Pepper huasteco yellow vein virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000839505.1 |
| Release date | 2015/2/12 |
| Submitter | Torres-Pacheco,I., Garzon-Tiznado,J.A., Herrera-Estrella,L., Rivera-Bustamante,R.F., Rivera-Bustamante,R. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
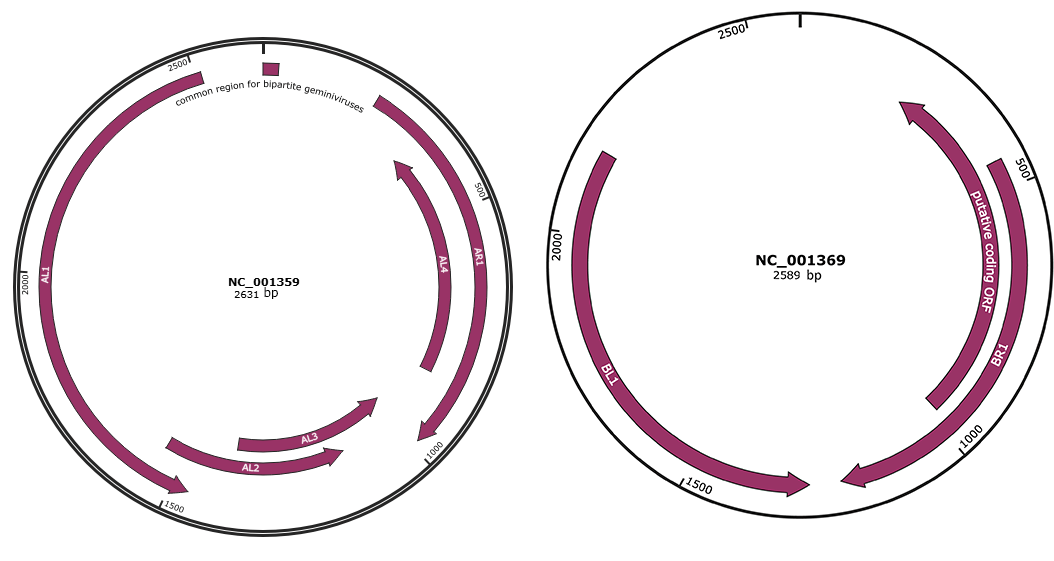
JBrowse
Genome
NC_001359
NC_001369
Gene Information
| NCBI Accession | NP_040320.1 |
|---|---|
| Location | 230-985 |
| Gene Name | AR1 |
| Protein Name | hypothetical protein |
| Coding Region | ATGCCTAAGCGTGATGCTCCTTGGCGATTAACGGCGGGGACCGCCAAGATTAGCCGAACTGGCAATAATTCACGGGCTCTTATCATGGGCCCGAGTACTAGCAGGGCCTCAGCTTGGGTTAATCGCCCAATGTACAGGAAGCCCCGGATTTATCGTATGTACAGAACTCCGGATGTGCCGAAAGGTTGTGAAGGTCCCTGTAAGGTTCAATCGTTTGAACAACGACATGACGTCTCTCATGTTGGTAAGGTTATTTGTATATCCGACGTAACTCGTGGTAATGGTATTACCCATCGTGTTGGCAAACGATTCTGCGTTAAGTCTGTCTATATTCTGGGCAAAATCTGGATGGATGAAAATATTAAGTTGAAGAACCATACCAACAGTGTCATGTTTTGGTTGGTTAGGGATAGGAGACCCTACGGTACGCCTATGGATTTTGGCCAAGTCTTTAACATGTATGACAACGAGCCCAGTACCGCTACTGTGAAGAACGATCTTCGGGATCGTTATCAAGTTATGCATAGATTCTATGCTAAGGTCACTGGTGGGCAATATGCAAGCAACGAGCAAGCCTTGGTTAGGCGTTTCTGGAAGGTGAACAACCATGTTGTGTATAACCATCAAGAAGCTGGGAAATATGAGAACCACACGGAGAATGCGCTGTTATTGTATATGGCATGTACTCATGCATCTAATCCCGTGTATGCAACACTCAAAATTCGGGTCTATTTTTATGACTCGATAATGAATTAA |
| Protein Sequence | MPKRDAPWRLTAGTAKISRTGNNSRALIMGPSTSRASAWVNRPMYRKPRIYRMYRTPDVPKGCEGPCKVQSFEQRHDVSHVGKVICISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRYQVMHRFYAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRVYFYDSIMN |
| NCBI Accession | NP_040321.1 |
|---|---|
| Location | 338-853 |
| Gene Name | AL4 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGTTATACACAACATGGTTGTTCACCTTCCAGAAACGCCTAACCAAGGCTTGCTCGTTGCTTGCATATTGCCCACCAGTGACCTTAGCATAGAATCTATGCATAACTTGATAACGATCCCGAAGATCGTTCTTCACAGTAGCGGTACTGGGCTCGTTGTCATACATGTTAAAGACTTGGCCAAAATCCATAGGCGTACCGTAGGGTCTCCTATCCCTAACCAACCAAAACATGACACTGTTGGTATGGTTCTTCAACTTAATATTTTCATCCATCCAGATTTTGCCCAGAATATAGACAGACTTAACGCAGAATCGTTTGCCAACACGATGGGTAATACCATTACCACGAGTTACGTCGGATATACAAATAACCTTACCAACATGAGAGACGTCATGTCGTTGTTCAAACGATTGAACCTTACAGGGACCTTCACAACCTTTCGGCACATCCGGAGTTCTGTACATACGATAAATCCGGGGCTTCCTGTACATTGGGCGATTAACCCAAGCTGA |
