Asystasia mosaic Madagascar virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000943705.1 |
| Isolate |
Madagascar |
| Release date |
2015/3/4 |
| Submitter |
De Bruyn,A., Harimalala,M., Ranomenjanahary,S., Reynaud,B., Lefeuvre,P., Lett,J.-M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
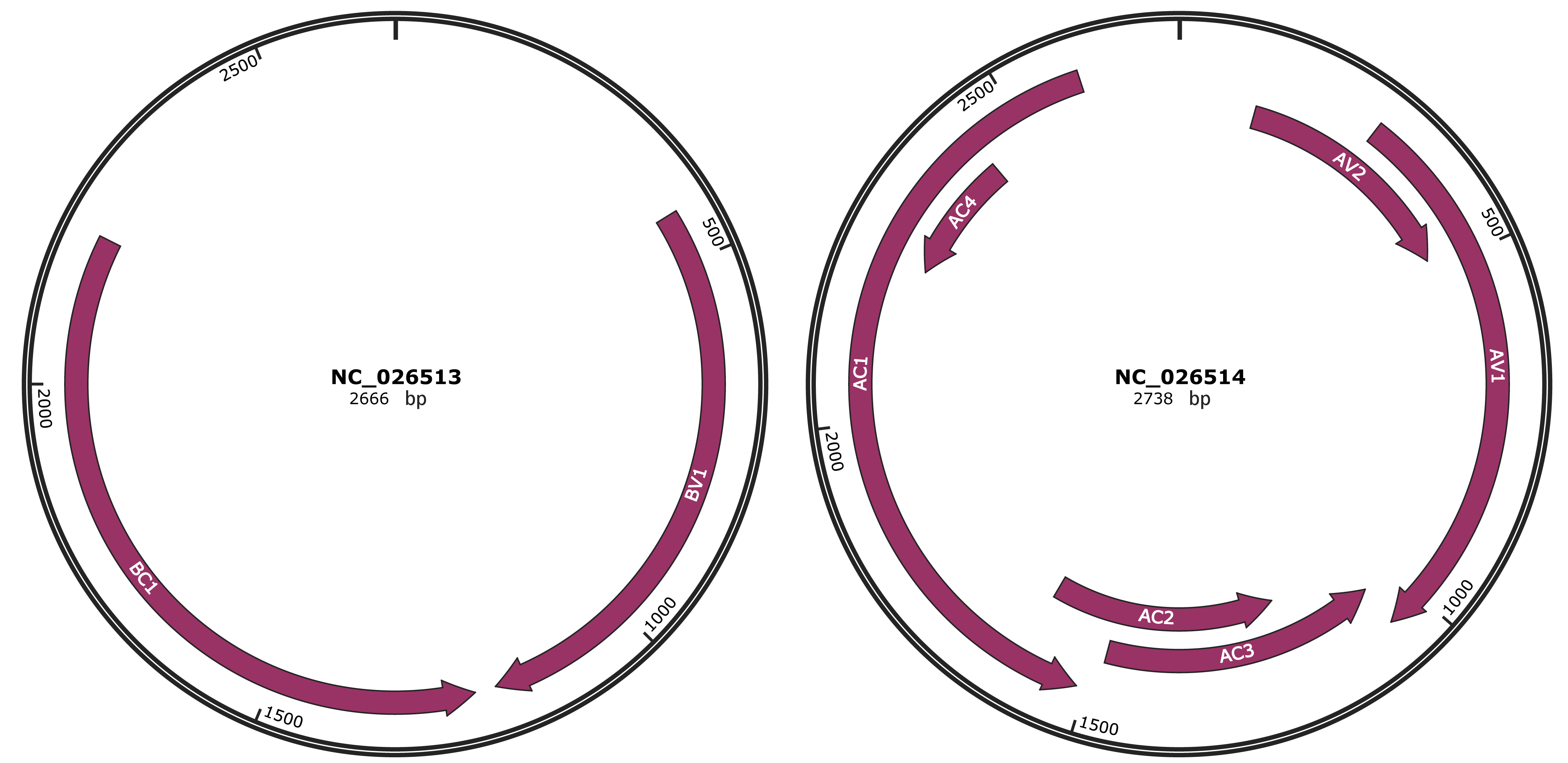
JBrowse
Genome
ACCGGGGGCGCCGATTTTTTTGGTGGAACGTGGGCCCCACATGCCAGCTGTCATAATCTCAGCCATACGATCATGTATCCGTTGTACAAGATATTTTTGTAGTATGAATGATTACGTGGGGCCCACACATCTGCACAGTAATTTCCTTATGCATTTTTATGCATTTTTAGTGCGCGTACGATCATTCTGACATGCCACGTGGGTATACTGTTCACACTATGACTGGTCAACAATTGCGGCTGAAATGTCCATAAGAGGGGTTATTTTCAGTTAAGAGCTACTCAAGTATTATAAATCTGTATGATAACAGTATCCGTCTAAATGTCTCTTGAAAATATTATAGTGTGGTATATTTTCTTCAGTATTGTCTTCTTCTTGTATTCCTTCTTATTTGCATTGTCTTTGCTCTTCAAGACAATATTTTCATGAGACATGTATTCCTCTGCCAGACGTTCAGTTAGGACACCGTATAGGGCTTTCTCTGTTAGGAAGACTGCTCGCAAGTCTGTGGCATTCTCATCTACTAAGCCTCCTGTTAATCGGGCTTTGTCATATGAATCATCGAAAAAGACCTATGTTTCCAGGACTATAGAAGATGTCCATTCTGGCCAGAGTCTTCAACTTAGTCAACAGTCCGATTACACCTCGTTTGTTAGCTTTCCGTCATTGTCTCACGATGGATCGTTCGGGAGATCCTTCGACCATATCAAGCTCATGAGTATCCGTGTGTCGGGTACTATACAAGTCAGCTGTGTAAATTCAGACGATCCTATGGGTGTATCTCCCCAGTTCAATGGAATATTTATGTTGAGTATTATATGCGACAAGAGACCATTCGTCCCTGATGGTGTGACCACTCTCCCTAAGTTTCAAGAGTTGTTTGGGAGTTATGAGTCTGTGTATGGTAGTCCTCGTTTGAAGGACAATGTCCGACATAGGTATAGGCTTCTAGGTCATGTTAAGAAGTATATATCTTCGGATAAGACACATGTCCAGGTCCCCTTTTTTTTTAGAAGACGCATAAGCTCGAGGAAATATCCAATATGGTCCTCGTTTAAAGACCCTGAGTCATCTCAGACCGGAGGGAATTACAAGAACATATCGAAGAATGCGTTAATTATTAGTTGTGTCTGGGTGTCTGTTCAAAACAGTAATTGTAGTGTGTACTCACAGAATGTATTGCACTATGTGGGATGATGTTATTGAGAAATGAATATAATACATTCTACAAATGTTTATTACTCTCTGTTTTATTCCTAATAAGACATTTGTTTATTGCATCCTCCACTATACTCTGGATGTCTCCCCTTGTCATTGTTGTGGACATTGTTTCGGATATCGAATCACCCGGGTCAATGGCTGATGCGTCGAGCCGTCTGAGACCTGCATATGGATATTCTCTCGACCTACTCGATCCTTCCTCGTTGTTGGCGCTTGTCTCGCCATCGTATTCGGCACGGGGCATTCTCATGGACCTGCTTCGTAATGTATCGCGTGTTAATTGGGCCGGCCCAGTAGATAAGCCCAGTTGTGACTTAGTGGCCCATGTCTCCCCTGGTAATATAGTTATGGGCCTTGGTATTATGGACCCTTGCTTGTGGGCCGTTGGTGTTGGGTTTAGCAGTCTGCGTCTGGGCTCGCCTTTCTCCACTGACCAAAAGTCCACACAAGACTTGTCAAAGCCCTTTGATAAAATGTTAATTGTTGGTGGTTTAAACCTAATGTCAGTGGAGTGTCTAGCAGAAGATAATCTCAGTTTCGCCTTAATTGAAGCGAACTTTACTCCTTGTAACACGTTTGAGTCTTCAACTTTGTATATGATCTCCCAGGGTGATTCTTCTGCTACAGAGAAGAAGGATGATGAGAAATAGTGTAGATCTACGTTACAGTCTATGGGGAAAGTAAATGCAGCCTGAGCTGCTTCCTCTTGGCTAACTCTGTTATCTCTGATCTCCACAATGACGGATCCGGTTGCGTTGAAAGGTACCTGATTTCTGTACTCAATAATTATGTGGTCGATTTTCATACATCGACCCATAAGTCTAACCCTAGTCTGCTCTAGACTGGACGGGAATTGCAGGTTAATTCTCGTAGCATCGTTTGTCAGGTTGTACTCTGCTCGTTTCGAGTCTATGTACTTGTTATTGACGACTGTGTAACTGTGTTCCATGTTAATTTCTGCAGAAAACACAGACATATATAATTATATTGAGAAACCCAGGCCGCGCAGCGGGAATTTCCTAAAATTATGAAGATAAATCGCTAATGATGTGCAAGAAATGCTTAATTACATTTAAAGAGAAGTTAATCAACTTAAGACACTTTCTAGAAAGCTAATTACTTACCTGTACGTATGCTGATAACTGATGAATATGTGTTTTAATAATAGGCAGATGTGTGCTATGGTGTTATTTATAAGGAATATTCGCATATAAAACGAGTTAAAACGAGTTATATTTCTAGAGAGAGAAAGTAGAGAGAGAAGCTCTGGAGGTTCCTCCAATCTGGTGGACACATTAAAATCCTAGTCATCGGTGGAACGGTGGACAATATATATGTGGGCTATAATGGGCTTTAAAAGCCTCTTTCTATTGGGCCTATTAAAGGCCCATTTACATGGGCCCAATTTCTTTTTTGGTCCACTAAGCGCCCCCGTATATAATATT
ACCGGATGGCCGCGCGCCCGGTGGACACCTTTACACGTGGATTCCACCAATGAGCATTCAGATAAGTGCTTTGCTTTCCGTATTTTTTGACTATATATGACGCTCCACTATTGTTTAATTGGTAAAGATGTGGGATCCACTTTGCAATGACTTCCCCTCCACGGTTCATGGATTCCGATGTATGTTGGCCACTAAATATCTTCTCGAGATTGAGAAGACATATGAGCCTAATTGTGTGGGCCAATTATTCATTAGGGATTTAATATCCGTCGTTCGCGCCCCTAATTATGTCGAAGCGACCAGGAGATATAATCATTTCCACACCCGCTTCAAAGGCACGACGTCGTCTCAACTTCGACAGCCCGCGTGTAGCTGCATCCTCTGTCCGCATCACCAGAAGGCAGGCATGGGTGAACAGGCCGATGTATCGCAAGCCCAGAATGTACCGCATGTGGCGGAGTTACGATGTTCCCAAGGGTTGTGAGGGTCCATGTAAGGTTCAATCATATGACCAGCGTGATGATGTTAAGCATGTAGGTGTTGTTAGATGTATATCCGATGTCACTAAAGGACCTGGGCTGACTCATCGTACAGGCAAACGTTTCACAGTGAAGTCAGTATATATATGTGGGAAGATATGGATGGATGAGAATATTAAGAAGCAGAATCATACTAATCATGTGTTGTTTTTCCTAACTAGAGATAGACGACCTTATGGTCAGGCGCCTATGGATTTTGGTCAAGTGTTTAACATGTTTGATAATGAACCTAGTACAGCTACGGTTAAGAATGATTTGCGAGATCGATTTCAGGTCCTGCGTCGGTTCTATGCTACTGTTGTTGGAGGTCCTTCGGGGATGAAAGAACAAGTCTTAGTTAGGCGTTTTTTTAAGCTTAACGCCCAGATTGTGTATAACCATCAGGATGGTGCTAAGTATGAGAACCATACAGAGAATGCTTTGTTGTTGTATATGGCATGTACACATGCTTCAAATCCTGTGTATGCTAGTCTGAAAGTTCGCATATATTTCTATGACAGCGTAAGCAATTAATAAATATTGAATTTTATTATGTGGTTTTCTTCTACATTGATGGTTCCATCGAGTACATTGTATAATACATAATCCACGCTATTAATACAAGTATTTATGCTTATAACTCCTAATGAGTTTAAGCGTTTCATGAAACTGTAATTAAAAACCCTCAAGAACCGAGATGTCGAACTCCTCAATCTCGTCCAGACCTTGAAGTTCAAATAACATTTGTGAATCCCTAAAGCCTTCCTCAGGTTGTGGTTGAACCTGATTTGGATGTTCAGTATGTCGTGGTTCGTGTTGAATGGTCTGTCGATGTGTTCTGTTATCGTTGTGTATATTGGATTCCTCAGTTCCCAGAAGTATATTCCACTCTGCGCTTGAGCTGCAGTGATGGATTCCCCTGTGCGAAAATCCATAATTGTTGCAGAGAGGATGTATGAGAACAGAACACCCACAGCCCAGATCTATCTTCTTTCTACGTTGCCTCTTCTTCTTGGCCTGTCTGTGCACTACTTTGATTGGCACAAGAGTAGAGAGGGTCGGAGATTGTGATGAAGGTCGCATTCTTTAAAGCCCACTGCTTCAGTCCTGCATTTTTGGGCTCATCGAGGAATTCTTTATAAGAGGACTGTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATACCACCTTTAATTTGAACTGGTTTCCCGTACTTGATATTGCTTTGCCAGTTGTGCTGGGCCCCCATGAACTCTTTGAAATGTTTCAGATAGTGCGGATCGACGTCATCAATGACGTTATACCAGGCATTATTGCTGTACACCTTATTTGACAAATCCAAATGGCCACACAAATAATTGTGAGGGCCCAATTGCCGGGCCCACATTGTCTTACCTGTCCTACTGGACCCCTCAATGACTATACTTTTGGGTCTTTGTGGCCGCGCAGCGGGACCCATGACATTTTCAGCTACCCACAGCTTCATCTCTTCTGGAACATTGGTGAAGCTTGCAGGTGTATATGGTGACTCGTATGGTACCCTCTTGGGTGCAAATATCTTATCCGCGTTTGCTGAAATGTTGTGGTACTGCAAGAAGTATGACTTGGGATCTCTTTCCTTGATCAATCTCATAGCAGCCTCTTTATTTGAGGCATTTAAAGCATCTGCGTATAGGTCTGCAAGGTTTTGCCCTTGACCCCTTGCGCTTCTTGCATCTATCTGGAATTCCCCATGGTCGATGAAGTCTCCTCCTTTCTCAATATATGTCTTGACATCTGACGAGCTCTTAGCTCCCTGAATGTTCGGATGGAAAGGTGTTGATCTGTTTGGGGAAACCAGGTCGAAGAATCTCTGATTTGTGCACTGGTATTTTCCTTCGAATTGTAATAGCACATGGAGATGAGGTTCCCCATTCTGGTGGAGTTCTCTGCAAACCCTAATGAATTTTATATTTACTGGTATTTGTTTGGCGAGAAGAAGAGATAGGGTTTCCTCTTTGCTCAGAGAGCATTGAGGATATGTGAGGAAGTAATTTTTGGCATTTATGTTGAATCTCCCTGCTCTCGGCATCTTGGGGATCAATCGGTGGGCACATTAAAATCCTATGTATTGGTGGAACGGTGGACAATTTATACTATGTCCACTAAATGGCATTTTGGTCATTTCTAAAAACCCCTTTAATTCAAAATCCCCATTAAAGCGGCCATCCCTATAATATT
Gene Information
|
NCBI Accession
|
YP_009121934.1
|
|
Location
|
433-1197 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTCCTCTGCCAGACGTTCAGTTAGGACACCGTATAGGGCTTTCTCTGTTAGGAAGACTGCTCGCAAGTCTGTGGCATTCTCATCTACTAAGCCTCCTGTTAATCGGGCTTTGTCATATGAATCATCGAAAAAGACCTATGTTTCCAGGACTATAGAAGATGTCCATTCTGGCCAGAGTCTTCAACTTAGTCAACAGTCCGATTACACCTCGTTTGTTAGCTTTCCGTCATTGTCTCACGATGGATCGTTCGGGAGATCCTTCGACCATATCAAGCTCATGAGTATCCGTGTGTCGGGTACTATACAAGTCAGCTGTGTAAATTCAGACGATCCTATGGGTGTATCTCCCCAGTTCAATGGAATATTTATGTTGAGTATTATATGCGACAAGAGACCATTCGTCCCTGATGGTGTGACCACTCTCCCTAAGTTTCAAGAGTTGTTTGGGAGTTATGAGTCTGTGTATGGTAGTCCTCGTTTGAAGGACAATGTCCGACATAGGTATAGGCTTCTAGGTCATGTTAAGAAGTATATATCTTCGGATAAGACACATGTCCAGGTCCCCTTTTTTTTTAGAAGACGCATAAGCTCGAGGAAATATCCAATATGGTCCTCGTTTAAAGACCCTGAGTCATCTCAGACCGGAGGGAATTACAAGAACATATCGAAGAATGCGTTAATTATTAGTTGTGTCTGGGTGTCTGTTCAAAACAGTAATTGTAGTGTGTACTCACAGAATGTATTGCACTATGTGGGATGA |
|
Protein Sequence
|
