Pavonia mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029255.2 |
| Isolate |
Brazil |
| Release date |
2018/12/27 |
| Submitter |
Pinto,V.B., Silva,J.P., Fiallo-Olive,E., Navas-Castillo,J., Zerbini,F.M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
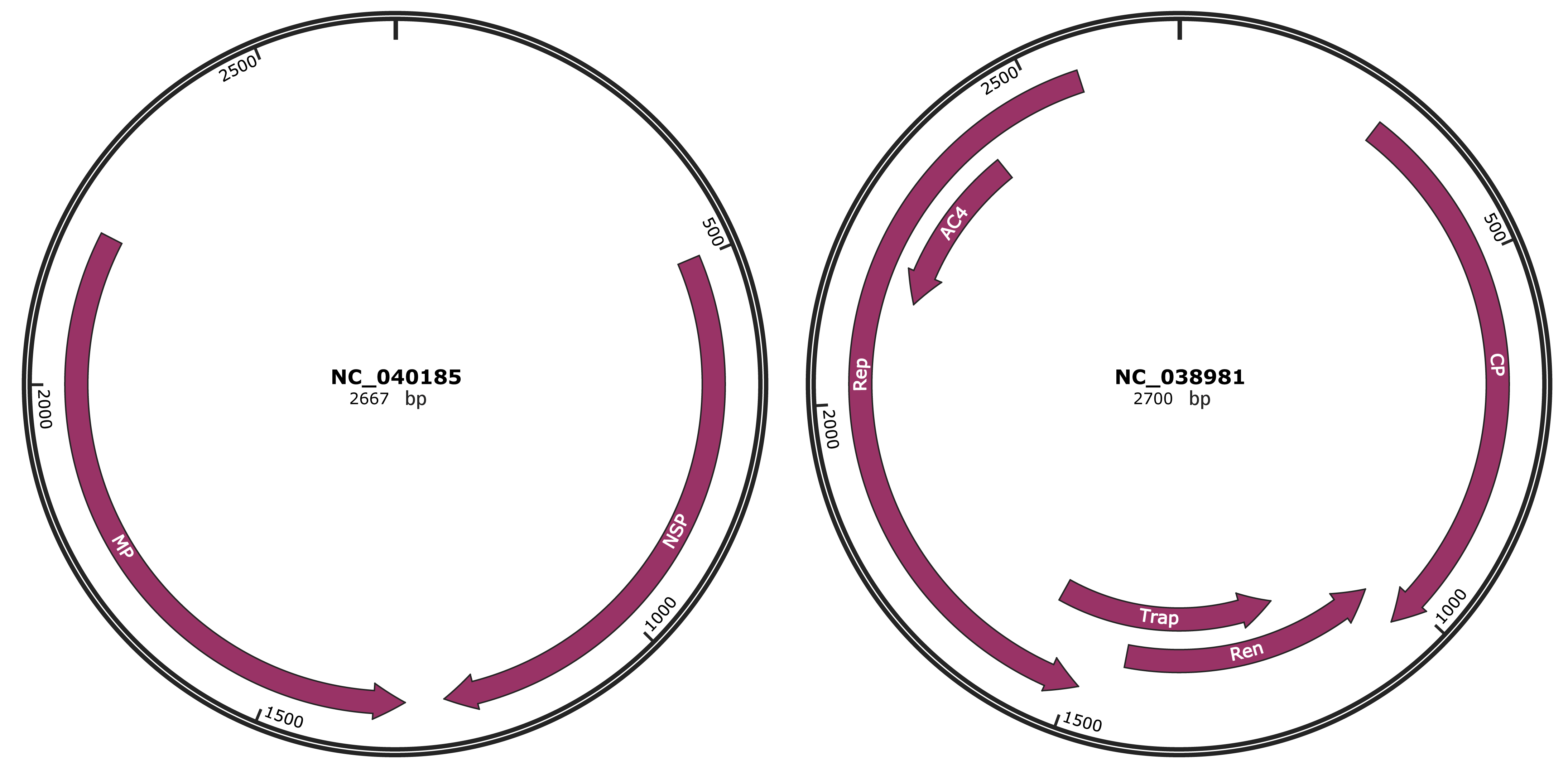
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTGCCCCCTCCCACGTGGCGCCCTGGTGACCGTTCATTCCCCTTCCCCCCCTCGTGGCGCGTTGGTGTCTGTTCGATTCTCTATCACTCGCGCGATTTCGTCCGTTCGATCGTGTTAAGTGCATTTTTGAAGTCCGCGAATTGAGTTGAGCGCATTTTTGAGTTCCGCCAATTAAAAATGAACACGTCGCGCGTCTCCCGCCTCGTTATACTTGTTCAGAACGCTTTGTGTTAAGACCGTTGGATGAACTTGAAATATATTTCTGTGCTTTAATTTGAATTTGACATCAAAGTCTGTGCGTTCTGACAATATGGCCCATATTTACAATGATTAATGTCTTTGGCATTGTACAATATTTTGACGTGGACCAATGAAATAAGAACTATATTGTTAAGTTATGCGATATATGTATAGGAATTTATATTTAAATTTAGTTAAGTTGAACAATAGACCACGTCTACAAAACAGGATTTAATATGTATCCGAGTAGGTATAGACGTGGCTGGTCTTCTAATCAGTCAAGAAAGTACTCAAGAAATCCTGTTGTCAAACGTTCGTATGCAGTGAAACGTAACGATGGGAAACGTCGTTCTGGCACTAGGAAAAAAACCCAGGAGGAAACTGCAATGGTGGAACAACGAATCCAGGAAAATCAGTATGGGCCTGAATTTGTGATGGTCCAGAATTCAGCCCTATCCACATTTATCACTTACCCCGAACTTGGTAAGAAATTACCCAATAGGTCCCGGTCGTACATCAAGTTGAAACGTTTGCGTTTCAAAGGTACGGTTAAGATTGAGCGTGTTCATGCTGATATGAACATGGATGGTTCAACGCCAAAGACCGAAGGCGTGTTCTCCCTGGTGGTCGTGGTTGATCGGAAACCCCATTTGAGTCCATCGGGATGCCTCCATACATTTGACGAGTTATTCGGTGCGAGAATCAATAGCCATGGTAATTTAGCCATTTCTGCCTCTTTGCGAGATCGTTTCTACATACGACACGTGGTGAAACGTGTACTGTCCGTGGAGAAGGATACGATGATGGTCGATCTGGAAGGAACAATGTCCCTTTCTAACAGGCGTTTTAGTTGTTGGGCGTCGTTTAAGGACGTTGATAGAGATTCATGTAATGGGGTTTATGCTAACATAAGCAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCGGATATTATGTCTAAGGCATCGACATTTGTATCGTTTGACCTTGATTATATCGGATAATTAATGACATTTAAAGACCGATTATGAGAACTAATATGCGTAAAGAAAATATTTATTTCAACGACTTAGGCTGTGAAGGAGTACAATTATTGTTAATACACTCTTGGACCGTCGTCCTTACAAGCTCACTCAACTGGGCCACTGACATCGTTATATTGGACTGCGCTCTCTGGGCTCCGACAATTGACGCAGATTCACCTGGGTCTAAGATGGTGGTTCCCAGTCTGTTAAGCTCCCTATACGGATGCGTAGCGTCCCCTAGATCAGATCCCGCATCTGACTGGTTTGGTCCTATGGTACTCCGTGAAGCCCATGATTCGCCTGGTTGTAACTCTAGTGGGCTGGGAAGCCCAAATCTTAATGTTGATGCGGATCTGATGAGTTTCCTCTCCCATCTTCCGTACCCGACGTGCGAGAAATCGATATCTTTCTCGGTGAACTGTTTGGATAAGATCTTTACCGTCGGTGCCCTGAATGGGATGTCGACCGAATGTTTTGCCGTCGACAATTTCAACTTGCCTTTGAATTTTGCGAAATGGGTCCTCTGATGAACATTCGTATCGGATACCCTATAATATAGTTTCCATGGAATTGGGTCTTTAAGGGAGAAGAAGGAAGATGAGAAATAGTGGAGATCTATGTTACATCTGATAGGAAATGTCCACGATGCTTGCAAAGATTCATTGTCTGTCATCCTTTTGTCGTGAATCTCCACTATCACTGACCCTGTGGCGTTAATTGGCACCTGTTGCCTGTATTCTATGACGCAATGGTCGATTTTCATGCAGCTACGACTGATTCTCGCAGACAATTGAGACGCCGTGGACGGAAATTGCAGAATTATCTCTGTTAAGTCGTGGGATAACTGATACTCATCGCGATGCGATTCTATGTAATTAAAGGCGTTAGGAGGATTAACCAACTGAGATTCCATTAAAAATACTGGGAGCGCAGCGACACCGACGAGGTAAATGTAATGGGTAAAGAGAATAAGTCAGAAAGAGAAGAAATCTGGAAGAAGAAATAATAAGATTAAACAGAACTCTGTTTTAGAAGGAACAGGAAAACATGAACGAGATAATTAATTGCACATCGTGAGTGAAAGTCTTTCTGGTTTTATAGACAAGGAAGAGACTTTGTAAAAGTGGAAAACGCTAACCATGATTTGAACGAGGATTAAATGTAAGGATAATTTGTTACGTTAAGTAATTATGTTTTATCGTCTTAGTCGGGGATATTTAAAAGGAAAAGTGAGTTCAATGGCATATTTGTAAATAAGAGCTTGTACACCGATTGAGCTCTCTTCAAAGTCTCTATGAATCGGTGTAATGGTGCCAATATATAGGCTATAGTTCCATAGGGTACAAGGGACACGTGGCGGCCATCCGACTATAATATT
ACCGGATGGCCGCGCGATTTTTTGCCCCCCCCACGTGGAGCCCTGGGGACCGTTCGATTCAGTTAAGCGCATTTTTGAATTCCGCGAAATTAATTGAGCGCATTTTTGAGATCCGCCCCGCGGACCCGTTCGAGCTTTAATTCAAATTAAAGTATAACCGTTTGGAATCGACCAATCATTTTGACTCTGACAAGCTTAGATATGCGTTAAAGTCCTTGGCGCCCAAGTTTAACCGTTATATAAAGTTAAACCTATGTTTAACCGTCATGCTTTAATTCAAAATGCCTAAGCGCGATGCCCCGTGGCGCTCGATGGCGGGAACTTCGAAGGTTAGTCGGGCTCTCAATTATTCCCCTCGCGGGGGTTTTGGGTCAAAGTTTGATAAGGCCGCCGCTTGGACTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGGACGCTAAGATCGCCCGACGTACCCAAAGGCTGTGAAGGCCCATGTAAAGTCCAGTCGTATGAGCAGCGCCACGATGTCTCACATACTGGGAAGGTGATCTGTATATCTGATGTCACCCGTGGTAACGGTATTACACATCGTGTCGGGAAACGTTTTTGCGTCAAGTCTGTTTACATTTTAGGGAAGATATGGATGGACGAGAACATCAAGTTGAAGAACCACACCAACAGCGTCATGTTCTGGCTGGTGAGAGATCGTAAACCGACCGGTACGGCTATGGATTTTGGGCATTTATTTAACATGTTTGACAACGAGCCCAGCACTGCAACCGTGAAGAACGATCTCCGTGACCGTTTCCAGGTAATGCACAGGTTTTATGCCAAGGTTACAGGTGGACAGTACGCTAGCAATGAACAGGCGCTGGTCAAGCGTTTCTGGAAGGTCAACACTCATGTGGTCTACAACAATCAGGAAGCTGCTAGATACGAGAATCATACGGAGAACGCCCTATTATTGTATATGGCATGTACGCATGCATCTAACCCCGTGTACGCAACGCTTAAGATTCGTATCTACTTTTACGATTCGGTCCGGAATTAATAAATTTTGAATTTTATTGAATGATCTTCGAGTACATAGGAGACATAACGTCTAGCCGTTGCGAATCGAACAGCTCTAATTACATTGTTAATGGTAATAACGCCTAAGCGATCTAGATACAAGAACACTAACGATCGGAATCTATTTAAATAAGTCGTCCCAGAAGCTTGAATCGATGTTGTCCAGACTTGGAAGTTCAGGAAGCATTTGTGGAGATCCAATGCTTTCCTCAGGTTGTGGTTGAACCGGATCTGGATGTGATATACCCTGGTGTTTGTGTATAACGGGACCTCTACTCTGTACATCTTGAAATAAAGGGGATTGTCTACCTCCCAGATATACACGCCATTCTCTGCCTGAGGCGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGATCGGCGCAATTGATATGGATGTATATTGAGCACCCGCAGTTAAGGTCTATGCGCCTACGACGAGTTATTCTCCGTTTCGCCGCCCTGTGTTGAGGTTTGATAGAGGGGGGAGTCGAGGAAGACGAACGTCGCATTATGTAATGTCCAGGCTTTGAGAGCTGAGTTTTCAGCTTTGTCGAGGAAATCTTTATAACTAGCCCCCTCGCCTGGATTGCAGAGCACGATTGAAGGAACCCCTCCTTTAATTTGAACAGGCTTTCCGTACTTGCAATTGGATTGCCAGTCCCTTTGGGCCCCGATAAGTTCCTTCCAGTGCTTTAACTTTAGATAATGCGGGCTTACGTCATCGATTACGTTGAACTCCACTTCGTTCGAGTAAACCCTAGAATTGAAGTCTAGGTGCCCGCTCAAATAATTATGTGGGCCTAATGCACGAGCCCACATCGTCTTCCCGGTCCTACTATCCCCCTCGATGATCAAGCTAACAGGTCGGACAGGCCGCGCAGCGGCATCAAGCCCAATATACTGAGCAACCCAATCCTTCATCTCGTCTGGCACGTTAGTGAATGAGGAGAGGGGGAATGGAGAAGCCCATGGCTCCGGAGGCTTAGAGAATATCCTGTCCAGGTTACTGGACAGATTGTGATACTGAAATAAGAACTTTTCCGGAAGCTTCTCCTTTATTATCTGCATGGCTTCGTCCTTTGATGCAGCATTTAATGCCTCTGCTGCTGCATCATTAGCTGTCTGTTGACCTCCTCTAGCAGATCTGCCGTCGATCTGAAAAGTACCCCATTCGATGTAATCTCCACCCTTCTCGATGTATGATTTGGCGTCGGAGGAGGATTTACACGATTTGTATTCCCCATGACAGACATTTGAATGTTGGGGATGTCGCAAGTCGAAGAATCTACAATTCGTGCACTGGAACTTTCCTTCGAACTGCAACAGAGCATGGAGATGAGGTGCTCCATCTTCGTGTAATTCTCTACATACACGGATATATTTCTTATTGGTTGGGGTTTCTAATGCTAATAATTGGGAAAGTGCCTCTTCTTTGGAGATGGAGCACCTGGGATAAGTGAGGAAATAATTTTTGGCGTTTACTTTAAAACGTTTTGGCGGTGGCATATTTGTAAATAAGAGCTTGTACACCGATTGAGCTCTCTTCAAAAGTCTCTATGAATCGGTGTAATGGTGCCAATATATAGGTAGGAGTTCCATAGGGTACAAATGGACACGTGGCGGCCATCCGACTATAATATT
