Sida chlorotic mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_003029395.1 |
| Isolate | Brazil |
| Release date | 2018/8/26 |
| Submitter | Ferro,C.G., Silva,J.P., Xavier,C.A.D., Godinho,M.T., Lima,A.T.M., Mar,T.B., Lau,D., Zerbini,F.M. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
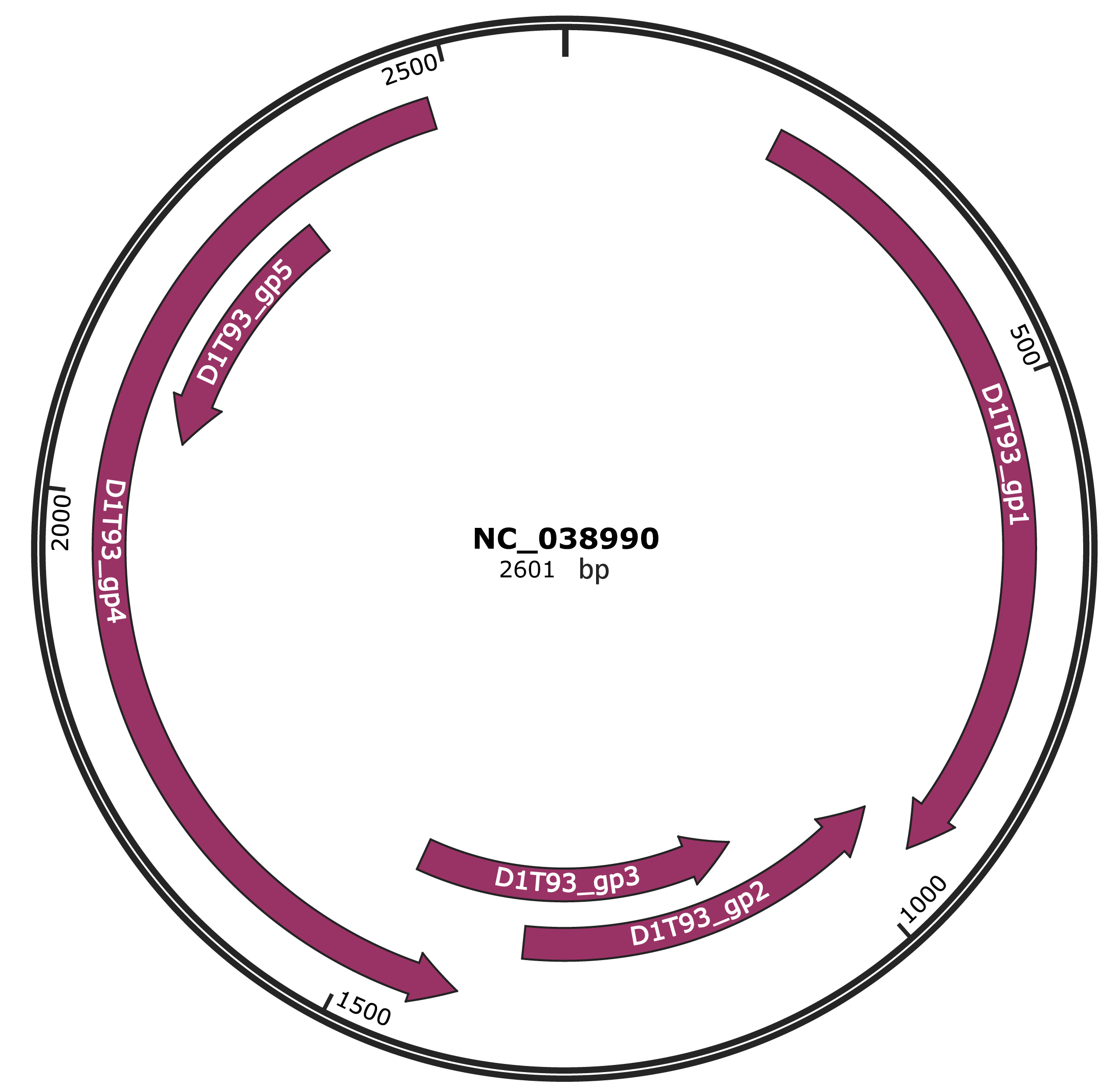
JBrowse
Genome
NC_038990
Gene Information
| NCBI Accession | YP_009508418.1 |
|---|---|
| Location | 199-948 |
| Protein Name | CP |
| Coding Region | ATGCCCAAGCGGGACGCTCCATGGCGCATAATGGCGGGGACCTCAAAGGTTTCCCGCTCTGTCAATTATTCACCCCGTGGTGGTCCTAAATTGGACAAGGCATCCGCTTGGGTCAACAGGCCCATGTACAGGAAGCCCAGGATTTACCGCACTTTGAGAAGCCCAGACGTCCCTAAGGGATGTGAAGGCCCGTGCAAGGTCCAGTCATATGAGTCTCGTCATGACGTTTCCCATGTTGGCAAGGTGATCTGTGTGTCAGATGTTACACGTGGCAACGGTATTACTCACCGCGTGGGTAAGCGATTCTGCGTCAAGTCTGTGTATATATTAGGGAAGATCTGGATGGATGAGACCATCAAGTTGAAGAACCACACGAACAGCGTCATGTTCTGGTTGGTTAGGGACCGGAGACCTTATGGAACGCCTATGGATTTTGGCCAAGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCCACCGTTAAGAACGATCTTCGAGATCGTTTTCAGGTTTTGCACAAGTTCTACGCCAAGGTTACGGGTGGACAGTATGCCAGCAACGAGCAGGCTATCGTGAAGCGCTTCTGGAAGGTCAACAATTACGTGGTCTACAACCATCAGGAAGCAGGGAAATATGAGAATCATACTGAAAACGGTCTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCCGTGTATGCTACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MPKRDAPWRIMAGTSKVSRSVNYSPRGGPKLDKASAWVNRPMYRKPRIYRTLRSPDVPKGCEGPCKVQSYESRHDVSHVGKVICVSDVTRGNGITHRVGKRFCVKSVYILGKIWMDETIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVLHKFYAKVTGGQYASNEQAIVKRFWKVNNYVVYNHQEAGKYENHTENGLLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_009508419.1 |
|---|---|
| Location | 945-1343 |
| Protein Name | REN |
