Bean calico mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000840005.1 |
| Release date | 2015/2/12 |
| Submitter | Brown,J.K., Ostrow,K.M., Idris,A.M., Stenger,D.C. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
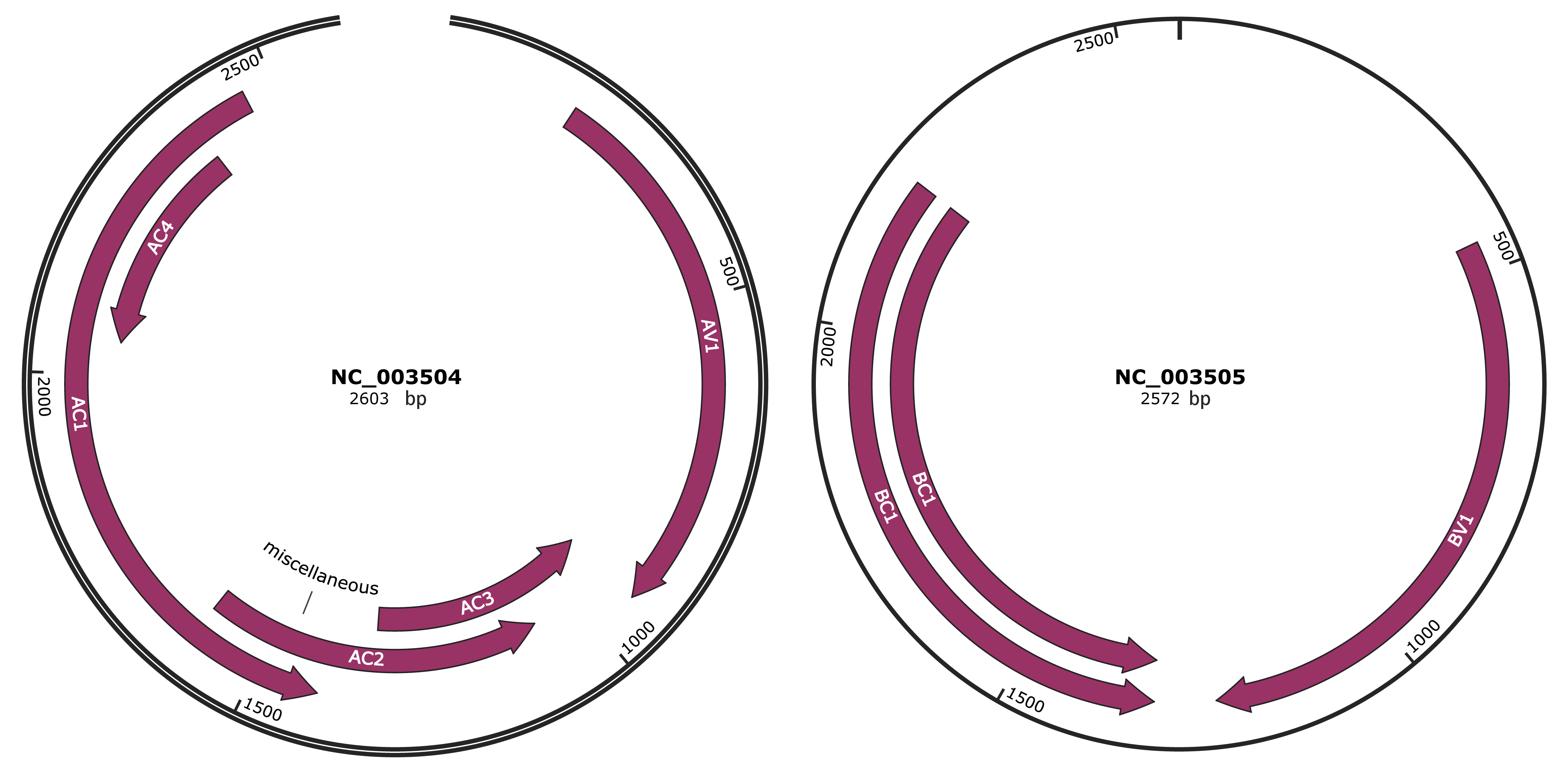
JBrowse
Genome
NC_003504
NC_003505
Gene Information
| NCBI Accession | NP_612594.1 |
|---|---|
| Location | 188-937 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCATGGCGTAACATGGCGGGGACCTCAAAGGTAACCCGTTCTAGCAATTATTCTCCTCGCGGTGGTCCCAAATTCAACAAGGCCGATGCATGGGTTAACAGGCCCATGTATAGGAAGCCCAGAATTTATCGGACATTGAGAGGCCCCGATGTTCCAAGAGGGTGTGAAGGACCTTGTAAGGTTCAGTCTTACGAGCAGAGACATGATGTTTCTCATGTCGGGAAGGTTATGTGCATTTCTGATATTACCCGTGGTAACGGTATTACCCACCGCGTTGGTAAGCGTTTTTGTGTTAAGTCCGTGTATATTTTAGGTAAGATATGGATGGACGAAAATATCAAGTTAAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTTAGAGATCGTAGACCATATGGTACTCCTCTTGATTTTGGCCAAGTGTTCAACATGTTTGACAACGAACCTAGTACTGCTACTGTGAAGAATGATTTGCGTGATCGTTTTCAAGTCATGCATAAATTTTATGGTAAGGTTACAGGTGGACAATATGCCAGCAACGAACAAGCACTGGTGAAGCGTTTTTGGAAGGTTAATAATTATGTTGTCTACAACCATCAAGAAGCTGGGAAATACGAAAATCATACTGAAAATGCATTATTATTGTATATGGCATGTACTCATGCTTCTAATCCTGTGTATGCTACATTGAAAATTCGGATCTATTTTTACGATTCGATAACCAATTAA |
| Protein Sequence | MPKRDAPWRNMAGTSKVTRSSNYSPRGGPKFNKADAWVNRPMYRKPRIYRTLRGPDVPRGCEGPCKVQSYEQRHDVSHVGKVMCISDITRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPLDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYGKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | NP_612595.1 |
|---|---|
| Location | 934-1332 |
| Gene Name | AC3 |
| Protein Name | Ren |
| Coding Region | ATGGATTCACGCACAGGGGAGTTCATCACTGCGGCTCAAGCAGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATATACACGATAGAGGATCCAATGTACACAAGGACGAGAATATACCACATCCAAATCCGGTTCAATTACAACCTAAGGAAGTCACTGAATCTACACAAAGCTTTCCTGAATTTCCAAATCTGGACGACGTCAGTTCAAGCTTCTGGAACGACTTATTTACAGAGATTTAAGTATTTAGTTTTATTGTATCTAGACAGAATAGGTGTTGTTGGAATTAATAACGTTATAAGAGCTGTTCGTTTCGCAACAGACAAACCATATGTAAATTATGTAATAGAAAATCATTCAATAAAATTCAAATATTATTAA |
