Pepper yellow leaf curl Aceh virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_013088375.1 |
| Isolate | Indonesia |
| Release date | 2021/6/1 |
| Submitter | Kesumawati,E., Okabe,S., Homma,K., Fujiwara,I., Zakaria,S., Kanzaki,S., Koeda,S. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
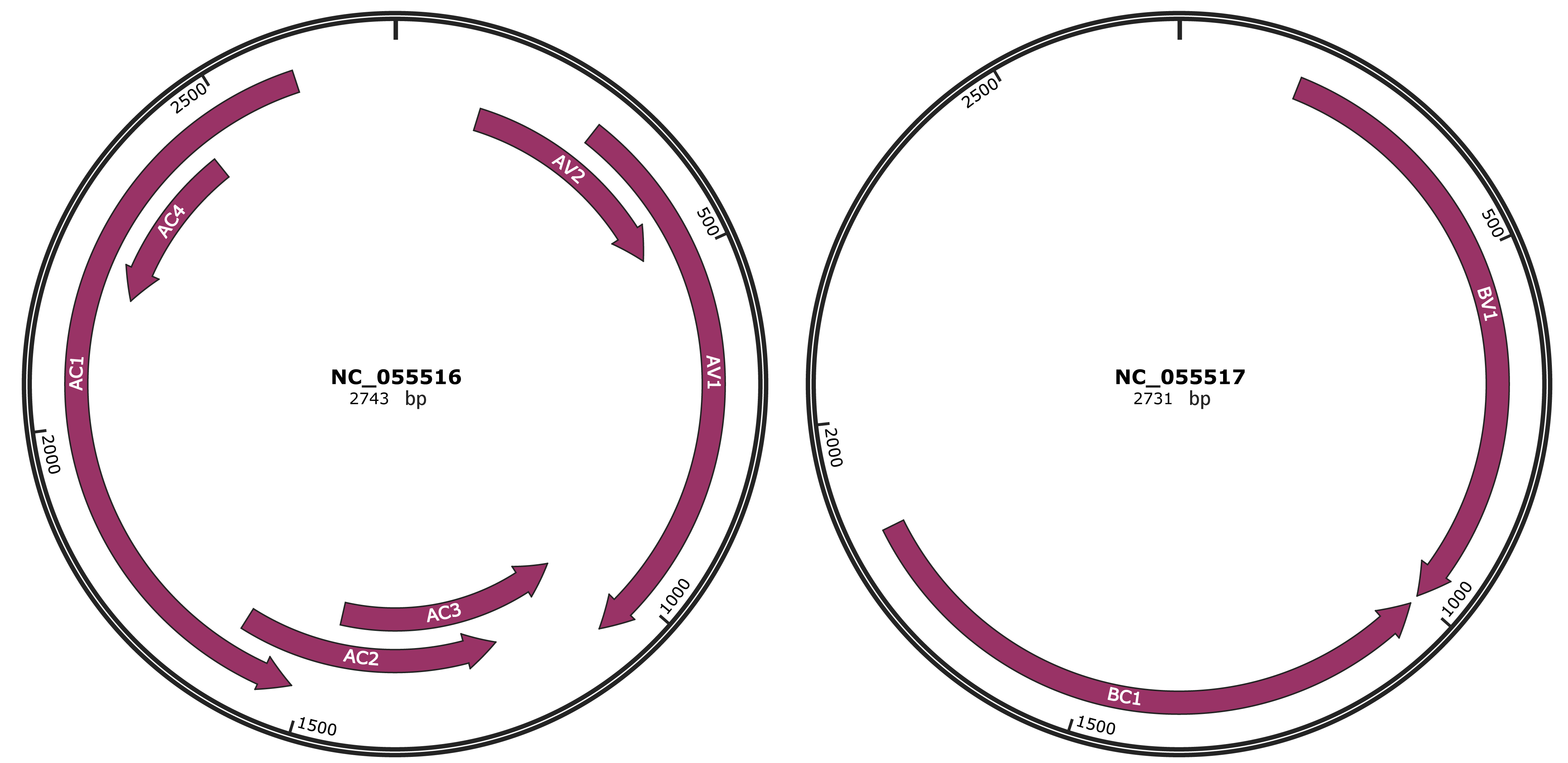
JBrowse
Genome
NC_055516
ACCGGATGGCCGCGCGATTTTTTAGGGTGGACCCCCGCCAAACTTTTGACTGACCAATCACGTTGCATCTGCAAAGCTTAATTAGTGGGTCGCCCACTATAAAGATAGGGACCACCCTCCACTATCCAAGGATGTGGGATCCGCTTATTCATCCTTTTCCTGAAACCCTACACGGGTTTCGATGCATGTTGGCTATCAAGTATCTGCAAAGCTTAGAGGCTACGTATTCTCCTGATACGGTTGGAGGTGAATTCGTGAGGGATTTAATTTGTCTGTTGCGGTGTAAAAATTATGCCGAAGCGTTCCATCGATACAGTGTCGTCGTTGCCAATGTCTATAACACGCCGGAGACTAAACTACGCGAGTCAGTACAGTCTCCCTGCTGCTGCCCCCACTGCCCCAGGCATGTCCTACAAACGAAGAGCGTGGGTAAATCGTCCTATGAATCGGAAACCCAGACTGTACAGGGGTCGAAGGAGCAGTGATGTTCCGCGGGGTTGTGAAGGACCTTGTAAGGTCCAATCCTTTGAACAGCGACATGACATAACACATACTGGGAAGGTCCTCTGTGTTTCCGATGTCACAAGAGGTAATGGTATTACTCACAGAGTTGGTAAAAGATTCTGTGTGAAATCTGTATATATTATTGGCAAAGTATGGATGGACGAGAACATCAAGTCGAAGAACCACACTAACAACGTCATGTTTTGGCTTGTGCGTGACCGGCGACCAGGTACAACTCCTTATGGTTTCGGAGAGTTGTTCAACATGTATGATAATGAACCCAGCACAGCAACTATCAAGAACGATCTTCGTGATCGTGTTCAGGTGTTACACCGTTTCTCAGCCACGGTGACTGGTGGTCAGTACGCAAGCAAGGAACAAGCAATCGTGAAGAGATTTTTTAGAGTTAACAACTATGTTGTTTACAATCATCAGGAAGCAGCAAAATATGAAAATCACACTGAAAATGCATTATTGTTGTATATGGCATGTACTCATGCATCCAATCCTGTATACGCGACATTGAAAATTCGTATTTACTTCTACGACAATGTAACAAATTAATAAAGGTTGAATTTTATTATGTGCAACTGCTTTGCGTACACAGTCTGTTCAAGTACATCCCACAAAACATAATTCACTGCTCTAATTACATTGTTTATTGACACGACGCCTAAATTGGACAGATATCTAATTACATTGTTTTTAAATACTCTTAAGAAATGCCAAATCTGAGGACGTAAACGAGTCCAGATGTGGAAGATTAAGAAACACTTGTGAATCCCCAGCGCTTTCCTCAGGTTGTGGTTGAACTGGATTTGTACTTCCATGTAGTCCATGTCGGTGTTGTACCCTCTGCTGCTGTGCCTCAGCACCTTGAAATAGAGGGGATTTGGAACCTTCCAAATATAGACGCCATTCTGCGCCTGAGCTGCAGTGATGTACTCCCCGGTGCGAAAATCCATGCCCGTGACAGTTGATACTGAGGTAATATGAGCAGCCGCAGTCTAAGTCAATACGTCTCCTGCGGATTATTTTCTTCTTCGCAATTTGGTGCAGTATCTTCTGTGGAACTTGAGTAGAGTGGCTCGTTGATGGTGACGAAGGTCGCATTTTTTACTGCCCAAGATTTCAATGCATTATTTTTGTCCTCGTCAAGGTATTCTTTATATGACGAGGTAGGACCAGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAATTGGCTTTCCGTACTTCGTGTTGCTTTGCCAGTTCCTCTGGGCCCCCATAAACTCTTTAAAGTGCTTGAGATAGTGGGGGTCGACGTCATCAATGACGTTGTACCAGGCGTCATTGTTGTATACCTTGGGGCTCAAGTCTAGATGTCCACAGAGATAATTATGGAGGCCCAATGACCTAGCCCACATTGTTTTTCCGGTTCTACTCTCACCTTCTATGACTATACTCTTGGGCCTCCAAGGCCGCGCAGCGGCATCTCCTACATTCTCGGACACCCACGCTTGAAGTTCCTCTGGAACTCGATCGAATGAAGAAGAAAGAAAAGGACAAACAAAAACCTCTAAAGGAGGTGCAAAAATCCTATCTAAATTAGAATTTAAATTATGAAAGTGAAAAATATAATCTTTTGGGAGTTTTTCCCTTATTATCCTAAGGGCTGCTTCTTTAGAACCTGCGTTTAGTGCCTCTGCGCAGGCGTCATTAGCATTCTGGCAGCCTCCTCTAGCACTTCGACCGTCGATCTGGAACGCTCCCCAGTCGATGGTGTCTCCGTCCTTGTCGATGTAGGCCTTGACGTCGGTGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCTGGTTGGGGATACGAGGTCGAAGAATCTTGGATTCTTGCACTGGAATTTCCCTTCGAATTGAATAAGCACGTGGAGATGAGGAGACCCATCTTCGTGAAGCTCTCTGCAGATCTTAATGTATTTTTTATTTGTAGGGGTTTCGAGGGCTTGTAATTGGGAAAGTGCCTCTTCTTTTGAAAGGGAGCACTGTGGATAAGTGATGAAAAAATTTTTGGCATTTATTCTAAATTTCGAAGGGGGAGGCATATTGACTGGTCAATCGGTGTCCAGCAAACTTGGCTATGCAATTGGTGTCTGGTGTCTTATTTATATTTGGACACCAAATGGCATTCTTGTAATTCCCATGGAAAGTCAAATTCCCAAAGCGGCCATCCGTATAATATT
NC_055517
ACCGAGGGCCGCGTTTTTTTTTTGTGGTCCCCCCACGTGCAGTACTACGTGTCCTCATCGTAGTCACACACAAATGGACAGTTGTCAATCATCCAAGGGTTCACGTACATCCTTTTGAAAGCTATAAGTATATTCAATTCATTATTCAGCAATTTGTTAGACAAAATGAGAATTCCCATTAGAACTCCCATGGGTTCAAACAGAGACCGGAGAGGTGGTTCTGGTTCCATATTCCGGTGGAACAACGCATATTCACGGTATTTTGGTCGTAGAGTTGGCACCCGTGTATACGGCATGCCCTTTGGTGGGTCTTCTGTACCTCGTAGACAAGTCAGCAATTCCGTTCGTCGGAACTTGTTTTCCGACCACCAGGACAAAGGGCGTAAAAGAAGAAATTCTATAGAGGAGGTACATGACGGTACAGACTATCTTCTTTGTAACAACACTTCTAAGGTGTCTTATATTAGCTATCCTGCCATGTGCCGTTCTGATTTTAGTAGCAGGGTAGATTCATTTGTGCGAGTGTTAGGGTTCAATGTTTCAGGGTCAGTAGTTGCCCGGCAACAGGAGCGTGTTGATGGTTCGCAGAAAACCGGTATCCACGGCATATTCAGCACAGTGGTCGTCCGTGACAAGAAGCCCTGCGAGTTCTCATCTGTGGATCCTCTCATCCCATTTGCGGAGATATTCGGACATGAGAAGGGAGCATGTTCTACTCTAAGAGTTAGAGATGCACATAGGAGTAGGTTTGTTTTAATCCAGCAGAAGAAGTGCGTTGTAAATACCGCTTTGCCGGTTCATGTATTTAGGTTTGTGTATTCGGTTAGGTTCAATAGATACCCTCTTTGGGTATCGTTCAAGGACACAACTGATGTAGAACCTAGTGGTCTCTACAGCAACGTGTCAAAGAACGCACTTCTTGTTTATTATGTCTGGTTATGCGATTCAAATGTAACTTCCGACATCCATGTAAAATACGACCTTGACTATATTGGATAAATAAAATTATATTTTATTTGATGGGTTTTGCATTCGAAGTTACATTACTGCCTTCCATACACAACTCTACAGTTTTTTTGATAATGTTAATTACATCGTCGTTAATCTTGTTGTTATTCACAACAACTTCGGAGGCGGACGGTCCCGGGTCTAGAGTCTGGTCTTGCAGCCTGTGTAGTCCTCTGTATGGAAGATCGTCTTGATCTTCATTCCCAATTGCACTTGCAGAAGCCCATGTCTGCCCAGGAAGAATTGCAGGAGTTGTGTATCTACATGACTGCGACTTCATGTTGTTCAGTCCTTGGACAGGTTTCCTGGAAACCTGAGAATGGGGCACTGTCCAGAAATCAATGTTGGTCATGTTAAATGCCTTGGACAATATTTCAATCTTGGGTGATTTGAACTGGATTTCTGTGGATTGTTTAGCCGAAGACATCTTCAGCTTGCCCTGCATCCTACAGAAATGTACCCCGTTGACGACGTTCGTGTCGTCAACCCTGTATAGAACCTTCCAAGGACTAGGGTCTTTCGGGGAAAAATACGAAGAGGAGTAGTAGTGTATATTGCAGTTGCACCCAATTGGAATTGTGAACTCAGCCTGTTTCGAGTCACCTTCGTGCAGTCGTGTGTCGTGCATCTCTATTATGACGTGTCCAGTTGCATTTACAGGAACCTGGTTCCTGTATTCAAGAATGACATGGTCAATCCTCAAACATTTGCCCATGAGTTTGGACAATTTTTGATCAAGAGTCGAAGGGAACAACAATGTCACTTCTGTTCTTTCATTGGACAGTTGAAACTCTGTCCTGTCCGACGTAGAATATGCAAGTGTGTTGTGGTTATTTTCCATATTTCACAGTGCATTCTTAGCTGGAATGCACTGCGTTTTATAATGGGTGTCAGAAAAGCTGCCGCACTGGGTGTCAGAAAAGAAATGGTAGTGGGTGTCAGAAAAGCTGCCACAGCTAGGGACCGCTAAATTTGAATTGTGAAAACCTAACAATTAAGGTTTGAGGCGTGGTTGTTATGCAGCCACGTCATGCATGTACTATGTGGATGACAGCTGTCATCCACTAACGGACAGAGCAATAATTAAAATTGGTAAAGCTGGAAACCCTAAATGGAATTTGACCGCAAATTCCAATTTAATTAATTTGTCAATATAATCTAATTCTGAAAGATGGATTGTTAACATACTCGTTAACACTAACAACCAACTGAATCAATTTATATTAACGGTAACATCGATTAACATACGGGTTAATCGACAAAACAGCAAACAAGTGGAATAACTAACGACTAAACACAACTAATCAGAATCTATTAACAAGAATTAGGCCGCGCAGCGGCAGTGTTCATCCATCTTATCCGAAACTAAACAAGCGGTAAAACAAGCTGGTGTCGTTAACATACCCATTAACAATAAATCAAATAATTAAGGTACTTAATTATTTGTGAAACTAGCTATACCTAACAATGTTGCAGTTTATATCCTAACATATAGACAAATCATATACTTATAATTATTATGAGATTTAATGTCAATGAAATCAGACCAGATTAGATAGCTGTCTAGAGAGAGAAAGTGAATTCTAGAGAGAGAAGCAATTGGAGACAATCCATCTATCGTCCTATATTGGTGTCTGGTGTCTTATTTATATTTGGACACCAAATGGCATTCTTGTAATTCCTATGGAAATTCAAATTCCCAAAGCGGCCCTCGTATAATATT
Gene Information
| NCBI Accession | YP_010087216.1 |
|---|---|
| Location | 132-485 |
| Gene Name | AV2 |
| Protein Name | AV2 protein |
| Coding Region | ATGTGGGATCCGCTTATTCATCCTTTTCCTGAAACCCTACACGGGTTTCGATGCATGTTGGCTATCAAGTATCTGCAAAGCTTAGAGGCTACGTATTCTCCTGATACGGTTGGAGGTGAATTCGTGAGGGATTTAATTTGTCTGTTGCGGTGTAAAAATTATGCCGAAGCGTTCCATCGATACAGTGTCGTCGTTGCCAATGTCTATAACACGCCGGAGACTAAACTACGCGAGTCAGTACAGTCTCCCTGCTGCTGCCCCCACTGCCCCAGGCATGTCCTACAAACGAAGAGCGTGGGTAAATCGTCCTATGAATCGGAAACCCAGACTGTACAGGGGTCGAAGGAGCAGTGA |
| Protein Sequence | MWDPLIHPFPETLHGFRCMLAIKYLQSLEATYSPDTVGGEFVRDLICLLRCKNYAEAFHRYSVVVANVYNTPETKLRESVQSPCCCPHCPRHVLQTKSVGKSSYESETQTVQGSKEQ |
| NCBI Accession | YP_010087217.1 |
|---|---|
| Location | 292-1068 |
| Gene Name | AV1 |
| Protein Name | AV1 protein |
| Coding Region | ATGCCGAAGCGTTCCATCGATACAGTGTCGTCGTTGCCAATGTCTATAACACGCCGGAGACTAAACTACGCGAGTCAGTACAGTCTCCCTGCTGCTGCCCCCACTGCCCCAGGCATGTCCTACAAACGAAGAGCGTGGGTAAATCGTCCTATGAATCGGAAACCCAGACTGTACAGGGGTCGAAGGAGCAGTGATGTTCCGCGGGGTTGTGAAGGACCTTGTAAGGTCCAATCCTTTGAACAGCGACATGACATAACACATACTGGGAAGGTCCTCTGTGTTTCCGATGTCACAAGAGGTAATGGTATTACTCACAGAGTTGGTAAAAGATTCTGTGTGAAATCTGTATATATTATTGGCAAAGTATGGATGGACGAGAACATCAAGTCGAAGAACCACACTAACAACGTCATGTTTTGGCTTGTGCGTGACCGGCGACCAGGTACAACTCCTTATGGTTTCGGAGAGTTGTTCAACATGTATGATAATGAACCCAGCACAGCAACTATCAAGAACGATCTTCGTGATCGTGTTCAGGTGTTACACCGTTTCTCAGCCACGGTGACTGGTGGTCAGTACGCAAGCAAGGAACAAGCAATCGTGAAGAGATTTTTTAGAGTTAACAACTATGTTGTTTACAATCATCAGGAAGCAGCAAAATATGAAAATCACACTGAAAATGCATTATTGTTGTATATGGCATGTACTCATGCATCCAATCCTGTATACGCGACATTGAAAATTCGTATTTACTTCTACGACAATGTAACAAATTAA |
