Pumpkin yellow mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000874505.1 |
| Isolate | Malaysia: Negeri Sembilan |
| Release date | 2015/2/13 |
| Submitter | Tsai,W.S., Shih,S.L., Roff,M.M.N., Green,S.K. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
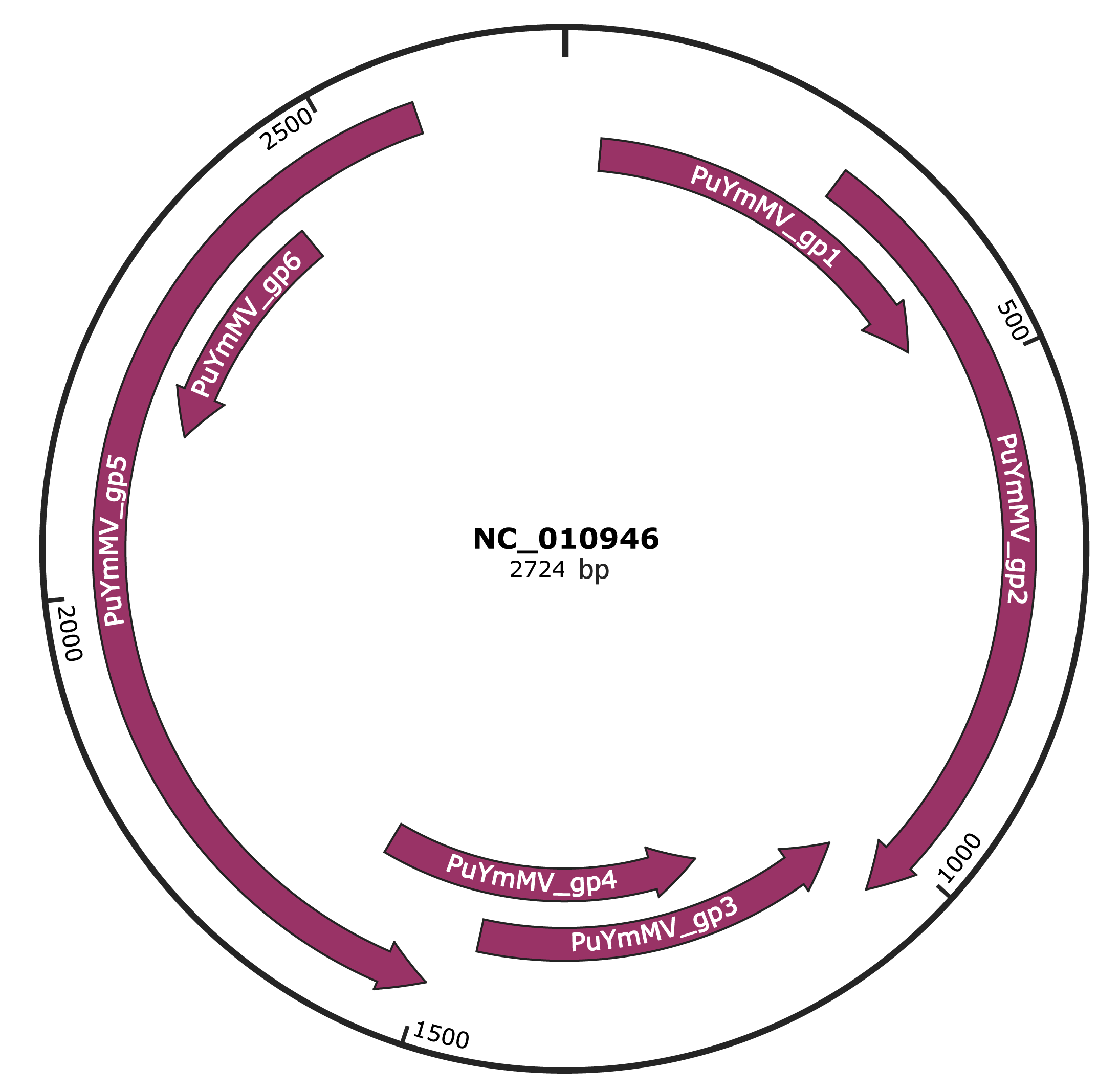
JBrowse
Genome
NC_010946
Gene Information
| NCBI Accession | YP_001974387.1 |
|---|---|
| Location | 40-456 |
| Protein Name | precoat protein |
| Coding Region | ATGAAATTCACGCTACATGGCTTATTTATTACATGGGGACCATTAAATAGACTTCCTCACCAAGTTTTGATCCACACCATGTGGGATCCACTTCTGCACGAATTTCCTGAAAGTGTTCATGGTCTAAGGTGCATGCTAGCGGTGAAATATCTTCAGGAAGTGGAAAAAACATATTCTCCGGACACAGTCGGCTACGATCTTGTCCGCGATCTTATTCTTGTTCTCCGCGCAAAGAACTATGTCGAAGCGACCAGCCGATATTATCATTTCAACTCCCGCGTCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCCTATGTTTCCCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAGGGAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCCAAGATGTACAGAATGTATAG |
| Protein Sequence | MKFTLHGLFITWGPLNRLPHQVLIHTMWDPLLHEFPESVHGLRCMLAVKYLQEVEKTYSPDTVGYDLVRDLILVLRAKNYVEATSRYYHFNSRVEGTPTSQLRQPLCFPCSCPHCPRHKGKGLDKQADEQKTQDVQNV |
| NCBI Accession | YP_001974388.1 |
|---|---|
| Location | 278-1048 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCAGCCGATATTATCATTTCAACTCCCGCGTCGAAGGTACGCCGACGTCTCAACTTCGACAGCCCCTATGTTTCCCGTGCAGTTGTCCCCATTGCCCGCGTCACAAAGGGAAAGGCCTGGACAAACAGGCCGATGAACAGAAAACCCAAGATGTACAGAATGTATAGAAGTCCCGACGTGCCAAGGGGCTGTGAAGGCCCTTGTAAAGTTCAATCCTTTGAATCTAGGCACGATGTCTCTCATATTGGGAAGGTATTGTGTATCAGTGATGTTACACGAGGAACCGGACTCACACATCGCGTTGGGAAGCGATTCTGTGTGAAATCTGTTTTTGTTTTGGGAAAGATATGGGTGGATGAAAATATCAAGACTAAAAATCACACTAATAGCGTTATATTGTTTTTGGTTCGAGACCGTCGTCCTACAAGAACTCCACAAGATTTTGGGGAGGTTTTTAATATGTTCGACAATGAACCGAGCACTGCAACGGTGAAGAACATGCATCGTGATCGATACCAAGTGATACGCAAATGGCATGCCACTGTGACGGGAGGAACATACGCATCAAGGGAGCAAGCATTAGTTAGGAAGTTTGTTAGAGTCAATAATTATGTTGTCTACAATCAACAAGAGGCCGGCAAGTATGAGAATCATACTGAAAATGCATTAATGTTGTATATGGCCTGTACTCACGCATCGAACCCTGTATACGCGACTTTGAAAATTCGGATCTATTTTTATGATTCGGTAACAAATTAA |