| Protein Sequence | MVIHNMVVHLPETPNQGLLVACILPTSDLSIESMHNLITIPKIVLHSSGTGLVVIHVKDLAKIHRRTVGSPIPNQPKHDTVGMVLQLNIFIHPDFAQNIDRLNAESFANTMGNTITTSYVGYTNNLTNMRDVMSLFKRLNLTGTFTTFRHIRSSVHTINPGLPVHWAINPS |
| NCBI Accession | NP_040322.1 |
|---|---|
| Location | 982-1380 |
| Gene Name | AL3 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGATTTACGCACCGGGGTACCCATCACTGCAGCTCAAGCAGCGAATGGCGTTTTTATCTGGGAGCTTCGAAATCCCCTATATTTCAAAATACGGCTAGTGGAGACGCCAATGTACACACGCAGCCGGGTATTTCACATTCAAGTCAGAGCAAACCACAACATGAGGACAGCGTTGGGTCTCCACAAAGCCTACTTCAACTTCCAAGTCTGGACGACGTTGACGACGATTTCTGGGCAGATTTACTTAAATAGATTTAAATTGCTTGTCATGTTTTATCTAGATAACTTAGGTCTTATTTCAGTTAACAATGTAATTAGGGCTGTTTCGTTTGCTACAGACAAACGTTATGTCAATGCTGTACTTGAGAATCATGAAATAATATACAAACTTTATTAA |
| Protein Sequence | MDLRTGVPITAAQAANGVFIWELRNPLYFKIRLVETPMYTRSRVFHIQVRANHNMRTALGLHKAYFNFQVWTTLTTISGQIYLNRFKLLVMFYLDNLGLISVNNVIRAVSFATDKRYVNAVLENHEIIYKLY |
| NCBI Accession | NP_040323.1 |
|---|---|
| Location | 1127-1543 |
| Gene Name | AL2 |
| Protein Name | hypothetical protein |
| Coding Region | ATGACTGGGTCCAAAAAAACGCCATCTACGTCACCATCGAAGAAGCTATCTTCACCACCGGAAGTCAAACTTCGCCATAGATTTGCAAAGAGACAGATACGACGTAGAAGGATTGATCTCGCTTGCGGCTGTTCAATTTATATACATATTAACTGTGTTAACAATGGATTTACGCACCGGGGTACCCATCACTGCAGCTCAAGCAGCGAATGGCGTTTTTATCTGGGAGCTTCGAAATCCCCTATATTTCAAAATACGGCTAGTGGAGACGCCAATGTACACACGCAGCCGGGTATTTCACATTCAAGTCAGAGCAAACCACAACATGAGGACAGCGTTGGGTCTCCACAAAGCCTACTTCAACTTCCAAGTCTGGACGACGTTGACGACGATTTCTGGGCAGATTTACTTAAATAG |
| Protein Sequence | MTGSKKTPSTSPSKKLSSPPEVKLRHRFAKRQIRRRRIDLACGCSIYIHINCVNNGFTHRGTHHCSSSSEWRFYLGASKSPIFQNTASGDANVHTQPGISHSSQSKPQHEDSVGSPQSLLQLPSLDDVDDDFWADLLK |
| NCBI Accession | NP_040324.1 |
