Pepper leaf curl Bangladesh virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000842805.1 |
| Isolate | Bangladesh: Bogra |
| Release date | 2015/2/12 |
| Submitter | Tsai,W.S., Green,S.K., Rashid,M.H. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
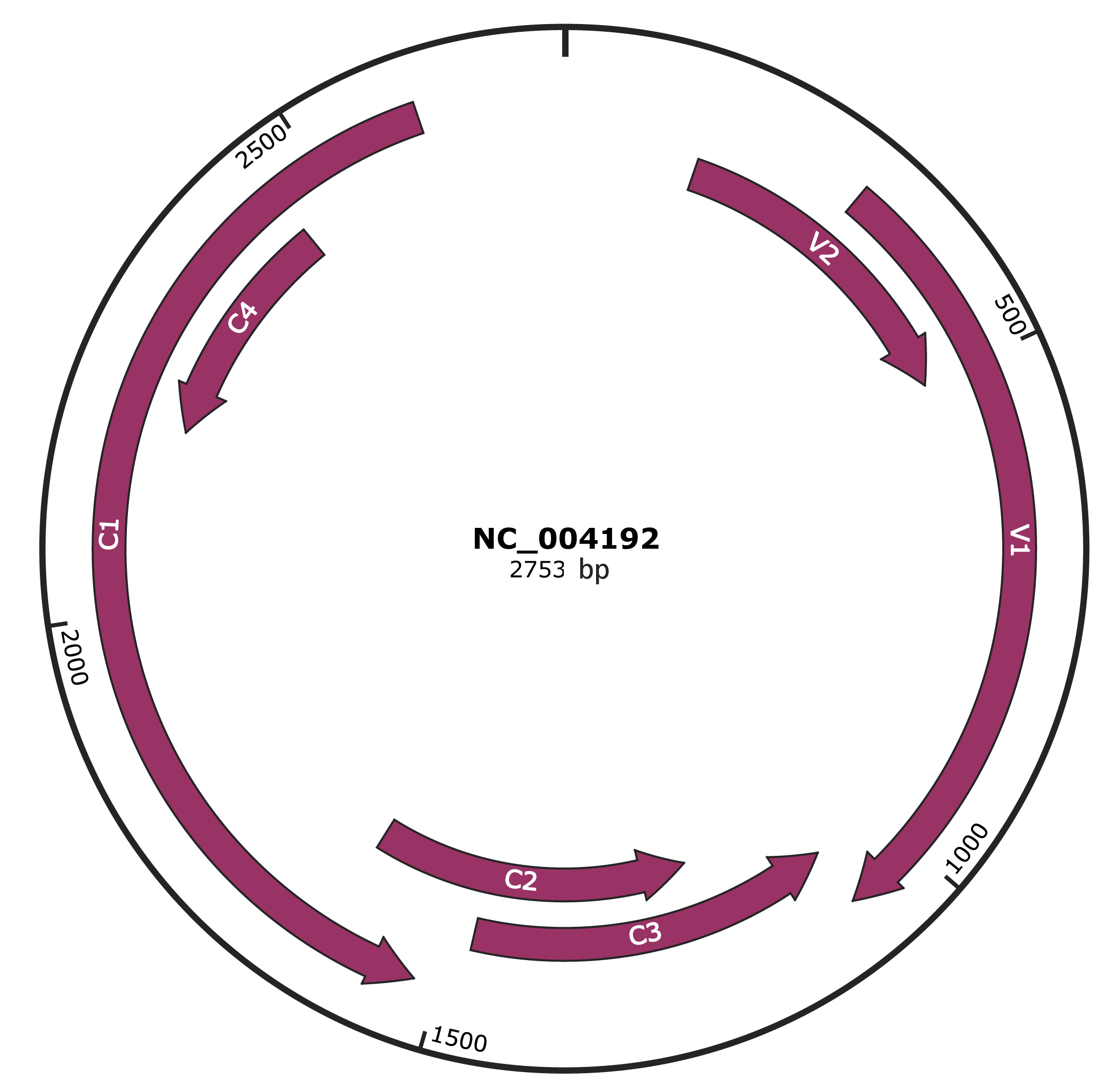
JBrowse
Genome
NC_004192
Gene Information
| NCBI Accession | NP_690912.1 |
|---|---|
| Location | 146-502 |
| Gene Name | V2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCATTATTAAACGAGTTCCCCGAAACCGTTCACGGTTTTCGGTGTATGCTAGCCGTTAAATATCTGCAGCTAGTAGAAAAGACGTATTCTCCAGATACTTTGGGGTACGACTTAATCCGGGATTTAATATCAGTCATCAGGGCCAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCCCATATTCCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAAAGCATGGGCGAACAGGCCCATGAACAGGAAGCCCAGGATGTACAGGATGTACAGAAGCCCAGATGTTCCTAG |
| Protein Sequence | MWDPLLNEFPETVHGFRCMLAVKYLQLVEKTYSPDTLGYDLIRDLISVIRARNYVEATSRYNHFHARLEGTPPSQLRQPIFQPCCCPHCPRHQSKSMGEQAHEQEAQDVQDVQKPRCS |
| NCBI Accession | NP_690913.1 |
|---|---|
| Location | 306-1076 |
| Gene Name | V1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCCCATATTCCAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAAAGCATGGGCGAACAGGCCCATGAACAGGAAGCCCAGGATGTACAGGATGTACAGAAGCCCAGATGTTCCTAGAGGCTGTGAAGGCCCGTGTAAGGTCCAGTCTTTTGAGTCTAGACATGATGTCCAACACATAGGCAAAGTCATGTGTGTTAGTGATGTTACTCGTGGAACTGGGCTGACCCATCGAGTTGGTAAAAGGTTTTGTGTTAAGTCCGTCTATGTTCTGGGCAAGATTTGGATGGATGAGAACATCAAGACTAAGAATCACACGAATAGTGTTATGTTCTTCCTTGTTAGAGATCGTAGGCCCGTAGATAAGCCCCAAGACTTTGGTGAGGTGTTTAACATGTTTGATAATGAGCCCAGTACGGCGACTGTGAAGAACGTGCATCGTGATAGGTATCAGGTGCTCAGGAAGTGGCATGCTACTGTGACAGGTGGTCAATATGCATCGAAGGAGCAAGCTCTTGTGAAGAAGTTTATTAGGGTTAATAATTACGTTGTGTATAACCAGCAGGAGGCTGGCAAGTATGAAAACCACACTGAGAATGCTTTGATGTTGTACATGGCGTGTACTCATGCTTCTAACCCTGTGTATGCTACTTTGAAGATACGGATCTATTTTTATGATTCCGTAACAAATTAA |
| Protein Sequence | MSKRPADIIISTPASKVRRRLNFDSPYSSRAAAPIVRVTKAKAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVQHIGKVMCVSDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWHATVTGGQYASKEQALVKKFIRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | NP_690914.1 |
|---|---|
