Pea leaf distortion virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_001974515.1 |
| Isolate | Nepal |
| Release date | 2017/1/29 |
| Submitter | Shahid,M.S., Pudashini,B.J., Khatri-Chhetri,G.B., Briddon,R.W., Natsuaki,K.T. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
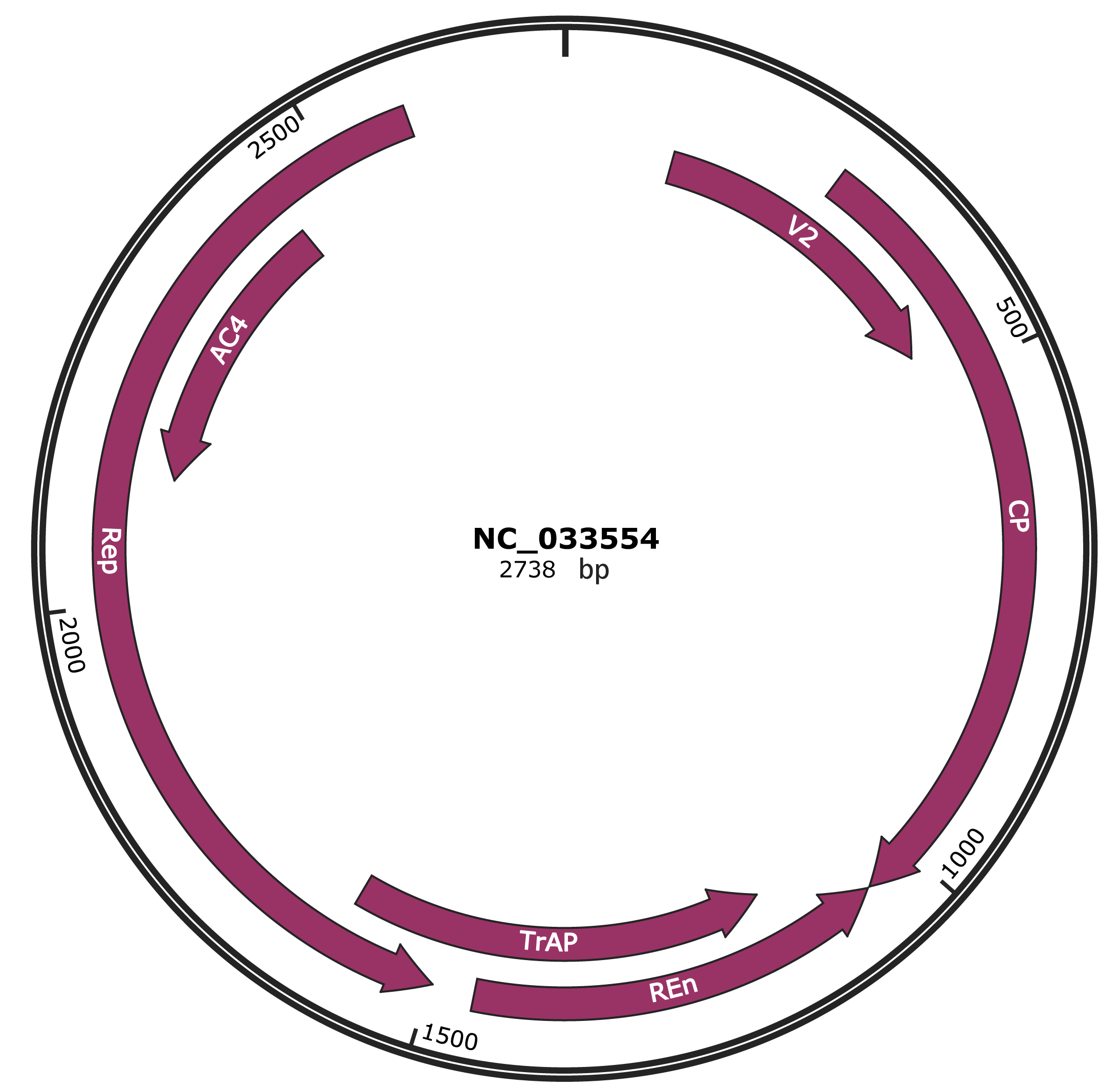
Genomic Organization
JBrowse
Genome
NC_033554
Gene Information
| NCBI Accession | YP_009344819.1 |
|---|---|
| Location | 119-466 |
| Gene Name | V2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCACTGCTAAACGAGTTCCCCGAGACGGTTCACGGGTTTCGTTGCATGCTTGCTATCAAATATCTTCAACATCTGTCTGAAGAATACTCTCCTGATACGGTAGGTTACGATTTAATCCGCGATTTAATATCAATTTTGCGTTCTAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCATCGTCTCAACTTCGACAGCCCATACGCGTGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAATCTCGCATGTGGGCGAACAGGCCCATGAATCGCAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPETVHGFRCMLAIKYLQHLSEEYSPDTVGYDLIRDLISILRSRNYVEASCRYRHFYPRVEGASSSQLRQPIRVPCCCPHCPRHKISHVGEQAHESQAQNVQDVQKP |
| NCBI Accession | YP_009344820.1 |
|---|---|
| Location | 279-1049 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCATCGTCTCAACTTCGACAGCCCATACGCGTGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAATCTCGCATGTGGGCGAACAGGCCCATGAATCGCAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCAAGGGGCTGTGAGGGTCCATGTAAGGTCCAGTCATTTGAGTCCAGACACGATGTAGTCCATATAGGGAAGGTCATGTGTATTAGTGATGTTACTCGCGGTACTGGGTTGACCCATAGAGTTGGTAAACGTTTCTGTGTTAAGTCAGTTTATGTGTTGGGTAAGATCTGGATGGATGAAAATATAAAGTCCAAGAATCATACGAACAATGTGATGTTCTTTCTCGTTCGTGATCGACGTCCGGTTGACAAGCCTCAGGATTTTGGAGAGGTCTTCAACATGTTTGACAACGAGCCTAGCACTGCTACTGTGAAGAATGTGCATCGCGATCGTTACCAGGTCTTGAGGAAATGGTATGCAACTGTCACTGGTGGACAGTATGGTGCAAAGGAACAGGCTTTAGTTAAGAAGTTTGTTAGGGTTAATAATTATGTTGTTTACAATCAGCAAGAGGCAGGGAAATACGAGAATCATTCTGAGAATGCCTTGATGTTGTATATGGCATGTACCCATGCCTCTAATCCTGTTTACGCCACTCTTAAGATTAGGATCTACTTCTACGATTCTGTAACGAATTGA |
| Protein Sequence | MSKRPADIVISTPASKVRHRLNFDSPYACRAAAPIVRVTKSRMWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKSKNHTNNVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWYATVTGGQYGAKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | YP_009344821.1 |
|---|---|
| Location | 1052-1456 |
| Gene Name | REn |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTTACGCACAGGGGGACCCATCACTGCAGCTCAAGCATGGAGTGGCGCCTATATCTGGGAAGTTCCAAATCCCCTCTATTTCAAGATCCTCAGCCACGACAACCGTCCATTCACGATGAACATGGACATCATCAAGATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTACCGAATCTGGACGACCTTACACCCTCAGACTGGTCTTTTCTTAAAAGTATTCAAAACCCAAGTCCTCAAGTATCTCACAAATCTGGGTGTAATCTCAATTAATTCAATTATTAGAGCAGTTGATCATGTATTATGGAAAAAAATAGAACAAACTATGTATGTAAACATGACTTCAGAAATAAAATTCGATCTTTATTAA |
