACATGCCTTCAATTACATAGAATCTCACCGTGATGAATATCAGCTTTCTCATGACCTAACTGAGATAATACTGCAATTCCCTTCAACGGCTTCTCAATTAACAGCTCGACTCAGTCGTAGCTGCATGAAGATCGACCACTGCGTCATAGAATACAGGCAACAGGTACCAATCAACGCCACAGGATCAGTAATTGTGGAGATCCACGACAAAAGGATGACGGACAACGAGTCATTACAGGCGTCATGGACTTTTCCGATCAGGTGCAACATAGATCTCCATTATTTCTCGGCTTCGTTCTTCTCGTTGAAGGACCCAATTCCATGGAAGTTGTACTACAGAGTGTGCGATACGAATGTTCATCAACGGACCCACTTCGCCAAGTTCAAAGGGAAACTGAAATTGTCCACAGCCAAACACTCCGTCGACATCCCCTTCCGGGCACCAACAGTGAAGATACTATCCAAACAGTTCACAGACAAGGATGTGGACTTTTCCCATGTGGATTATGGGAAATGGGAAAGGAAGCCCATCAGATGCGCGTCCATGTCAAGGGTTGGATTACGAGGCCCAATTGAAATAAGGCCTGGCGAGTCATGGGCTTCCAGGAGTACCATAGGTATGGGCCAATCAGATGCGGACTCAGCGGTGGAGAACGAGATCCACCCATACAGACACCTGAACAGGCTGGGGACCAGCGTTATGGATCCAGGAGAGTCTGCTTCTATTGTGGGAGACCAGAGAGCGGGGTCCAATATCACGATATCAATGGGACAGTTGAACGAGTTAGTCAGGACTACGGTCCAAGAATGTATTAATCATAACTGTCAGGCTTCTCAAGCCAAATCATTGAAATGA |
| Protein Sequence | MDSQLVNPPHAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRVGLRGPIEIRPGESWASRSTIGMGQSDADSAVENEIHPYRHLNRLGTSVMDPGESASIVGDQRAGSNITISMGQLNELVRTTVQECINHNCQASQAKSLK |
References More References in PubMed
| 1 |
Complete Genome Sequence of a New Strain of Sida Golden Mosaic Buckup Virus from Florida, USA. Iqbal Z, et al. Microbiol Resour Announc. 2020 Jan 9;9(2):e01115-19. doi: 10.1128/MRA.01115-19. PMID: 31919159 |
|---|---|
| 2 |
Characterization of sida golden mottle virus isolated from Sida santaremensis Monteiro in Florida. Al-Aqeel HA, et al. Arch Virol. 2018 Oct;163(10):2907-2911. doi: 10.1007/s00705-018-3903-x. Epub 2018 Jun 21. PMID: 29931396 |
| 3 |
The molecular characterisation of a Sida-infecting begomovirus from Jamaica. Stewart C, et al. Arch Virol. 2014 Feb;159(2):375-8. doi: 10.1007/s00705-013-1814-4. Epub 2013 Aug 11. PMID: 23933798 |