Pepper leafroll virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_004787035.1 |
| Isolate | Peru: La Libertad, San Carlos Alto |
| Release date | 2019/6/28 |
| Submitter | Martinez-Ayala,A., Sanchez-Campos,S., Aragon-Caballero,L., Navas-Castillo,J., Moriones,E. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
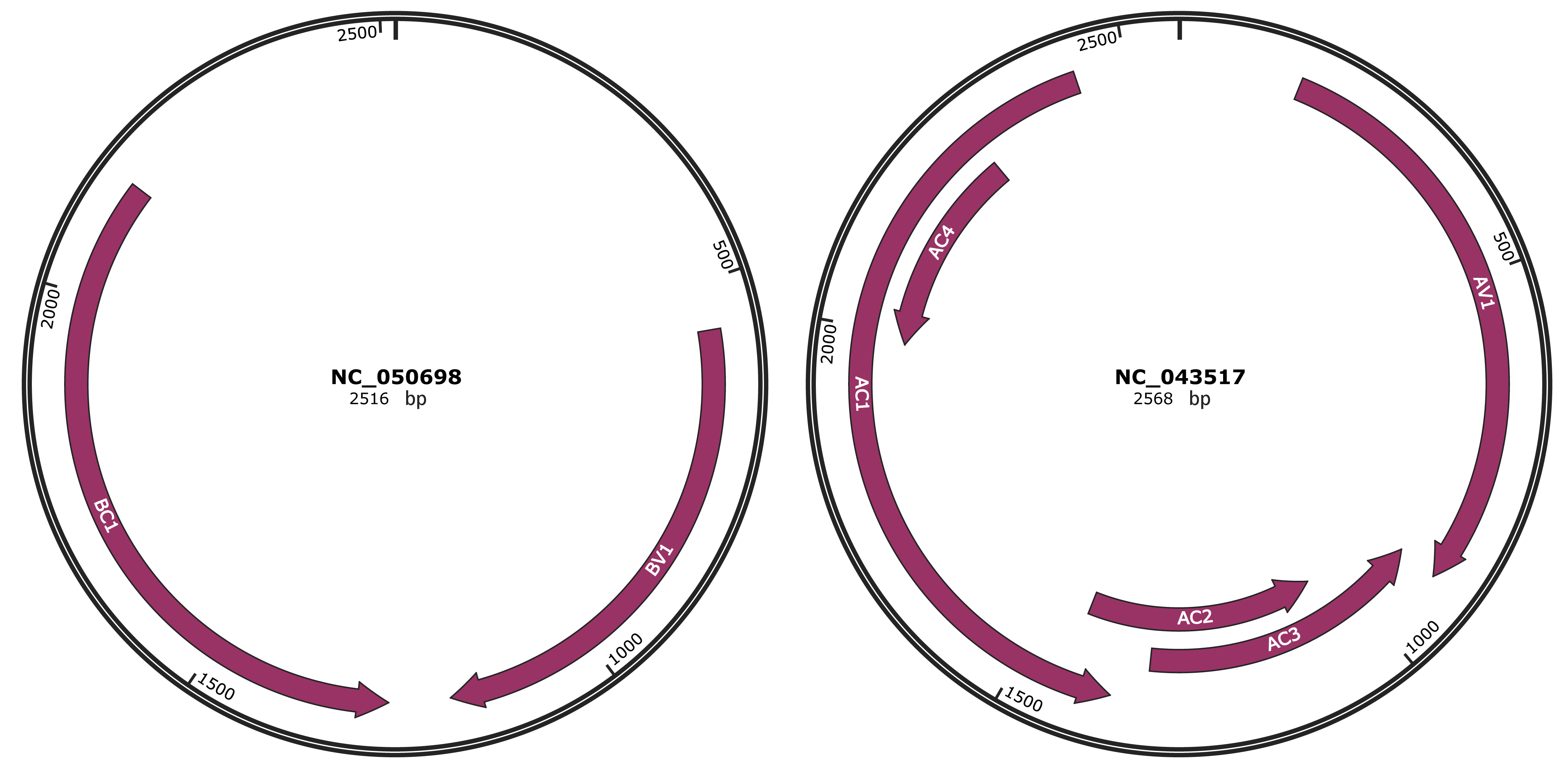
JBrowse
Genome
NC_050698
NC_043517
Gene Information
| NCBI Accession | YP_009927293.1 |
|---|---|
| Location | 562-1188 |
| Gene Name | BV1 |
| Protein Name | NSP |
| Coding Region | ATGCCAGTGTCAGCCCAACGGATACATGAGAACCAATATGGGCCTGAGTTTGTTATGGCCCAAAATACAGCCATATCTAGTTACATCACATATCCTACACTTGGTAAGGGTGACTCTTGTCGATCACGGAGTTATATTAAGTTAAAACGTCTGCGTTTCAAAGGTACACTAAAGATTGAACGTATTAATCCGGATGTGAATATGCAAGATTTAAGCCCGAAGATTGAAGGTGTATTTTCTATGGTAATTGTTGTTGATCGTAAACCTCATCTTGGGGCATCTGGACGTCTGCATACGTTTGATGAACTATTTGGAGCAAGGATACATAGCCATGGGAATTTGGTTGTTACTGCTGCACAGAGAGACCGTTTTTATATACGGCATGTGTTTAAGCAAGTTATGTCCGTTGAAAATGATTCTACAATGGTCGATTTGGAAGGAGTGACATATTTATCGAACAGGCGTTATAATTGCTGGTCTACATTTAAAGACGTTGATCGTGATTCATGTAATGGGGTTTATGATAATATTAGCAAAAATGCTGTGTTAGTCTATTATTGCTGGATGACGGATATTCTATCTAAGGCATCGACATTTGTATCATTTGATCTTGATTATATTGGATGA |
| Protein Sequence | MPVSAQRIHENQYGPEFVMAQNTAISSYITYPTLGKGDSCRSRSYIKLKRLRFKGTLKIERINPDVNMQDLSPKIEGVFSMVIVVDRKPHLGASGRLHTFDELFGARIHSHGNLVVTAAQRDRFYIRHVFKQVMSVENDSTMVDLEGVTYLSNRRYNCWSTFKDVDRDSCNGVYDNISKNAVLVYYCWMTDILSKASTFVSFDLDYIG |
| NCBI Accession | YP_009927294.1 |
|---|---|
| Location | 1267-2148 |
| Gene Name | BC1 |
| Protein Name | MP |
| Coding Region | ATGGGTTCACAGCTAGATTTCCCACCAACAGCGTTTAATTATGTCGAATCTCAACGTGATGAATATCAATTATCTCACGACTTAACTGAGATTATTTTGCAGTTTCCTTCAACAGCTTCACAACTTACTGCAAGACTGAGTCGTAGCTGTATGAAAATTGACCATTGCGTCATTGAATACAGACAACAAGTACCGATTAACGCATCTGGTTCTGTAATAGTGGAGATTCATGATAAAAGAATGACTGATAATGAGTCATTGCAAGCGTCATGGACATTTCCCATAAGATGTAACATAGACCTCCACTATTTCTCTTCGTCATTCTTTTCGCTTAAAGACCCAATTCCATGGAAATTATATTATAGAGTTAGCGACACGAATGTTCATCAAAGGACACATTTTGCCAAATTCAAAGGCAAGCTGAAATTATCGACGGCTAAACATTCCGTGGATATTCCTTTCAGACCCCCAACTGTAAAAATATTGTCTAAGCAGTTTACCGAGAAAGATATAGATTTCTCGCATGTTGGGTACGGCAAATATGAAAGGAAACTCATCAGGTCCGCATCCAGTTCAAGATATGGGCTACACAGCCCAATTACAATAGCACCAGGTGAAACATGGGCAACACGAAGTACTATCGGGTCTGGTCATACAGATGCGGACTCTGATATTGAGAGCGCACTACATCCTTACAAAGAACTACACAGAATAGGTACGAGCTTATTAGACCCAGGTGACTCCGCATCAATTGTAGGTGCGCGACGAGCAGAGTCCAACATAACAATGTCTATGGCCCAGTTAAATGAATTGGTTAAGACTGCGGCCCAGGAATGTATTAAAAATAACTGTACTCCTACTGAGACCAAATCCTTGAAATAA |
| Protein Sequence | MGSQLDFPPTAFNYVESQRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINASGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRPPTVKILSKQFTEKDIDFSHVGYGKYERKLIRSASSSRYGLHSPITIAPGETWATRSTIGSGHTDADSDIESALHPYKELHRIGTSLLDPGDSASIVGARRAESNITMSMAQLNELVKTAAQECIKNNCTPTETKSLK |
| NCBI Accession | YP_009666355.1 |
|---|---|
| Location | 158-907 |
| Gene Name | AV1 |
| Protein Name | CP |
| Coding Region | ATGCCAAAGCGGGATGCCCCATGGCGTACTATGGCGGGGACCTCCAAGGTGTCTCGTAATGCCAACTATTCCCCTCGTGGTGGTCCAAAGTTTGACAAGGCCTCTGCTTGGGTGAACAGGCCCATGTATAGGAAGCCCAGGATTTACCGGACTCTACGAGGGCCCGATGTTCCAAGAGGTTGTGAAGGGCCTTGTAAGGTGCAGTCTTACGAGCAACGTCATGATATTTCCCATGTTGGTAAAGTTATGTGTATATCTGATGTCACGCGTGGTAACGGTATTACCCATCGTGTAGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATTTTAGGTAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGCGTGATGTTCTGGTTGGTGAGAGACCGTAGACCTTATTCCACGCCTATGGACTTTGGTCAAGTATTCAACATGTTTGATAATGAACCCAGTACTGCCACGGTGAAAAATGATTTGCGTGACCGTTATCAAGTTATGCACAAGTTTTATGCTAAGGTTACTGGTGGACAATATGCAAGTAACGAACAGGCGTTGGTCAAACGTTTCTGGAAGGTTAACAACTATGTGGTCTACAACCATCAGGAAGCGGGGAAATACGAGAATCATACGGAGAATGCGTTACTATTGTATATGGCATGTACTCATGCGTCTAATCCTGTGTATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATATTAAATTAA |
| Protein Sequence | MPKRDAPWRTMAGTSKVSRNANYSPRGGPKFDKASAWVNRPMYRKPRIYRTLRGPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYSTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
| NCBI Accession | YP_009666356.1 |
|---|---|
| Location | 904-1326 |
| Gene Name | AC3 |
| Protein Name | TrAP |
