Potato yellow mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000838665.1 |
| Release date | 2015/2/12 |
| Submitter | Fontes,E.P., Eagle,P.A., Sipe,P.S., Luckow,V.A., Hanley-Bowdoin,L., Coutts,R.H., Coffin,R.S., Roberts,E.J., Hamilton,W.D., Gladfelter,H.J., Schaffer,R.L., Petty,I.T. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
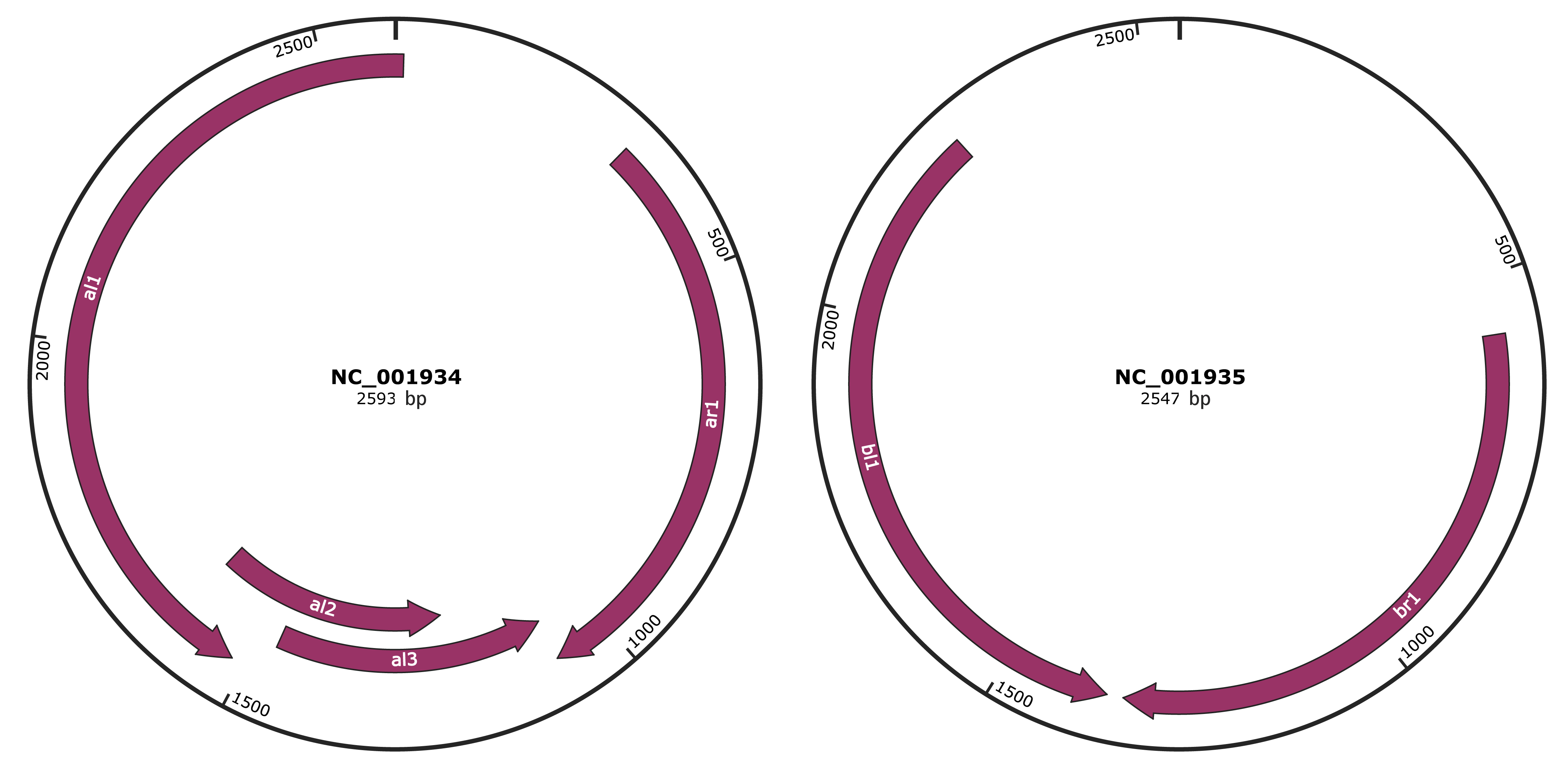
JBrowse
Genome
NC_001934
NC_001935
Gene Information
| NCBI Accession | NP_047237.1 |
|---|---|
| Location | 1519-2593,1-11 |
| Gene Name | al1 |
| Protein Name | AL1 protein |
| Coding Region | ATGCCACGAAAGGGTTCGTTCTCTATTAAAGCCAAAAATTATTTCCTTACGTATCCTCAATGCTCTATTAGCAAAGAAGAAGCACTTTCCCAACTTCAAAACCTAACTATCCCAGTCAACAAGAAATTCATCAAGATTTGCAGAGAACTTCACGAGAATGGGGAACCTCATCTCCACGTTCTTATCCAGTTCGAAGGCAAATACAACTGCACAAATAACAGACTGTTCGATCTGGTGTCCCCAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCGAGCTCCGATGTCAAGTCGTATGTCGAGAAAGACGGAGACACCATCGAATGGGGTTTGTTCCAGATTGACGGAAGAAGTGCTCGAGGGGGCCAGCAGACAGTTAACGACGCAGCTGCCGAGGCACTAAACTCTGGAACAAAGGAAGCAGCCATGAAAATCATTAAAGAGAAGTTGCCGGAAAAGTTTCTTTTTCAGTATCATAACCTATCCTGTAACCTCGATAGGATTTTCATGAAGGCTCCAGAGACATGGGCTCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCCGACGAGATGCAAGAGTGGGCAGATGGTTATTTCGGAAAGAGTAGTGCGGCGCGCCCAGAAAGACCTATTAGTATTATAATTGAAGGTGATTCTCGAAGAGGCAAGACGATGTGGGCGCGAGTCTTAGGCCCACATAATTACTTGAGCGGTCATCTTGATTTCAATCCCAGGGTCTATTCGAATGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAACTGCTTGGGGCCCAAAGGGATTGGCAATCAAATTGTAAGTACGGAAAGCCTGTTCAAATTAAAGGCGGTATCCCATCAATCGTGCTCTGCAATCCTGGTGAGGGTTCCAGCTATAAAGCTTTCCTCGACAAAGACGAAAATGCGTCTCTCAAAAACTGGACTCTAAAGAATGCGGTCTTCATCACCATCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCAAAGAAGAGGGCAATCAGGAGGAGACGCATTGA |
| Protein Sequence | MPRKGSFSIKAKNYFLTYPQCSISKEEALSQLQNLTIPVNKKFIKICRELHENGEPHLHVLIQFEGKYNCTNNRLFDLVSPTRSTHFHPNIQGAKSSSDVKSYVEKDGDTIEWGLFQIDGRSARGGQQTVNDAAAEALNSGTKEAAMKIIKEKLPEKFLFQYHNLSCNLDRIFMKAPETWAPPFPLSSFTNVPDEMQEWADGYFGKSSAARPERPISIIIEGDSRRGKTMWARVLGPHNYLSGHLDFNPRVYSNEVEYNVIDDVAPQYLKLKHWKELLGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKAFLDKDENASLKNWTLKNAVFITITAPLYQEGTQASKEEGNQEETH |
| NCBI Accession | NP_047238.1 |
|---|---|
| Location | 321-1076 |
| Gene Name | ar1 |