MYSSARRSVRTPYRAFSVRKTARKSVAFSSTKPPVNRALSYESSKKTYVSRTIEDVHSGQSLQLSQQSDYTSFVSFPSLSHDGSFGRSFDHIKLMSIRVSGTIQVSCVNSDDPMGVSPQFNGIFMLSIICDKRPFVPDGVTTLPKFQELFGSYESVYGSPRLKDNVRHRYRLLGHVKKYISSDKTHVQVPFFFRRRISSRKYPIWSSFKDPESSQTGGNYKNISKNALIISCVWVSVQNSNCSVYSQNVLHYVG |
|
NCBI Accession
|
YP_009121935.1
|
|
Location
|
1226-2197 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGTCTGTGTTTTCTGCAGAAATTAACATGGAACACAGTTACACAGTCGTCAATAACAAGTACATAGACTCGAAACGAGCAGAGTACAACCTGACAAACGATGCTACGAGAATTAACCTGCAATTCCCGTCCAGTCTAGAGCAGACTAGGGTTAGACTTATGGGTCGATGTATGAAAATCGACCACATAATTATTGAGTACAGAAATCAGGTACCTTTCAACGCAACCGGATCCGTCATTGTGGAGATCAGAGATAACAGAGTTAGCCAAGAGGAAGCAGCTCAGGCTGCATTTACTTTCCCCATAGACTGTAACGTAGATCTACACTATTTCTCATCATCCTTCTTCTCTGTAGCAGAAGAATCACCCTGGGAGATCATATACAAAGTTGAAGACTCAAACGTGTTACAAGGAGTAAAGTTCGCTTCAATTAAGGCGAAACTGAGATTATCTTCTGCTAGACACTCCACTGACATTAGGTTTAAACCACCAACAATTAACATTTTATCAAAGGGCTTTGACAAGTCTTGTGTGGACTTTTGGTCAGTGGAGAAAGGCGAGCCCAGACGCAGACTGCTAAACCCAACACCAACGGCCCACAAGCAAGGGTCCATAATACCAAGGCCCATAACTATATTACCAGGGGAGACATGGGCCACTAAGTCACAACTGGGCTTATCTACTGGGCCGGCCCAATTAACACGCGATACATTACGAAGCAGGTCCATGAGAATGCCCCGTGCCGAATACGATGGCGAGACAAGCGCCAACAACGAGGAAGGATCGAGTAGGTCGAGAGAATATCCATATGCAGGTCTCAGACGGCTCGACGCATCAGCCATTGACCCGGGTGATTCGATATCCGAAACAATGTCCACAACAATGACAAGGGGAGACATCCAGAGTATAGTGGAGGATGCAATAAACAAATGTCTTATTAGGAATAAAACAGAGAGTAATAAACATTTGTAG |
|
Protein Sequence
|
MSVFSAEINMEHSYTVVNNKYIDSKRAEYNLTNDATRINLQFPSSLEQTRVRLMGRCMKIDHIIIEYRNQVPFNATGSVIVEIRDNRVSQEEAAQAAFTFPIDCNVDLHYFSSSFFSVAEESPWEIIYKVEDSNVLQGVKFASIKAKLRLSSARHSTDIRFKPPTINILSKGFDKSCVDFWSVEKGEPRRRLLNPTPTAHKQGSIIPRPITILPGETWATKSQLGLSTGPAQLTRDTLRSRSMRMPRAEYDGETSANNEEGSSRSREYPYAGLRRLDASAIDPGDSISETMSTTMTRGDIQSIVEDAINKCLIRNKTESNKHL |
|
NCBI Accession
|
YP_009121936.1
|
|
Location
|
119-484 |
|
Gene Name
|
AV2 |
|
Protein Name
|
movement protein |
|
Coding Region