| Coding Region | ATGTCCACATCAACTGCTGCAACGACGGATTTACGCACAGGGGAACTCATCACTGTGCCTCAAGCAGAGAATGGCGTATATACCTGGGAGATAGAAAATCCCCTCTATTTCAAAATAACCAACGTAGAGAAGCCTCTCTACACGAGGACAACAATATTCCACGTCCAGATACGCTTCAACCACAACCTGAGGAAAGCGTTGGATCTCCACAAGGCATTTCTCAATTTCCAAGTTTGGACGACATTGACGACAGCTTCTGGGCAGATATATTTAAGTAGATTTAAATATTTAGTATTGTCGTTTTTAGATAGAGTAGGTGTTATTGGACTCAACAATGTAATCAGAGCTGTTCGTTACGCAACAGACAGAGCATATGTAAATTATGTACTTGAGAATCATGAAATAAAATTCAAAATTTATTAA |
| Protein Sequence | MSTSTAATTDLRTGELITVPQAENGVYTWEIENPLYFKITNVEKPLYTRTTIFHVQIRFNHNLRKALDLHKAFLNFQVWTTLTTASGQIYLSRFKYLVLSFLDRVGVIGLNNVIRAVRYATDRAYVNYVLENHEIKFKIY |
| NCBI Accession | YP_009666357.1 |
|---|---|
| Location | 1049-1438 |
| Gene Name | AC2 |
| Protein Name | REn |
| Coding Region | ATGCGAAATTCATCACTCTCAACGCCCCCTTGTATCAAAGCACAGCACACAGCAGCGAAACGTAGAGCACCTAGACGTAGACGCATCGACCTTAATTGTGGGTGTTCTATTTATGTCCACATCAACTGCTGCAACGACGGATTTACGCACAGGGGAACTCATCACTGTGCCTCAAGCAGAGAATGGCGTATATACCTGGGAGATAGAAAATCCCCTCTATTTCAAAATAACCAACGTAGAGAAGCCTCTCTACACGAGGACAACAATATTCCACGTCCAGATACGCTTCAACCACAACCTGAGGAAAGCGTTGGATCTCCACAAGGCATTTCTCAATTTCCAAGTTTGGACGACATTGACGACAGCTTCTGGGCAGATATATTTAAGTAG |
| Protein Sequence | MRNSSLSTPPCIKAQHTAAKRRAPRRRRIDLNCGCSIYVHINCCNDGFTHRGTHHCASSREWRIYLGDRKSPLFQNNQRREASLHEDNNIPRPDTLQPQPEESVGSPQGISQFPSLDDIDDSFWADIFK |
| NCBI Accession | YP_009666358.1 |
|---|---|
| Location | 1374-2435 |
| Gene Name | AC1 |
| Protein Name | Rep |
| Coding Region | ATGCCCTTACCAAAGCGTTTTCAAGTAAGTGCGAAGAACTTCTTCCTCACATACCCTCATTGTCCATTAACCAAAGAAGAAGCTCTTGCACAGATACAGCAACTCAATACACCAACAAATAAGAAGTTCATTCGCGTTACAAGAGAACTCCATGAGGATGGGCAACCTCATCTACACGTGCTTATCCAGTTCGAAGGAAAATTCAGATGCCAAAATCCAAGATTCTTCGACTTGGTCTCCCCAACAAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAGAGCTCGTCAGATGTCAAGACCTACATGGAGAAAGACGGAGACTTCATTGATTTTGGAATTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAATGATACGTACGCCAAGGTTCTCAATGCACAGTGTGCATCAACGGCACTTAATATATTAAGAGAAGAACAGCCAAGAGATTATGTTCTTCATTTAGACAAAATTAGGGGGCATATTAATAAGTTATTTCAAAAGGCTCCAGAACCTTGGGTACCTCCATTCCACCTCTCCTCGTTCAATAATGTCCCAAAAGAAATGCAAGATTGGGCTGATGATTATTTTGGGAGAGGTGCCGCTGCGCGGCCGGAAAGACCTATTAGTATCATCATCGAAGGTGATAGTCGAACAGGGAAGACAATGTGGGCGCGTGCACTAGGGCCACATAATTATTTAAGCGGACATCTCGACTTTAATTCAAATGTGTACTCAAATAATGCAGAGTACAACGTCATTGATGATGTCAGTCCGCAATATTTAAAGATGAAACATTGGAAAGAGATAATTGGGGCTCAAAAGGACTGGCAATCAAACTGCAAATACGGGAAGCCAGTTCAAATTAAAGGAGGAATTCCCGCTATCGTGCTGTGCAATCCAGGAGAGGGGGCCAGTTATAAATATTTCCTTGACAGACAGGAAAATGCATCGCTAAAATCGTGGACACTCCATAATGCGAAATTCATCACTCTCAACGCCCCCTTGTATCAAAGCACAGCACACAGCAGCGAAACGTAG |
