Potato yellow mosaic Panama virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000839305.1 |
| Release date | 2015/2/12 |
| Submitter | Engel,M., Fernandez,O., Jeske,H., Frischmuth,T. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
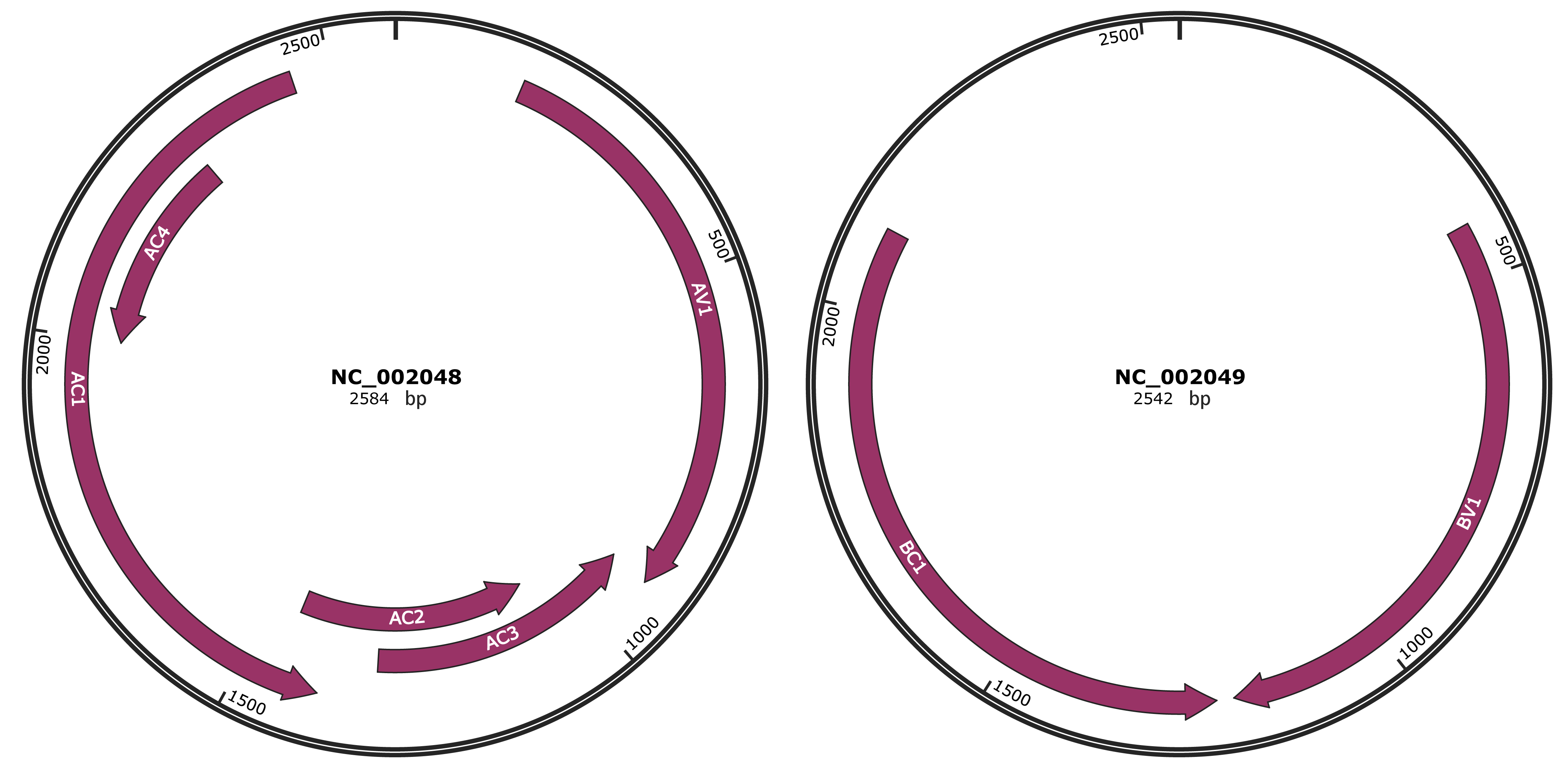
JBrowse
Genome
NC_002048
ACCGGATGGCCGCGCTTTTTTTCTTTTATGGGCTTTACTTGTATTGGGCTTTACTTTGGCCCAATCATAATCTGTCTGACAATCTTAGATAAGTGGAAATACTTTGGCGCTAAGTTGCTCTTTGTGTATAAATTAAAGCCTCTTGGCCCACTATCTTTAACTCAAAATGCCTAAGCGCGACGCTCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTATTCTCCTCGTGCAGGAATTGGGCCAAGAATAAACAAGGCCGCTGAATGGGTTAACAGGCCCATGTATCGGAAGCCCAGGATCTATCGGACGTTGAGGACGCCTGATGTTCCAAGAGGTTGTGAAGGGCCTTGTAAGGTCCAGTCATTCGAGCAGCGACATGACATCTTACACACTGGTAAGGTAATGTGTATATCTGACGTTACACGTGGTAACGGTATTACCCACCGTGTCGGTAAGCGGTTTTGTGTTAAGTCCGTTTACATATTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACTAACAGCGTCATGTTCTGGCTGGTCAGAGACCGAAGACCGTATGGAACGCCTATGGATTTCGGACAAGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCTACTGTTAAGAACGATCTTCGTGATCGTTATCAGGTCATGCATAGGTTCTACGGCAAGGTCACAGGTGGTCAGTATGCAAGCAACGAGCAGGCTATTGTGAGGCGGTTTTGGAAGGTCAACAATCACGTGGTCTACAACCACCAAGAAGCTGGCAAATATGAGAACCATACGGAGAACGCACTATTATTGTACATGGCATGTACTCATGCCTCAAACCCTGTATATGCAACGCTTAAGATTCGGATCTATTTTTATGATTCGATCTTAAATTAATAAAATTTTAATTTTATTGAATGATTTTCCAGTACATGATTTACATATGATCGATCTGTTGCAAAACGAACAGCTCTAATTACATTGTTAATTGAAATAACACCTAACTGATCTAAGTACATAAGGACTAAATGTCTAAATCTAGCTAAATAATTCGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGATCCAACGCTCTCCTGAGGTTGTGGTTGAATCTGATTTGGAGGTGGTACACCCTGGTTCTGGTGTATGATATGTGTTCTACTCGGTTTATCTTGAAATATAGGGGATTTTCTATCTCCCAGATAAACACGCCATTCTCTGCCTGACGTGCAGTGATGAGCTCCCCTGTGCGTGAATCCATGTCCTGCGCAGTCTATGTGGAAGTATATGGAGCAACCGCAGTCTAAATCAATGCGTCTCCTTCTGATGGCCCTCCTCTTAGCTTGCCTGTGTGCTTTCTTGATAGAGGGGGGCTGTGAGGGTGATGAAGACAGCATTCTTTAGAGTCCAGTTTTTGAGAGACGCATTATCTTCTTTCTCGAGGAAAGCTTTATAGCTGGAACCCTCGCCAGGATTGCAGAGCACGATTGATGGGATCCCTCCTTTAATTTGAACAGGCTTTCCGTACTTGCAATTTGATTGCCAATCTTTTTGGGCCCCAATGAGTTCTTTCCAGTGCTTTAGCTTTAGATACTGCGGTGCGACGTCATCAATGACGTTATATTCCACTTCATTCGAATAGACCCTAGAATTGAAATCAAGATGACCGCTCAAGTAATTATGTGGGCCTAAGACCCGAGCCCACATCGTCTTCCCCGTTCGAGAGTCACCTTCAATGATAATACTAATAGGTCTTTCCCGGCGCGCAGCGGCACTCCTTCCAAAATAGTCATCAGCCCACCTTAGCATCTCGTCCGGAACGTTAGTGAAAGAGGAGAGTGGAAACGGAGGAGCCCATGGTTCCGGAGCATTTGCGAATATTCGTTCAAGATTCGAACGAATGTTATGATTTTGAAGGACAAAGTCCTTCGGTTGTTCTTCTCTCAATATATTGAGGGCCTCGGAGACCGTGCCTGAATTGAGGGCTTTGGCATATGAATCATTGGCAGTCTGGCAACCTCCTCTAGCTGATCGTCCATCGATCTGGAAAATTCCAAAATCAATGAAGTCTCCGTCTTTTTCCACATAGGTCTTGACGTCTGAAGACGATTTAGCTCTCTGTATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACCAAGTCGAAGAATCGTTGATTGGTGCACTGGTACTTTCCTTCGAACTGGATGAGAACGTGGAGATGAGGTTGCCCATCTTCGTGTAGTTCTCTTGAAACACGAATGAATTTCTTAGAAGTTGGGGTTTCTAGGTTTTGCAATTGGGAAAGGGCTTCTTCTTTTGTGAGCGAACACTGGGGATATGTGAGGAAATAATTCCTGGCATTTATACTAAAACGACCTGCCCGTGGCATTTTGGTAAATATGATAGTGTCCCCCGATTGAGCTCTCTCTAAAACTCTATATGAATCGGTGGAACGGTGGACAATATATAGTAGAAGTCTCATTAACGGATTTGCAACACGTGGCGGCCATCCGCTATAATATT
NC_002049
ACCGGATGGCCGCGCTTTTTTTATACTGGGCTTTATATAGAGGCCCATTTGGAGTGGGTTTTTGGCCCATTTGGACTAACCACTCTCTTTCCTCGTATTTTCTCTGTGGTTTCTTTTAACTTTAATTTAAAATCACTTTTAAATTAAATATCTTTTTTTTTGTGTGGTCAATTTCGACAGCTGTTCTGCATAATATATATACTGACGACGTGGGTAATTTTCGACCAAGTTACAGTGTTTAAGTCGAAATTGTTTTTAACTGCTTTTGATTTAAGAGCTCATGGACCTATTGAGCTACATTGCACGTGTACCATTTAAATTGATCGTGTGGAGTCAAATTTTACATAATTGTATGAACTGACATGCATATATATTTGGCCGAAATAGGAAATGAGCTCATTATTACGTGGTATACAGACAATATTTGAAAATGTATCCTACGAAGTATAGGCGTGTGTCTTTGTCTAGCCAACCACGTAATTATTCACGTAATACTTCGATAAGACGTCAATCAGTTTTCAAGCGTAATGACAACAAGCATCGAACGTTTCCAACCGGTAAGACAACGGATGTTTCCATGATGAAGGCCCAACGGATTCATGAGAATCAATATGGTCCAGATTTTGCAATGGTTCATAATACAGCAGTGTCTACATTCATTAGCTACCCTGATGTGGCTAAGTCTATGCCTAACCGAAAGAGGTCATATATTAAGCTAAAACGACTTCGTTTCAAGGGTATAGTGAAAGTGGAACGTGTTCATGCAGAGGTGAACATGGACTGTTTAGCGCCTAAGACCGAAGGAGTTTTCTCTCTGGTTATTGTGATGGATCGAAAACCTCATCTTGGACCATCTGGGGGGCTGCCTACTTTCGATGAGCTGTTTGGCGCCAGGATCCACAGTCATGGTAACCTGGCAATAGTTCCTTCTTTTAAGGATCGTTTCTACATACGCCATGTATTGAAGCGGGTGATATCAGTGGACAAGGATACTATGATGGTGGACATCGAAGGCGTTACAACCCTTTCTAGCAGGCGTTTTAATTGTTGGGCTGGTTTTAAGGACCTTGATGTAGAGTCTCGAAAGGGTGTATATGATAATATTAATAAGAACGCCTTGTTAGTTTATTATTGTTGGATGTCGGATACTGTATCCAAAGCATCCACATTTGTATCGTTTGATCTTGACTATATTGGATGAGATATATATAATAATAAAAATTTTATTTTAAATTTTTGGGCTGAGAACTATTACACTGACTCTTTATACATTCTTGGACAGTTGTCCTTACAAGTTCATTTAACTGGGCTATAGACATGGTTATGTTGGACTGCGCCCTGTTTGCACCAACTATAGATGCGCTCTCTCCCGGATCTAGAACGCTGGCTCCTAGCCTTTGCAGATCTCGATACGGATGTAACTCGTTTTCTATCTCTGACTCCCCTTCTGAATGGACCCAACCTATAGTACTCCTGGAAGCCCATGATTCACCAGGCCTTAGATCAATTGGGCCTCTGAGCCCAACTCTCGACATTGATGCGCACCGTATGGGCTTCCTCTCCCATTTGCCATAGTCGACGTGAGAGAAATCTACATCTTTATCGGTGAATTGCTTGGACAGGATTTTCACCGTTGGCGCTCTGAACGGAATGTCCACGGAATGTTTAGCCGTCGACAGTTTCAGCTTCCCTTTGAACTTGGCAAAGTGTGTCCGCTGATGAACATTTGTATCTGAAACTCTGTAATAGAGTTTCCATGGGATGGGGTCTTTTAGGGAGAAAAAGGAAGCTGAAAAATAGTGGAGATCTATGTTGCATCTTATCGGGAATGTCCATGACGCCTGTAGTGATTCGTTGTCTGTCATCCTCTTGTCATGAATCTCCACTATTACAGAACCGGTGGCGTTGATGGGTACCTGTTGCCTGTACTCAATTACGCAGTGGTCTATTTTCATACAGCTGCGACTGAGCCTCGCCGTTAACTGCGCCGCCGTCGAAGGAAATTGGAGTATTATCTCAGTTAGATCATGAGAAAGCTGATACTCATCCCGCTGAGACTCTATGTAATTGAAAGCATGAGGAGGATTCACTAATTGAGAATTCATTTATGAAAAATAGGCGCGCAGCGGCACCGCTTAGAGAATACGAACAAGAAAGTACAGATATAGGGTTTCGTCAGAAAGTTAAAGACCTATTAGTATTATCATTGAAGGTGACTCTCGAACGGGCAAAACGATGATCTCGAAGGGAGAATAGAGAAACAGTAGATTATTATGGAAGAGTCTGCTATGATAAGATTCAAGGATTATGATGTTTATATAGAGAAGATGGTAATGATGAGGCAGCAATTAAGATATATCAGATAATAAATAGACGCATTAATAAAGAAGAAACCTTTCCGTGGCATTTTGGTAAATATGATAGTGTCCACCGATTGAGCTCTCTCTAAAACTCTATATGAATTGGTGGAACGGTGGACAATATATAGTAGAAGCCTCATTTAACGGATTTGCAACACGTGGCGGCCATCCGCTATAATATT
Gene Information
| NCBI Accession | NP_049352.1 |
|---|---|