| Protein Sequence | MSKRPADIIISTPASKVRRRLNFDSPYVSRAVVPIARVTKGKAWTNRPMNRKPKMYRMYRSPDVPRGCEGPCKVQSFESRHDVSHIGKVLCISDVTRGTGLTHRVGKRFCVKSVFVLGKIWVDENIKTKNHTNSVILFLVRDRRPTRTPQDFGEVFNMFDNEPSTATVKNMHRDRYQVIRKWHATVTGGTYASREQALVRKFVRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | YP_001974389.1 |
|---|---|
| Location | 1045-1455 |
| Protein Name | C3 protein |
| Coding Region | ATGATCACGGATTCACGCACAGGGGAGTACATCACTGTGGATCGAGCAGAGAGTGGCGTATATATCTGGGAAGTTCCAAATCCCCTCTATTTCAAAATATTGAAACACGACATCAGACCTTGTCTCACGGAACACGACATAATCAAAATGCATGTAATGTTCAACCACAAACTGCGGAAAGCACTGGGACTTCACAAATGTGTTCTAATGTTCCAGATCTGGACGGGCTTACGCCCTCCGACTGGGATTTTCTTGAGAGTCTTTAAGACCCAAGTCCTTAAGTACTTGGATATGTTAGGGGTGATTAGTATTTACAATGTATTAAGAGCAGTTTATCACGTTTTAGACGATGTATTGGAAAAGACAATTGATGTATGGACAACATATAATGTGAAATTGAATATATATTAA |
| Protein Sequence | MITDSRTGEYITVDRAESGVYIWEVPNPLYFKILKHDIRPCLTEHDIIKMHVMFNHKLRKALGLHKCVLMFQIWTGLRPPTGIFLRVFKTQVLKYLDMLGVISIYNVLRAVYHVLDDVLEKTIDVWTTYNVKLNIY |
| NCBI Accession | YP_001974390.1 |
|---|---|
| Location | 1190-1594 |
| Protein Name | C2 protein |
| Coding Region | ATGCAATCTTCCTCACAATCAAAGAACCACTCTATTCCGGTCGCGAAAAAATCGCTACCGCACAACAAGAAGAAGAATATCAGGCGCAGACGAATTGATCTACCGTGCGGATGCTCGTATTACATGTCAATAAATTGCCATGATCACGGATTCACGCACAGGGGAGTACATCACTGTGGATCGAGCAGAGAGTGGCGTATATATCTGGGAAGTTCCAAATCCCCTCTATTTCAAAATATTGAAACACGACATCAGACCTTGTCTCACGGAACACGACATAATCAAAATGCATGTAATGTTCAACCACAAACTGCGGAAAGCACTGGGACTTCACAAATGTGTTCTAATGTTCCAGATCTGGACGGGCTTACGCCCTCCGACTGGGATTTTCTTGAGAGTCTTTAA |
| Protein Sequence | MQSSSQSKNHSIPVAKKSLPHNKKKNIRRRRIDLPCGCSYYMSINCHDHGFTHRGVHHCGSSREWRIYLGSSKSPLFQNIETRHQTLSHGTRHNQNACNVQPQTAESTGTSQMCSNVPDLDGLTPSDWDFLESL |
| NCBI Accession | YP_001974391.1 |
|---|---|