| Protein Sequence | MPKRSIDTVSSLPMSITRRRLNYASQYSLPAAAPTAPGMSYKRRAWVNRPMNRKPRLYRGRRSSDVPRGCEGPCKVQSFEQRHDITHTGKVLCVSDVTRGNGITHRVGKRFCVKSVYIIGKVWMDENIKSKNHTNNVMFWLVRDRRPGTTPYGFGELFNMYDNEPSTATIKNDLRDRVQVLHRFSATVTGGQYASKEQAIVKRFFRVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDNVTN |
| NCBI Accession | YP_010087218.1 |
|---|---|
| Location | 1065-1469 |
| Gene Name | AC3 |
| Protein Name | AC3 protein |
| Coding Region | ATGGATTTTCGCACCGGGGAGTACATCACTGCAGCTCAGGCGCAGAATGGCGTCTATATTTGGAAGGTTCCAAATCCCCTCTATTTCAAGGTGCTGAGGCACAGCAGCAGAGGGTACAACACCGACATGGACTACATGGAAGTACAAATCCAGTTCAACCACAACCTGAGGAAAGCGCTGGGGATTCACAAGTGTTTCTTAATCTTCCACATCTGGACTCGTTTACGTCCTCAGATTTGGCATTTCTTAAGAGTATTTAAAAACAATGTAATTAGATATCTGTCCAATTTAGGCGTCGTGTCAATAAACAATGTAATTAGAGCAGTGAATTATGTTTTGTGGGATGTACTTGAACAGACTGTGTACGCAAAGCAGTTGCACATAATAAAATTCAACCTTTATTAA |
| Protein Sequence | MDFRTGEYITAAQAQNGVYIWKVPNPLYFKVLRHSSRGYNTDMDYMEVQIQFNHNLRKALGIHKCFLIFHIWTRLRPQIWHFLRVFKNNVIRYLSNLGVVSINNVIRAVNYVLWDVLEQTVYAKQLHIIKFNLY |
| NCBI Accession | YP_010087219.1 |
|---|---|
| Location | 1210-1617 |
| Gene Name | AC2 |
| Protein Name | AC2 protein |
| Coding Region | ATGCGACCTTCGTCACCATCAACGAGCCACTCTACTCAAGTTCCACAGAAGATACTGCACCAAATTGCGAAGAAGAAAATAATCCGCAGGAGACGTATTGACTTAGACTGCGGCTGCTCATATTACCTCAGTATCAACTGTCACGGGCATGGATTTTCGCACCGGGGAGTACATCACTGCAGCTCAGGCGCAGAATGGCGTCTATATTTGGAAGGTTCCAAATCCCCTCTATTTCAAGGTGCTGAGGCACAGCAGCAGAGGGTACAACACCGACATGGACTACATGGAAGTACAAATCCAGTTCAACCACAACCTGAGGAAAGCGCTGGGGATTCACAAGTGTTTCTTAATCTTCCACATCTGGACTCGTTTACGTCCTCAGATTTGGCATTTCTTAAGAGTATTTAA |