| Protein Name | AR1 protein |
| Coding Region | ATGCCTAAGCGCGATGCCCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTACTCTCCTCGTTCAGGAATTGGGCCAAGAATAAACAAGGCCGCTGAATGGGTTAATAGGCCCATGTACCGGAAGCCCAGGATCTATCGGACGCTGAGGACGCCTGATGTTCCTAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCTTTCGAGCAGCGACACGATATCTTACACACTGGCAAGGTAATGTGCATATCTGACGTTACTCGCGGTAACGGTATTACTCACCGTGTCGGGAAGCGGTTCTGTGTTAAGTCCGTTTACATATTAGGTAAGATATGGATGGACGAGAATATCAAGCTGAAGAACCACACCAACAGCGTCATGTTCTGGCTGGTCAGAGACCGAAGACCGTATGGAACGCCTATGGATTTCGGACAAGTGTTCAACATGTTCGACAATGAGCCTAGCACCGCCACTGTTAAGAACGATCTTCGTGATCGTTATCAGGTCATGCATAGGTTCTATGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCATGCTATTGTGAGGCGTTTCTGGAAGGTCAACAACCACGTTGTTTACAACCACCAGGAAGCTGGCAAATACGAGAATCATACTGAGAACGCCCTATTATTGTACATGGCATGTACTCATGCCTCAAATCCTGTATATGCAACACTTAAGATTCGGATCTATTTTTATGATTCGATCTTAAATTAA |
| Protein Sequence | MPKRDAPWRSMAGTSKVSRNANYSPRSGIGPRINKAAEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSFEQRHDILHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYGKVTGGQYASNEHAIVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
| NCBI Accession | NP_047239.1 |
|---|---|
| Location | 1073-1471 |
| Gene Name | al3 |
| Protein Name | AL3 protein |
| Coding Region | ATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATAAACCAAGTAGAGGACATGCAATACACCAGGACCAGGATATACAGCGTCCAAATCCGGTTCAACCACAACCTCAGGAGAGCATTGGATCTCCACAAAGCATACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGAATTATTTAGCTAGATTTAGACAATTAGTTCTTCTGTACTTAGACCGGTTAGGTGTCATTTCAATTAACAATGTAATTAGATCTGTTCGTTTTGCAACAGATAGATCATATGTAAATTATGTACTGGAAAATCATTCAATAAAATATAAATTTTATTAA |
| Protein Sequence | MDSRTGELITARQAENGVFIWEIENPLYFKINQVEDMQYTRTRIYSVQIRFNHNLRRALDLHKAYLNFQVWTTSMTASGSNYLARFRQLVLLYLDRLGVISINNVIRSVRFATDRSYVNYVLENHSIKYKFY |
| NCBI Accession | NP_047240.1 |
|---|---|
| Location | 1218-1607 |
| Gene Name | al2 |
| Protein Name | AL2 protein |
| Coding Region | ATGCGGTCTTCATCACCATCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCAAAGAAGAGGGCAATCAGGAGGAGACGCATTGACTTAGACTGCGGTTGCTCCATATACTTCCACATAGACTGCGCAGGACATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATAAACCAAGTAGAGGACATGCAATACACCAGGACCAGGATATACAGCGTCCAAATCCGGTTCAACCACAACCTCAGGAGAGCATTGGATCTCCACAAAGCATACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGAATTATTTAGCTAG |
| Protein Sequence | MRSSSPSQPPSIKKAHRQAKKRAIRRRRIDLDCGCSIYFHIDCAGHGFTHRGAHHCTSGREWRVYLGDRKSPLFQDKPSRGHAIHQDQDIQRPNPVQPQPQESIGSPQSIPELPSLDDIDDSFWVELFS |
| NCBI Accession | NP_047241.1 |
|---|---|
| Location | 575-1345 |
| Gene Name | br1 |
| Protein Name | BR1 protein |
| Coding Region | ATGTATCCTAATAGGCACAGGCGTGCTTCTTTTTGTAGCCAGCCACGTACTTACCCACGTAATAGTTTGATTAGACAGCAGTCATTATTCAAGCGTAATGTTAGCAAACGACGACCATTTCAAACCGTGAAGATGGTTGATGACTCCATGATGAAGGCACAACGTATTCATGAGAATCAATACGGTCCAGATTTTTCACTGGCCCATAATACAGCCGTCTCTACATTTATAAGTTACCCTGATATTGCTAAGTCTCTGCCCAATAGAACCAGGTCATATATTAAGCTAAAACGACTTCGGTTCAAGGGTATTGTGAAGGTGGAACGTGTACATGTAGAGGTTAACATGGACTGTTCTGTGCCTAAGACCGAAGGAGTTTTCTCTTTGGTTATTGTAGTGGATCGTAAACCTCACCTTGGACCCTCTGGGGGACTGCCTACATTTGACGAGCTATTTGGCGCTAGGATCCACAGTCATGGTAACTTGGCAATAGTTCCATCTCTGAAGGATCGGTTCTACATACGCCATGTACTGAAGCGTGTGATATCAGTCGAGAAGGACACCATGATGGTGGACATAGAAGGTGTTGTAGCCCTTTCTAGCAGACGTTTTAATTGTTGGGCTGGTTTTAAGGACCTTGACATAGAGTCCCGAAAGGGTGTTTATGATAACATTAATAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCGGATACAGTATCCAAAGCATCCACATTTGTATCGTTTGATCTTGATTATATTGGATGA |
| Protein Sequence | MYPNRHRRASFCSQPRTYPRNSLIRQQSLFKRNVSKRRPFQTVKMVDDSMMKAQRIHENQYGPDFSLAHNTAVSTFISYPDIAKSLPNRTRSYIKLKRLRFKGIVKVERVHVEVNMDCSVPKTEGVFSLVIVVDRKPHLGPSGGLPTFDELFGARIHSHGNLAIVPSLKDRFYIRHVLKRVISVEKDTMMVDIEGVVALSSRRFNCWAGFKDLDIESRKGVYDNINKNALLVYYCWMSDTVSKASTFVSFDLDYIG |
| NCBI Accession | NP_047242.1 |
|---|---|
| Location | 1367-2248 |
| Gene Name | bl1 |
| Protein Name | BL1 protein |
| Coding Region | ATGAATTCTCAGTTAGTTAATCCTCCTCATGCTTTCAATTACATAGAGTCTCAACGGGATGAATATCAGCTTTCGCATGACCTAACTGAGATAATACTGCAATTTCCGTCGACGGCGGCGCAGTTAACGGCGAGGCTCAGTCGCAGCTGTATGAAGATAGACCACTGCGTAATTGAGTACAGGCAACAGGTACCCATCAACGCCACCGGGTCTGTAATAGTGGAGATTCATGATAAGAGGATGACAGACAACGAATCTCTGCAGGCGTCATGGACGTTCCCGTTAAGATGCAACATAGATCTCCACTATTTCTCAGCTTCCTTTTTCTCCCTAAAAGATCCTATCCCATGGAAACTCTATTACAGAGTTTCCGACACGAACGTTCATCAACGGACACACTTTGCCAAGTTCAAAGGGAAGCTGAAACTGTCGACGGCGAAACATTCCGTAGACATTCCGTTCAGAGCACCAACGGTCAAGATCCTGTCCAAACAGTTCACAGATAAGGACGTGGATTTCTCGCACGTCGACTACGGGAGATGGGAGAGGAAGCCCATTAGATGCGCATCAATGTCCAGAGTTGGGCTCAGAGGCCCAATTGAAATAAGGCCTGGTGAATCATGGGCTTCCAGGAGTACAATAGGAGTGGGTCAATCAGAGGGCGAGTCAGAGATAGAGAACGAGCTACATACGTATCGAGATTTGCAAAGACTAGGAGCCAGCGTCCTAGATCCAGGAGAGTCAGCATCTATAGTTGGTGCTAACATGGCCCAATCGAACATAACCATGTCCGTAGCCCAGTTAAATGAACTTGTAAGGACAACTGTCCAAGAATGTATAAAGAGTAATTGTAATAGTTCTCAGCCAAAAAATTTTAAATAA |