| Location | 1497-2582 |
| Protein Name | replication-associated protein C1 |
| Coding Region | ATGCCTAGAGCCGGACGTTTTTCTATTAAAGCCAAAAATTATTTTCTCACTTATCCACAGTGCTCCCTCACCAAGGAAGAAGCACTTTCCCAATTAAAACCTCTACAAACCCCAACAAATAAAAAATATATCAAAATCTGTAGAGAGCTGCACGAAGATGGGAGCCCTCATCTCCATGTGCTCATTCAATTCGAAGGCAAATGCAACTGCACGAATAACAGATTCTTCGACTTGGTATCCCCAACCAAGTCTACACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAATCCTACCTGGACAAGGACGGAGACACCCTCGACTGGGGAGAATTCCAGATCGACGGTCGAAGTGCTAGAGGAGGGTGCCAGAATTCTAACGACGCATGCGCAGAAGCCTTAAACGCAGGTTCCAAAGAAGCAGCACTAAGTATAATAAGGGAGAAACTCCCAAAAGATTATATTTTTCAATTTCATAATTTAAATTCTAATTTAGATAGGATTTTTGCACCTCCTTTAGAGGTTTTTGTTTGTCCTTTTCTTTCTTCTTCATTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGTTTCTGAGAACGTGGGGTGTTCCGCTGCGCGGCCAAATAGACCCATAAGTATTGTCATAGAGGGTGAGAGTCGTACAGGAAGGACAATGTGGGCTCGTTCATTGGGCCCACATAATTATCTGTGCGGTCATCTAGATCTGAGTCCAAAGGTGTACAGCAACGATGCATGGTACAACGTCATTGATGACGTCGACCCCCACTATTTAAAGCATTTCAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACGAAGTACGGAAAGCCAATTCAAATTAAAGGTGGTATCCCGACAATCTTCCTATGCAATCCAGGACCAACGTCATCATATAAAGAGTACTTGGAAGAGGATAAGAATTCAGCACTGAAGCAGTGGGCATTAAAGAATGCAATCTTCCTCACAATCAAAGAACCACTCTATTCCGGTCGCGAAAAAATCGCTACCGCACAACAAGAAGAAGAATATCAGGCGCAGACGAATTGA |
| Protein Sequence | MPRAGRFSIKAKNYFLTYPQCSLTKEEALSQLKPLQTPTNKKYIKICRELHEDGSPHLHVLIQFEGKCNCTNNRFFDLVSPTKSTHFHPNIQGAKSSSDVKSYLDKDGDTLDWGEFQIDGRSARGGCQNSNDACAEALNAGSKEAALSIIREKLPKDYIFQFHNLNSNLDRIFAPPLEVFVCPFLSSSFDQVPEELEEWVSENVGCSAARPNRPISIVIEGESRTGRTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLEEDKNSALKQWALKNAIFLTIKEPLYSGREKIATAQQEEEYQAQTN |
| NCBI Accession | YP_001974392.1 |
|---|---|
| Location | 2168-2425 |
| Protein Name | C4 protein |
| Coding Region | ATGGGAGCCCTCATCTCCATGTGCTCATTCAATTCGAAGGCAAATGCAACTGCACGAATAACAGATTCTTCGACTTGGTATCCCCAACCAAGTCTACACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAATCCTACCTGGACAAGGACGGAGACACCCTCGACTGGGGAGAATTCCAGATCGACGGTCGAAGTGCTAGAGGAGGGTGCCAGAATTCTAACGACGCATGCGCAGAAGCCTTAA |