| Protein Sequence | MDSRTGEFITAAQAENSVFIWEVPNPLYFKIYTIEDPMYTRTRIYHIQIRFNYNLRKSLNLHKAFLNFQIWTTSVQASGTTYLQRFKYLVLLYLDRIGVVGINNVIRAVRFATDKPYVNYVIENHSIKFKYY |
| NCBI Accession | NP_612596.1 |
|---|---|
| Location | 1073-1597 |
| Gene Name | AC2 |
| Protein Name | TrAP |
| Coding Region | ATGGAAAGCCGGTTCAAATTAAAGGCGGGATACCATCAATCGTGCTGTGCAATCCAGGAGAGGGGGCCAGTTATAAAGATTTCCTCGACAAAGAGGAAAACGCATCGCTTAAAAATTGGACAATCCAAAATGCTAAATTCATCTTCCTCAACACCCCCCTCTATCAAAGCACAGCACAGGATCGCTAAAAGAAGAGCTATTCGACGACGACGGATAGATTTGAACTGCGGCTGTTCCATATTTCTACACATCAACTGCGCTGATAATGGATTCACGCACAGGGGAGTTCATCACTGCGGCTCAAGCAGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATATACACGATAGAGGATCCAATGTACACAAGGACGAGAATATACCACATCCAAATCCGGTTCAATTACAACCTAAGGAAGTCACTGAATCTACACAAAGCTTTCCTGAATTTCCAAATCTGGACGACGTCAGTTCAAGCTTCTGGAACGACTTATTTACAGAGATTTAA |
| Protein Sequence | MESRFKLKAGYHQSCCAIQERGPVIKISSTKRKTHRLKIGQSKMLNSSSSTPPSIKAQHRIAKRRAIRRRRIDLNCGCSIFLHINCADNGFTHRGVHHCGSSREFRFYLGGSKSPLFQDIHDRGSNVHKDENIPHPNPVQLQPKEVTESTQSFPEFPNLDDVSSSFWNDLFTEI |
| NCBI Accession | NP_612597.1 |
|---|---|
| Location | 1410-2459 |
| Gene Name | AC1 |
| Protein Name | Rep |
| Coding Region | ATGCCACGGAACCCCAGTTCTTTTCGTATAACTGCAAGAAACATCTTCTTAACATACCCACAGTGCGACATAAACAAGGATGAAGCTCTTCGCTTGCTTCAAGAACTGCCATGGTCAGTCGTCAAACCAACATATATCCGAGTCGCCCGAGAGGAACATTCAGATGGATTCCCTCATCTACACTGTCTCATTCAACTCTCAGGCAAGTCCAACATCAAGGATGTTAGATTTTTCGACCTTACTCACCCAAGAAGGTCTGCCAATTTTCACCCAAACGTTCAGGCAGCCAAGGACACCAACGCAGTCAAGAACTACATCACCAAAGAAGGTGATTATTGTGAATCCGGGGAATATAAGGTGTCTGGCTCAACAAAATCAAACAAGGACGACGTATACCACAACGCAGTAAATGCAGGAAGTATTAAAGAGGCGCTAGACATTATTAGAGCCGGAGATCCAAAGACATTCATCGTCAACTACCATAACATAAAGGCCAACATCGAACGCCTCTTTAAAAAGGCTCCAGAACCATGGGTTCCTCCGTTTCAACTCTCTTCCTTCACGTTCGTTCCAGATGAGATGCAAGAGTGGGCGGACGACTATTTCGGAAGGGGTGCCGCTGCGCGGGCGGAGAGACCTATTAGTATCATCGTCGAAGGTGGTTCACGTACCGGAAAAACCATGTGGGCTCGTGCATTAGGACCACACAATTATCTTAGTGGACACCTGGATTTCAATTCTTCAGTGTACTCTAACGAGGTTGAGTATAACGTCATCGATGACATCAGTCCGCAATACCTAAAGCTAAAGCACTGGAAAGAATTGATTGGGGCCCAAAGAGACTGGCAATCCAACTGCAAATATGGAAAGCCGGTTCAAATTAAAGGCGGGATACCATCAATCGTGCTGTGCAATCCAGGAGAGGGGGCCAGTTATAAAGATTTCCTCGACAAAGAGGAAAACGCATCGCTTAAAAATTGGACAATCCAAAATGCTAAATTCATCTTCCTCAACACCCCCCTCTATCAAAGCACAGCACAGGATCGCTAA |
| Protein Sequence | MPRNPSSFRITARNIFLTYPQCDINKDEALRLLQELPWSVVKPTYIRVAREEHSDGFPHLHCLIQLSGKSNIKDVRFFDLTHPRRSANFHPNVQAAKDTNAVKNYITKEGDYCESGEYKVSGSTKSNKDDVYHNAVNAGSIKEALDIIRAGDPKTFIVNYHNIKANIERLFKKAPEPWVPPFQLSSFTFVPDEMQEWADDYFGRGAAARAERPISIIVEGGSRTGKTMWARALGPHNYLSGHLDFNSSVYSNEVEYNVIDDISPQYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENASLKNWTIQNAKFIFLNTPLYQSTAQDR |
| NCBI Accession | NP_612598.1 |
|---|---|
| Location | 2051-2380 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGAAGCTCTTCGCTTGCTTCAAGAACTGCCATGGTCAGTCGTCAAACCAACATATATCCGAGTCGCCCGAGAGGAACATTCAGATGGATTCCCTCATCTACACTGTCTCATTCAACTCTCAGGCAAGTCCAACATCAAGGATGTTAGATTTTTCGACCTTACTCACCCAAGAAGGTCTGCCAATTTTCACCCAAACGTTCAGGCAGCCAAGGACACCAACGCAGTCAAGAACTACATCACCAAAGAAGGTGATTATTGTGAATCCGGGGAATATAAGGTGTCTGGCTCAACAAAATCAAACAAGGACGACGTATACCACAACGCAGTAA |
| Protein Sequence | MKLFACFKNCHGQSSNQHISESPERNIQMDSLIYTVSFNSQASPTSRMLDFSTLLTQEGLPIFTQTFRQPRTPTQSRTTSPKKVIIVNPGNIRCLAQQNQTRTTYTTTQ |
| NCBI Accession | NP_612599.1 |
|---|---|
| Location | 462-1238 |
| Gene Name | BV1 |
| Protein Name | BV1 |
