Sida chlorotic leaf virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_018587405.1 |
| Isolate | Mexico |
| Release date | 2021/6/1 |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
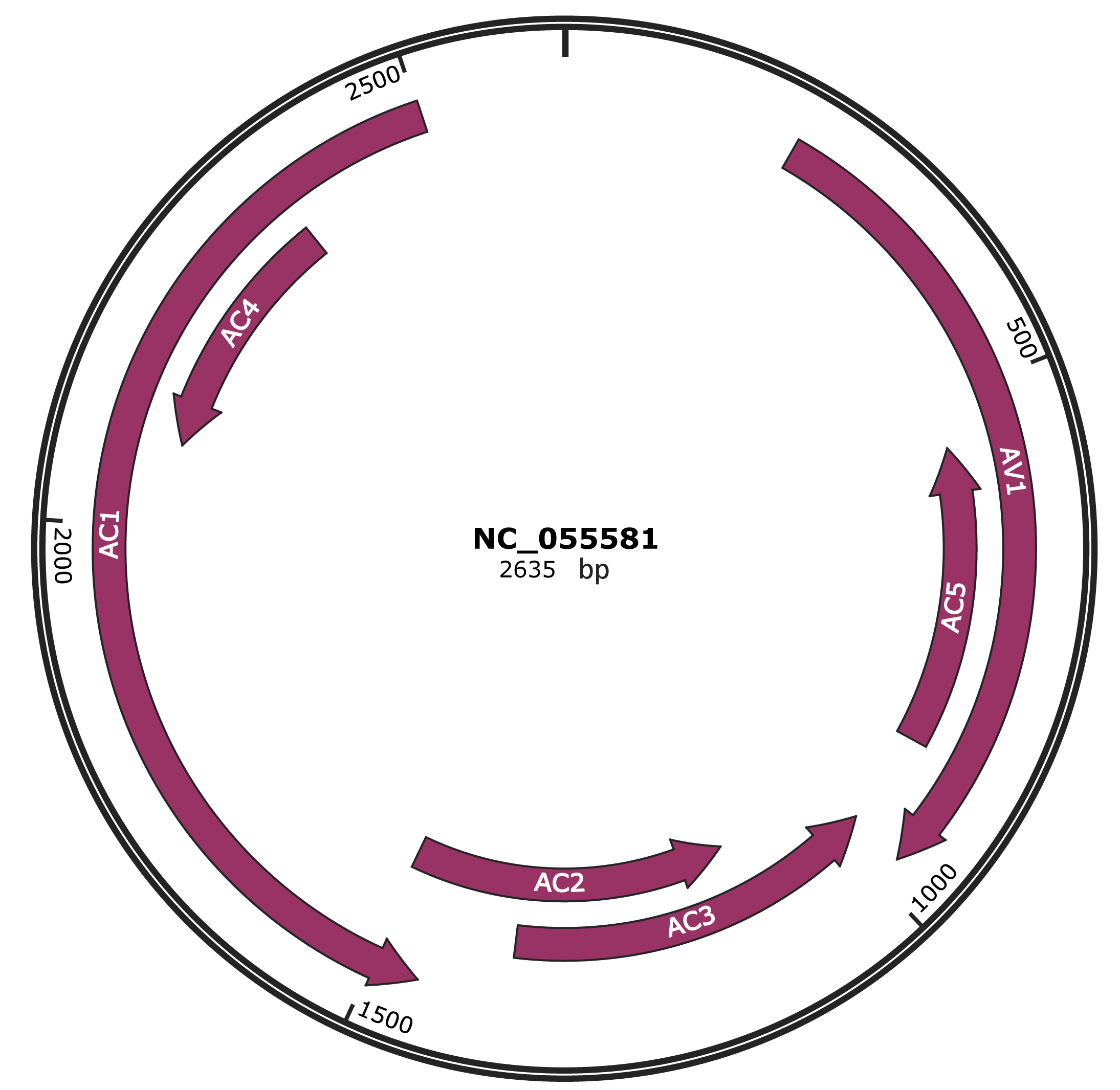
JBrowse
Genome
NC_055581
Gene Information
| NCBI Accession | YP_010087776.1 |
|---|---|
| Location | 219-974 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGACGCCCCATGGCGTACTATGGCGGGGACCTCAAAGGTTTCTCGCTCCGCCAATTATTCACCTCGTGGTGGATATGGGCCGAAATTCGACAAGGCCGCTGCTTGGGTTAACAGACCCATGTATAGGAAGCCCAGAATCTATCGGGCGCTTAGAGGACCTGACGTGCCTAAGGGTTGTGAAGGGCCTTGTAAGGTTCAATCCTTTGAACAGCGTCATGATATTTCCCATGTTGGTAAGGTCATGTGTATATCTGATGTCACACGTGGTAATGGTATTACCCATCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTATATTCTAGGTAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCACACGAACAGCGTCATGTTTTGGTTGGTCAGAGACAGAAGACCCTATGGCACCCCTATGGATTTTGGTCAAGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCTACGGTGAAGAACGATCTTCGTGATCGTTTTCAGGTCATGCACAGGTTCTATGCTAAGGTGACTGGTGGTCAATATGCTAGCAACGAGCAGGCATTGGTTAGGCGATTCTGGAGAGTCAACACTCATGTTGTCTATAACCACCAGGAAGCCGCTAAGTACGAGAATCATACTGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACATTGAAAATTCGGATCTATTTTTATGATTCGATCAGCAATTAA |
| Protein Sequence | MPKRDAPWRTMAGTSKVSRSANYSPRGGYGPKFDKAAAWVNRPMYRKPRIYRALRGPDVPKGCEGPCKVQSFEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHRFYAKVTGGQYASNEQALVRRFWRVNTHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
| NCBI Accession | YP_010087777.1 |
|---|---|
| Location | 552-869 |
| Gene Name | AC5 |
| Protein Name | putative AC5 protein |
| Coding Region | ATGATTCTCGTACTTAGCGGCTTCCTGGTGGTTATAGACAACATGAGTGTTGACTCTCCAGAATCGCCTAACCAATGCCTGCTCGTTGCTAGCATATTGACCACCAGTCACCTTAGCATAGAACCTGTGCATGACCTGAAAACGATCACGAAGATCGTTCTTCACCGTAGCAGTACTGGGCTCGTTGTCGAACATGTTGAACACTTGACCAAAATCCATAGGGGTGCCATAGGGTCTTCTGTCTCTGACCAACCAAAACATGACGCTGTTCGTGTGGTTCTTCAGCTTGATGTTCTCGTCCATCCATATCTTACCTAG |