| Location | 167-922 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGACGCTCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTATTCTCCTCGTGCAGGAATTGGGCCAAGAATAAACAAGGCCGCTGAATGGGTTAACAGGCCCATGTATCGGAAGCCCAGGATCTATCGGACGTTGAGGACGCCTGATGTTCCAAGAGGTTGTGAAGGGCCTTGTAAGGTCCAGTCATTCGAGCAGCGACATGACATCTTACACACTGGTAAGGTAATGTGTATATCTGACGTTACACGTGGTAACGGTATTACCCACCGTGTCGGTAAGCGGTTTTGTGTTAAGTCCGTTTACATATTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACTAACAGCGTCATGTTCTGGCTGGTCAGAGACCGAAGACCGTATGGAACGCCTATGGATTTCGGACAAGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCTACTGTTAAGAACGATCTTCGTGATCGTTATCAGGTCATGCATAGGTTCTACGGCAAGGTCACAGGTGGTCAGTATGCAAGCAACGAGCAGGCTATTGTGAGGCGGTTTTGGAAGGTCAACAATCACGTGGTCTACAACCACCAAGAAGCTGGCAAATATGAGAACCATACGGAGAACGCACTATTATTGTACATGGCATGTACTCATGCCTCAAACCCTGTATATGCAACGCTTAAGATTCGGATCTATTTTTATGATTCGATCTTAAATTAA |
| Protein Sequence | MPKRDAPWRSMAGTSKVSRNANYSPRAGIGPRINKAAEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSFEQRHDILHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYGKVTGGQYASNEQAIVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
| NCBI Accession | NP_049353.1 |
|---|---|
| Location | 919-1317 |
| Gene Name | AC3 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAGAAAATCCCCTATATTTCAAGATAAACCGAGTAGAACACATATCATACACCAGAACCAGGGTGTACCACCTCCAAATCAGATTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGAATTATTTAGCTAGATTTAGACATTTAGTCCTTATGTACTTAGATCAGTTAGGTGTTATTTCAATTAACAATGTAATTAGAGCTGTTCGTTTTGCAACAGATCGATCATATGTAAATCATGTACTGGAAAATCATTCAATAAAATTAAAATTTTATTAA |
| Protein Sequence | MDSRTGELITARQAENGVFIWEIENPLYFKINRVEHISYTRTRVYHLQIRFNHNLRRALDLHKAYLNFQVWTTSMTASGSNYLARFRHLVLMYLDQLGVISINNVIRAVRFATDRSYVNHVLENHSIKLKFY |
| NCBI Accession | NP_049354.1 |
|---|---|
| Location | 1064-1453 |
| Gene Name | AC2 |
| Protein Name | hypothetical protein |