| Protein Sequence | MPLPKRFQVSAKNFFLTYPHCPLTKEEALAQIQQLNTPTNKKFIRVTRELHEDGQPHLHVLIQFEGKFRCQNPRFFDLVSPTRSAHFHPNIQGAKSSSDVKTYMEKDGDFIDFGIFQVDGRSARGGCQSANDTYAKVLNAQCASTALNILREEQPRDYVLHLDKIRGHINKLFQKAPEPWVPPFHLSSFNNVPKEMQDWADDYFGRGAAARPERPISIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSNVYSNNAEYNVIDDVSPQYLKMKHWKEIIGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKYFLDRQENASLKSWTLHNAKFITLNAPLYQSTAHSSET |
| NCBI Accession | YP_009666359.1 |
|---|---|
| Location | 1985-2284 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGAGGATGGGCAACCTCATCTACACGTGCTTATCCAGTTCGAAGGAAAATTCAGATGCCAAAATCCAAGATTCTTCGACTTGGTCTCCCCAACAAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAGAGCTCGTCAGATGTCAAGACCTACATGGAGAAAGACGGAGACTTCATTGATTTTGGAATTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAATGATACGTACGCCAAGGTTCTCAATGCACAGTGTGCATCAACGGCACTTAATATATTAA |
| Protein Sequence | MRMGNLIYTCLSSSKENSDAKIQDSSTWSPQQGQHISIQTFRELRARQMSRPTWRKTETSLILEFSKSMEDQLEEVANLPMIRTPRFSMHSVHQRHLIY |
References More References in PubMed
| 1 |
Kamran A, et al. Plant Dis. 2018 Feb;102(2):318-326. doi: 10.1094/PDIS-03-17-0418-RE. Epub 2017 Nov 21. PMID: 30673532 |
|---|---|
| 2 |
Commodity risk assessment of Petunia spp. and Calibrachoa spp. unrooted cuttings from Kenya. EFSA Panel on Plant Health (PLH), et al. EFSA J. 2024 Apr 25;22(4):e8742. doi: 10.2903/j.efsa.2024.8742. eCollection 2024 Apr. PMID: 38665158 |
| 3 |
Li Y, et al. Front Microbiol. 2021 Feb 26;12:623875. doi: 10.3389/fmicb.2021.623875. eCollection 2021. PMID: 33717012 |
| 4 |
Nolasco G, et al. J Virol Methods. 1993 Dec 15;45(2):201-18. doi: 10.1016/0166-0934(93)90104-y. PMID: 8113346 |
| 5 |
Muntingia yellow spot virus: a novel New World begomovirus infecting Muntingia calabura L. Romay G, et al. Arch Virol. 2021 Jun;166(6):1759-1762. doi: 10.1007/s00705-021-05039-5. Epub 2021 Mar 20. PMID: 33745066 |