| Protein Sequence | MILVLSGFLVVIDNMSVDSPESPNQCLLVASILTTSHLSIEPVHDLKTITKIVLHRSSTGLVVEHVEHLTKIHRGAIGSSVSDQPKHDAVRVVLQLDVLVHPYLT |
| NCBI Accession | YP_010087778.1 |
|---|---|
| Location | 971-1369 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACCGGGGAACCCATCACTGCGCATCAAGCAGAGAGTGGCGTTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAAACCAGGTGGAGGTTCCACCGTTCTCCCTGATCACAATATATCATGTCCAGATAAGGTTCAACCACAACCTGAGGAGGGCACTGGGTCTACACAAAGCCTTCCTGAATTTCCAAGTCTGGACGACATTGCTTCGAGTTTCTGGGACGACGTATTTAAATAGATTTAGTCGCTTAGTCATGTTGTACTTAGACAATATAGGCGTTATTTCAATTAATAATGTTATTCGAGCTGTTCGCTTCGCGACAGACAGATCATATGTAAATGATGTACTTGAGAATCATGAAATAAAATTCTTATTTTATTAA |
| Protein Sequence | MDSRTGEPITAHQAESGVFIWEVPNPLYFKINQVEVPPFSLITIYHVQIRFNHNLRRALGLHKAFLNFQVWTTLLRVSGTTYLNRFSRLVMLYLDNIGVISINNVIRAVRFATDRSYVNDVLENHEIKFLFY |
| NCBI Accession | YP_010087779.1 |
|---|---|
| Location | 1116-1505 |
| Gene Name | AC2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCGAAATTCGTCACCATCAACGCCCCCCTCTATCAAAGCACAACATAGACGAGCCAAGAGAAGGGCTGTTCGTCGTAGACGGTTGGACCTGAACTGCGGCTGTTCCATATTCCTGCACATCAATTGCGTCAATCATGGATTCACGCACCGGGGAACCCATCACTGCGCATCAAGCAGAGAGTGGCGTTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAAACCAGGTGGAGGTTCCACCGTTCTCCCTGATCACAATATATCATGTCCAGATAAGGTTCAACCACAACCTGAGGAGGGCACTGGGTCTACACAAAGCCTTCCTGAATTTCCAAGTCTGGACGACATTGCTTCGAGTTTCTGGGACGACGTATTTAAATAG |
| Protein Sequence | MRNSSPSTPPSIKAQHRRAKRRAVRRRRLDLNCGCSIFLHINCVNHGFTHRGTHHCASSREWRFYLGGSKSPLFQDKPGGGSTVLPDHNISCPDKVQPQPEEGTGSTQSLPEFPSLDDIASSFWDDVFK |
| NCBI Accession | YP_010087780.1 |
|---|---|