| Coding Region | ATGCTGTCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAAGCACACAGGCAAGCTAAGAGGAGGGCCATCAGAAGGAGACGCATTGATTTAGACTGCGGTTGCTCCATATACTTCCACATAGACTGCGCAGGACATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAGAAAATCCCCTATATTTCAAGATAAACCGAGTAGAACACATATCATACACCAGAACCAGGGTGTACCACCTCCAAATCAGATTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGAATTATTTAGCTAG |
| Protein Sequence | MLSSSPSQPPSIKKAHRQAKRRAIRRRRIDLDCGCSIYFHIDCAGHGFTHRGAHHCTSGREWRVYLGDRKSPIFQDKPSRTHIIHQNQGVPPPNQIQPQPQESVGSPQSLPELPSLDDIDDSFWVELFS |
| NCBI Accession | NP_049355.1 |
|---|---|
| Location | 1395-2450 |
| Gene Name | AC1 |
| Protein Name | hypothetical protein |
| Coding Region | ATGCCACGGGCAGGTCGTTTTAGTATAAATGCCAGGAATTATTTCCTCACATATCCCCAGTGTTCGCTCACAAAAGAAGAAGCCCTTTCCCAATTGCAAAACCTAGAAACCCCAACTTCTAAGAAATTCATTCGTGTTTCAAGAGAACTACACGAAGATGGGCAACCTCATCTCCACGTTCTCATCCAGTTCGAAGGAAAGTACCAGTGCACCAATCAACGATTCTTCGACTTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGAGAGCTAAATCGTCTTCAGACGTCAAGACCTATGTGGAAAAAGACGGAGACTTCATTGATTTTGGAATTTTCCAGATCGATGGACGATCAGCTAGAGGAGGTTGCCAGACTGCCAATGATTCATATGCCAAAGCCCTCAATTCAGGCACGGTCTCCGAGGCCCTCAATATATTGAGAGAAGAACAACCGAAGGACTTTGTCCTTCAAAATCATAACATTCGTTCGAATCTTGAACGAATATTCGCAAATGCTCCGGAACCATGGGCTCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCGGACGAGATGCTAAGGTGGGCTGATGACTATTTTGGAAGGAGTGCCGCTGCGCGCCGGGAAAGACCTATTAGTATTATCATTGAAGGTGACTCTCGAACGGGGAAGACGATGTGGGCTCGGGTCTTAGGCCCACATAATTACTTGAGCGGTCATCTTGATTTCAATTCTAGGGTCTATTCGAATGAAGTGGAATATAACGTCATTGATGACGTCGCACCGCAGTATCTAAAGCTAAAGCACTGGAAAGAACTCATTGGGGCCCAAAAAGATTGGCAATCAAATTGCAAGTACGGAAAGCCTGTTCAAATTAAAGGAGGGATCCCATCAATCGTGCTCTGCAATCCTGGCGAGGGTTCCAGCTATAAAGCTTTCCTCGAGAAAGAAGATAATGCGTCTCTCAAAAACTGGACTCTAAAGAATGCTGTCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAAGCACACAGGCAAGCTAA |
| Protein Sequence | MPRAGRFSINARNYFLTYPQCSLTKEEALSQLQNLETPTSKKFIRVSRELHEDGQPHLHVLIQFEGKYQCTNQRFFDLVSPTRSAHFHPNIQRAKSSSDVKTYVEKDGDFIDFGIFQIDGRSARGGCQTANDSYAKALNSGTVSEALNILREEQPKDFVLQNHNIRSNLERIFANAPEPWAPPFPLSSFTNVPDEMLRWADDYFGRSAAARRERPISIIIEGDSRTGKTMWARVLGPHNYLSGHLDFNSRVYSNEVEYNVIDDVAPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKAFLEKEDNASLKNWTLKNAVFITLTAPLYQESTQAS |