| Coding Region | ATGGATTCACGCACAGGGGAGAACATCACTGTGTCTCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTTTATTTCAGGATCGACCATGTGGAGGATCCGATATACACAATGACAAGGATATACCACATCCAGATACGGTTCAACCACAACGTCAGGAAGGCGCTGGGTCTACACAAAGCCTACCTGAACTTCCAAGTCTGGACGACCTCGATTCGAGCTTCTGGGACGACATATTTACATAGATTTAAGCATTTAGTTAATATGTATTTAGATAATATAGGTGTTATAGGACTTAACCATGTAATAAGAGCTGTTCGATTCGCAACAGACAAATATTATGTAAATTATGTACTCGAGAATCATGAAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTGENITVSQAENSVFIWEVPNPLYFRIDHVEDPIYTMTRIYHIQIRFNHNVRKALGLHKAYLNFQVWTTSIRASGTTYLHRFKHLVNMYLDNIGVIGLNHVIRAVRFATDKYYVNYVLENHEIKFKFY |
| NCBI Accession | YP_009508420.1 |
|---|---|
| Location | 1090-1479 |
| Protein Name | TRAP |
| Coding Region | ATGCGAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACCACAACACAAAATCGCGAAGAAGAGGGCAATTCGTCGTAAGCGCATTGACCTCAATTGCGGCTGTTCCATCTTCCTCCACATCAACTGCGCAAATCATGGATTCACGCACAGGGGAGAACATCACTGTGTCTCAGGCAGAGAATTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTTTATTTCAGGATCGACCATGTGGAGGATCCGATATACACAATGACAAGGATATACCACATCCAGATACGGTTCAACCACAACGTCAGGAAGGCGCTGGGTCTACACAAAGCCTACCTGAACTTCCAAGTCTGGACGACCTCGATTCGAGCTTCTGGGACGACATATTTACATAG |
| Protein Sequence | MRNSSSSTPPSIKPQHKIAKKRAIRRKRIDLNCGCSIFLHINCANHGFTHRGEHHCVSGREFRFYLGGSKSPLFQDRPCGGSDIHNDKDIPHPDTVQPQRQEGAGSTQSLPELPSLDDLDSSFWDDIFT |
| NCBI Accession | YP_009508421.1 |
|---|---|
| Location | 1400-2479 |
| Protein Name | Rep |
| Coding Region | ATGCCATCCGTTCCAAAACGATTCCGTATTTCTTCCAAAAATTATTTCCTCACATACCCCCTATGCACATTAACCAAGGAAGAAACCCTTTCCCAAATAAAAGCCCTAAACACCCCAACAAATAAGAAGTTCATCAAAATATGCAGAGAGCTTCATGAAAATGGGCAACCTCACCTCCACGTGCTTCTCCAATTCGAAGGCAAATTCGTGTGCACAAATCAGAGACTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATCGACAAGGACGGTGACACCCTCGAATGGGGAGAATTCCAAATCGACGGAAGAAGTGCTAGAGGAGGTTGCCAGACAGCTAACGACGCTGCCGCAGAGGCCTTAAACGCCCCTTCAAAAGAAGCGGCGTTACAAATAATAAGAGAGAAGCTGCCGGAGAAATTTCTCTTTCAATATCACAATCTGTCCAGTAACCTGGACAGAATTTTCTCTAAGGCTCCAGAACCGTGGGTTCCTCCGTTTCTTCTCTCAACCTTCACTGCCGTTCCGGATGAGATGCAAGAGTGGGCTGATGATTATTTCGGTAGGGGTGCCGCTGCGCGGCCAGACAGACCTATTAGTTTGATTGTCGAGGGTGATTCGAGAACGGGAAAGACGATGTGGGCTCGTGCATTAGGCCCACATAATTATTTAAGTGGACACCTAGACTTCAATTCTAGGGTTTACTCAAATGAAGCGGAATACAACGTCATTGATGACGTTGCCCCGCAATATCTAAAGATGAAGCACTGGAAAGAGCTGATTGGGGCCCAAAAAGACTGGCAGTCCAACTGTAAATATGGAAAGCCAGTTCAAATTAAAGGAGGCATTCCATCAATCGTGCTATGCAATCCAGGCGAGGGGGCTAGCTATAAAGACTTCCTCAACAAAGAGGAAAATGCTTCACTGAGAGCGTGGACAATACACAATGCGAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACCACAACACAAAATCGCGAAGAAGAGGGCAATTCGTCGTAA |
| Protein Sequence | MPSVPKRFRISSKNYFLTYPLCTLTKEETLSQIKALNTPTNKKFIKICRELHENGQPHLHVLLQFEGKFVCTNQRLFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGCQTANDAAAEALNAPSKEAALQIIREKLPEKFLFQYHNLSSNLDRIFSKAPEPWVPPFLLSTFTAVPDEMQEWADDYFGRGAAARPDRPISLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNEAEYNVIDDVAPQYLKMKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENASLRAWTIHNAKFIFLDAPLYQTTTQNREEEGNSS |
| NCBI Accession | YP_009508422.1 |
|---|---|
| Location | 2062-2325 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAAATGGGCAACCTCACCTCCACGTGCTTCTCCAATTCGAAGGCAAATTCGTGTGCACAAATCAGAGACTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATCGACAAGGACGGTGACACCCTCGAATGGGGAGAATTCCAAATCGACGGAAGAAGTGCTAGAGGAGGTTGCCAGACAGCTAACGACGCTGCCGCAGAGGCCTTAA |
| Protein Sequence | MKMGNLTSTCFSNSKANSCAQIRDSSTWYPQPGQHISIRTFRELNHRPTSSPTSTRTVTPSNGENSKSTEEVLEEVARQLTTLPQRP |
References More References in PubMed
| 1 |
Zambrano K, et al. Arch Virol. 2011 Dec;156(12):2263-6. doi: 10.1007/s00705-011-1093-x. Epub 2011 Aug 19. PMID: 21853328 |
|---|---|
| 2 |
Hernández-Zepeda C, et al. Virus Genes. 2007 Dec;35(3):825-33. doi: 10.1007/s11262-007-0149-1. Epub 2007 Aug 8. PMID: 17682933 |
| 3 |
Two new begomoviruses infecting tomato and Hibiscus sp. in the Amazon region of Brazil. Quadros AFF, et al. Arch Virol. 2019 Jul;164(7):1897-1901. doi: 10.1007/s00705-019-04245-6. Epub 2019 Apr 10. PMID: 30972592 |
| 4 |
Complete sequence of a new bipartite begomovirus infecting Sida sp. in Northeastern Brazil. Macedo MA, et al. Arch Virol. 2020 Jan;165(1):253-256. doi: 10.1007/s00705-019-04458-9. Epub 2019 Nov 22. PMID: 31758274 |