Pouzolzia golden mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000918895.1 |
| Isolate |
China |
| Release date |
2015/2/22 |
| Submitter |
Tang,Y.F., Du,Z.G., He,Z.F., She,X.M., Cai,J.H. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
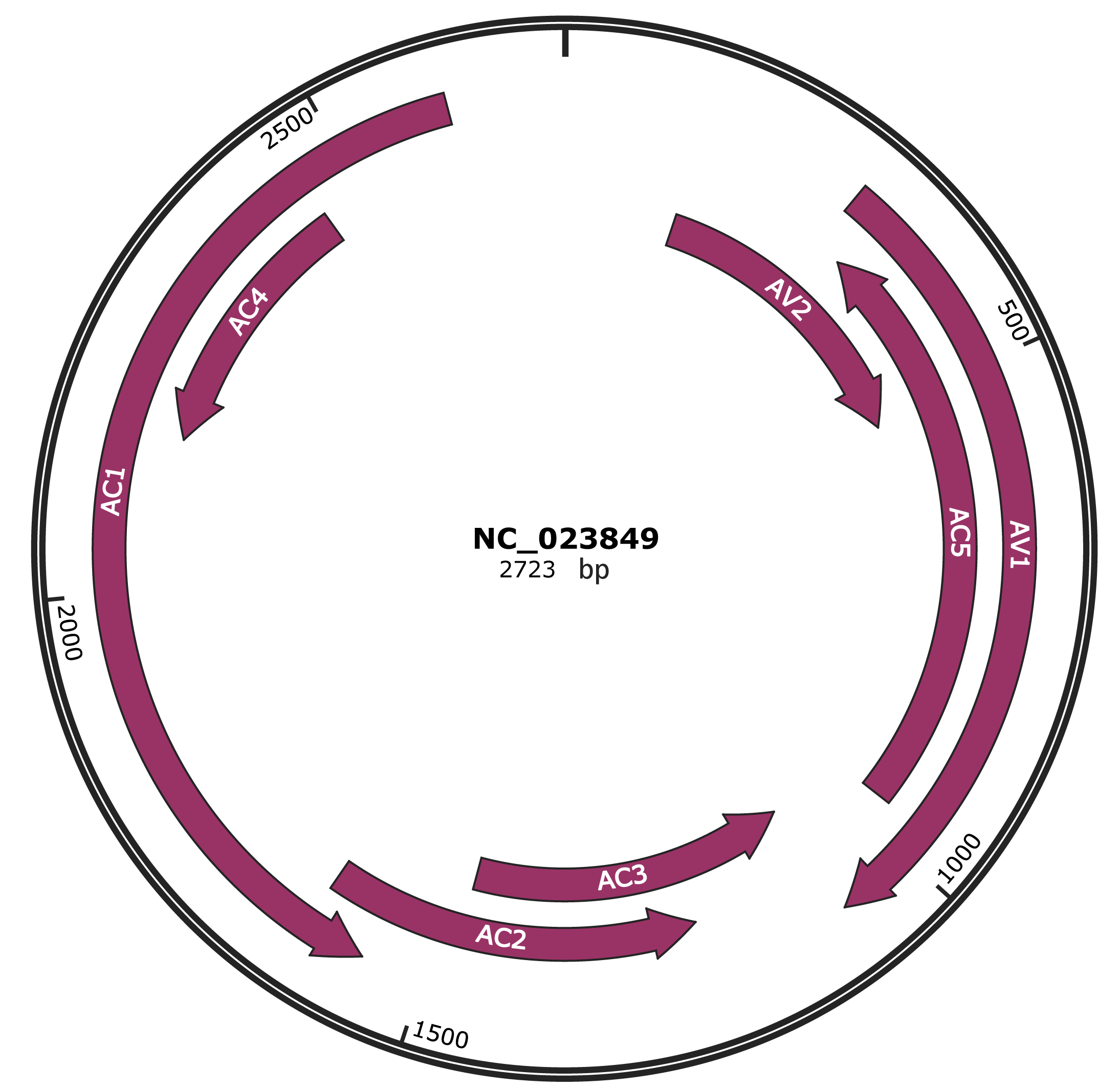
JBrowse
Genome
ACCTGATGGCCGCGCTTTTGGGGTCCCCCTTTTTGTGGTCCCCTCCACTAATTTCTGTCGGCCAATAGAAACGCGTGCTCAAAGTCTAATTATTGGTGCGCATATCTATAAAGAACTTGTCCACCAAGTTCGAATTAAAAATGTGGGATCCTTTGGTTAACGAGTTTCCCGAGACCGTGCACGGTCTTCGGTGTATGCTAGCTATAAAATATCTGCTTTTAATTGAAAATACATACGCGCCAGATACCCTAGGGTACGATCTAATTCGTGACCTCATTCTCGTCATCCGTGCCAGAAATTATGACGAAGCGTCCCGCCGATATAGTCATTTCAACTCCCGCCTCGAAAGTACGACGCCGGCTGAGCTACGACACTCCCGGAGTCAGCCGTGCCTCTGTCCCCACTGTCCTCGTCACAAATCGAAAGAAAGCATGGACGTACAGGCCCAGTTATCGAAAGCCCAAAATGTACAGAATGTACAAGAGCCCAGATGTCCCACGCGGATGCGAGGGCCCATGTAAGGTCCAGTCTTACGAACAGCGACATGACATAGCCCACACTGGGAAGGTCATATGCATCTCTGACGTTACACGTGGCGGTGGTCTTACCCACCGCACAGGGAAGAGGTTCTGTGTTAAGTCCGTGTACATAATCGGGAAGGTGTGGATGGATGAAAATATCAAGACCAAGAATCACACCAACACTGTTATGTTCTATCTCGTCAGAGATAGACGACCTTTTGGTACTGCCATGGACTTTGGTCAAGTGTTCAACATGTACGACAATGAACCTAGTACTGCTACGGTGAAGAACGATCTTCGTGATCGTTATCAGGTTATGCGTCGTTTTTCTGCATCGGTGACCGGTGGTCAATATGCGTGCAAGGAACAGGCGATAGTTAGGAAGTTTTTTACCGTTAATAATCATGTAGTTTATAATCATCAAGAAGCGGGAAAGTATGATAACCATACTGAAAACGCTATGTTATTGTATATGGCATGTACTCATGCTAGCAATCCTGTGTATGCAACATTGAAAATTAGAATCTATTTCTATGATTCGCTTCAGAATTAATAAACATTGAATTTTATTATAGTCGAAAGTTGTACATCAATAGTCTTGTCCAATACATTATTCATTACATGATTAACCGCCCTAATTACATTGTTAATACTAACAATCCCTAAATTGTTCAAATGTTTCATACATTGAACCCTAAATACTCTTAAGAAACGCCCAGTCTGAGGTTGTAAATGAGTCCAGATCTGGAAGATCAGAAAACACTGGTGAAGTCCCAACGCTTTCCTCAGGTTGTGGTTGAATTGGATTTGGATCGTGATAATGTCGTGGTTCGTCAGTGATGGTCGTTGCTCGTGATTGATGATCCTGAAATAGAGGGGATTTGGCACCGTCCAGATATACGCGCCATTCTCTGCTTGAGTTGCAGTGATGAGTGCCCCGGTGCGTGAATCCATGATTCGCACAATCTATGGAGTAGTAGTATGAACAGCCACAAGGGAGATCTACTCTCCTTCTCCTGATGGTTTTCTTTTTACAAAGTCTATGCTTGACTTTGATTGGAATCTGAGTAGAGTGGCCCGCTGATGGTGACGAAGAGCGCATTTTTTAATGCCCAATCTTTTAGTGCTGCATTCTTTTCCTCGTTAAGATATTCTTTATATGAGGATGTCGGGCCTGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAATGGGTTTCCCATATTTCGTGTTGCTTTGCCAGTCTCTCTGGGCCCCCATAAATTCCTTGAAGTGCTTTAGATAGTGGGGATCAACGTCATCAATGACGTTATACCAAGCATTATTGCTATATACTCTTGGGCTGAGATCGAGATGCCCACATAAATAATTATGTGGCCCTAATGACCTAGCCCACATTGTTTTACCTGTTCGACTATGCCCTTCAATTACAATTGATTTAGGTCTAATAGGCCGCGCAGCGGGACTCATTACATTTTCGGAAACCCAACACTCAATTTCATCTGGGACTAGATCAAACGACGAAGATAGAAAAGGATTTTTAAAAACCTCGGAACGAGTAGGAAAAATTCTATCTAAATTACTATTTAGATTATGAAACTGTAAAATATAATCTTTGGGCTCTAATTCCTTAATTACATTAAGAGCCTCTGACTTACTGCCAGAGTTAAGCGCCTTGGCGTAAGCATCATTGGCTGATTGTTTTCCCCCTCGTGCAGATCGTCCGTCGATCTGAAACTCTCCCCATTCGACGGTGTCTCCGTCCTTCTCCATATATGACTTGACATCGGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCTAGTTGGGGAGACCAAATCGAAGAATCGCTGATTCTTGCACTGGAATTTCCCTTCGAATTGAATGAGAACGTGGAGATGAGGAGACCCATCTTCGTGAAGCTCTCTGCAAATTTTAATATATTTTTTATTAGTAGGGGTAATTAGGTTTCGTATTTGGGAAAGTGCCTCCTCTTTCGAGAGAGAACACTGAGGATATGTAAGGAAGTAGTTTTTGGCACTGAGTTTAAACTTAGAAGGAGGAGCCATTGACTTGGTCAATCGGTGTCCAGCAAACTATCGTATATAATTGGGGTATGGGGTCTTATTTATAGTAAGGGGGGTTTTACATATAGTTACTTGCGGCCATCAGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009021220.1
|
|
Location
|
141-521 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCTTTGGTTAACGAGTTTCCCGAGACCGTGCACGGTCTTCGGTGTATGCTAGCTATAAAATATCTGCTTTTAATTGAAAATACATACGCGCCAGATACCCTAGGGTACGATCTAATTCGTGACCTCATTCTCGTCATCCGTGCCAGAAATTATGACGAAGCGTCCCGCCGATATAGTCATTTCAACTCCCGCCTCGAAAGTACGACGCCGGCTGAGCTACGACACTCCCGGAGTCAGCCGTGCCTCTGTCCCCACTGTCCTCGTCACAAATCGAAAGAAAGCATGGACGTACAGGCCCAGTTATCGAAAGCCCAAAATGTACAGAATGTACAAGAGCCCAGATGTCCCACGCGGATGCGAGGGCCCATGTAA |
|
Protein Sequence
|
MWDPLVNEFPETVHGLRCMLAIKYLLLIENTYAPDTLGYDLIRDLILVIRARNYDEASRRYSHFNSRLESTTPAELRHSRSQPCLCPHCPRHKSKESMDVQAQLSKAQNVQNVQEPRCPTRMRGPM |
|
NCBI Accession