| NCBI Accession | NP_049356.1 |
|---|---|
| Location | 2000-2293 |
| Gene Name | AC4 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGGCAACCTCATCTCCACGTTCTCATCCAGTTCGAAGGAAAGTACCAGTGCACCAATCAACGATTCTTCGACTTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGAGAGCTAAATCGTCTTCAGACGTCAAGACCTATGTGGAAAAAGACGGAGACTTCATTGATTTTGGAATTTTCCAGATCGATGGACGATCAGCTAGAGGAGGTTGCCAGACTGCCAATGATTCATATGCCAAAGCCCTCAATTCAGGCACGGTCTCCGAGGCCCTCAATATATTGA |
| Protein Sequence | MGNLISTFSSSSKESTSAPINDSSTWYPQPGQHISIRTYRELNRLQTSRPMWKKTETSLILEFSRSMDDQLEEVARLPMIHMPKPSIQARSPRPSIY |
| NCBI Accession | NP_049357.1 |
|---|---|
| Location | 431-1201 |
| Gene Name | BV1 |
| Protein Name | hypothetical protein |
| Coding Region | ATGTATCCTACGAAGTATAGGCGTGTGTCTTTGTCTAGCCAACCACGTAATTATTCACGTAATACTTCGATAAGACGTCAATCAGTTTTCAAGCGTAATGACAACAAGCATCGAACGTTTCCAACCGGTAAGACAACGGATGTTTCCATGATGAAGGCCCAACGGATTCATGAGAATCAATATGGTCCAGATTTTGCAATGGTTCATAATACAGCAGTGTCTACATTCATTAGCTACCCTGATGTGGCTAAGTCTATGCCTAACCGAAAGAGGTCATATATTAAGCTAAAACGACTTCGTTTCAAGGGTATAGTGAAAGTGGAACGTGTTCATGCAGAGGTGAACATGGACTGTTTAGCGCCTAAGACCGAAGGAGTTTTCTCTCTGGTTATTGTGATGGATCGAAAACCTCATCTTGGACCATCTGGGGGGCTGCCTACTTTCGATGAGCTGTTTGGCGCCAGGATCCACAGTCATGGTAACCTGGCAATAGTTCCTTCTTTTAAGGATCGTTTCTACATACGCCATGTATTGAAGCGGGTGATATCAGTGGACAAGGATACTATGATGGTGGACATCGAAGGCGTTACAACCCTTTCTAGCAGGCGTTTTAATTGTTGGGCTGGTTTTAAGGACCTTGATGTAGAGTCTCGAAAGGGTGTATATGATAATATTAATAAGAACGCCTTGTTAGTTTATTATTGTTGGATGTCGGATACTGTATCCAAAGCATCCACATTTGTATCGTTTGATCTTGACTATATTGGATGA |
| Protein Sequence | MYPTKYRRVSLSSQPRNYSRNTSIRRQSVFKRNDNKHRTFPTGKTTDVSMMKAQRIHENQYGPDFAMVHNTAVSTFISYPDVAKSMPNRKRSYIKLKRLRFKGIVKVERVHAEVNMDCLAPKTEGVFSLVIVMDRKPHLGPSGGLPTFDELFGARIHSHGNLAIVPSFKDRFYIRHVLKRVISVDKDTMMVDIEGVTTLSSRRFNCWAGFKDLDVESRKGVYDNINKNALLVYYCWMSDTVSKASTFVSFDLDYIG |
