Sida golden mosaic Brazil virus
Basic Information
| Genus | Begomovirus |
|---|---|
| Isolate | Brazil |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
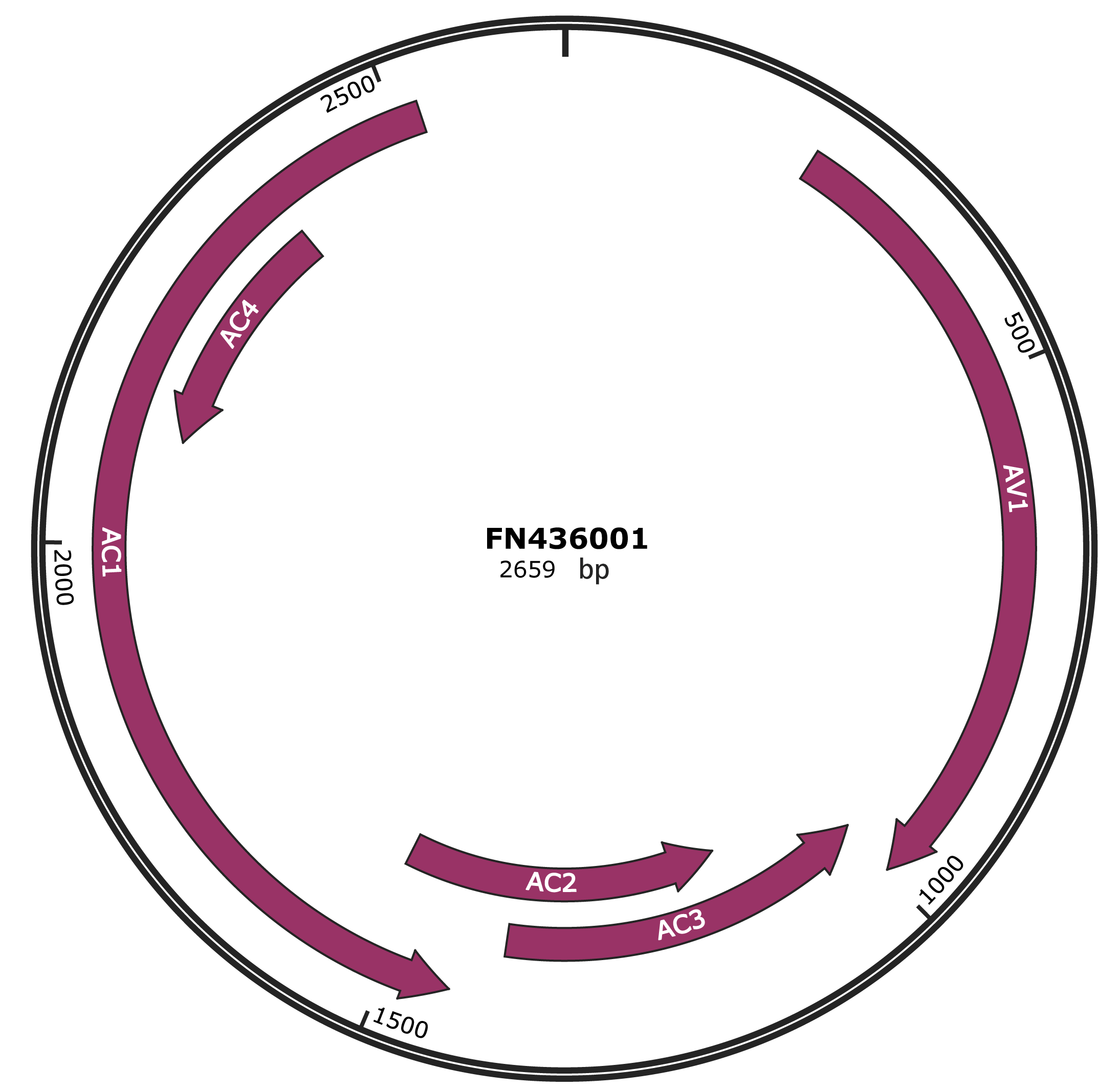
JBrowse
Genome
FN436001
Gene Information
| NCBI Accession | CBA18086.1 |
|---|---|
| Location | 241-996 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCAAAGCGGGATCCCTCATGGCGCATGGTGGTGGGAACCTCAAAGGTTAGCCGCTCCTCCAATTTTTCACCTCGTGGAGGTGGAGGCCCAAGAGTCAACAAGGCCTCAGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATATAGGACGCTGAGGACGCCTGATGTTCCCAGAGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTACGAGCAGCGTCATGACATTTCTCATGTCGGCAAGGTGATGTGTATATCTGATGTGACACGAGGTAATGGTATTACCCATCGTGTTGGTAAGCGTTTCTGTGTTAAATCTGTATATATTTTAGGGAAGATATGGATGGACGAGAACATCAAGTTAAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCAGAGATCGTAGACCTTATGGCACCCCGATGGATTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGCACTGCAACCGTCAAGAACGATCTCCGTGATCGTTTCCAAGTCATGCACAAGTTCTATGCCAAGGTCACTGGTGGGCAATATGCGAGCAACGAGCAGGCTCTGGTCAAGCGTTTCTGGAAGGTCAACAACCATGTTGTCTACAACCACCAGGAAGCTGGGAAATATGAGAATCATACTGAGAATGCATTGCTACTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCTACGCTTAAGATTCGGATCTATTTTTACGATTCGATCACCAATTAA |
| Protein Sequence | MPKRDPSWRMVVGTSKVSRSSNFSPRGGGGPRVNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | CBA18087.1 |
|---|---|
| Location | 993-1391 |
| Gene Name | AC3 |
| Protein Name | replication enhancer |
| Coding Region | ATGGATTCACGCACAGGGGCACTCATCACTGCACATCAGGCAGAGAATGGCGTTTATATCTGGGAGATAACAAATCCCCTCTATTTCAAGATATACGAGGTAGAGGATCTACCATACACAACGACCAGAGTATATCACGTCCAGATCAGGTTCAATCACAACCTCAGGAGAGCGTTGGGTCTCCACAAGGCTTACATGACCTTCCAAGTCTGGACGACATCGATTCGAGCTTCTGGAACGACTTATTTGAATAGGTTTAGACATTTAGTCATGTTGTATTTAGATAACCTAGGGGTTATTACCATTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAGATCATATGTCAACTATGTACTTGAACATTACTCAATAAAATTCAATATTTATTAA |
| Protein Sequence | MDSRTGALITAHQAENGVYIWEITNPLYFKIYEVEDLPYTTTRVYHVQIRFNHNLRRALGLHKAYMTFQVWTTSIRASGTTYLNRFRHLVMLYLDNLGVITINNVIRAVRFATDRSYVNYVLEHYSIKFNIY |