Gene Information
|
NCBI Accession
|
YP_009547930.1
|
|
Location
|
498-1268 |
|
Gene Name
|
NSP |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATCCGAGTAGGTATAGACGTGGCTGGTCTTCTAATCAGTCAAGAAAGTACTCAAGAAATCCTGTTGTCAAACGTTCGTATGCAGTGAAACGTAACGATGGGAAACGTCGTTCTGGCACTAGGAAAAAAACCCAGGAGGAAACTGCAATGGTGGAACAACGAATCCAGGAAAATCAGTATGGGCCTGAATTTGTGATGGTCCAGAATTCAGCCCTATCCACATTTATCACTTACCCCGAACTTGGTAAGAAATTACCCAATAGGTCCCGGTCGTACATCAAGTTGAAACGTTTGCGTTTCAAAGGTACGGTTAAGATTGAGCGTGTTCATGCTGATATGAACATGGATGGTTCAACGCCAAAGACCGAAGGCGTGTTCTCCCTGGTGGTCGTGGTTGATCGGAAACCCCATTTGAGTCCATCGGGATGCCTCCATACATTTGACGAGTTATTCGGTGCGAGAATCAATAGCCATGGTAATTTAGCCATTTCTGCCTCTTTGCGAGATCGTTTCTACATACGACACGTGGTGAAACGTGTACTGTCCGTGGAGAAGGATACGATGATGGTCGATCTGGAAGGAACAATGTCCCTTTCTAACAGGCGTTTTAGTTGTTGGGCGTCGTTTAAGGACGTTGATAGAGATTCATGTAATGGGGTTTATGCTAACATAAGCAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCGGATATTATGTCTAAGGCATCGACATTTGTATCGTTTGACCTTGATTATATCGGATAA |
|
Protein Sequence
|
MYPSRYRRGWSSNQSRKYSRNPVVKRSYAVKRNDGKRRSGTRKKTQEETAMVEQRIQENQYGPEFVMVQNSALSTFITYPELGKKLPNRSRSYIKLKRLRFKGTVKIERVHADMNMDGSTPKTEGVFSLVVVVDRKPHLSPSGCLHTFDELFGARINSHGNLAISASLRDRFYIRHVVKRVLSVEKDTMMVDLEGTMSLSNRRFSCWASFKDVDRDSCNGVYANISKNALLVYYCWMSDIMSKASTFVSFDLDYIG |
|
NCBI Accession
|
YP_009547931.1
|
|
Location
|
1321-2202 |
|
Gene Name
|
MP |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAGTTGGTTAATCCTCCTAACGCCTTTAATTACATAGAATCGCATCGCGATGAGTATCAGTTATCCCACGACTTAACAGAGATAATTCTGCAATTTCCGTCCACGGCGTCTCAATTGTCTGCGAGAATCAGTCGTAGCTGCATGAAAATCGACCATTGCGTCATAGAATACAGGCAACAGGTGCCAATTAACGCCACAGGGTCAGTGATAGTGGAGATTCACGACAAAAGGATGACAGACAATGAATCTTTGCAAGCATCGTGGACATTTCCTATCAGATGTAACATAGATCTCCACTATTTCTCATCTTCCTTCTTCTCCCTTAAAGACCCAATTCCATGGAAACTATATTATAGGGTATCCGATACGAATGTTCATCAGAGGACCCATTTCGCAAAATTCAAAGGCAAGTTGAAATTGTCGACGGCAAAACATTCGGTCGACATCCCATTCAGGGCACCGACGGTAAAGATCTTATCCAAACAGTTCACCGAGAAAGATATCGATTTCTCGCACGTCGGGTACGGAAGATGGGAGAGGAAACTCATCAGATCCGCATCAACATTAAGATTTGGGCTTCCCAGCCCACTAGAGTTACAACCAGGCGAATCATGGGCTTCACGGAGTACCATAGGACCAAACCAGTCAGATGCGGGATCTGATCTAGGGGACGCTACGCATCCGTATAGGGAGCTTAACAGACTGGGAACCACCATCTTAGACCCAGGTGAATCTGCGTCAATTGTCGGAGCCCAGAGAGCGCAGTCCAATATAACGATGTCAGTGGCCCAGTTGAGTGAGCTTGTAAGGACGACGGTCCAAGAGTGTATTAACAATAATTGTACTCCTTCACAGCCTAAGTCGTTGAAATAA |
|
Protein Sequence
|
MESQLVNPPNAFNYIESHRDEYQLSHDLTEIILQFPSTASQLSARISRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTEKDIDFSHVGYGRWERKLIRSASTLRFGLPSPLELQPGESWASRSTIGPNQSDAGSDLGDATHPYRELNRLGTTILDPGESASIVGAQRAQSNITMSVAQLSELVRTTVQECINNNCTPSQPKSLK |
|
NCBI Accession
|
YP_009508384.1
|
|
Location
|
282-1037 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCGTGGCGCTCGATGGCGGGAACTTCGAAGGTTAGTCGGGCTCTCAATTATTCCCCTCGCGGGGGTTTTGGGTCAAAGTTTGATAAGGCCGCCGCTTGGACTAACAGGCCCATGTACAGGAAGCCCAGGATATATCGGACGCTAAGATCGCCCGACGTACCCAAAGGCTGTGAAGGCCCATGTAAAGTCCAGTCGTATGAGCAGCGCCACGATGTCTCACATACTGGGAAGGTGATCTGTATATCTGATGTCACCCGTGGTAACGGTATTACACATCGTGTCGGGAAACGTTTTTGCGTCAAGTCTGTTTACATTTTAGGGAAGATATGGATGGACGAGAACATCAAGTTGAAGAACCACACCAACAGCGTCATGTTCTGGCTGGTGAGAGATCGTAAACCGACCGGTACGGCTATGGATTTTGGGCATTTATTTAACATGTTTGACAACGAGCCCAGCACTGCAACCGTGAAGAACGATCTCCGTGACCGTTTCCAGGTAATGCACAGGTTTTATGCCAAGGTTACAGGTGGACAGTACGCTAGCAATGAACAGGCGCTGGTCAAGCGTTTCTGGAAGGTCAACACTCATGTGGTCTACAACAATCAGGAAGCTGCTAGATACGAGAATCATACGGAGAACGCCCTATTATTGTATATGGCATGTACGCATGCATCTAACCCCGTGTACGCAACGCTTAAGATTCGTATCTACTTTTACGATTCGGTCCGGAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRALNYSPRGGFGSKFDKAAAWTNRPMYRKPRIYRTLRSPDVPKGCEGPCKVQSYEQRHDVSHTGKVICISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRKPTGTAMDFGHLFNMFDNEPSTATVKNDLRDRFQVMHRFYAKVTGGQYASNEQALVKRFWKVNTHVVYNNQEAARYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVRN |
|
NCBI Accession
|
YP_009508385.1
|
|
Location
|
1034-1432 |
|
Gene Name
|
Ren |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCGCCTCAGGCAGAGAATGGCGTGTATATCTGGGAGGTAGACAATCCCCTTTATTTCAAGATGTACAGAGTAGAGGTCCCGTTATACACAAACACCAGGGTATATCACATCCAGATCCGGTTCAACCACAACCTGAGGAAAGCATTGGATCTCCACAAATGCTTCCTGAACTTCCAAGTCTGGACAACATCGATTCAAGCTTCTGGGACGACTTATTTAAATAGATTCCGATCGTTAGTGTTCTTGTATCTAGATCGCTTAGGCGTTATTACCATTAACAATGTAATTAGAGCTGTTCGATTCGCAACGGCTAGACGTTATGTCTCCTATGTACTCGAAGATCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAENGVYIWEVDNPLYFKMYRVEVPLYTNTRVYHIQIRFNHNLRKALDLHKCFLNFQVWTTSIQASGTTYLNRFRSLVFLYLDRLGVITINNVIRAVRFATARRYVSYVLEDHSIKFKIY |
|
NCBI Accession
|
YP_009508386.1
|
|
Location
|
1179-1568 |
|
Gene Name
|
Trap |
|
Protein Name
|
trans-activating protein |
|
Coding Region
|
ATGCGACGTTCGTCTTCCTCGACTCCCCCCTCTATCAAACCTCAACACAGGGCGGCGAAACGGAGAATAACTCGTCGTAGGCGCATAGACCTTAACTGCGGGTGCTCAATATACATCCATATCAATTGCGCCGATCATGGATTCACGCACAGGGGAACTCATCACTGCGCCTCAGGCAGAGAATGGCGTGTATATCTGGGAGGTAGACAATCCCCTTTATTTCAAGATGTACAGAGTAGAGGTCCCGTTATACACAAACACCAGGGTATATCACATCCAGATCCGGTTCAACCACAACCTGAGGAAAGCATTGGATCTCCACAAATGCTTCCTGAACTTCCAAGTCTGGACAACATCGATTCAAGCTTCTGGGACGACTTATTTAAATAG |
|
Protein Sequence
|
MRRSSSSTPPSIKPQHRAAKRRITRRRRIDLNCGCSIYIHINCADHGFTHRGTHHCASGREWRVYLGGRQSPLFQDVQSRGPVIHKHQGISHPDPVQPQPEESIGSPQMLPELPSLDNIDSSFWDDLFK |
|
NCBI Accession
|
YP_009508387.1
|
|
Location
|