|
TTGGTAAAGATGTGGGATCCACTTTGCAATGACTTCCCCTCCACGGTTCATGGATTCCGATGTATGTTGGCCACTAAATATCTTCTCGAGATTGAGAAGACATATGAGCCTAATTGTGTGGGCCAATTATTCATTAGGGATTTAATATCCGTCGTTCGCGCCCCTAATTATGTCGAAGCGACCAGGAGATATAATCATTTCCACACCCGCTTCAAAGGCACGACGTCGTCTCAACTTCGACAGCCCGCGTGTAGCTGCATCCTCTGTCCGCATCACCAGAAGGCAGGCATGGGTGAACAGGCCGATGTATCGCAAGCCCAGAATGTACCGCATGTGGCGGAGTTACGATGTTCCCAAGGGTTGTGA |
|
Protein Sequence
|
MVKMWDPLCNDFPSTVHGFRCMLATKYLLEIEKTYEPNCVGQLFIRDLISVVRAPNYVEATRRYNHFHTRFKGTTSSQLRQPACSCILCPHHQKAGMGEQADVSQAQNVPHVAELRCSQGL |
|
NCBI Accession
|
YP_009121937.1
|
|
Location
|
288-1052 |
|
Gene Name
|
AV1 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGTCGAAGCGACCAGGAGATATAATCATTTCCACACCCGCTTCAAAGGCACGACGTCGTCTCAACTTCGACAGCCCGCGTGTAGCTGCATCCTCTGTCCGCATCACCAGAAGGCAGGCATGGGTGAACAGGCCGATGTATCGCAAGCCCAGAATGTACCGCATGTGGCGGAGTTACGATGTTCCCAAGGGTTGTGAGGGTCCATGTAAGGTTCAATCATATGACCAGCGTGATGATGTTAAGCATGTAGGTGTTGTTAGATGTATATCCGATGTCACTAAAGGACCTGGGCTGACTCATCGTACAGGCAAACGTTTCACAGTGAAGTCAGTATATATATGTGGGAAGATATGGATGGATGAGAATATTAAGAAGCAGAATCATACTAATCATGTGTTGTTTTTCCTAACTAGAGATAGACGACCTTATGGTCAGGCGCCTATGGATTTTGGTCAAGTGTTTAACATGTTTGATAATGAACCTAGTACAGCTACGGTTAAGAATGATTTGCGAGATCGATTTCAGGTCCTGCGTCGGTTCTATGCTACTGTTGTTGGAGGTCCTTCGGGGATGAAAGAACAAGTCTTAGTTAGGCGTTTTTTTAAGCTTAACGCCCAGATTGTGTATAACCATCAGGATGGTGCTAAGTATGAGAACCATACAGAGAATGCTTTGTTGTTGTATATGGCATGTACACATGCTTCAAATCCTGTGTATGCTAGTCTGAAAGTTCGCATATATTTCTATGACAGCGTAAGCAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPASKARRRLNFDSPRVAASSVRITRRQAWVNRPMYRKPRMYRMWRSYDVPKGCEGPCKVQSYDQRDDVKHVGVVRCISDVTKGPGLTHRTGKRFTVKSVYICGKIWMDENIKKQNHTNHVLFFLTRDRRPYGQAPMDFGQVFNMFDNEPSTATVKNDLRDRFQVLRRFYATVVGGPSGMKEQVLVRRFFKLNAQIVYNHQDGAKYENHTENALLLYMACTHASNPVYASLKVRIYFYDSVSN |
|
NCBI Accession
|
YP_009121938.1
|
|
Location
|
1049-1483 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
CTGTTCTCATACATCCTCTCTGCAACAATTATGGATTTTCGCACAGGGGAATCCATCACTGCAGCTCAAGCGCAGAGTGGAATATACTTCTGGGAACTGAGGAATCCAATATACACAACGATAACAGAACACATCGACAGACCATTCAACACGAACCACGACATACTGAACATCCAAATCAGGTTCAACCACAACCTGAGGAAGGCTTTAGGGATTCACAAATGTTATTTGAACTTCAAGGTCTGGACGAGATTGAGGAGTTCGACATCTCGGTTCTTGAGGGTTTTTAATTACAGTTTCATGAAACGCTTAAACTCATTAGGAGTTATAAGCATAAATACTTGTATTAATAGCGTGGATTATGTATTATACAATGTACTCGATGGAACCATCAATGTAGAAGAAAACCACATAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MFSYILSATIMDFRTGESITAAQAQSGIYFWELRNPIYTTITEHIDRPFNTNHDILNIQIRFNHNLRKALGIHKCYLNFKVWTRLRSSTSRFLRVFNYSFMKRLNSLGVISINTCINSVDYVLYNVLDGTINVEENHIIKFNIY |
|
NCBI Accession
|
YP_009121939.1
|
|
Location
|
1194-1601 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCGACCTTCATCACAATCTCCGACCCTCTCTACTCTTGTGCCAATCAAAGTAGTGCACAGACAGGCCAAGAAGAAGAGGCAACGTAGAAAGAAGATAGATCTGGGCTGTGGGTGTTCTGTTCTCATACATCCTCTCTGCAACAATTATGGATTTTCGCACAGGGGAATCCATCACTGCAGCTCAAGCGCAGAGTGGAATATACTTCTGGGAACTGAGGAATCCAATATACACAACGATAACAGAACACATCGACAGACCATTCAACACGAACCACGACATACTGAACATCCAAATCAGGTTCAACCACAACCTGAGGAAGGCTTTAGGGATTCACAAATGTTATTTGAACTTCAAGGTCTGGACGAGATTGAGGAGTTCGACATCTCGGTTCTTGAGGGTTTTTAA |
|
Protein Sequence
|
MRPSSQSPTLSTLVPIKVVHRQAKKKRQRRKKIDLGCGCSVLIHPLCNNYGFSHRGIHHCSSSAEWNILLGTEESNIHNDNRTHRQTIQHEPRHTEHPNQVQPQPEEGFRDSQMLFELQGLDEIEEFDISVLEGF |
|
NCBI Accession
|
YP_009121940.1
|
|
Location
|
1513-2601 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