|---|---|
| Location | 1464-2513 |
| Gene Name | AL1 |
| Protein Name | hypothetical protein |
| Coding Region | ATGCCATTACCTAAACGATTTCGTTTAAATGCCAAGAATTATTTCCTCACCTATCCACAATGTTCCATTTCCAAAGAAGAGCGTCTCGCTCAACTACAAAACCTCTCGACGCCGGTAAACAAGAAGTACATCAAAATTTGCAAAGAATCTCATGAAGATGGGCAACCTCATCTGCACGTGCTTATTCAGTTCGAAGGAAAATACCAATGCACGAACAACCGATTCTTTGACCTCGTATCCTCTACCAGATCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAGACGTACATCGACAAAGACGGCGATACCGTAGAATGGGGAGAATTCCAAATAGACGGCAGATCTGCTAGAGGAGGACAGCAGTCTGCTAATGACACATATGCTAAGGCGTTAAATTCAGCATCTGCAGAAGAAGCTCTGCAGATCATAAAGGAAGAACAACCTCAGCATTTCTTCCTCCAATTTCATAACATTGTGTCAAACGCTAATCGGATATTCCAAACTCCCCCGGAACCGTGGGTTCCTCCATTTCAACAGGCGTCCTTTAATAATGTGCCTGCAATAATGACACAATGGGTGTCTGATAATGTATGTGATGCCGCTGCGCGGCCAATGAGACCATTGTCATTAGTGGTCGAGGGTCCTTCACGGACAGGCAAAACATTATGGGCCCGAAGTCTCGGCCCACACAATTACATATGTGGTCATATGGATCTCAGCCCAAAAATCTACTCCAATAATGCATGGTATAACGTCATTGATGACATCCCTCCGCATTATGTTAAGCACTTTAAAGAGTTTATGGGGGCCCAACGGGATTGGCAATCAAACTGCAAATACGGCAAACCAATTCAAATTAAAGGTGGGATACCCACTATCTTTCTTTGCAATCCGGGCCCCCAGTCTTCCTATAAAGACTACCTCAGCGAAGAGAAAAATAGGAGCCTCAATGACTGGGTCCAAAAAAACGCCATCTACGTCACCATCGAAGAAGCTATCTTCACCACCGGAAGTCAAACTTCGCCATAG |
| Protein Sequence | MPLPKRFRLNAKNYFLTYPQCSISKEERLAQLQNLSTPVNKKYIKICKESHEDGQPHLHVLIQFEGKYQCTNNRFFDLVSSTRSAHFHPNIQGAKSSSDVKTYIDKDGDTVEWGEFQIDGRSARGGQQSANDTYAKALNSASAEEALQIIKEEQPQHFFLQFHNIVSNANRIFQTPPEPWVPPFQQASFNNVPAIMTQWVSDNVCDAAARPMRPLSLVVEGPSRTGKTLWARSLGPHNYICGHMDLSPKIYSNNAWYNVIDDIPPHYVKHFKEFMGAQRDWQSNCKYGKPIQIKGGIPTIFLCNPGPQSSYKDYLSEEKNRSLNDWVQKNAIYVTIEEAIFTTGSQTSP |
| NCBI Accession | NP_040354.1 |
|---|---|
| Location | 447-1217 |
| Gene Name | BR1 |
| Protein Name | BR1 protein |