| Protein Sequence | MRPSSPSTSHSTQVPQKILHQIAKKKIIRRRRIDLDCGCSYYLSINCHGHGFSHRGVHHCSSGAEWRLYLEGSKSPLFQGAEAQQQRVQHRHGLHGSTNPVQPQPEESAGDSQVFLNLPHLDSFTSSDLAFLKSI |
| NCBI Accession | YP_010087220.1 |
|---|---|
| Location | 1517-2605 |
| Gene Name | AC1 |
| Protein Name | AC1 protein |
| Coding Region | ATGCCTCCCCCTTCGAAATTTAGAATAAATGCCAAAAATTTTTTCATCACTTATCCACAGTGCTCCCTTTCAAAAGAAGAGGCACTTTCCCAATTACAAGCCCTCGAAACCCCTACAAATAAAAAATACATTAAGATCTGCAGAGAGCTTCACGAAGATGGGTCTCCTCATCTCCACGTGCTTATTCAATTCGAAGGGAAATTCCAGTGCAAGAATCCAAGATTCTTCGACCTCGTATCCCCAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCACCGACGTCAAGGCCTACATCGACAAGGACGGAGACACCATCGACTGGGGAGCGTTCCAGATCGACGGTCGAAGTGCTAGAGGAGGCTGCCAGAATGCTAATGACGCCTGCGCAGAGGCACTAAACGCAGGTTCTAAAGAAGCAGCCCTTAGGATAATAAGGGAAAAACTCCCAAAAGATTATATTTTTCACTTTCATAATTTAAATTCTAATTTAGATAGGATTTTTGCACCTCCTTTAGAGGTTTTTGTTTGTCCTTTTCTTTCTTCTTCATTCGATCGAGTTCCAGAGGAACTTCAAGCGTGGGTGTCCGAGAATGTAGGAGATGCCGCTGCGCGGCCTTGGAGGCCCAAGAGTATAGTCATAGAAGGTGAGAGTAGAACCGGAAAAACAATGTGGGCTAGGTCATTGGGCCTCCATAATTATCTCTGTGGACATCTAGACTTGAGCCCCAAGGTATACAACAATGACGCCTGGTACAACGTCATTGATGACGTCGACCCCCACTATCTCAAGCACTTTAAAGAGTTTATGGGGGCCCAGAGGAACTGGCAAAGCAACACGAAGTACGGAAAGCCAATTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCTGGTCCTACCTCGTCATATAAAGAATACCTTGACGAGGACAAAAATAATGCATTGAAATCTTGGGCAGTAAAAAATGCGACCTTCGTCACCATCAACGAGCCACTCTACTCAAGTTCCACAGAAGATACTGCACCAAATTGCGAAGAAGAAAATAATCCGCAGGAGACGTATTGA |
| Protein Sequence | MPPPSKFRINAKNFFITYPQCSLSKEEALSQLQALETPTNKKYIKICRELHEDGSPHLHVLIQFEGKFQCKNPRFFDLVSPTRSTHFHPNIQGAKSSTDVKAYIDKDGDTIDWGAFQIDGRSARGGCQNANDACAEALNAGSKEAALRIIREKLPKDYIFHFHNLNSNLDRIFAPPLEVFVCPFLSSSFDRVPEELQAWVSENVGDAAARPWRPKSIVIEGESRTGKTMWARSLGLHNYLCGHLDLSPKVYNNDAWYNVIDDVDPHYLKHFKEFMGAQRNWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEDKNNALKSWAVKNATFVTINEPLYSSSTEDTAPNCEEENNPQETY |
