Pepper golden mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000842765.1 |
| Release date | 2015/2/12 |
| Submitter | Torres-Pacheco,I., Garzon-Tiznado,J.A., Brown,J.K., Becerra-Flora,A., Rivera-Bustamante,R.F., Mendez-Lozano,J., Fauquet,C.M. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
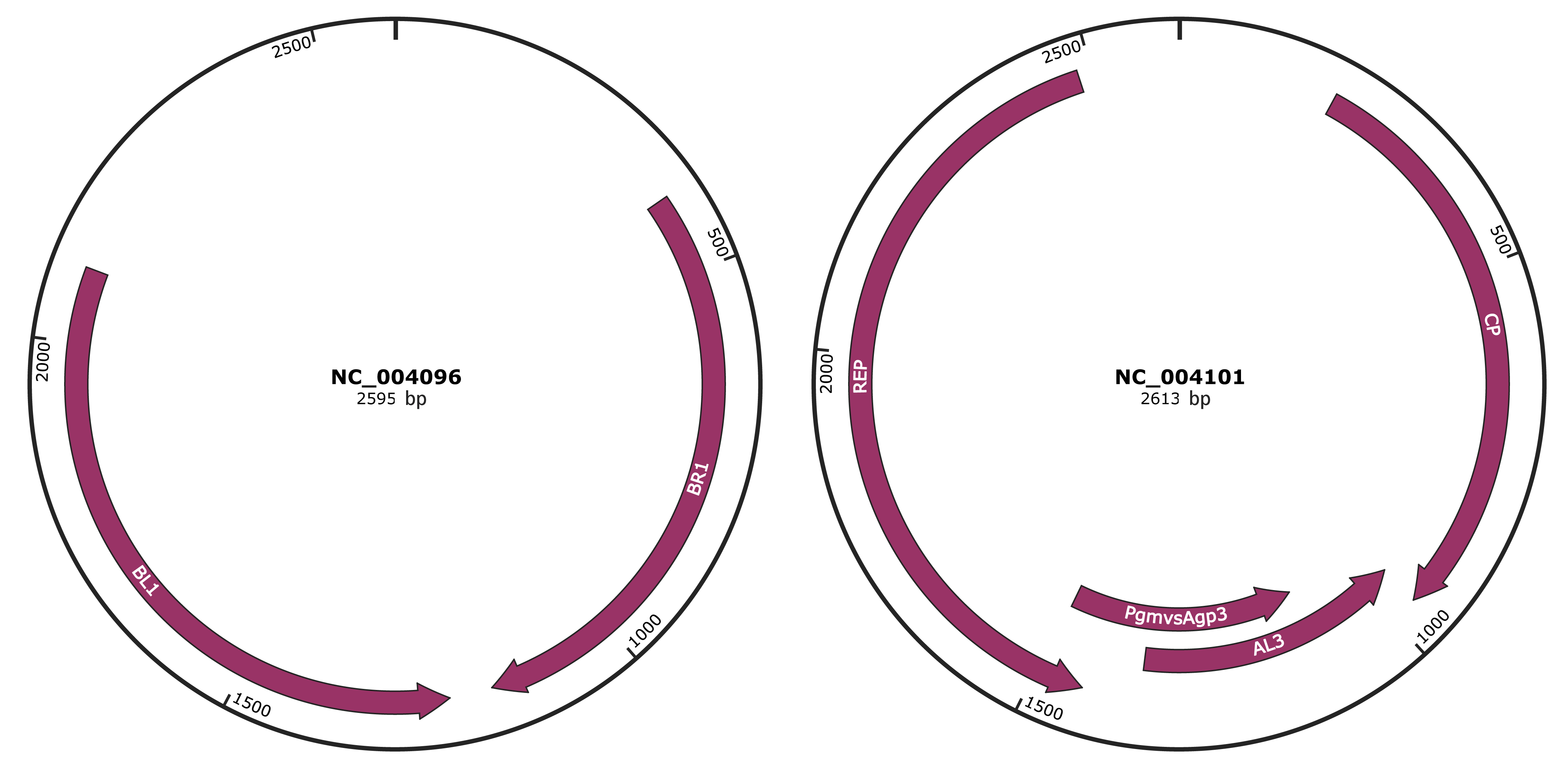
JBrowse
Genome
NC_004096
NC_004101
Gene Information
| NCBI Accession | NP_671456.1 |
|---|---|
| Location | 400-1170 |
| Gene Name | BR1 |
| Protein Name | nuclear shuttle |
| Coding Region | ATGTATCAGTCAAGGTATACACGTGTGGCACCCTATGTGCAGAGACGATTTCAACGACGTAATCAAGTGTTTAAGCGCACAGTATCAGGGAGACGTAATGACGTTAAACGTCGATCAAGTCAATTAATTAAGAGTAATGAGGAACCTAAGATTACGTCGCAGCGCATACATGAAAACCAATATGGCCCTGAGTTCGTTATGGCGCATAATGCAGCTATTTCCACGTTCATTAATTATCCTGTACTTGGTAAGACTCAACCTAATCGAAGCAGGTCGTATATTAAGCTTAAACGTTTATCGTTTAAGGGAACCGTTAAGATTGAACGTGTGCATGCTGACGTGAACATGGACGGGGTCTGTCCTAAAATTGAAGGCGTCTTCTCACTGGTTATTGTGGTTGATCGTAAACCACATTTAAGTTCGTCTGGGGTGTTGCATACATTTGATGAAGTATTCGGTGCAAGAATCCACAGCCATGGGAACTTAGCCATTACAACATCTTTGAAAGATCGGTATTACGTCCGGCATGTATTGAAGCGCGTATTGTCAGTTGAGAAGGACACTGTCATGGTAGATATCGAAGGATGCACATCCCTTTCTAACAAGCGCTTCAACTGCTGGTCTACATTTAAGGATTTAGAACATGACACATGTAACGGTGTTTATGCGAATATAAGCAAGAATGCCATATTAGTTTACTATTGCTGGATGTCGGATGTCATGTCTAAAGCATCCACATTTGTATCATATGACCTAGAATATGTAGGGTGA |
| Protein Sequence | MYQSRYTRVAPYVQRRFQRRNQVFKRTVSGRRNDVKRRSSQLIKSNEEPKITSQRIHENQYGPEFVMAHNAAISTFINYPVLGKTQPNRSRSYIKLKRLSFKGTVKIERVHADVNMDGVCPKIEGVFSLVIVVDRKPHLSSSGVLHTFDEVFGARIHSHGNLAITTSLKDRYYVRHVLKRVLSVEKDTVMVDIEGCTSLSNKRFNCWSTFKDLEHDTCNGVYANISKNAILVYYCWMSDVMSKASTFVSYDLEYVG |
| NCBI Accession | NP_671457.1 |
|---|---|
| Location | 1227-2096 |
| Gene Name | BL1 |
| Protein Name | viral movement protein |
| Coding Region | ATGGAAGCGGGGTTGGCGAGTGCTCCTAGCGCCTTTAATTATCTTGAATCTCATAGAGATGAATACCAGCTGTCGCATGATCTGACKGAGATAGTCCTTCAGTTTCCTTCCACGGCATCACAGCTAACGGCACGACTAAGTCGCAGCTGTATGAAAATTGACCACTGCGTCATAGAATATAGACAGCAGGTTCCGATTAACGCCTCTGGGTCGGTCATTGTGGAGATTCATGACCAAAGAATGACGGATAACGAGTCATTACAAGCATCTTGGACATTTCCAATACGATGCAACATAGACCTACATTACTTCTCGTCGTCATTCTTTTCACTGAAGGACCCCATTCCATGGAGATTATACTACCGAGTGTCCGACACAAATGTACATCAAAGGACTCATTTTGCCAAGTTCAAAGGCAAGCTAAAACTCTCAACAGCTAAGCACTCGGTAGATATACCATTCCGGGCTCCCACTGTCAAAATACTATCTAAACAATTCTCCCATAACGATGTGGACTTCTCCCATGTGGACTATGGCCAGTGGGAGCGCAAAGTCTTACGGTCCAATTCAATGTCAAGGGTTGGGCTTACAGGCCCAATTGAATTGAGGCCAGGTGAGTCATGGGCTTCCAGGAGCACCGTGGGTACAAGTAGTCCTTCAAGGGATTCGAAGATGCACCCCTATAGAGAGCTTCATCAATTGGGCCCAAGCGTATTAGACCCAGGTGATTCCGCATCACAGGTTGGTCTACAAAGAGCCCACTCCAATATAACAATGTCAATGGCCCAATTGAACGAACTTGTTAGGACTACGGTTCACGAATGTATTAGTAACAATTGTAACCCGGCACAGCCGAAGTCTTTGCAATAA |
| Protein Sequence | MEAGLASAPSAFNYLESHRDEYQLSHDLTEIVLQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINASGSVIVEIHDQRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWRLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSHNDVDFSHVDYGQWERKVLRSNSMSRVGLTGPIELRPGESWASRSTVGTSSPSRDSKMHPYRELHQLGPSVLDPGDSASQVGLQRAHSNITMSMAQLNELVRTTVHECISNNCNPAQPKSLQ |
| NCBI Accession | NP_671472.1 |
|---|---|
| Location | 208-963 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGGTTAAGCGGGATGCCCCATGGCGTTTAATGGCGGGGACCTCTAAGGTTTCCGGCTCTGCGAATTATTCACGTGGCACGGGTATGGGGCCTAAATTCGATAAGGCCGCTGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGTATATATCGTACGTATAGAAGCCCAGATGTGCCTAGASSATGTGAAGGGCCATGTAAGGTCCAGTCCTTCGAGCAGCGGCATGATATCTCGCATGTTGGCAAGGTCATGTGCATTTCTGACGTGACACGTGGTAATGGTATTACCCATCGTGTAGGCAAGCGTTTCTGCGTCAAGTCTGCATACGTTCTGGGTAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACCAACAGCGTCATGTTCTGGCTCGTGAGAGATAGGAGACCATATGGTACCCCTATGGACTTTGGTCAGGTGTTCAACATGTATGACAACGAGCCCAGTACAGCTACTGTGAAGAACGATTTGCGTGATCGTTTCCAAGTCATGCACAGGTTCTCGGCTAAGGTCACAGGTGGACAGTATGCCAGCAACGAGCAGGCATTGGTTAGGCGTTTCTGGAAGGTGAACAACTACGTCGTGTACAACCATCAGGAAGCTGGCAAATACGAGAATCATACTGAGAACGCCCTGCTATTGTATATGGCATGTACACATGCCTCTAACCCTGTGTACGCGACATTGAAAATTCGAATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MVKRDAPWRLMAGTSKVSGSANYSRGTGMGPKFDKAAAWVNRPMYRKPSIYRTYRSPDVPRXCEGPCKVQSFEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSAYVLGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRFQVMHRFSAKVTGGQYASNEQALVRRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | NP_671473.1 |
|---|---|
| Location | 960-1358 |