| Coding Region | ATGTATTCTACTAGATTTAGACGTGGGTTATCCTATGTTCCACGGCGTTATAATCCACGTAATTATGGTTTTAAACGTACATTCGTCGTTAAACGTGGTGATGCTAAACGACGTCAGACTCAAGTGAAGAAACTAACAGAAGATGTTAAAATGTCATCACAACGCATCCATGAAAATCAATATGGTCCAGAATTTGTCATGGCGCATAATACAGCAATATCTACATTCATCAATTATCCCCAACTGTGTAAGACTCAGCCCAATCGTAGTAGGTCATATATTAAGTTAAAATCGTTACATTTTAAGGGAACCTTAAAGATCGAACGTGTTGGGTCTGAGGTAAATATGGCTGGGTTAAATCCGAAGATTGAGGGTGTGTTTACTGTGGTTTTAGTTGTTGACCGTAAGCCACATTTGAATCCTACTGGTAACTTGCTACAGTTTGACGAGTTATTTGGTGCAAGAATTCACAGTCTAGGGAACTTAGCCGTTACCCCGGCGTTGAAAGAACGGTTCTACATACTGCATGTGTTGAAGCGAGTTATCTCCGTTGAGAAGGATAGTATGATGCTGGACCTAGAAGGATCCACTTGTCTCTCTAGTCGGCGTTATAATTGTTGGTCTACATTTAAGGACCTTGATCCTTCGTCATGTAACGGCGTCTATGATAATATAAGCAAAAACGCCATATTAGTTTATTATTGTTGGATGTCGGATGCTATGTCTAAGGCATCCACATTTGTATCATTTGATTTGGACTATTTTGGTTAA |
| Protein Sequence | MYSTRFRRGLSYVPRRYNPRNYGFKRTFVVKRGDAKRRQTQVKKLTEDVKMSSQRIHENQYGPEFVMAHNTAISTFINYPQLCKTQPNRSRSYIKLKSLHFKGTLKIERVGSEVNMAGLNPKIEGVFTVVLVVDRKPHLNPTGNLLQFDELFGARIHSLGNLAVTPALKERFYILHVLKRVISVEKDSMMLDLEGSTCLSSRRYNCWSTFKDLDPSSCNGVYDNISKNAILVYYCWMSDAMSKASTFVSFDLDYFG |
| NCBI Accession | NP_597687.1 |
|---|---|
| Location | 1277-2158 |
| Gene Name | BL1 |
| Protein Name | BL1 protein |
| Coding Region | ATGGATTCATGGTTGGCGAATCCTCCTAGCGCATTCAATTATATAGAGTCACATAGAGATGAATATCAGCTCTCTCATGACTTAACGGAGATAATACTTCAATTTCCGTCAACGGCGTCGCAGTACGCTGCCAGACTTAGTCGTAGCTGTATGAAAATTGACCATTGCGTTATCGAGTATAGACAGCAAGTTCCGATAAACGCCACTGGGTCGGTCATAGTGGAAATCCATGACAAACGAATGACAGACAATGAATCATTACAAGCTTCTTGGACATTTCCACTAAGATGTAACATCGATCTCCATTATTTCTCAGCATCCTTCTTCTCCTTGAAGGACCCCATACCCTGGAAGCTATATTACAGAGTCTCCGATACTAACGTACATCAGAACACCCATTTTGCCAAGTTCAAAGGGAAATTGAAGTTGTCCACAGCTAAACACTCCGTGGATATACCTTTCCGGGCTCCGACGGTGAAGATTTTATCGAAACAGTTCACCCATAACGATGTGGACTTTACACATGTGGACTACGGCAGGTGGGAGAGAAAACCATTGAGGTCAGCATCCATGTCAAGGTTCGGCATTACAGGCCCAATTGAATTAAAACCAGGTGAATCCTGGGCTTGTAGAAGCACCATAGGAACCACTCACACAGATGCTGACAACCAAGGACATAGCGCATTACATCCGTATAAAGATCTTCATCAGTTAGGCGGAAGTGTTTTGGACCCAGGTGATTCAGCATCACAAGTGGGTCTAACACGCTCTCAATCAAATATAACTATGTCCTTGGCCCAGTTGAATGAGCTTGTAAGGACTACGGTCCATGAATGTATTAACAGTAATTGTAATCCGACACAACCGAAGTCGCTAAGATAA |