| NCBI Accession | YP_010087221.1 |
|---|---|
| Location | 2191-2448 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGTCTCCTCATCTCCACGTGCTTATTCAATTCGAAGGGAAATTCCAGTGCAAGAATCCAAGATTCTTCGACCTCGTATCCCCAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCACCGACGTCAAGGCCTACATCGACAAGGACGGAGACACCATCGACTGGGGAGCGTTCCAGATCGACGGTCGAAGTGCTAGAGGAGGCTGCCAGAATGCTAATGACGCCTGCGCAGAGGCACTAA |
| Protein Sequence | MGLLISTCLFNSKGNSSARIQDSSTSYPQPGQHISIRTFRELNQAPTSRPTSTRTETPSTGERSRSTVEVLEEAARMLMTPAQRH |
| NCBI Accession | YP_010087222.1 |
|---|---|
| Location | 166-999 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGAGAATTCCCATTAGAACTCCCATGGGTTCAAACAGAGACCGGAGAGGTGGTTCTGGTTCCATATTCCGGTGGAACAACGCATATTCACGGTATTTTGGTCGTAGAGTTGGCACCCGTGTATACGGCATGCCCTTTGGTGGGTCTTCTGTACCTCGTAGACAAGTCAGCAATTCCGTTCGTCGGAACTTGTTTTCCGACCACCAGGACAAAGGGCGTAAAAGAAGAAATTCTATAGAGGAGGTACATGACGGTACAGACTATCTTCTTTGTAACAACACTTCTAAGGTGTCTTATATTAGCTATCCTGCCATGTGCCGTTCTGATTTTAGTAGCAGGGTAGATTCATTTGTGCGAGTGTTAGGGTTCAATGTTTCAGGGTCAGTAGTTGCCCGGCAACAGGAGCGTGTTGATGGTTCGCAGAAAACCGGTATCCACGGCATATTCAGCACAGTGGTCGTCCGTGACAAGAAGCCCTGCGAGTTCTCATCTGTGGATCCTCTCATCCCATTTGCGGAGATATTCGGACATGAGAAGGGAGCATGTTCTACTCTAAGAGTTAGAGATGCACATAGGAGTAGGTTTGTTTTAATCCAGCAGAAGAAGTGCGTTGTAAATACCGCTTTGCCGGTTCATGTATTTAGGTTTGTGTATTCGGTTAGGTTCAATAGATACCCTCTTTGGGTATCGTTCAAGGACACAACTGATGTAGAACCTAGTGGTCTCTACAGCAACGTGTCAAAGAACGCACTTCTTGTTTATTATGTCTGGTTATGCGATTCAAATGTAACTTCCGACATCCATGTAAAATACGACCTTGACTATATTGGATAA |
| Protein Sequence | MRIPIRTPMGSNRDRRGGSGSIFRWNNAYSRYFGRRVGTRVYGMPFGGSSVPRRQVSNSVRRNLFSDHQDKGRKRRNSIEEVHDGTDYLLCNNTSKVSYISYPAMCRSDFSSRVDSFVRVLGFNVSGSVVARQQERVDGSQKTGIHGIFSTVVVRDKKPCEFSSVDPLIPFAEIFGHEKGACSTLRVRDAHRSRFVLIQQKKCVVNTALPVHVFRFVYSVRFNRYPLWVSFKDTTDVEPSGLYSNVSKNALLVYYVWLCDSNVTSDIHVKYDLDYIG |
| NCBI Accession | YP_010087223.1 |