| Gene Name | AL3 |
| Protein Name | AL3 protein |
| Coding Region | ATGGATTCACGCACAGGGGAGAGCATCACTGTGCATCAGGCAGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTATTTTTCAGGATACAGCACGTGGAGGACCCGTTGTTCACCAGAACCAGGATATACCACATCGTAGTCCGGTTCAACCACAACCTACGTCGAGCATTAGCTCTCCACAAGGCATTCCTCCATTTCCAAGTCTGGACGACTTCGATGACAGCTTCTGGGACGACATATTTAAGTAGATTCAAATTTCGCGTCATGTTGTATTTACATACGCTAGGGGCCATAGGCATAAACAATGTAATCAGAGCTGTTCGTTTTGCGACGGACAAATCCTATGTAAATTATGTACTTGAGAATCATGAAATAAAATGCAAACTTTATTAA |
| Protein Sequence | MDSRTGESITVHQAENSVFIWEVPNPLFFRIQHVEDPLFTRTRIYHIVVRFNHNLRRALALHKAFLHFQVWTTSMTASGTTYLSRFKFRVMLYLHTLGAIGINNVIRAVRFATDKSYVNYVLENHEIKCKLY |
| NCBI Accession | NP_671474.1 |
|---|---|
| Location | 1105-1494 |
| Protein Name | trap |
| Coding Region | ATGCTCAATTCGTCATCCTCCACGCTCCCCTCTATAAAAGCACAGCACAGGATAGCTAAGAAGCGACCTATTCGCAGACGACGCATAGACCTAAACTGCGGCTGCTCTATCTTTCTCCACATCAACTGCGCTAATAATGGATTCACGCACAGGGGAGAGCATCACTGTGCATCAGGCAGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTATTTTTCAGGATACAGCACGTGGAGGACCCGTTGTTCACCAGAACCAGGATATACCACATCGTAGTCCGGTTCAACCACAACCTACGTCGAGCATTAGCTCTCCACAAGGCATTCCTCCATTTCCAAGTCTGGACGACTTCGATGACAGCTTCTGGGACGACATATTTAAGTAG |
| Protein Sequence | MLNSSSSTLPSIKAQHRIAKKRPIRRRRIDLNCGCSIFLHINCANNGFTHRGEHHCASGREFRFYLGGSKSPIFQDTARGGPVVHQNQDIPHRSPVQPQPTSSISSPQGIPPFPSLDDFDDSFWDDIFK |
| NCBI Accession | NP_671475.1 |
|---|---|
| Location | 1436-2482 |
| Gene Name | REP |
| Protein Name | Rep |
| Coding Region | ATGCCACTACCACCAAAATCCTTTCGTTTACAATGTAAAAACATTTTCTTAACATATCCACAATGCGATATCCCAAAGGATGAAGCTCTCGAAATGCTCCGTAATTTAAAATGGGCAGTGGTAAAACCCATCTATCTCCGGGTATCACGAGAGGAGCATTCCGATGGGTTCCCGCACTTGCACTGTCTAATCCAGTTGACTGGAAAATGCAACATCAAAGATGCCCGGTTCTTCGACATTACTCACCCCCGGAGATCTGCCCAGTTTCATCCAAACGTTCAGGCATCCAAGGACGCAAATGCCGTTAAAAATTACATAACAAAAGATGGTGATTATTGTGAATCTGGGCAGTACAAAGTTTCCGGGGGGTCAAAAGCAAATAAAGACGACGTCTACCATAACGCTGTAAATGCTGCAAGTGCGGGGGAGGCGCTCGACATAATCAAAGCTGGTGATCCGAAAACGTTCATTGTTAGTTATCATAACATAAAGGCTAACATCGAGCGCCTATTTACAACTCCTCCTATGCCATGGACTCCTCCTTATCCATTATCCTCGTTTAACAACGTTCCTGAGGATATGCAACATTGGGTTGCTGAATATTTTGGTCGGAGTTGTGCGCGGCCAGATAGACCGATTAGTATTGTCATTGAGGGTGATTCGCGATGCGGCAAGACAATGTGGGCACGTGCACTAGGCCCACATAATTATTTGAGCGGTCATCTTGATTTCAATGCAAAGGTCTATTCAAACTATGTGGAGTATAACGTCATTGATGATATCACGCCCCAATATCTAAAGATGAAACACTGGAAAGAGCTTATTGGGGCCCAAAAAGACTGGCAGTCCAACTGTAAATACGGAAAGCCAGTTCAAATTAAAGGCGGGATACCATCAATCGTGCTGTGCAATCCAGGGGAAGGTAGCAGCTATATAGCTTTCCTCAACAAAGAGGAAAATGCAGAATTAAGAGCGTGGACATTAAAAAATGCTCAATTCGTCATCCTCCACGCTCCCCTCTATAAAAGCACAGCACAGGATAGCTAA |
| Protein Sequence | MPLPPKSFRLQCKNIFLTYPQCDIPKDEALEMLRNLKWAVVKPIYLRVSREEHSDGFPHLHCLIQLTGKCNIKDARFFDITHPRRSAQFHPNVQASKDANAVKNYITKDGDYCESGQYKVSGGSKANKDDVYHNAVNAASAGEALDIIKAGDPKTFIVSYHNIKANIERLFTTPPMPWTPPYPLSSFNNVPEDMQHWVAEYFGRSCARPDRPISIVIEGDSRCGKTMWARALGPHNYLSGHLDFNAKVYSNYVEYNVIDDITPQYLKMKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYIAFLNKEENAELRAWTLKNAQFVILHAPLYKSTAQDS |
References More References in PubMed
| 1 |
Genetic and Phenotypic Variation of the Pepper golden mosaic virus Complex. Brown JK, et al. Phytopathology. 2005 Oct;95(10):1217-24. doi: 10.1094/PHYTO-95-1217. PMID: 18943475 |
|---|---|
| 2 |
Vargas-Salinas M, et al. 3 Biotech. 2021 Mar;11(3):114. doi: 10.1007/s13205-021-02653-7. Epub 2021 Feb 3. PMID: 33604230 |
| 3 |
Méndez-Lozano J, et al. Plant Dis. 2001 Dec;85(12):1291. doi: 10.1094/PDIS.2001.85.12.1291A. PMID: 30831814 |
| 4 |
Trejo-Saavedra DL, et al. Biol Res. 2013;46(4):333-40. doi: 10.4067/S0716-97602013000400004. PMID: 24510135 |
| 5 |
Méndez-Lozano J, et al. Phytopathology. 2003 Mar;93(3):270-7. doi: 10.1094/PHYTO.2003.93.3.270. PMID: 18944336 |
| 6 |
Pepper golden mosaic virus Affecting Tomato Crops in the Baja California Peninsula, Mexico. Holguín-Peña RJ, et al. Plant Dis. 2004 Feb;88(2):221. doi: 10.1094/PDIS.2004.88.2.221A. PMID: 30812435 |
| 7 |
Carrillo-Tripp J, et al. Phytopathology. 2007 Jan;97(1):51-9. doi: 10.1094/PHYTO-97-0051. PMID: 18942936 |
| 8 |
Méndez-Lozano J, et al. Plant Dis. 2006 Jan;90(1):109. doi: 10.1094/PD-90-0109B. PMID: 30786488 |
| 9 |
Castro RM, et al. Plant Pathol J. 2013 Sep;29(3):285-93. doi: 10.5423/PPJ.OA.12.2012.0182. PMID: 25288955 |
| 10 |
Méndez-Lozano J, et al. Plant Dis. 2006 Jul;90(7):972. doi: 10.1094/PD-90-0972B. PMID: 30781046 |