| Protein Sequence | MDSWLANPPSAFNYIESHRDEYQLSHDLTEIILQFPSTASQYAARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPLRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQNTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTHNDVDFTHVDYGRWERKPLRSASMSRFGITGPIELKPGESWACRSTIGTTHTDADNQGHSALHPYKDLHQLGGSVLDPGDSASQVGLTRSQSNITMSLAQLNELVRTTVHECINSNCNPTQPKSLR |
References More References in PubMed
| 1 |
Rivero-Montejo SJ, et al. Plant Physiol Biochem. 2023 Oct;203:108074. doi: 10.1016/j.plaphy.2023.108074. Epub 2023 Oct 8. PMID: 37832367 |
|---|---|
| 2 |
Early and late gene expression in pepper huasteco yellow vein virus. Shimada-Beltrán H, et al. J Gen Virol. 2007 Nov;88(Pt 11):3145-3153. doi: 10.1099/vir.0.83003-0. PMID: 17947542 |
| 3 |
Commodity risk assessment of Petunia spp. and Calibrachoa spp. unrooted cuttings from Guatemala. EFSA Panel on Plant Health (PLH), et al. EFSA J. 2024 Jan 25;22(1):e8544. doi: 10.2903/j.efsa.2024.8544. eCollection 2024 Jan. PMID: 38273989 |
| 4 |
Superinfection by PHYVV Alters the Recovery Process in PepGMV-Infected Pepper Plants. Rodríguez-Gandarilla MG, et al. Viruses. 2020 Mar 5;12(3):286. doi: 10.3390/v12030286. PMID: 32151060 |
| 5 |
González-Pérez E, et al. Viruses. 2024 May 31;16(6):888. doi: 10.3390/v16060888. PMID: 38932180 |
| 6 |
Bañuelos-Hernández B, et al. Arch Virol. 2012 Sep;157(9):1835-41. doi: 10.1007/s00705-012-1358-z. Epub 2012 Jun 10. PMID: 22684489 |
| 7 |
Carrillo-Tripp J, et al. Phytopathology. 2007 Jan;97(1):51-9. doi: 10.1094/PHYTO-97-0051. PMID: 18942936 |
| 8 |
Mendoza-Figueroa JS, et al. Pestic Biochem Physiol. 2018 Feb;145:56-65. doi: 10.1016/j.pestbp.2018.01.005. Epub 2018 Feb 4. PMID: 29482732 |
| 9 |
Nava A, et al. Arch Virol. 2013 Feb;158(2):399-406. doi: 10.1007/s00705-012-1501-x. Epub 2012 Oct 14. PMID: 23064695 |
| 10 |
A New Begomovirus Causes Tomato Leaf Curl Disease in Baja California Sur, Mexico. Holguín-Peña RJ, et al. Plant Dis. 2005 Mar;89(3):341. doi: 10.1094/PD-89-0341A. PMID: 30795368 |