|
YP_009021221.1
|
|
Location
|
301-1074 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGACGAAGCGTCCCGCCGATATAGTCATTTCAACTCCCGCCTCGAAAGTACGACGCCGGCTGAGCTACGACACTCCCGGAGTCAGCCGTGCCTCTGTCCCCACTGTCCTCGTCACAAATCGAAAGAAAGCATGGACGTACAGGCCCAGTTATCGAAAGCCCAAAATGTACAGAATGTACAAGAGCCCAGATGTCCCACGCGGATGCGAGGGCCCATGTAAGGTCCAGTCTTACGAACAGCGACATGACATAGCCCACACTGGGAAGGTCATATGCATCTCTGACGTTACACGTGGCGGTGGTCTTACCCACCGCACAGGGAAGAGGTTCTGTGTTAAGTCCGTGTACATAATCGGGAAGGTGTGGATGGATGAAAATATCAAGACCAAGAATCACACCAACACTGTTATGTTCTATCTCGTCAGAGATAGACGACCTTTTGGTACTGCCATGGACTTTGGTCAAGTGTTCAACATGTACGACAATGAACCTAGTACTGCTACGGTGAAGAACGATCTTCGTGATCGTTATCAGGTTATGCGTCGTTTTTCTGCATCGGTGACCGGTGGTCAATATGCGTGCAAGGAACAGGCGATAGTTAGGAAGTTTTTTACCGTTAATAATCATGTAGTTTATAATCATCAAGAAGCGGGAAAGTATGATAACCATACTGAAAACGCTATGTTATTGTATATGGCATGTACTCATGCTAGCAATCCTGTGTATGCAACATTGAAAATTAGAATCTATTTCTATGATTCGCTTCAGAATTAA |
|
Protein Sequence
|
MTKRPADIVISTPASKVRRRLSYDTPGVSRASVPTVLVTNRKKAWTYRPSYRKPKMYRMYKSPDVPRGCEGPCKVQSYEQRHDIAHTGKVICISDVTRGGGLTHRTGKRFCVKSVYIIGKVWMDENIKTKNHTNTVMFYLVRDRRPFGTAMDFGQVFNMYDNEPSTATVKNDLRDRYQVMRRFSASVTGGQYACKEQAIVRKFFTVNNHVVYNHQEAGKYDNHTENAMLLYMACTHASNPVYATLKIRIYFYDSLQN |
|
NCBI Accession
|
YP_009021222.1
|
|
Location
|
331-969 |
|
Gene Name
|
AC5 |
|
Protein Name
|
AC5 protein |
|
Coding Region
|
ATGGTTATCATACTTTCCCGCTTCTTGATGATTATAAACTACATGATTATTAACGGTAAAAAACTTCCTAACTATCGCCTGTTCCTTGCACGCATATTGACCACCGGTCACCGATGCAGAAAAACGACGCATAACCTGATAACGATCACGAAGATCGTTCTTCACCGTAGCAGTACTAGGTTCATTGTCGTACATGTTGAACACTTGACCAAAGTCCATGGCAGTACCAAAAGGTCGTCTATCTCTGACGAGATAGAACATAACAGTGTTGGTGTGATTCTTGGTCTTGATATTTTCATCCATCCACACCTTCCCGATTATGTACACGGACTTAACACAGAACCTCTTCCCTGTGCGGTGGGTAAGACCACCGCCACGTGTAACGTCAGAGATGCATATGACCTTCCCAGTGTGGGCTATGTCATGTCGCTGTTCGTAAGACTGGACCTTACATGGGCCCTCGCATCCGCGTGGGACATCTGGGCTCTTGTACATTCTGTACATTTTGGGCTTTCGATAACTGGGCCTGTACGTCCATGCTTTCTTTCGATTTGTGACGAGGACAGTGGGGACAGAGGCACGGCTGACTCCGGGAGTGTCGTAGCTCAGCCGGCGTCGTACTTTCGAGGCGGGAGTTGA |