| Protein Sequence | MNSQLVNPPHAFNYIESQRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPLRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKPIRCASMSRVGLRGPIEIRPGESWASRSTIGVGQSEGESEIENELHTYRDLQRLGASVLDPGESASIVGANMAQSNITMSVAQLNELVRTTVQECIKSNCNSSQPKNFK |
References More References in PubMed
| 1 |
Potato aucuba mosaic virus in Potato in New York State. Susaimuthu J, et al. Plant Dis. 2007 Sep;91(9):1202. doi: 10.1094/PDIS-91-9-1202A. PMID: 30780673 |
|---|---|
| 2 |
Evidence of occurring alfalfa mosaic virus in potato plants in Assam, India. Halabi MH, et al. Virusdisease. 2019 Dec;30(4):571-573. doi: 10.1007/s13337-019-00560-3. Epub 2019 Dec 9. PMID: 31897419 |
| 3 |
Characterization of potato yellow mosaic virus as a geminivirus with a bipartite genome. Roberts EJ, et al. Intervirology. 1988;29(3):162-9. doi: 10.1159/000150042. PMID: 3182230 |
| 4 |
Potato yellow mosaic virus: a synonym of tomato yellow mosaic virus. Morales FJ, et al. Arch Virol. 2001;146(11):2249-53. doi: 10.1007/s007050170035. PMID: 11765926 |
| 5 |
Jung HW, et al. Plant Dis. 2002 Feb;86(2):112-117. doi: 10.1094/PDIS.2002.86.2.112. PMID: 30823306 |
| 6 |
The infectivity of dimeric potato yellow mosaic geminivirus clones in different hosts. Buragohain AK, et al. J Gen Virol. 1994 Oct;75 ( Pt 10):2857-61. doi: 10.1099/0022-1317-75-10-2857. PMID: 7931179 |
| 7 |
Miao R, et al. Viruses. 2022 Sep 30;14(10):2171. doi: 10.3390/v14102171. PMID: 36298727 |
| 8 |
Li F, et al. New Phytol. 2015 Oct;208(2):555-69. doi: 10.1111/nph.13473. Epub 2015 May 22. PMID: 26010321 |
| 9 |
Global Plant Virus Disease Pandemics and Epidemics. Jones RAC. Plants (Basel). 2021 Jan 25;10(2):233. doi: 10.3390/plants10020233. PMID: 33504044 |
| 10 |
Complete genome sequence of pepper yellow mosaic virus, a potyvirus, occurring in Brazil. Lucinda N, et al. Arch Virol. 2012 Jul;157(7):1397-401. doi: 10.1007/s00705-012-1313-z. Epub 2012 Apr 15. PMID: 22527869 |