| NCBI Accession | NP_049358.1 |
|---|---|
| Location | 1224-2105 |
| Gene Name | BC1 |
| Protein Name | hypothetical protein |
| Coding Region | ATGAATTCTCAATTAGTGAATCCTCCTCATGCTTTCAATTACATAGAGTCTCAGCGGGATGAGTATCAGCTTTCTCATGATCTAACTGAGATAATACTCCAATTTCCTTCGACGGCGGCGCAGTTAACGGCGAGGCTCAGTCGCAGCTGTATGAAAATAGACCACTGCGTAATTGAGTACAGGCAACAGGTACCCATCAACGCCACCGGTTCTGTAATAGTGGAGATTCATGACAAGAGGATGACAGACAACGAATCACTACAGGCGTCATGGACATTCCCGATAAGATGCAACATAGATCTCCACTATTTTTCAGCTTCCTTTTTCTCCCTAAAAGACCCCATCCCATGGAAACTCTATTACAGAGTTTCAGATACAAATGTTCATCAGCGGACACACTTTGCCAAGTTCAAAGGGAAGCTGAAACTGTCGACGGCTAAACATTCCGTGGACATTCCGTTCAGAGCGCCAACGGTGAAAATCCTGTCCAAGCAATTCACCGATAAAGATGTAGATTTCTCTCACGTCGACTATGGCAAATGGGAGAGGAAGCCCATACGGTGCGCATCAATGTCGAGAGTTGGGCTCAGAGGCCCAATTGATCTAAGGCCTGGTGAATCATGGGCTTCCAGGAGTACTATAGGTTGGGTCCATTCAGAAGGGGAGTCAGAGATAGAAAACGAGTTACATCCGTATCGAGATCTGCAAAGGCTAGGAGCCAGCGTTCTAGATCCGGGAGAGAGCGCATCTATAGTTGGTGCAAACAGGGCGCAGTCCAACATAACCATGTCTATAGCCCAGTTAAATGAACTTGTAAGGACAACTGTCCAAGAATGTATAAAGAGTCAGTGTAATAGTTCTCAGCCCAAAAATTTAAAATAA |
| Protein Sequence | MNSQLVNPPHAFNYIESQRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRVGLRGPIDLRPGESWASRSTIGWVHSEGESEIENELHPYRDLQRLGASVLDPGESASIVGANRAQSNITMSIAQLNELVRTTVQECIKSQCNSSQPKNLK |
References More References in PubMed
| 1 |
Potato yellow mosaic virus: a synonym of tomato yellow mosaic virus. Morales FJ, et al. Arch Virol. 2001;146(11):2249-53. doi: 10.1007/s007050170035. PMID: 11765926 |
|---|---|
| 2 |
Herrera-Vásquez JA, et al. Plant Dis. 2009 Feb;93(2):198. doi: 10.1094/PDIS-93-2-0198A. PMID: 30764131 |
| 3 |
Distribution and diversity of geminiviruses in trinidad and tobago. Umaharan P, et al. Phytopathology. 1998 Dec;88(12):1262-8. doi: 10.1094/PHYTO.1998.88.12.1262. PMID: 18944827 |
| 4 |
Engel M, et al. J Gen Virol. 1998 Oct;79 ( Pt 10):2313-7. doi: 10.1099/0022-1317-79-10-2313. PMID: 9780034 |