Rhynchosia yellow mosaic India virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000887955.1 |
| Isolate | India |
| Release date | 2015/2/22 |
| Submitter | Jyothsna,P., Rawat,R., Malathi,V.G. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
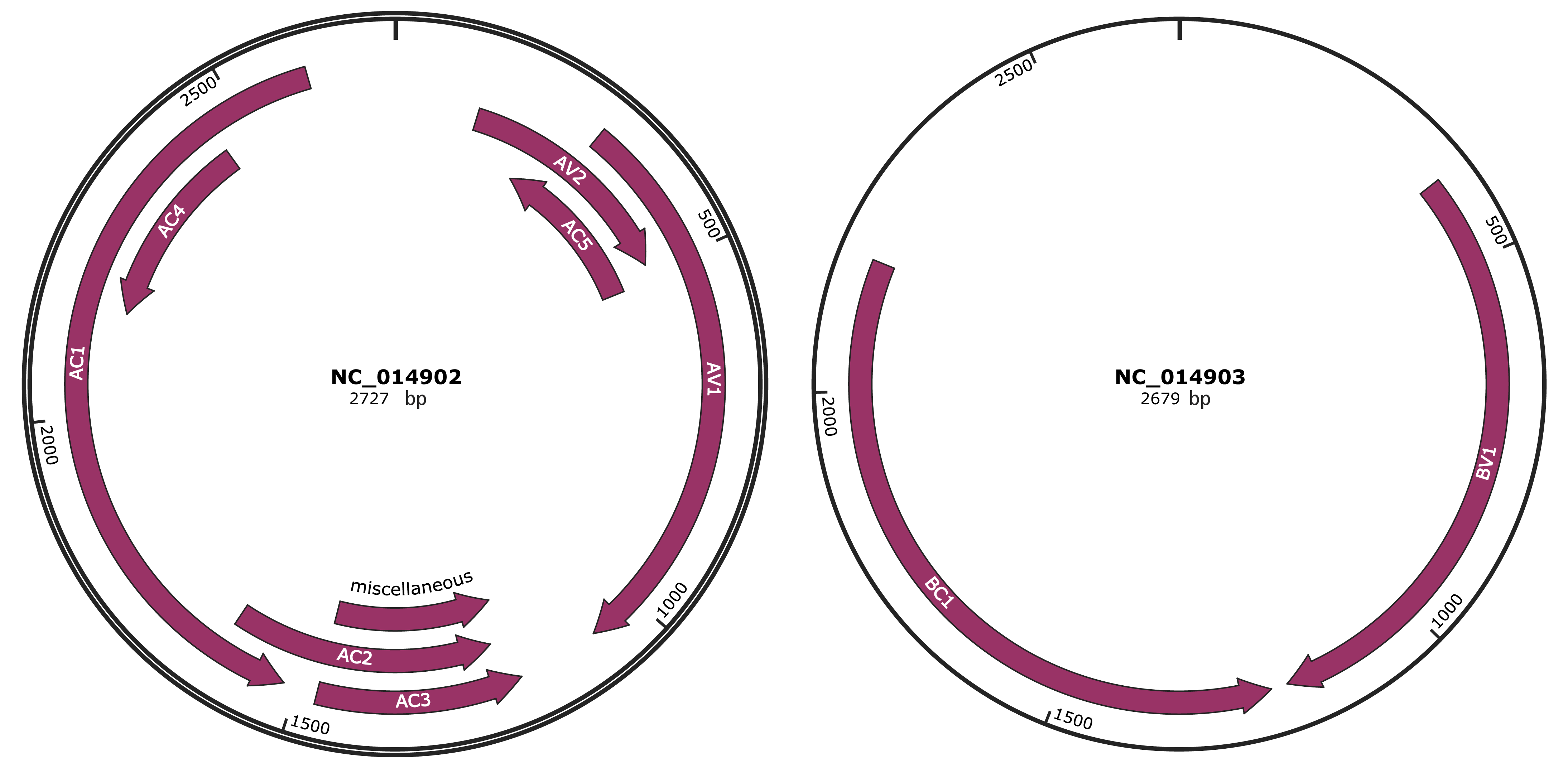
JBrowse
Genome
NC_014902
ACCTGAGGACCCGCGCCGGTGTACGAGGCGTCTTTTGCTTTATTTACCTTTATGTCATTCAACCAAATGCGCTCCTCAGCGCTTAGATATTTTAAATTTGAATTATAAACGTGGGGACTACGTACCCCAATGATAAAGATGTGGGATCCATTGTTGAATGACTTTCCCAAATCACGGCATGGTTTTCGGTGCATGATTGCCATTAAGTTCTTGCAAGCCTGTCAAGAACAATATCCTAATAATTCATTGGGATTTGAATTTTTGCGCAAACTCATTTCAAATTTGCGCTCCAAGGACCATGCCAAAGCGGAATTACGATACCGCCTTCTCATCACCGCTATCAGTAGTTCGTCGAAGATTGAACTTCGACAGCCCAATGGCACTACCTGCACCTGCATCCAGTGCCCAAGGCACAACAAGGAGAAGGCGTTGGACGAATCGTCCGATGTGGAGGAAACCACGTTTTTATCGATTGTATCGGACACCTGATGTTCCACGTGGTTGTGAAGGTCCATGTAAGGTTCAATCCTTTGAACAACGGCATGATATTGCCCATACTGGCAAAGTAATTTGCATTTCAGATGTTACTCGAGGTAATGGAATTACTCATCGTGTTGGGAAACGTTTCTGTGTCAAGTCCGTATATATTACTGGTAAGGTTTGGATGGACGAGAATATTAAGTCCAAAAACCATACTAATACGGTCATGTTTAAGTTATGTCGTGACAGACGACCCTTTGGGACTCCTATGGATTTCGGTCAGGTGTTTAATATGTATGATAATGAACCAAGTACTGCGACAGTGAAGAACGATCTTCGTGATCGTTTTCAAGTTCTGCGAAGATTTAATGCCACGGTTACAGGTGGCCAATATGCATGCAAGGAGCAAGCCATGGTTAACCGTTTTTATCGTGTTAACAATCATGTGGTTTATAATCATCAGGAAGCTGCCAAATATGAAAATCATACTGAGAATGCGTTGTTATTGTATATGGCATGTACTCATGCTTCAAACCCTGTGTATGCGACATTAAAGATCAGGATCTATTTCTATGATTCTGTTGGAAATTAATAAAGATTGAATTTTATTTCATTGTTTTGTTGCACCTCAATTGTGCCTTCAAATACATTGTACATTACATGATCGACAGATCGAATAACATTATTAATACAAAGTACGCCTAAACTATTCAGAAATTGAAAACTGAAGCTTAAATGTCTTTAAGAAAAGACCAGTCGGAGGCCGTAAGGTCGTCCAAATTTTGAAGGTCAAAAAACATTTGTGAATCCCCAGTGCCTTCCTTAAGTTGTGGTTGAATCTGATCTGGACAGTCAAAATGTCGTTGTTGCTGTTGAACGGTCTCTTGTGATGCTCGAGGATCTTGAAATATAGGGGATTTTTTATCTCCCAGATATATACGCCATTCTGTGCTTGAATTGCAGTGATGTTCTCCCCTGTGCGTAAATCCATGGTTAGCACAGTTAATGTGCATATAATATGAGCAGCCGCACTTGAGGTCAATTCGTTTGCGTCGAATTGCTTTCTTCTTGGCGCACCTGTGTTGCGCTTTGATTGACGGTGGTGAAAAATGGTTCTTTGATGGTGTAGAATTCCGCATTCTTGGAAGCCCACAATTTTAGTGATGCATTTGCTTCCTCGTCGAGGAACTCTTTATAAGAAGATTTGTTGCCTGGGTTGCAGAGAAAGATTGTGGGGATACCACCTTTAATCATTGTGGGCTTTCCGTATTTGACGTTACTTTGCCAGTCACGTTGTGCGCCCATGAATTCTTTGAAATGTTTCAAATAATGCGGATCGACGTCATCAATGACGTTATACCATGCATCGTTGGAATACACTTTCGGACTAAGGTCCAAATGGCCGCAGAGATAATTGTGCGGCCCCAATGCACGAGCCCATGTCGTCTTCCCAGTACGACTATCACCTTCAATGACAATGCTAATCGGTCTTTCTGGCCGCGCAGCGGAATCCTTCACATTTCTTTCCGCCCAAGAAGAAATGTACGGTGGAACATTATCGAATGATTCAATTGAATAACGAGGTTCATAAACTGGAACACTTTTTTCAAAAATTTTATCAAAATTCTTAGCTAAATTATGAAAATATAAAACGAAATCCTTCGGAGCCTTTTCCTTTAGTATAACGAGCGCCTCAGAGGTATTTCCTGCATTGATTGCTTCGGCATAAGCGTCGTTTGCAGATTGCTTACCTCCTCGACTTGATCGACCATCAATTTGGAATTCTCCATGATCAACGACGTCTCCGTCTTTTTCCATGTATTTTTTAACATCTGAGCTACTTTTAGCTCCCTGAATGTTCGGATGGAAATATGTTGACCTGGTTTCGGCATGGAGATCGAAGAACCTCTGGTTTTTGCACTGGAATTTTCCTTCGAATTGAAGCAGAACATGTAAGTGAGGAATGCCATCTTCATGAAGTTCTCTGCAAATTCGGATGAATTTCTTGTTTACAGGAGTTGATATAGCGAGTAATTGCTCCAAAGCAGCTTCCTTTGACAGAGTGCATCTGGGATATGTAAGGAAATAGTTCTTTGCGTTTATCTTGAAACGACTCGAATTTGCCATATTGCAAGTCGTTTTTGTATCGGTGTACACCGATTGCCTTATAGCGCCTGTTATTGGTGTATTGGAGTCCCATATATAGGAGTCTCCTAAAACCCTCTAACGGGTCCTCAGAATAATATT
NC_014903
ACCTGAGGACCCGCGCCGGTGTCCCGTCTCTAAGAAGTGGTCCCACAGGTGTCGTGGCATTATGTGGTGACAGCCTGAAGGTTATACTAATGCATCCGCAATTTATGGCGCTTAAAAAGGCGCCCCATGTGCGTATCCGCCTTTAATTTGAATTGTCCTTCAAATATTTTCCGAAAATAACCTTGGAGTACACAAACGACAAATTAATGCGAAGGCAATTATGTGCAATATTTTTAAATTGTAAGGGGTATTAACGATATTGCACGATATTTGTTTACCGGTAACGTTGATATTCGGTTAAATATCTAACATATCTTGTCGTTTGATGGCAGCTTATATAACATTTTAAATTTTATTATATAACAATCATCAGATTGTAAGTTATATGTGTGAAAACACTTATTGTTACAACATAATGAAAATGTTATCTACAAATACTCCTAGCAACAATTGGCGATCTCCCTTTCGTCGCAACACTAATTATCGTCGAGGTGGTCGTATTATGAACACACCATCCAGGTTTAAAATACGGGTTGCTAGGAGATTGTCTTATGGTAAGGTTGAACGACCACTCCAATTTGGAAAATTATGTGAAAAACAACATGGTATCCATATGTCTCTTTCTAGTAATCGTGATATCACGTCATTTATTAGTTATCCTCCATTAAGCTTTGATGGTGATGGTCGTTCAAGGGATTATATTAAATTATTAAGTTTAACTATTTCCGGAATGATAAGTGCAAGGGTTGTATCTGGAGATCAACCTATGGATAATGACATTTATCGCCGCGGAATGTTCGTCATTTCGTTGATTTTAGATCGCAAACCTTATATTGCTGAAGGTGCAAATGAACTGCCGTCATTTGAAGAATTATTTGGTCAGTATTCAGAGAGTTATGTCAATATGCGACTGTTGCCTAGTCGCCAAGATCGTTTCCGTTTGTTAGGAACGATTAAAAAAAATATTAATTGCGACTCTGGAGCGGCAGATGTTAATGTGGGCAAATACATTCGATTTGTTCAAGGTCGTCGGACATTATGGTCAAGATTCAAGGACCCTGACCCTATGGAATCTGGAGGCAATTACCGAAATATTGCAACTAATGCTATATTAGTTAATTATGCATTTATTTCAATGCAACATATTACAGTCAATCCGCTTGTACAATTTGAGTTGAACTATGTTGGATAATTAGAATGATGAATAAAATAATTTATAATTTTTTATTGACATTTGATTTTTGTGATACAAGACATTTGTTTACAGTAGATTCAATAATTTCCTCAATTTCCTTTCTACTAATTGAGGAATTATTAGTTTGTGATACAGAATCACCTGGGTCTAATGATGCTTCCGGTAGTTGATGTAAATGTTTTAGTGGGAACTCCGCTTCAGATGAACTAGGTTTTAGTTCAATGCCTAAGTTGCAATTTGGGCTATAGCGCATAGATGCGCTTCTTGATATTTGAGATTTAGTGGTCCAAGTTTCACCTGGTTGTAATAATATGGGCCTGTTAATTGGGCCATCGTGCCTACCAATGGGATTGGGATTTAATAATCGTCTAATGGGCTTCGGTCGTCCAACAGACCAAAAATCAACGCATTCAGGTGTGAAATCCTTTGATAGGATTTTCACTCTTGGCGGTTTGAACCGAATATCCGTCGAATGTTTCGCGGTTGATAATTTTAGTCTGGCCATAATTTGTGCAAACATCGTATCCTGTATTACATTTGAGTCTTCTACCTTGTAGACTAATTGCCACGGAGATGTATCTTTAACTGAAAAAAATGAAGAGGAGAAATAATGTAGATCAACATTACAACCAATGGGAAATGTGAATGCAGCTTGTGCTGCCTCGTCGTCGCAAAGTCTCTTGTCTAAAATGGTCACAACCACGGTGCCTGTGGCGTTAAATGGAACTTGGTTCCTATACTCGATCACAACGTGATCAATTTTCATGCATTTGCCCATTAGTTTGACCATTTTCTGTTCCAGGAAAGTTGGAAATTGAAGAGCAATTTCGGTATCATCATTTGTCAATTTGTATTCGCATCGCTTTGATTCAATATAGTTGCTTGTCGCAACAACTCCCGTGTAATTTTCCATGGTTATTAAATAACAATTGCGATGCGGTACAAAACCTGCGTAAGAAATTCCATCCATTATAATCATATTATTCTTTATCCGGCCGCGCAAGCGGCATTATTTTAAAATATTGTTAGCATCAACAACAAATTGACCCAGAATGTGAAAACGTTATAACTTTATGCGTAATTTGTAAAAATTACGAGCCATTGCGAAAGAAAATTGCTGAGGAAAATAATATTTTATAAAAATAGTTGACAAGAATATGCATACCTTATTGCTGGAAATATTAAAACTCGTATATGTTAACGCTTTCCTAATATTATATTTATAGAGGAATGAAAACAACAATAACCGTTAATATTTGTTTATGTGCGCTATTTATATATAGCATTTAAGTGACGGCGTGTGTGGTTTCATTCACACCAATGACTCTTAAACGAGAGCGTCTCTCTCTAGAATTGATATGCGATAGTTTCTCTCTCTAGCGAATCGGTGTACACCGATTGCCTTATAGCGCATGTTATTGGTGTATTGGAGTCCCATATATAGAGTCCCCTATAACCCTGACACGGGTCCTCAGTATAATATT
Gene Information
| NCBI Accession | YP_004123931.1 |
|---|---|
| Location | 130-489 |
| Gene Name | AV2 |
| Protein Name | precoat protein |
| Coding Region | ATGATAAAGATGTGGGATCCATTGTTGAATGACTTTCCCAAATCACGGCATGGTTTTCGGTGCATGATTGCCATTAAGTTCTTGCAAGCCTGTCAAGAACAATATCCTAATAATTCATTGGGATTTGAATTTTTGCGCAAACTCATTTCAAATTTGCGCTCCAAGGACCATGCCAAAGCGGAATTACGATACCGCCTTCTCATCACCGCTATCAGTAGTTCGTCGAAGATTGAACTTCGACAGCCCAATGGCACTACCTGCACCTGCATCCAGTGCCCAAGGCACAACAAGGAGAAGGCGTTGGACGAATCGTCCGATGTGGAGGAAACCACGTTTTTATCGATTGTATCGGACACCTGA |
| Protein Sequence | MIKMWDPLLNDFPKSRHGFRCMIAIKFLQACQEQYPNNSLGFEFLRKLISNLRSKDHAKAELRYRLLITAISSSSKIELRQPNGTTCTCIQCPRHNKEKALDESSDVEETTFLSIVSDT |
| NCBI Accession | YP_004123932.1 |
|---|---|
| Location | 222-515 |
| Gene Name | AC5 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGACCTTCACAACCACGTGGAACATCAGGTGTCCGATACAATCGATAAAAACGTGGTTTCCTCCACATCGGACGATTCGTCCAACGCCTTCTCCTTGTTGTGCCTTGGGCACTGGATGCAGGTGCAGGTAGTGCCATTGGGCTGTCGAAGTTCAATCTTCGACGAACTACTGATAGCGGTGATGAGAAGGCGGTATCGTAATTCCGCTTTGGCATGGTCCTTGGAGCGCAAATTTGAAATGAGTTTGCGCAAAAATTCAAATCCCAATGAATTATTAGGATATTGTTCTTGA |
| Protein Sequence | MDLHNHVEHQVSDTIDKNVVSSTSDDSSNAFSLLCLGHWMQVQVVPLGCRSSIFDELLIAVMRRRYRNSALAWSLERKFEMSLRKNSNPNELLGYCS |
| NCBI Accession | YP_004123933.1 |
|---|---|