TTGATCCCCAAGATGCCGAGAGCAGGGAGATTCAACATAAATGCCAAAAATTACTTCCTCACATATCCTCAATGCTCTCTGAGCAAAGAGGAAACCCTATCTCTTCTTCTCGCCAAACAAATACCAGTAAATATAAAATTCATTAGGGTTTGCAGAGAACTCCACCAGAATGGGGAACCTCATCTCCATGTGCTATTACAATTCGAAGGAAAATACCAGTGCACAAATCAGAGATTCTTCGACCTGGTTTCCCCAAACAGATCAACACCTTTCCATCCGAACATTCAGGGAGCTAAGAGCTCGTCAGATGTCAAGACATATATTGAGAAAGGAGGAGACTTCATCGACCATGGGGAATTCCAGATAGATGCAAGAAGCGCAAGGGGTCAAGGGCAAAACCTTGCAGACCTATACGCAGATGCTTTAAATGCCTCAAATAAAGAGGCTGCTATGAGATTGATCAAGGAAAGAGATCCCAAGTCATACTTCTTGCAGTACCACAACATTTCAGCAAACGCGGATAAGATATTTGCACCCAAGAGGGTACCATACGAGTCACCATATACACCTGCAAGCTTCACCAATGTTCCAGAAGAGATGAAGCTGTGGGTAGCTGAAAATGTCATGGGTCCCGCTGCGCGGCCACAAAGACCCAAAAGTATAGTCATTGAGGGGTCCAGTAGGACAGGTAAGACAATGTGGGCCCGGCAATTGGGCCCTCACAATTATTTGTGTGGCCATTTGGATTTGTCAAATAAGGTGTACAGCAATAATGCCTGGTATAACGTCATTGATGACGTCGATCCGCACTATCTGAAACATTTCAAAGAGTTCATGGGGGCCCAGCACAACTGGCAAAGCAATATCAAGTACGGGAAACCAGTTCAAATTAAAGGTGGTATTCCCACTATCTTCCTCTGCAATCCAGGACCACAGTCCTCTTATAAAGAATTCCTCGATGAGCCCAAAAATGCAGGACTGAAGCAGTGGGCTTTAAAGAATGCGACCTTCATCACAATCTCCGACCCTCTCTACTCTTGTGCCAATCAAAGTAGTGCACAGACAGGCCAAGAAGAAGAGGCAACGTAG |
|
Protein Sequence
|
MIPKMPRAGRFNINAKNYFLTYPQCSLSKEETLSLLLAKQIPVNIKFIRVCRELHQNGEPHLHVLLQFEGKYQCTNQRFFDLVSPNRSTPFHPNIQGAKSSSDVKTYIEKGGDFIDHGEFQIDARSARGQGQNLADLYADALNASNKEAAMRLIKERDPKSYFLQYHNISANADKIFAPKRVPYESPYTPASFTNVPEEMKLWVAENVMGPAARPQRPKSIVIEGSSRTGKTMWARQLGPHNYLCGHLDLSNKVYSNNAWYNVIDDVDPHYLKHFKEFMGAQHNWQSNIKYGKPVQIKGGIPTIFLCNPGPQSSYKEFLDEPKNAGLKQWALKNATFITISDPLYSCANQSSAQTGQEEEAT |
|
NCBI Accession
|
YP_009121941.1
|
|
Location
|
2235-2432 |
|
Gene Name
|
AC4 |
|
Protein Name
|
ac4 |
|
Coding Region
|
ATGGGGAACCTCATCTCCATGTGCTATTACAATTCGAAGGAAAATACCAGTGCACAAATCAGAGATTCTTCGACCTGGTTTCCCCAAACAGATCAACACCTTTCCATCCGAACATTCAGGGAGCTAAGAGCTCGTCAGATGTCAAGACATATATTGAGAAAGGAGGAGACTTCATCGACCATGGGGAATTCCAGATAG |
|
Protein Sequence
|
MGNLISMCYYNSKENTSAQIRDSSTWFPQTDQHLSIRTFRELRARQMSRHILRKEETSSTMGNSR |