| Location | 1456-2502 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCACGGAAGGGTTCTTTCTCTATTAAAGCCAAAAACTATTTTCTCACTTATCCCCAGTGCTCTCTTAAGAAAGAGGAGGCACTGGAACAACTCAGGAACATCAAAACTCCCACGAATAAGAAATTTATCAAGGTCTGCAGGGAGTTTCATGAAGATGGGCAGCCTCATATCCATGTGCTTATACAGTTCGAAGGGAAGTTCAACTGCACAAATAACAGATTATTCGATATGGTGTCCTCAACCAGGTCTGCCCATTTCCACCCAAACATACAAGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAAGACGGTGACACCATCGAATGGGGGGTGTTCCAGATCGACGGAAGAAGTGCTCGCGGCGGTCAGCAGACATCTAACGACGCAGCCGCCGAGGCGTTAAATTCTGGAACAAAGGAGGAGGCAATGAGGATAATCAAAGAAAAACTTCCGGAAAAGTTTTTATTTCAGTTTCATAACCTATCGAGTAACCTCGACAGGATATTCAGTAAGGCTCCGGAGCCATGGACTCCTCCGTTTCAACTCTCCACATTCACTAACGTCCCAGTGGAGATGCAAAGGTGGGCAGATGACTATTTCGGGAAAGATGCCGCTGCGCGGCCGGAGAGACCTATTAGCATCATCATTGAAGGTGATTCAAGGACGGGAAAAACGATGTGGGCTCGTGCTTTAGGTTCTCATAATTACTTGTCTGGACACCTGGACTTCAATCCTCGAGTCTATTCAAATGAAGTGGAGTATAACGTCATTGATGACGTTAGTCCACATTATCTCAAACTAAAGCACTGGAAAGAGCTAATAGGGTCCCAAAGAGACTGGCAGTCCAACTGTAAATATGGAAAGCCGGTTCAAATTAAAGGAGGTATCCCATCAATTGTGCTTTGTAACCCGGGAGAGGGGGCTTCTTATAAACACTTCCTAGACAAAGAAGAAAACGCATCACTAAAAGCGTGGACGCTTCATAATGCGAAATTCGTCACCATCAACGCCCCCCTCTATCAAAGCACAACATAG |
| Protein Sequence | MPRKGSFSIKAKNYFLTYPQCSLKKEEALEQLRNIKTPTNKKFIKVCREFHEDGQPHIHVLIQFEGKFNCTNNRLFDMVSSTRSAHFHPNIQGAKSSSDVKSYVEKDGDTIEWGVFQIDGRSARGGQQTSNDAAAEALNSGTKEEAMRIIKEKLPEKFLFQFHNLSSNLDRIFSKAPEPWTPPFQLSTFTNVPVEMQRWADDYFGKDAAARPERPISIIIEGDSRTGKTMWARALGSHNYLSGHLDFNPRVYSNEVEYNVIDDVSPHYLKLKHWKELIGSQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKHFLDKEENASLKAWTLHNAKFVTINAPLYQSTT |
| NCBI Accession | YP_010087781.1 |
|---|---|
| Location | 2088-2351 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAGATGGGCAGCCTCATATCCATGTGCTTATACAGTTCGAAGGGAAGTTCAACTGCACAAATAACAGATTATTCGATATGGTGTCCTCAACCAGGTCTGCCCATTTCCACCCAAACATACAAGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACGTCGAGAAAGACGGTGACACCATCGAATGGGGGGTGTTCCAGATCGACGGAAGAAGTGCTCGCGGCGGTCAGCAGACATCTAACGACGCAGCCGCCGAGGCGTTAA |