| Location | 299-1072 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCAAAGCGGAATTACGATACCGCCTTCTCATCACCGCTATCAGTAGTTCGTCGAAGATTGAACTTCGACAGCCCAATGGCACTACCTGCACCTGCATCCAGTGCCCAAGGCACAACAAGGAGAAGGCGTTGGACGAATCGTCCGATGTGGAGGAAACCACGTTTTTATCGATTGTATCGGACACCTGATGTTCCACGTGGTTGTGAAGGTCCATGTAAGGTTCAATCCTTTGAACAACGGCATGATATTGCCCATACTGGCAAAGTAATTTGCATTTCAGATGTTACTCGAGGTAATGGAATTACTCATCGTGTTGGGAAACGTTTCTGTGTCAAGTCCGTATATATTACTGGTAAGGTTTGGATGGACGAGAATATTAAGTCCAAAAACCATACTAATACGGTCATGTTTAAGTTATGTCGTGACAGACGACCCTTTGGGACTCCTATGGATTTCGGTCAGGTGTTTAATATGTATGATAATGAACCAAGTACTGCGACAGTGAAGAACGATCTTCGTGATCGTTTTCAAGTTCTGCGAAGATTTAATGCCACGGTTACAGGTGGCCAATATGCATGCAAGGAGCAAGCCATGGTTAACCGTTTTTATCGTGTTAACAATCATGTGGTTTATAATCATCAGGAAGCTGCCAAATATGAAAATCATACTGAGAATGCGTTGTTATTGTATATGGCATGTACTCATGCTTCAAACCCTGTGTATGCGACATTAAAGATCAGGATCTATTTCTATGATTCTGTTGGAAATTAA |
| Protein Sequence | MPKRNYDTAFSSPLSVVRRRLNFDSPMALPAPASSAQGTTRRRRWTNRPMWRKPRFYRLYRTPDVPRGCEGPCKVQSFEQRHDIAHTGKVICISDVTRGNGITHRVGKRFCVKSVYITGKVWMDENIKSKNHTNTVMFKLCRDRRPFGTPMDFGQVFNMYDNEPSTATVKNDLRDRFQVLRRFNATVTGGQYACKEQAMVNRFYRVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVGN |
| NCBI Accession | YP_004123934.1 |
|---|---|
| Location | 1212-1619 |
| Gene Name | AC2 |
| Protein Name | transcription activator protein |
| Coding Region | ATGCGGAATTCTACACCATCAAAGAACCATTTTTCACCACCGTCAATCAAAGCGCAACACAGGTGCGCCAAGAAGAAAGCAATTCGACGCAAACGAATTGACCTCAAGTGCGGCTGCTCATATTATATGCACATTAACTGTGCTAACCATGGATTTACGCACAGGGGAGAACATCACTGCAATTCAAGCACAGAATGGCGTATATATCTGGGAGATAAAAAATCCCCTATATTTCAAGATCCTCGAGCATCACAAGAGACCGTTCAACAGCAACAACGACATTTTGACTGTCCAGATCAGATTCAACCACAACTTAAGGAAGGCACTGGGGATTCACAAATGTTTTTTGACCTTCAAAATTTGGACGACCTTACGGCCTCCGACTGGTCTTTTCTTAAAGACATTTAA |
| Protein Sequence | MRNSTPSKNHFSPPSIKAQHRCAKKKAIRRKRIDLKCGCSYYMHINCANHGFTHRGEHHCNSSTEWRIYLGDKKSPIFQDPRASQETVQQQQRHFDCPDQIQPQLKEGTGDSQMFFDLQNLDDLTASDWSFLKDI |
| NCBI Accession | YP_004123935.1 |
|---|---|
| Location | 1519-2607 |
| Gene Name | AC1 |
| Protein Name | replication initiation protein |