| Coding Region | ATGTACATGTATCATAATAGGAATAGACGTGGATGGTCATATACCCCACGACGAGGTTATGCACGAAATGGCTTGTATAAGCGTCCCTGTACTTACAAGCGTGTAGATGATAAACGACGCCCGAGTAGTTCAAATAAGGTGTATGATGATACAAAGATGTCACTCCAGCGTATTCATGAGGATCAGTTTGGACCAGAATTTGTTTTGCGTCATAATACAGCATTGTCTACATTTATTACTTATCCTAGTCTTGTTAAGAATGAACCTAACCGTTCTAGATCATATATCAAGTTAAAGCGACTTCGTTTTAAAGGAACTCTGAAGATTGAACGGGTTCACGCTGACGTTAACATGGACGCTCCAAACTCAAAGATTGAAGGAGTTTTTTCTATGGTTGTAGTTGTTGATCGTAAGCCACATTTGAATCCAACTGGATGTCTGCATACATTTGATGAGATGTTTGGAGCCAGGATACATAGCCACGGAAATTTAGCTATCACACCCACATTGAAAGAACGTTTTTATATTCGACATGTTATGAAGCGTGTGTTATCGGTGGAGAAAGATAGTCTAATGGTTGATTTTGAAGGAGTGACGATTTTATCTAATAGACGTTTTACGTGTTGGTCTTCATTTAATGACCACGAAAGAGATTCATGTAACGGGGTATATTCCAACATAAACAGGAATGCTCTATTAGTTTATTACTGTTGGATGTCGGACGACATGTCCAAGGCGTCAACATTTGTATCATTTGATCTCGACTATATTGGATAA |
| Protein Sequence | MYMYHNRNRRGWSYTPRRGYARNGLYKRPCTYKRVDDKRRPSSSNKVYDDTKMSLQRIHEDQFGPEFVLRHNTALSTFITYPSLVKNEPNRSRSYIKLKRLRFKGTLKIERVHADVNMDAPNSKIEGVFSMVVVVDRKPHLNPTGCLHTFDEMFGARIHSHGNLAITPTLKERFYIRHVMKRVLSVEKDSLMVDFEGVTILSNRRFTCWSSFNDHERDSCNGVYSNINRNALLVYYCWMSDDMSKASTFVSFDLDYIG |
| NCBI Accession | NP_612600.1 |
|---|---|
| Location | 1320-2198 |
| Gene Name | BC1 |
| Protein Name | BC1 |
| Coding Region | ATGGAGTCTAAATTAGTCATACCACCAAACGCATTTAACTATATCGAGTCTCACCGGGACGAATATCAGCTTTCTCATGACCTGACGGAGATAATCCTTCAATTTCCGTCGACGGCGTCTCAATTGGGTGCAAGACTGACGCGAAGTTGTATGAAGATAGACCATTGTGTAATAGAGTACAGGCAACAGGTACCCATAAACGCGTCAGGAACTGTGATAGTGGAGATTCATGATAAAAGAATGCAAGACAACGAATCATTGCAAGCGTCATGGACTTTTCCGATAAGATGTAATATAGATCTCCACTACTTCTCGTCTTCATTCTTCTCCCTCAAAGACCCAATACCTTGGAAATTGTATTACAAAGTGACAGACTCAAATGTCCATCAGCGAACCCATTTCGCTAAATTTAAAGGTAAATTGAAGTTGTCGACGGCGAAACATTCCGTTGATATCCCTTTCCGGGCACCAACTGTGAAGATATTGTCCAAACAATTTACCGATAAGGATATTGATTTTTGTCACGTGGGGTATGGGAAATGGGAGAGGAGAATGGTCAAATCCGCATCGTCAAGATATGGGCTTAACGGCCCAATAGAAATAGGACCAGGAGAATCATGGGCTGCCAGAAGTGTCATTGATATAGTCCGTTCAAATGCGGATTCGAATTTAGATGAGGAAATTCACCCGTATAAAGAATTAAATAGACTGGGTACAACAATACTGGACCCGGGTGAATCTGCTTCAATAGTAGGAATACAACGCTCACAATCAAACATTACGATGTCAATGGCCCAATTAAACGACATCGTTAGATCTACAGTACAAGAGTGTATCAACACAAATTGTATTCCTACACACCCCAAATCGTTAAAATAG |