| NCBI Accession | CBA18088.1 |
|---|---|
| Location | 1138-1527 |
| Gene Name | AC2 |
| Protein Name | transcriptional regulator |
| Coding Region | ATGCTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACGACAGCACAGGATCGCCAAGAGGAGAGCGATCAGACGACGGCGAGTTGATCTAGAGTGCGGGTGCACGATATATCAGCACCTGAACTGCACGGGACATGGATTCACGCACAGGGGCACTCATCACTGCACATCAGGCAGAGAATGGCGTTTATATCTGGGAGATAACAAATCCCCTCTATTTCAAGATATACGAGGTAGAGGATCTACCATACACAACGACCAGAGTATATCACGTCCAGATCAGGTTCAATCACAACCTCAGGAGAGCGTTGGGTCTCCACAAGGCTTACATGACCTTCCAAGTCTGGACGACATCGATTCGAGCTTCTGGAACGACTTATTTGAATAG |
| Protein Sequence | MLNSSSSTPPSIKRQHRIAKRRAIRRRRVDLECGCTIYQHLNCTGHGFTHRGTHHCTSGREWRLYLGDNKSPLFQDIRGRGSTIHNDQSISRPDQVQSQPQESVGSPQGLHDLPSLDDIDSSFWNDLFE |
| NCBI Accession | CBA18089.1 |
|---|---|
| Location | 1439-2524 |
| Gene Name | AC1 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCACCACCGAAGCGTTTTAAGGTCAATGCCAAAAACTATTTCCTAACATACCCTGATTGTTCGATTGCTAAAGAAACTGCACTTGAACAACTCATAAACCTAGAAACACCCAGCAAGAAGAAATATATCAGGGTATGTAGAGAGTTCCACGAGAATGGGAAACCACATCTGCATGCCCTTGTTCAATTTGAAGGCAAGTTCCAGTGCACAAATTGCAGATTCTTCGATCTTAAACACCCAAACACCTCTTCCGTCGCCCATGCCAATATACAGGGTGCAAAGTCATCATCTGATGTCAAGTCCTACATCAAGAAGGACGGTGATTACATCGACTGGGGTACTTTTCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAGACAGCTAATGACGCAGCATCAGAGGCGTTGAATTCTTCTTCAAAGGAAGAAGCTATGCAGATAATAAAGGAGAAACTACCAGAGAAGTTTCTCTTCCAGTACCATAACCTCTCAACCAACCTGGATAAGCTCTTCAAGAAGGCTCCAGAACCATGGGTTCCTCCGTTTCAACTCTCAACATTCACTAACGTTCCTCATGAGATGCAAGAGTGGGCTGATGATTATTTTGGAAGGGTTGTCGCTGCGCGGCCAGACAGACCTATCAGTTTGATTGTTGAGGGTGATTCAAGAACAGGGAAGACGATGTGGGCTCGTGCTTTAGGCCCACATAATTACTTGAGTGGACATCTGGACTTCAATTCTAGAGTCTTCTCAAATGAAGTGGAATATAACGTCATTGATGACGTTAGCCCGCACTACCTAAAGCTAAAGCACTGGAAAGAATTGATTGGAGCCCAGAGGGACTGGCAAAGCAACTGCAAGTACGGAAAGCCAGTTCAAATTAAAGGGGGAATCCCATCAATCGTGCTTTGCAATCCAGGAGAGGGGGCCAGCTATAAAGAATTCCTAGACAAGCAGGAAAATGCAGCCTTGAGGTCGTGGACACTCCATAATGCTAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACGACAGCACAGGATCGCCAAGAGGAGAGCGATCAGACGACGGCGAGTTGA |