| Coding Region | ATGGCAAATTCGAGTCGTTTCAAGATAAACGCAAAGAACTATTTCCTTACATATCCCAGATGCACTCTGTCAAAGGAAGCTGCTTTGGAGCAATTACTCGCTATATCAACTCCTGTAAACAAGAAATTCATCCGAATTTGCAGAGAACTTCATGAAGATGGCATTCCTCACTTACATGTTCTGCTTCAATTCGAAGGAAAATTCCAGTGCAAAAACCAGAGGTTCTTCGATCTCCATGCCGAAACCAGGTCAACATATTTCCATCCGAACATTCAGGGAGCTAAAAGTAGCTCAGATGTTAAAAAATACATGGAAAAAGACGGAGACGTCGTTGATCATGGAGAATTCCAAATTGATGGTCGATCAAGTCGAGGAGGTAAGCAATCTGCAAACGACGCTTATGCCGAAGCAATCAATGCAGGAAATACCTCTGAGGCGCTCGTTATACTAAAGGAAAAGGCTCCGAAGGATTTCGTTTTATATTTTCATAATTTAGCTAAGAATTTTGATAAAATTTTTGAAAAAAGTGTTCCAGTTTATGAACCTCGTTATTCAATTGAATCATTCGATAATGTTCCACCGTACATTTCTTCTTGGGCGGAAAGAAATGTGAAGGATTCCGCTGCGCGGCCAGAAAGACCGATTAGCATTGTCATTGAAGGTGATAGTCGTACTGGGAAGACGACATGGGCTCGTGCATTGGGGCCGCACAATTATCTCTGCGGCCATTTGGACCTTAGTCCGAAAGTGTATTCCAACGATGCATGGTATAACGTCATTGATGACGTCGATCCGCATTATTTGAAACATTTCAAAGAATTCATGGGCGCACAACGTGACTGGCAAAGTAACGTCAAATACGGAAAGCCCACAATGATTAAAGGTGGTATCCCCACAATCTTTCTCTGCAACCCAGGCAACAAATCTTCTTATAAAGAGTTCCTCGACGAGGAAGCAAATGCATCACTAAAATTGTGGGCTTCCAAGAATGCGGAATTCTACACCATCAAAGAACCATTTTTCACCACCGTCAATCAAAGCGCAACACAGGTGCGCCAAGAAGAAAGCAATTCGACGCAAACGAATTGA |
| Protein Sequence | MANSSRFKINAKNYFLTYPRCTLSKEAALEQLLAISTPVNKKFIRICRELHEDGIPHLHVLLQFEGKFQCKNQRFFDLHAETRSTYFHPNIQGAKSSSDVKKYMEKDGDVVDHGEFQIDGRSSRGGKQSANDAYAEAINAGNTSEALVILKEKAPKDFVLYFHNLAKNFDKIFEKSVPVYEPRYSIESFDNVPPYISSWAERNVKDSAARPERPISIVIEGDSRTGKTTWARALGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNVKYGKPTMIKGGIPTIFLCNPGNKSSYKEFLDEEANASLKLWASKNAEFYTIKEPFFTTVNQSATQVRQEESNSTQTN |
| NCBI Accession | YP_004123936.1 |
|---|---|
| Location | 2157-2456 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGAAGATGGCATTCCTCACTTACATGTTCTGCTTCAATTCGAAGGAAAATTCCAGTGCAAAAACCAGAGGTTCTTCGATCTCCATGCCGAAACCAGGTCAACATATTTCCATCCGAACATTCAGGGAGCTAAAAGTAGCTCAGATGTTAAAAAATACATGGAAAAAGACGGAGACGTCGTTGATCATGGAGAATTCCAAATTGATGGTCGATCAAGTCGAGGAGGTAAGCAATCTGCAAACGACGCTTATGCCGAAGCAATCAATGCAGGAAATACCTCTGAGGCGCTCGTTATACTAA |