| Location | 1073-1477 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTCACGCACAGGGGCACCCATCACTGCAGCTCAGGCCAAGAATGGCGTGTTTATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAACCGAGCACCACAACCGGCCATTCCTAATGAACCACGACATCATAACAGTCCAAGTACAGTTCAATCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAACCTTCCGAATCTGGACGACCTTACAGCCTCGGACTGGTCATTTCTTAAGGGTATTTAGGACCCAAGTTTTGCAGTTTTTAAATAATTTTGCTGTAATTAGTATAAACAATGTAATTAGAGCAGTCGATCATGTATTATGGAATGTAGTAGCGCAAACAATTTATGTACAAAGTTCAAACATAATAAAATTCAATATTTATTAA |
| Protein Sequence | MDSRTGAPITAAQAKNGVFIWEITNPLYFKITEHHNRPFLMNHDIITVQVQFNHNLRKALGIHKCFLTFRIWTTLQPRTGHFLRVFRTQVLQFLNNFAVISINNVIRAVDHVLWNVVAQTIYVQSSNIIKFNIY |
| NCBI Accession | NP_690915.1 |
|---|---|
| Location | 1218-1622 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCGACCTTCATCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGCTAGCCAAGAAGGGGACCAGGCGTCGTCGCGTTGACCTAGACTGCGGCTGTTCATATTTCATCGCATTACGCTGCCACGGCTATGGATTCACGCACAGGGGCACCCATCACTGCAGCTCAGGCCAAGAATGGCGTGTTTATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAACCGAGCACCACAACCGGCCATTCCTAATGAACCACGACATCATAACAGTCCAAGTACAGTTCAATCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAACCTTCCGAATCTGGACGACCTTACAGCCTCGGACTGGTCATTTCTTAAGGGTATTTAG |
| Protein Sequence | MRPSSPSKAHSTQVPIKVQHRLAKKGTRRRRVDLDCGCSYFIALRCHGYGFTHRGTHHCSSGQEWRVYLGDNKSPVFQDNRAPQPAIPNEPRHHNSPSTVQSQPEESVGDTQMFSNLPNLDDLTASDWSFLKGI |
| NCBI Accession | NP_690916.1 |
|---|---|
| Location | 1525-2610 |
| Gene Name | C1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGACACGTACACACCAATTCCAAGTTAAAGCCAAAAATATCTTCCTCACTTATCCAAAATGCCCAATACCGAAAGAACAAATGCTAGAAATTCTGAAATCTATAAATTGCCCTTCTGATAAATTATTTATCAGAGTTTCACAGGAAAAACACCAAGATGGGAGCTTGCATATCCACGCGCTCATCCAATTCAAAGGTAAATCCCAGTTCAGAAACCCAAGACATTTCGATGTCACTCACCCTAATAACGCCACCCAATTCCACCCAAATTTCCAGGGAGCTAAGTCCAGCTCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTCGCTTTCAGATCGATGGAAGATCTGCTCGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCTTAAATGCGGGTTCGGCTGAAGCGGCATTAGCAATAATAAGGGAAAAACTCCCAAAAGATTTTATTTTTCAATATCATAATTTAAAATGTAATTTAGATAGGATTTTTACACCTCCGTTGGAGGTTTATGTTTCTCCTTTTTGTTCTTCTTCTTTTGATCAAGTTCCCGGAGAACTTGAGGAATGGGCTTCCGAGAACGTGGTGAGTGCCGCTGCGCGGCCATTGAGACCCATGAGTATTGTGGTAGAGGGTGATAGTCGAACAGGGAAGACCATGTGGGCTAGGTCGTTGGGTCCACACAATTATTTGTGTGGTCATCTAGACCTTAGCCCTAAGGTCTACAGTAATGACGCCTGGTACAACGTCATTGATGACGTCGATCCCCACTACCTAAAACACTTTAAGGAATTCATGGGGGCCCAAAGGGACTGGCAATCAAATACGAAATACGGAAAGCCAGTGCAAATTAAAGGTGGAATTCCCGCTATCTTCCTCTGCAATCCAGGACCGCATTCCAGCTATAAAGAGTTCTTGGATGAAGAGAAGAATTCCGCACTCAAAAATTGGGCTTTAAAGAATGCGACCTTCATCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGCTAGCCAAGAAGGGGACCAGGCGTCGTCGCGTTGA |
| Protein Sequence | MTRTHQFQVKAKNIFLTYPKCPIPKEQMLEILKSINCPSDKLFIRVSQEKHQDGSLHIHALIQFKGKSQFRNPRHFDVTHPNNATQFHPNFQGAKSSSDVKSYIEKDGDYIDWGRFQIDGRSARGGQQTANDAAAEALNAGSAEAALAIIREKLPKDFIFQYHNLKCNLDRIFTPPLEVYVSPFCSSSFDQVPGELEEWASENVVSAAARPLRPMSIVVEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPAIFLCNPGPHSSYKEFLDEEKNSALKNWALKNATFITLEGPLYSGSNQSAAQASQEGDQASSR |
| NCBI Accession | NP_690917.1 |
|---|---|
| Location | 2196-2453 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGAGCTTGCATATCCACGCGCTCATCCAATTCAAAGGTAAATCCCAGTTCAGAAACCCAAGACATTTCGATGTCACTCACCCTAATAACGCCACCCAATTCCACCCAAATTTCCAGGGAGCTAAGTCCAGCTCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTCGCTTTCAGATCGATGGAAGATCTGCTCGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCTTAA |
| Protein Sequence | MGACISTRSSNSKVNPSSETQDISMSLTLITPPNSTQISRELSPAPMSSPTSRRTVITSTGVAFRSMEDLLEEVNRQLMMLQQRP |
References More References in PubMed
| 1 |
Vo TTB, et al. Microorganisms. 2023 Dec 1;11(12):2907. doi: 10.3390/microorganisms11122907. PMID: 38138051 |
|---|---|
| 2 |
Xie Y, et al. Arch Virol. 2003 Oct;148(10):2047-54. doi: 10.1007/s00705-003-0153-2. PMID: 14551824 |
| 3 |
Maruthi MN, et al. Phytopathology. 2005 Dec;95(12):1472-81. doi: 10.1094/PHYTO-95-1472. PMID: 18943559 |
| 4 |
Ghosh D, et al. Virol J. 2025 Dec 21;23(1):20. doi: 10.1186/s12985-025-03005-0. PMID: 41423612 |
| 5 |
Khan ZA, et al. Arch Virol. 2017 Feb;162(2):561-565. doi: 10.1007/s00705-016-3096-0. Epub 2016 Oct 13. PMID: 27738844 |
| 6 |
Chromatin remodeling by HIRA and FAS2 restricts geminivirus pathogenesis in plants. Sultana S, et al. Virol J. 2026 Jan 19;23(1):39. doi: 10.1186/s12985-026-03068-7. PMID: 41555392 |
| 7 |
Diversity and distribution of begomoviruses infecting tomato in India. Reddy RV, et al. Arch Virol. 2005 May;150(5):845-67. doi: 10.1007/s00705-004-0486-5. Epub 2005 Feb 10. PMID: 15703846 |