|
Protein Sequence
|
MVIILSRFLMIINYMIINGKKLPNYRLFLARILTTGHRCRKTTHNLITITKIVLHRSSTRFIVVHVEHLTKVHGSTKRSSISDEIEHNSVGVILGLDIFIHPHLPDYVHGLNTEPLPCAVGKTTATCNVRDAYDLPSVGYVMSLFVRLDLTWALASAWDIWALVHSVHFGLSITGPVRPCFLSICDEDSGDRGTADSGSVVAQPASYFRGGS |
|
NCBI Accession
|
YP_009021223.1
|
|
Location
|
1071-1475 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGCACTCATCACTGCAACTCAAGCAGAGAATGGCGCGTATATCTGGACGGTGCCAAATCCCCTCTATTTCAGGATCATCAATCACGAGCAACGACCATCACTGACGAACCACGACATTATCACGATCCAAATCCAATTCAACCACAACCTGAGGAAAGCGTTGGGACTTCACCAGTGTTTTCTGATCTTCCAGATCTGGACTCATTTACAACCTCAGACTGGGCGTTTCTTAAGAGTATTTAGGGTTCAATGTATGAAACATTTGAACAATTTAGGGATTGTTAGTATTAACAATGTAATTAGGGCGGTTAATCATGTAATGAATAATGTATTGGACAAGACTATTGATGTACAACTTTCGACTATAATAAAATTCAATGTTTATTAA |
|
Protein Sequence
|
MDSRTGALITATQAENGAYIWTVPNPLYFRIINHEQRPSLTNHDIITIQIQFNHNLRKALGLHQCFLIFQIWTHLQPQTGRFLRVFRVQCMKHLNNLGIVSINNVIRAVNHVMNNVLDKTIDVQLSTIIKFNVY |
|
NCBI Accession
|
YP_009021224.1
|
|
Location
|
1216-1623 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCGCTCTTCGTCACCATCAGCGGGCCACTCTACTCAGATTCCAATCAAAGTCAAGCATAGACTTTGTAAAAAGAAAACCATCAGGAGAAGGAGAGTAGATCTCCCTTGTGGCTGTTCATACTACTACTCCATAGATTGTGCGAATCATGGATTCACGCACCGGGGCACTCATCACTGCAACTCAAGCAGAGAATGGCGCGTATATCTGGACGGTGCCAAATCCCCTCTATTTCAGGATCATCAATCACGAGCAACGACCATCACTGACGAACCACGACATTATCACGATCCAAATCCAATTCAACCACAACCTGAGGAAAGCGTTGGGACTTCACCAGTGTTTTCTGATCTTCCAGATCTGGACTCATTTACAACCTCAGACTGGGCGTTTCTTAAGAGTATTTAG |
|
Protein Sequence
|
MRSSSPSAGHSTQIPIKVKHRLCKKKTIRRRRVDLPCGCSYYYSIDCANHGFTHRGTHHCNSSREWRVYLDGAKSPLFQDHQSRATTITDEPRHYHDPNPIQPQPEESVGTSPVFSDLPDLDSFTTSDWAFLKSI |
|
NCBI Accession
|
YP_009021225.1
|
|
Location
|
1562-2611 |
|
Gene Name
|
AC1 |
|
Protein Name
|
Rep protein |
|
Coding Region
|