| Protein Sequence | MGALISMCSFNSKANATARITDSSTWYPQPSLHISIRTFRELNPAPTSNPTWTRTETPSTGENSRSTVEVLEEGARILTTHAQKP |
References More References in PubMed
| 1 |
Zechmann B, et al. Protoplasma. 2021 Nov;258(6):1201-1211. doi: 10.1007/s00709-021-01626-0. Epub 2021 Feb 22. PMID: 33619654 |
|---|---|
| 2 |
Epidemiology of Zucchini yellow mosaic virus in cucurbit crops in a remote tropical environment. Clarke R, et al. Virus Res. 2020 May;281:197897. doi: 10.1016/j.virusres.2020.197897. Epub 2020 Feb 19. PMID: 32087188 |
| 3 |
Complete Genome Sequence of a Zucchini Yellow Mosaic Virus Isolated from Pumpkin in Oklahoma. Khanal V, et al. Microbiol Resour Announc. 2019 Jan 10;8(2):e01583-18. doi: 10.1128/MRA.01583-18. eCollection 2019 Jan. PMID: 30643904 |
| 4 |
Phaneendra C, et al. Virusdisease. 2014;25(3):390-3. doi: 10.1007/s13337-013-0189-1. Epub 2014 Feb 1. PMID: 25674610 |
| 5 |
Abdelkhalek A, et al. Biology (Basel). 2022 Jul 30;11(8):1150. doi: 10.3390/biology11081150. PMID: 36009777 |
| 6 |
First Report of Squash Mosaic Virus in Ornamental Pumpkin in the Czech Republic. Svoboda J, et al. Plant Dis. 2011 Oct;95(10):1321. doi: 10.1094/PDIS-05-11-0444. PMID: 30731671 |
| 7 |
Ali R, et al. Sci Rep. 2024 May 28;14(1):12257. doi: 10.1038/s41598-024-62128-6. PMID: 38806538 |
| 8 |
Simmons HE, et al. Virus Res. 2013 Sep;176(1-2):259-64. doi: 10.1016/j.virusres.2013.06.016. Epub 2013 Jul 8. PMID: 23845301 |
| 9 |
First Report of Zucchini yellow mosaic virus in Cucurbits in Ivory Coast. Koné D, et al. Plant Dis. 2010 Nov;94(11):1378. doi: 10.1094/PDIS-06-10-0416. PMID: 30743639 |
| 10 |
Maina S, et al. Plant Dis. 2019 Jun;103(6):1326-1336. doi: 10.1094/PDIS-09-18-1666-RE. Epub 2019 Apr 16. PMID: 30995424 |