| Protein Sequence | MPPPKRFKVNAKNYFLTYPDCSIAKETALEQLINLETPSKKKYIRVCREFHENGKPHLHALVQFEGKFQCTNCRFFDLKHPNTSSVAHANIQGAKSSSDVKSYIKKDGDYIDWGTFQIDGRSARGGQQTANDAASEALNSSSKEEAMQIIKEKLPEKFLFQYHNLSTNLDKLFKKAPEPWVPPFQLSTFTNVPHEMQEWADDYFGRVVAARPDRPISLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVFSNEVEYNVIDDVSPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKEFLDKQENAALRSWTLHNAKFIFLDSPLYQTTAQDRQEESDQTTAS |
| NCBI Accession | CBA18090.1 |
|---|---|
| Location | 2110-2367 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGAAACCACATCTGCATGCCCTTGTTCAATTTGAAGGCAAGTTCCAGTGCACAAATTGCAGATTCTTCGATCTTAAACACCCAAACACCTCTTCCGTCGCCCATGCCAATATACAGGGTGCAAAGTCATCATCTGATGTCAAGTCCTACATCAAGAAGGACGGTGATTACATCGACTGGGGTACTTTTCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAGACAGCTAATGACGCAGCATCAGAGGCGTTGA |
| Protein Sequence | MGNHICMPLFNLKASSSAQIADSSILNTQTPLPSPMPIYRVQSHHLMSSPTSRRTVITSTGVLFRSTEDLLEEVSRQLMTQHQRR |
References More References in PubMed
| 1 |
First Report of Sida micrantha mosaic virus in Phaseolus vulgaris in Brazil. Fernandes-Acioli NAN, et al. Plant Dis. 2011 Sep;95(9):1196. doi: 10.1094/PDIS-05-10-0343. PMID: 30732032 |
|---|---|
| 2 |
Andrade EC, et al. J Gen Virol. 2006 Dec;87(Pt 12):3687-3696. doi: 10.1099/vir.0.82279-0. PMID: 17098986 |
| 3 |
Complete sequence of a new bipartite begomovirus infecting Sida sp. in Northeastern Brazil. Macedo MA, et al. Arch Virol. 2020 Jan;165(1):253-256. doi: 10.1007/s00705-019-04458-9. Epub 2019 Nov 22. PMID: 31758274 |
| 4 |
Bornancini VA, et al. Viruses. 2020 Feb 11;12(2):202. doi: 10.3390/v12020202. PMID: 32054104 |
| 5 |
Two new begomoviruses infecting tomato and Hibiscus sp. in the Amazon region of Brazil. Quadros AFF, et al. Arch Virol. 2019 Jul;164(7):1897-1901. doi: 10.1007/s00705-019-04245-6. Epub 2019 Apr 10. PMID: 30972592 |
| 6 |
Three distinct begomoviruses associated with soybean in central Brazil. Fernandes FR, et al. Arch Virol. 2009;154(9):1567-70. doi: 10.1007/s00705-009-0463-0. Epub 2009 Jul 28. PMID: 19636495 |