Bean dwarf mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000838545.1 |
| Release date | 2015/2/12 |
| Submitter | Gilbertson,R.L., Faria,J.C., Hanson,S.F., Morales,F.J., Ahlquist,P.G., Maxwell,D.P., Russell,D.R., Hidayat,S.H. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
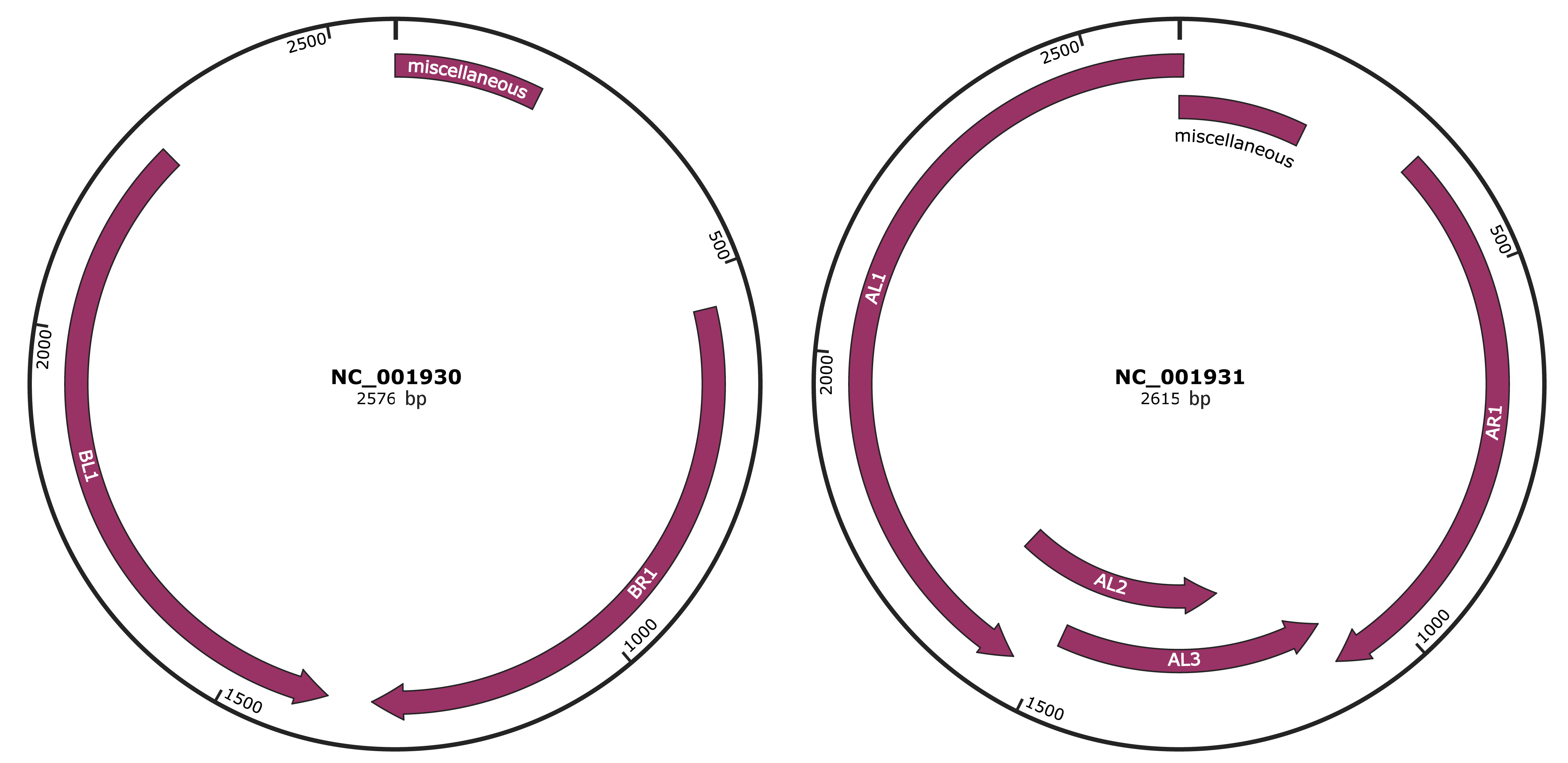
JBrowse
Genome
NC_001930
NC_001931
Gene Information
| NCBI Accession | NP_047221.1 |
|---|---|
| Location | 548-1318 |
| Gene Name | BR1 |
| Protein Name | hypothetical protein |
| Coding Region | ATGTATGGTTTGCGGAATAAACGTGGTTCATCGTTCAGCCATCGCCGATTTTATTCACGTAGCAGTTTTTTAAATCGCTTGTCCGCTAATAAGCGTCATGATGGCAAACGTCGAGCTATGAATCCTAGTAAGCCCATTGACGAGCCCAAGATGTCAGCCCAACGCATACATGAGAACCAGTATGGGCCTGAATTTGTAATGGCCCATAATTCAGCCATTTCTACGTTTATCAGCTACCCCAGCAAGGGCAAGATGGAACCCAACCGATCGAGGTCCTATATTAAGTTGAAACGACTTCGTTTCAAAGGGACTGTCAAGATTGATCGTGTTCAACCAGATATGAACATTGACGGTTCTGCCCCAAAAGTGGAAGGAGTGTTCTCTCTGGTGGTTGTTGTGGATCGTAAACCCCACTTGGGTGCGTCTGGATGCCTGCATACATTCGACGAGCTGTTCGGTGCAAGGATCCATAGCCATGGTAATCTCAGCATAACACCCTCTTTGAAAGACCGATTCTACATAAGACACGTGTTCAAACGTGTATTGTCCGTGGAGAAGGATACGATGATGGTTGACGTGGAAGGATCTACATCGCTCTCTAACAGGCGATATAATTGTTGGTCCACTTTTAAGGATCTTGACCATGAGTCATGCAAGGGTGTTTATGACAACATCAGCAAGAACGCCCTCCTAGTATATTACTGTTGGATGTCAGATACTATGTCAAAGGCATCTACTTTTGTATCGTTTGACCTTGATTATATCGGTTGA |
| Protein Sequence | MYGLRNKRGSSFSHRRFYSRSSFLNRLSANKRHDGKRRAMNPSKPIDEPKMSAQRIHENQYGPEFVMAHNSAISTFISYPSKGKMEPNRSRSYIKLKRLRFKGTVKIDRVQPDMNIDGSAPKVEGVFSLVVVVDRKPHLGASGCLHTFDELFGARIHSHGNLSITPSLKDRFYIRHVFKRVLSVEKDTMMVDVEGSTSLSNRRYNCWSTFKDLDHESCKGVYDNISKNALLVYYCWMSDTMSKASTFVSFDLDYIG |
| NCBI Accession | NP_047222.1 |
|---|---|
| Location | 1376-2257 |
| Gene Name | BL1 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGATTCTCAATTGGTCAATCCTCCCAACGCATTTAACTACATAGAGTCCCATCGGGACGAATATCAACTTTCTCATGACCTCACTGAGATAATTCTGCAATTCCCTTCCACGGCGTCGCAGTTAACAGCTAGGCTGAGCCGTAGCTGCATGAAGATCGACCACTGCGTCATAGAGTACAGGCAACAAGTGCCGATTAACGCGACAGGGTCGGTCATTGTCGAGATCCACGACAAGCGAATGACAGACAACGAATCGCTGCAGGCTTCCTGGACATTTCCAATCAGATGCAACATAGATCTACATTATTTCTCGGCTTCGTTCTTCTCGTTGAAAGACCCAATTCCATGGAAACTCTATTATAGGGTTTGCGATACGAATGTTCATCAGAGGACCCACTTCGCCAAGTTCAAAGGGAAACTGAAACTATCGACGGCGAAACACTCCGTGGATATACCCTTCCGGGCACCGACAGTAAAGATCCTGTCGAAACAGTTCACAGATAAAGATGTCGACTTTTCACATGTCGACTACGGAAGATGGGAAAGGAAACCCATAAGATGCGCATCCATGTCAAGGATTGGACTACCAGGCCCAATAGAGATCAAGCCGGGTGAATCATGGGCTTCACGGAGTACAATTGGGCTCAGCAACTCCGATGCCGACTCAGAGGTGGAAAACGCAATGCATCCATATAGGCATCTCAGCAGGCTTGGAACAAGCGTCTTAGACCCAGGGGAGTCTGCCTCAATTGTAGGGGCCCAGAGAGCGGAATCCAACATTACTATGTCGATGGGGCAATTAAACGAGCTAGTGAAAAACACTGTCCAGGAGTGTATAAATAGTAACTGTAAGGCTTATCAGCCCAAATCGTTGCAATAA |
| Protein Sequence | MDSQLVNPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKPIRCASMSRIGLPGPIEIKPGESWASRSTIGLSNSDADSEVENAMHPYRHLSRLGTSVLDPGESASIVGAQRAESNITMSMGQLNELVKNTVQECINSNCKAYQPKSLQ |
| NCBI Accession | NP_047223.1 |
|---|---|
| Location | 1536-2615,1-6 |
| Gene Name | AL1 |
| Protein Name | replicative protein |
| Coding Region | ATGCCACCGCCTAAGAAATTTAGAGTTCAATCGAGGAACTATTTCCTCACATATCCACAGTGCTCTCTTACTAAAGAGGAAGCACTTTCCCAAATCCAAAACCTAAAAACTCCAGTTAACAAGAAATTCATCAAGATTTGCAGGGAATTACACGAAGATGGGGAACCTCATCTGCACGTCCTCATCCAGTTCGAAGGTAAATACCAATGCACGAATAACAGATTCTTCGATCTGGTTTCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGACGGCGACACCGTCGAATGGGGAGTGTTTCAAATCGACGGCAGATCTGCTAGAGGAGGTCAGCAGTCTGCTAACGATACATACGCAAAGGCGTTAAATGCAGGATCCGCAGAGCAAGCTCTGCGCATAATAAAGGAAGAACAACCGCAACATTTCTTCCTTCAGCATCACAACCTGGTCGCTAACGCCACCAGCATATTCAAAAAGGCTCCGGAACCATGGGTTCCTCCGTTTCCCCTCTCTTCGTCTACTAACGTTCCAGACGAGATGCAAGAGTGGGCAGACGATTATTTCGGGAGAGGTTCCGCTGCGCGGCCAGAAAGACCAGTAAGTCTCATAGTAGAAGGTGATTCGAGAACAGGGAAGACGATGTGGGCTCGAGCACTAGGCCCACATAATTATTTAAGTGGACACCTAGACTTCAATTCCAAAGTGTTCACAGACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCATTATCTAAAGTTAAAGCACTGGAAGGAATTGATTGGGGCCCAAAAGAATTGGCAGTCAAATTGCAAGTACGGCAAGCCTGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTATGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTAAACAAAGAGGAAAATACAGCGCTAAGGAATTGGACGTTGAAGAATGCAATCTTCATCACTCTCGACTCCACCCTCTATCAAGAAGGCACACAGGCAAGCCAAGCGGCGGGCGATCAGGAGACGCCGCATTGA |
| Protein Sequence | MPPPKKFRVQSRNYFLTYPQCSLTKEEALSQIQNLKTPVNKKFIKICRELHEDGEPHLHVLIQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTVEWGVFQIDGRSARGGQQSANDTYAKALNAGSAEQALRIIKEEQPQHFFLQHHNLVANATSIFKKAPEPWVPPFPLSSSTNVPDEMQEWADDYFGRGSAARPERPVSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVFTDEVEYNVIDDVAPHYLKLKHWKELIGAQKNWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENTALRNWTLKNAIFITLDSTLYQEGTQASQAAGDQETPH |
| NCBI Accession | NP_047224.1 |
|---|---|
| Location | 338-1093 |
| Gene Name | AR1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGATGCCCCATGGCGCTCTATGGCGGGAACGACAAAGGTCAGTCGCAATGCCAATTACTCTCCCCGTGGGGGAATTGGGCCAAAGATGACAAGGGCCGCAGAGTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTATCGAACGCTAAGGACGCCTGACGTCCCACGAGGTTGTGAAGGCCCATGTAAGGTGCAGTCTTATGAACAGCGTCACGATATTTCACATGTTGGGAAGGTAATGTGTATCTCTGATGTCACACGTGGTAATGGCATTACTCACCGTGTTGGCAAGCGTTTTTGTGTTAAGTCTGTGTATATTCTAGGAAAGATTTGGATGGATGAGAATATCAAGCTCAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGAACGCCCATGGATTTCGGCCAGTTGTTCAACATGTTTGACAACGAGCCCAGCACTGCCACGGTTAAGAACGATCTTCGCGATCGTTTTCAAGTTATGCATAAGTTCTATGGGAAAGTCACAGGTGGACAGTATGCGAGCAATGAACAGGCAATCGTCAAGCGTTTTTGGAAGGTCAACAATCATGTGGTTTACAATCATCAAGAGGCTGGCAAGTATGAGAATCATACGGAGAACGCCTTATTATTGTATATGGCATGTACACATGCCTCTAATTCTGTGTATGCAACTCTGAAAATTCGGATCTATTTTTACGATTCGATCATGAATTAA |
| Protein Sequence | MPKRDAPWRSMAGTTKVSRNANYSPRGGIGPKMTRAAEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQLFNMFDNEPSTATVKNDLRDRFQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNSVYATLKIRIYFYDSIMN |
| NCBI Accession | NP_047225.1 |
|---|---|
| Location | 1090-1488 |
| Gene Name | AL3 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGATTCACGCACAGGGGAGCTCATCACTGCACTTCAAGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACAGAGTAGAGGAACCGTTGTACACCAACAGCAGGGTATACAGCGTACAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGATATCGACGACAGCTTCTGGGTCGACTTATTTAAATAGATTTAAACATTTAGTTATTATGTATTTAGATCAATTAGGAATTATATCCATTAACAATGTCATTAGAGGTGTTCGATTCGCAACAGACAGATCGTATGTAACTCATGTAATAGAATATCATTCAATAAAATTCAAACTTTATTAA |
| Protein Sequence | MDSRTGELITALQAENGVYIWEIENPLYFKIYRVEEPLYTNSRVYSVQIRFNHNLRRALHLHKAFLNFQVWTISTTASGSTYLNRFKHLVIMYLDQLGIISINNVIRGVRFATDRSYVTHVIEYHSIKFKLY |
| NCBI Accession | NP_047226.1 |
|---|---|
| Location | 1235-1624 |
| Gene Name | AL2 |