| Protein Sequence | MKMGSLISMCLYSSKGSSTAQITDYSIWCPQPGLPISTQTYKELNPAPTSSPTSRKTVTPSNGGCSRSTEEVLAAVSRHLTTQPPRR |
References More References in PubMed
| 1 |
García-Rodríguez DA, et al. PeerJ. 2023 Mar 22;11:e15047. doi: 10.7717/peerj.15047. eCollection 2023. PMID: 36974135 |
|---|---|
| 2 |
Zambrano K, et al. Arch Virol. 2011 Dec;156(12):2263-6. doi: 10.1007/s00705-011-1093-x. Epub 2011 Aug 19. PMID: 21853328 |
| 3 |
Weed Hosts: Hidden Reservoirs for Whitefly-Transmitted Viruses Threatening Georgia Cucurbits. Dhadly DK, et al. Plant Dis. 2025 Nov;109(11):2352-2361. doi: 10.1094/PDIS-12-24-2730-RE. Epub 2025 Nov 21. PMID: 40150965 |
| 4 |
First Report of Sida micrantha mosaic virus in Phaseolus vulgaris in Brazil. Fernandes-Acioli NAN, et al. Plant Dis. 2011 Sep;95(9):1196. doi: 10.1094/PDIS-05-10-0343. PMID: 30732032 |
| 5 |
Complete sequence of a new bipartite begomovirus infecting Sida sp. in Northeastern Brazil. Macedo MA, et al. Arch Virol. 2020 Jan;165(1):253-256. doi: 10.1007/s00705-019-04458-9. Epub 2019 Nov 22. PMID: 31758274 |
| 6 |
Two new begomoviruses infecting tomato and Hibiscus sp. in the Amazon region of Brazil. Quadros AFF, et al. Arch Virol. 2019 Jul;164(7):1897-1901. doi: 10.1007/s00705-019-04245-6. Epub 2019 Apr 10. PMID: 30972592 |
| 7 |
Hernández-Zepeda C, et al. Virus Genes. 2007 Dec;35(3):825-33. doi: 10.1007/s11262-007-0149-1. Epub 2007 Aug 8. PMID: 17682933 |
| 8 |
Complete genome sequence of a new bipartite begomovirus infecting tomato in Brazil. Rego-Machado CM, et al. Arch Virol. 2019 Nov;164(11):2873-2875. doi: 10.1007/s00705-019-04380-0. Epub 2019 Aug 20. PMID: 31432269 |