ATGGCTCCTCCTTCTAAGTTTAAACTCAGTGCCAAAAACTACTTCCTTACATATCCTCAGTGTTCTCTCTCGAAAGAGGAGGCACTTTCCCAAATACGAAACCTAATTACCCCTACTAATAAAAAATATATTAAAATTTGCAGAGAGCTTCACGAAGATGGGTCTCCTCATCTCCACGTTCTCATTCAATTCGAAGGGAAATTCCAGTGCAAGAATCAGCGATTCTTCGATTTGGTCTCCCCAACTAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAGTCATATATGGAGAAGGACGGAGACACCGTCGAATGGGGAGAGTTTCAGATCGACGGACGATCTGCACGAGGGGGAAAACAATCAGCCAATGATGCTTACGCCAAGGCGCTTAACTCTGGCAGTAAGTCAGAGGCTCTTAATGTAATTAAGGAATTAGAGCCCAAAGATTATATTTTACAGTTTCATAATCTAAATAGTAATTTAGATAGAATTTTTCCTACTCGTTCCGAGGTTTTTAAAAATCCTTTTCTATCTTCGTCGTTTGATCTAGTCCCAGATGAAATTGAGTGTTGGGTTTCCGAAAATGTAATGAGTCCCGCTGCGCGGCCTATTAGACCTAAATCAATTGTAATTGAAGGGCATAGTCGAACAGGTAAAACAATGTGGGCTAGGTCATTAGGGCCACATAATTATTTATGTGGGCATCTCGATCTCAGCCCAAGAGTATATAGCAATAATGCTTGGTATAACGTCATTGATGACGTTGATCCCCACTATCTAAAGCACTTCAAGGAATTTATGGGGGCCCAGAGAGACTGGCAAAGCAACACGAAATATGGGAAACCCATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCAGGCCCGACATCCTCATATAAAGAATATCTTAACGAGGAAAAGAATGCAGCACTAAAAGATTGGGCATTAAAAAATGCGCTCTTCGTCACCATCAGCGGGCCACTCTACTCAGATTCCAATCAAAGTCAAGCATAG |
|
Protein Sequence
|
MAPPSKFKLSAKNYFLTYPQCSLSKEEALSQIRNLITPTNKKYIKICRELHEDGSPHLHVLIQFEGKFQCKNQRFFDLVSPTRSTHFHPNIQGAKSSSDVKSYMEKDGDTVEWGEFQIDGRSARGGKQSANDAYAKALNSGSKSEALNVIKELEPKDYILQFHNLNSNLDRIFPTRSEVFKNPFLSSSFDLVPDEIECWVSENVMSPAARPIRPKSIVIEGHSRTGKTMWARSLGPHNYLCGHLDLSPRVYSNNAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLNEEKNAALKDWALKNALFVTISGPLYSDSNQSQA |
|
NCBI Accession
|
YP_009021226.1
|
|
Location
|
2164-2454 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGTCTCCTCATCTCCACGTTCTCATTCAATTCGAAGGGAAATTCCAGTGCAAGAATCAGCGATTCTTCGATTTGGTCTCCCCAACTAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAGTCATATATGGAGAAGGACGGAGACACCGTCGAATGGGGAGAGTTTCAGATCGACGGACGATCTGCACGAGGGGGAAAACAATCAGCCAATGATGCTTACGCCAAGGCGCTTAACTCTGGCAGTAAGTCAGAGGCTCTTAATGTAA |
|
Protein Sequence
|
MGLLISTFSFNSKGNSSARISDSSIWSPQLGQHISIRTFRELNQAPMSSHIWRRTETPSNGESFRSTDDLHEGENNQPMMLTPRRLTLAVSQRLLM |