| Protein Sequence | MKMAFLTYMFCFNSKENSSAKTRGSSISMPKPGQHISIRTFRELKVAQMLKNTWKKTETSLIMENSKLMVDQVEEVSNLQTTLMPKQSMQEIPLRRSLY |
| NCBI Accession | YP_004123937.1 |
|---|---|
| Location | 386-1192 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTGTGAAAACACTTATTGTTACAACATAATGAAAATGTTATCTACAAATACTCCTAGCAACAATTGGCGATCTCCCTTTCGTCGCAACACTAATTATCGTCGAGGTGGTCGTATTATGAACACACCATCCAGGTTTAAAATACGGGTTGCTAGGAGATTGTCTTATGGTAAGGTTGAACGACCACTCCAATTTGGAAAATTATGTGAAAAACAACATGGTATCCATATGTCTCTTTCTAGTAATCGTGATATCACGTCATTTATTAGTTATCCTCCATTAAGCTTTGATGGTGATGGTCGTTCAAGGGATTATATTAAATTATTAAGTTTAACTATTTCCGGAATGATAAGTGCAAGGGTTGTATCTGGAGATCAACCTATGGATAATGACATTTATCGCCGCGGAATGTTCGTCATTTCGTTGATTTTAGATCGCAAACCTTATATTGCTGAAGGTGCAAATGAACTGCCGTCATTTGAAGAATTATTTGGTCAGTATTCAGAGAGTTATGTCAATATGCGACTGTTGCCTAGTCGCCAAGATCGTTTCCGTTTGTTAGGAACGATTAAAAAAAATATTAATTGCGACTCTGGAGCGGCAGATGTTAATGTGGGCAAATACATTCGATTTGTTCAAGGTCGTCGGACATTATGGTCAAGATTCAAGGACCCTGACCCTATGGAATCTGGAGGCAATTACCGAAATATTGCAACTAATGCTATATTAGTTAATTATGCATTTATTTCAATGCAACATATTACAGTCAATCCGCTTGTACAATTTGAGTTGAACTATGTTGGATAA |
| Protein Sequence | MCENTYCYNIMKMLSTNTPSNNWRSPFRRNTNYRRGGRIMNTPSRFKIRVARRLSYGKVERPLQFGKLCEKQHGIHMSLSSNRDITSFISYPPLSFDGDGRSRDYIKLLSLTISGMISARVVSGDQPMDNDIYRRGMFVISLILDRKPYIAEGANELPSFEELFGQYSESYVNMRLLPSRQDRFRLLGTIKKNINCDSGAADVNVGKYIRFVQGRRTLWSRFKDPDPMESGGNYRNIATNAILVNYAFISMQHITVNPLVQFELNYVG |
| NCBI Accession | YP_004123938.1 |
|---|---|