| Protein Sequence | MESKLVIPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLGARLTRSCMKIDHCVIEYRQQVPINASGTVIVEIHDKRMQDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVTDSNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDIDFCHVGYGKWERRMVKSASSRYGLNGPIEIGPGESWAARSVIDIVRSNADSNLDEEIHPYKELNRLGTTILDPGESASIVGIQRSQSNITMSMAQLNDIVRSTVQECINTNCIPTHPKSLK |
References More References in PubMed
| 1 |
Idris AM, et al. J Virol. 2008 Feb;82(4):1959-67. doi: 10.1128/JVI.01992-07. Epub 2007 Dec 5. PMID: 18057231 |
|---|---|
| 2 |
Brown JK, et al. Phytopathology. 1999 Apr;89(4):273-80. doi: 10.1094/PHYTO.1999.89.4.273. PMID: 18944770 |
| 3 |
Diaz M, et al. Plant Dis. 2002 Feb;86(2):188. doi: 10.1094/PDIS.2002.86.2.188B. PMID: 30823326 |
| 4 |
Parrella G, et al. Plant Dis. 2010 Jul;94(7):924. doi: 10.1094/PDIS-94-7-0924A. PMID: 30743579 |
| 5 |
Jones RAC, et al. Plant Dis. 2012 Sep;96(9):1384. doi: 10.1094/PDIS-04-12-0378-PDN. PMID: 30727195 |
| 6 |
Guzman P, et al. Plant Dis. 2000 Apr;84(4):488. doi: 10.1094/PDIS.2000.84.4.488C. PMID: 30841181 |
| 7 |
Cucurbit leaf curl virus, a New Whitefly Transmitted Geminivirus in Arizona, Texas, and Mexico. Brown JK, et al. Plant Dis. 2000 Jul;84(7):809. doi: 10.1094/PDIS.2000.84.7.809A. PMID: 30832123 |
| 8 |
Brown JK, et al. Plant Dis. 2001 Sep;85(9):1027. doi: 10.1094/PDIS.2001.85.9.1027C. PMID: 30823088 |
| 9 |
Potter JL, et al. Plant Dis. 2003 Oct;87(10):1205-1212. doi: 10.1094/PDIS.2003.87.10.1205. PMID: 30812724 |
| 10 |
Brown JK, et al. Phytopathology. 2002 Jul;92(7):734-42. doi: 10.1094/PHYTO.2002.92.7.734. PMID: 18943269 |