| Protein Sequence | MDLRTGGPITAAQAWSGAYIWEVPNPLYFKILSHDNRPFTMNMDIIKIRIQFNYNLRRALGVHKCFLTYRIWTTLHPQTGLFLKVFKTQVLKYLTNLGVISINSIIRAVDHVLWKKIEQTMYVNMTSEIKFDLY |
| NCBI Accession | YP_009344822.1 |
|---|---|
| Location | 1149-1601 |
| Gene Name | TrAP |
| Protein Name | transcription associated protein |
| Coding Region | ATGCGATCTTCATCACCCTCGAAGGACCACTATACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAAGCGCAACAGGAGGAGGAGAGTCGATCTTGAATGCGGGTGTTCTTATTTTCTATCTCTAAACTGCTTCAACCATGGATTTACGCACAGGGGGACCCATCACTGCAGCTCAAGCATGGAGTGGCGCCTATATCTGGGAAGTTCCAAATCCCCTCTATTTCAAGATCCTCAGCCACGACAACCGTCCATTCACGATGAACATGGACATCATCAAGATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTACCGAATCTGGACGACCTTACACCCTCAGACTGGTCTTTTCTTAAAAGTATTCAAAACCCAAGTCCTCAAGTATCTCACAAATCTGGGTGTAATCTCAATTAA |
| Protein Sequence | MRSSSPSKDHYTQVPIKVQHREAKKRNRRRRVDLECGCSYFLSLNCFNHGFTHRGTHHCSSSMEWRLYLGSSKSPLFQDPQPRQPSIHDEHGHHQDQDPIQLQPSESSGSAQVFSDLPNLDDLTPSDWSFLKSIQNPSPQVSHKSGCNLN |
| NCBI Accession | YP_009344823.1 |
|---|---|
| Location | 1498-2586 |
| Gene Name | Rep |
| Protein Name | replication associated protein |
| Coding Region | ATGGCTCCAAAGCGGTTTGTTATTTATTCTAAAAACTATTTCCTCACTTATCCCAAGTGTTCTCTCACTAAAGAAGAAGCACTTTCCCAAATCCAGAATCTTCAAACCCCAACTTCCCAAAAATATATTAAAATCTGCCGAGAACTCCATGAAAATGGGGAACCTCATCTGCACGTGCTCATCCAGTTCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTATCCCCAAATAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGACACTCTCGAATGGGGGGAGTTTCAGATCGACGGACGATCTGCAAGAGGAGGACAACAGACAGCAAACGACGCTTACGCCGCGGCACTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAGGGAACTAGCTCCTAAAGATTTTGTACTACAATTTCATAATTTAAATGCAAATCTAGACAGGATCTTTCAGGAGCCACCGGCTCCCTACGTTTCTCCCTTTTCCTCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGTGTCGGAGAACGTCGTCGACGCCGCTGCGCGGCCCCTGAGACCTCAAAGTATAGTAATTGAGGGAGACAGTCGAACCGGCAAGACAATGTGGGCTAGGTCACTAGGCCCACATAACTATCTATGTGGACACTTAGACTTAAGTCCCAAGGTCTACAGTAACGACGCCTGGTACAACGTCATTGATGACGTCGACCCGCATTTCCTCAAACACTTTAAGGAGTTCATGGGGGCCCAAAGGGACTGGCAATCCAACACTAAATACGGGAAACCAGTTCAAATTAAAGGCGGGATACCGACAATCTTCCTCTGCAATCCTGGTCCCAACAGCAGTTATAAAGAATTCCTCGACGAGGAAAAGAACAGCGCATTAAAGAATTGGGCTCTCAAGAATGCGATCTTCATCACCCTCGAAGGACCACTATACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAAGCGCAACAGGAGGAGGAGAGTCGATCTTGA |