| Protein Name | hypothetical protein |
| Coding Region | ATGCAATCTTCATCACTCTCGACTCCACCCTCTATCAAGAAGGCACACAGGCAAGCCAAGCGGCGGGCGATCAGGAGACGCCGCATTGACCTGGAATGCGGTTGCTCCATCTACATACACATAGGTTGTACGGGACATGGATTCACGCACAGGGGAGCTCATCACTGCACTTCAAGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATATACAGAGTAGAGGAACCGTTGTACACCAACAGCAGGGTATACAGCGTACAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTTCCTGAACTTCCAAGTCTGGACGATATCGACGACAGCTTCTGGGTCGACTTATTTAAATAG |
| Protein Sequence | MQSSSLSTPPSIKKAHRQAKRRAIRRRRIDLECGCSIYIHIGCTGHGFTHRGAHHCTSSREWRVYLGDRKSPLFQDIQSRGTVVHQQQGIQRTDTVQPQPEESVASPQSLPELPSLDDIDDSFWVDLFK |
References More References in PubMed
| 1 |
Bean dwarf mosaic virus: a model system for the study of viral movement. Levy A, et al. Mol Plant Pathol. 2010 Jul;11(4):451-61. doi: 10.1111/j.1364-3703.2010.00619.x. PMID: 20618704 |
|---|---|
| 2 |
Garrido-Ramirez ER, et al. Mol Plant Microbe Interact. 2000 Nov;13(11):1184-94. doi: 10.1094/MPMI.2000.13.11.1184. PMID: 11059485 |
| 3 |
Levy A, et al. Plant Mol Biol. 2003 Dec;53(6):789-803. doi: 10.1023/B:PLAN.0000023662.25756.43. PMID: 15082926 |
| 4 |
Interactions between Common Bean Viruses and Their Whitefly Vector. Ferreira AL, et al. Viruses. 2024 Oct 2;16(10):1567. doi: 10.3390/v16101567. PMID: 39459901 |
| 5 |
Seo YS, et al. Theor Appl Genet. 2004 Mar;108(5):786-93. doi: 10.1007/s00122-003-1504-9. Epub 2003 Nov 19. PMID: 14625673 |
| 6 |
Miklas PN, et al. Plant Dis. 2009 Jun;93(6):645-648. doi: 10.1094/PDIS-93-6-0645. PMID: 30764403 |
| 7 |
Seo YS, et al. Mol Plant Pathol. 2007 Mar;8(2):151-62. doi: 10.1111/j.1364-3703.2007.00379.x. PMID: 20507487 |
| 8 |
Hou YM, et al. Mol Plant Microbe Interact. 2000 Mar;13(3):297-308. doi: 10.1094/MPMI.2000.13.3.297. PMID: 10707355 |
| 9 |
Genetic diversity of begomoviruses infecting tomato plant in Saudi Arabia. Sohrab SS. Saudi J Biol Sci. 2020 Jan;27(1):222-228. doi: 10.1016/j.sjbs.2019.08.015. Epub 2019 Aug 22. PMID: 31889840 |
| 10 |
First Report and Characterization of Rhynchosia golden mosaic virus in Honduras. Potter JL, et al. Plant Dis. 2000 Sep;84(9):1045. doi: 10.1094/PDIS.2000.84.9.1045A. PMID: 30832009 |