|---|---|
| Location | 1013-1849 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGAAAATAACCACAACACACTTGCATATTCTACGTCGGACAGGACAGAGTTTCAACTGTCCAATGAAAGAACAGAAGTGACATTGTTGTTCCCTTCGACTCTTGATCAAAAATTGTCCAAACTCATGGGCAAATGTTTGAGGATTGACCATGTCATTCTTGAATACAGGAACCAGGTTCCTGTAAATGCAACTGGACACGTCATAATAGAGATGCACGACACACGACTGCACGAAGGTGACTCGAAACAGGCTGAGTTCACAATTCCAATTGGGTGCAACTGCAATATACACTACTACTCCTCTTCGTATTTTTCCCCGAAAGACCCTAGTCCTTGGAAGGTTCTATACAGGGTTGACGACACGAACGTCGTCAACGGGGTACATTTCTGTAGGATGCAGGGCAAGCTGAAGATGTCTTCGGCTAAACAATCCACAGAAATCCAGTTCAAATCACCCAAGATTGAAATATTGTCCAAGGCATTTAACATGACCAACATTGATTTCTGGACAGTGCCCCATTCTCAGGTTTCCAGGAAACCTGTCCAAGGACTGAACAACATGAAGTCGCAGTCATGTAGATACACAACTCCTGCAATTCTTCCTGGGCAGACATGGGCTTCTGCAAGTGCAATTGGGAATGAAGATCAAGACGATCTTCCATACAGAGGACTACACAGGCTGCAAGACCAGACTCTAGACCCGGGACCGTCCGCCTCCGAAGTTGTTGTGAATAACAACAAGATTAACGACGATGTAATTAACATTATCAAAAAAACTGTAGAGTTGTGTATGGAAGGCAGTAATGTAACTTCGAATGCAAAACCCATCAAATAA |
| Protein Sequence | MENNHNTLAYSTSDRTEFQLSNERTEVTLLFPSTLDQKLSKLMGKCLRIDHVILEYRNQVPVNATGHVIIEMHDTRLHEGDSKQAEFTIPIGCNCNIHYYSSSYFSPKDPSPWKVLYRVDDTNVVNGVHFCRMQGKLKMSSAKQSTEIQFKSPKIEILSKAFNMTNIDFWTVPHSQVSRKPVQGLNNMKSQSCRYTTPAILPGQTWASASAIGNEDQDDLPYRGLHRLQDQTLDPGPSASEVVVNNNKINDDVINIIKKTVELCMEGSNVTSNAKPIK |
References More References in PubMed
| 1 |
Kesumawati E, et al. Arch Virol. 2019 Sep;164(9):2379-2383. doi: 10.1007/s00705-019-04316-8. Epub 2019 Jun 15. PMID: 31203434 |
|---|---|
| 2 |
Koeda S, et al. Plant Dis. 2020 Dec;104(12):3221-3229. doi: 10.1094/PDIS-03-20-0613-RE. Epub 2020 Oct 12. PMID: 33044916 |
| 3 |
Koeda S, et al. Theor Appl Genet. 2021 Sep;134(9):2947-2964. doi: 10.1007/s00122-021-03870-7. Epub 2021 Jun 3. PMID: 34081151 |
| 4 |
Koeda S, et al. Theor Appl Genet. 2022 Jul;135(7):2437-2452. doi: 10.1007/s00122-022-04125-9. Epub 2022 Jun 2. PMID: 35652932 |