| Protein Sequence | MAPKRFVIYSKNYFLTYPKCSLTKEEALSQIQNLQTPTSQKYIKICRELHENGEPHLHVLIQFEGKYKCQNQRFFDLVSPNRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIRELAPKDFVLQFHNLNANLDRIFQEPPAPYVSPFSSSSFDQVPEELEEWVSENVVDAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNSALKNWALKNAIFITLEGPLYSGSNQSTAQGSEEAQQEEESRS |
| NCBI Accession | YP_009344824.1 |
|---|---|
| Location | 2130-2438 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAAATGGGGAACCTCATCTGCACGTGCTCATCCAGTTCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTATCCCCAAATAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGACACTCTCGAATGGGGGGAGTTTCAGATCGACGGACGATCTGCAAGAGGAGGACAACAGACAGCAAACGACGCTTACGCCGCGGCACTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAGGGAACTAG |
| Protein Sequence | MKMGNLICTCSSSSRGNTSARISDSSTWYPQIGQHISIQTYRELNPAPTSSPTSTRTETLSNGGSFRSTDDLQEEDNRQQTTLTPRHLTQAVSQRLLESLGN |
References More References in PubMed
| 1 |
First Report of Pea enation mosaic virus Infecting Pea and Broad Bean in Spain. Tornos T, et al. Plant Dis. 2008 Oct;92(10):1469. doi: 10.1094/PDIS-92-10-1469C. PMID: 30769558 |
|---|---|
| 2 |
Shahid MS, et al. Virus Genes. 2017 Apr;53(2):300-306. doi: 10.1007/s11262-016-1424-9. Epub 2016 Dec 23. PMID: 28012011 |
| 3 |
Tan ST, et al. Sci Rep. 2021 Oct 26;11(1):21045. doi: 10.1038/s41598-021-99320-x. PMID: 34702954 |
| 4 |
Virus-induced gene silencing as a tool for functional genomics in a legume species. Constantin GD, et al. Plant J. 2004 Nov;40(4):622-31. doi: 10.1111/j.1365-313X.2004.02233.x. PMID: 15500476 |
| 5 |
Detection of Poinsettia mosaic virus Infecting Poinsettias (Euphorbia pulcherrima) in Venezuela. Carballo O, et al. Plant Dis. 2001 Nov;85(11):1208. doi: 10.1094/PDIS.2001.85.11.1208D. PMID: 30823179 |
| 6 |
Gillaspie AG Jr, et al. Plant Dis. 1998 Jul;82(7):807-810. doi: 10.1094/PDIS.1998.82.7.807. PMID: 30856955 |
| 7 |
First report of occurrence of two viruses on pea field in Iran. Esfandiari N, et al. Commun Agric Appl Biol Sci. 2005;70(3):411-6. PMID: 16637207 |
| 8 |
First Report of Bean yellow mosaic virus in Alaska from Clover (Trifolium spp.). Robertson NL, et al. Plant Dis. 2010 Mar;94(3):372. doi: 10.1094/PDIS-94-3-0372A. PMID: 30754235 |
| 9 |
Baker CA, et al. Plant Dis. 2004 Feb;88(2):223. doi: 10.1094/PDIS.2004.88.2.223B. PMID: 30812442 |
| 10 |
Anemone - an Additional Perennial Ornamental Host of Tobacco Rattle Virus in the U.S. Lockhart BE, et al. Plant Dis. 1998 Jun;82(6):712. doi: 10.1094/PDIS.1998.82.6.712B. PMID: 30857036 |