| Location | 1215-2174 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGATTATAATGGATGGAATTTCTTACGCAGGTTTTGTACCGCATCGCAATTGTTATTTAATAACCATGGAAAATTACACGGGAGTTGTTGCGACAAGCAACTATATTGAATCAAAGCGATGCGAATACAAATTGACAAATGATGATACCGAAATTGCTCTTCAATTTCCAACTTTCCTGGAACAGAAAATGGTCAAACTAATGGGCAAATGCATGAAAATTGATCACGTTGTGATCGAGTATAGGAACCAAGTTCCATTTAACGCCACAGGCACCGTGGTTGTGACCATTTTAGACAAGAGACTTTGCGACGACGAGGCAGCACAAGCTGCATTCACATTTCCCATTGGTTGTAATGTTGATCTACATTATTTCTCCTCTTCATTTTTTTCAGTTAAAGATACATCTCCGTGGCAATTAGTCTACAAGGTAGAAGACTCAAATGTAATACAGGATACGATGTTTGCACAAATTATGGCCAGACTAAAATTATCAACCGCGAAACATTCGACGGATATTCGGTTCAAACCGCCAAGAGTGAAAATCCTATCAAAGGATTTCACACCTGAATGCGTTGATTTTTGGTCTGTTGGACGACCGAAGCCCATTAGACGATTATTAAATCCCAATCCCATTGGTAGGCACGATGGCCCAATTAACAGGCCCATATTATTACAACCAGGTGAAACTTGGACCACTAAATCTCAAATATCAAGAAGCGCATCTATGCGCTATAGCCCAAATTGCAACTTAGGCATTGAACTAAAACCTAGTTCATCTGAAGCGGAGTTCCCACTAAAACATTTACATCAACTACCGGAAGCATCATTAGACCCAGGTGATTCTGTATCACAAACTAATAATTCCTCAATTAGTAGAAAGGAAATTGAGGAAATTATTGAATCTACTGTAAACAAATGTCTTGTATCACAAAAATCAAATGTCAATAAAAAATTATAA |
| Protein Sequence | MIIMDGISYAGFVPHRNCYLITMENYTGVVATSNYIESKRCEYKLTNDDTEIALQFPTFLEQKMVKLMGKCMKIDHVVIEYRNQVPFNATGTVVVTILDKRLCDDEAAQAAFTFPIGCNVDLHYFSSSFFSVKDTSPWQLVYKVEDSNVIQDTMFAQIMARLKLSTAKHSTDIRFKPPRVKILSKDFTPECVDFWSVGRPKPIRRLLNPNPIGRHDGPINRPILLQPGETWTTKSQISRSASMRYSPNCNLGIELKPSSSEAEFPLKHLHQLPEASLDPGDSVSQTNNSSISRKEIEEIIESTVNKCLVSQKSNVNKKL |
References More References in PubMed
| 1 |
Akram M, et al. Virus Genes. 2025 Feb;61(1):110-120. doi: 10.1007/s11262-024-02120-4. Epub 2024 Nov 6. PMID: 39503983 |
|---|---|
| 2 |
Dokka N, et al. Plant Dis. 2023 Oct;107(10):2924-2928. doi: 10.1094/PDIS-06-22-1473-SC. Epub 2023 Oct 11. PMID: 36890129 |
| 3 |
Akram M, et al. Arch Virol. 2024 Dec 11;170(1):7. doi: 10.1007/s00705-024-06203-3. PMID: 39661203 |
| 4 |
Jyothsna P, et al. Virus Genes. 2011 Jun;42(3):407-14. doi: 10.1007/s11262-011-0580-1. Epub 2011 Feb 12. PMID: 21318241 |
| 5 |
Simmonds-Gordon RN, et al. Arch Virol. 2014 Oct;159(10):2815-8. doi: 10.1007/s00705-014-2112-5. Epub 2014 May 29. PMID: 24872185 |