1489-2565 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACCGCCAAAACGTTTTAAAGTAAACGCCAAAAATTATTTCCTCACTTATCCCAGGTGCTCCATCTCCAAAGAAGAGGCACTTTCCCAATTATTAGCATTAGAAACCCCAACCAATAAGAAATATATCCGTGTATGTAGAGAATTACACGAAGATGGAGCACCTCATCTCCATGCTCTGTTGCAGTTCGAAGGAAAGTTCCAGTGCACGAATTGTAGATTCTTCGACTTGCGACATCCCCAACATTCAAATGTCTGTCATGGGGAATACAAATCGTGTAAATCCTCCTCCGACGCCAAATCATACATCGAGAAGGGTGGAGATTACATCGAATGGGGTACTTTTCAGATCGACGGCAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGCAGCAGCAGAGGCATTAAATGCTGCATCAAAGGACGAAGCCATGCAGATAATAAAGGAGAAGCTTCCGGAAAAGTTCTTATTTCAGTATCACAATCTGTCCAGTAACCTGGACAGGATATTCTCTAAGCCTCCGGAGCCATGGGCTTCTCCATTCCCCCTCTCCTCATTCACTAACGTGCCAGACGAGATGAAGGATTGGGTTGCTCAGTATATTGGGCTTGATGCCGCTGCGCGGCCTGTCCGACCTGTTAGCTTGATCATCGAGGGGGATAGTAGGACCGGGAAGACGATGTGGGCTCGTGCATTAGGCCCACATAATTATTTGAGCGGGCACCTAGACTTCAATTCTAGGGTTTACTCGAACGAAGTGGAGTTCAACGTAATCGATGACGTAAGCCCGCATTATCTAAAGTTAAAGCACTGGAAGGAACTTATCGGGGCCCAAAGGGACTGGCAATCCAATTGCAAGTACGGAAAGCCTGTTCAAATTAAAGGAGGGGTTCCTTCAATCGTGCTCTGCAATCCAGGCGAGGGGGCTAGTTATAAAGATTTCCTCGACAAAGCTGAAAACTCAGCTCTCAAAGCCTGGACATTACATAATGCGACGTTCGTCTTCCTCGACTCCCCCCTCTATCAAACCTCAACACAGGGCGGCGAAACGGAGAATAACTCGTCGTAG |
|
Protein Sequence
|
MPPPKRFKVNAKNYFLTYPRCSISKEEALSQLLALETPTNKKYIRVCRELHEDGAPHLHALLQFEGKFQCTNCRFFDLRHPQHSNVCHGEYKSCKSSSDAKSYIEKGGDYIEWGTFQIDGRSARGGQQTANDAAAEALNAASKDEAMQIIKEKLPEKFLFQYHNLSSNLDRIFSKPPEPWASPFPLSSFTNVPDEMKDWVAQYIGLDAAARPVRPVSLIIEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNEVEFNVIDDVSPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGVPSIVLCNPGEGASYKDFLDKAENSALKAWTLHNATFVFLDSPLYQTSTQGGETENNSS |
|
NCBI Accession
|
YP_009508388.1
|
|
Location
|
2151-2408 |
|
Gene Name
|
AC4 |
|
Protein Name
|
ac4 protein |
|
Coding Region
|
ATGGAGCACCTCATCTCCATGCTCTGTTGCAGTTCGAAGGAAAGTTCCAGTGCACGAATTGTAGATTCTTCGACTTGCGACATCCCCAACATTCAAATGTCTGTCATGGGGAATACAAATCGTGTAAATCCTCCTCCGACGCCAAATCATACATCGAGAAGGGTGGAGATTACATCGAATGGGGTACTTTTCAGATCGACGGCAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGCAGCAGCAGAGGCATTAA |
|
Protein Sequence
|
MEHLISMLCCSSKESSSARIVDSSTCDIPNIQMSVMGNTNRVNPPPTPNHTSRRVEITSNGVLFRSTADLLEEVNRQLMMQQQRH |