Passionfruit leaf distortion virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_001876915.1 |
| Isolate | Colombia |
| Release date | 2016/11/13 |
| Submitter | Vaca-Vaca,J.C., Carrasco-Lozano,E.C., Lopez-Lopez,K., Carrasco-Lozano,E. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
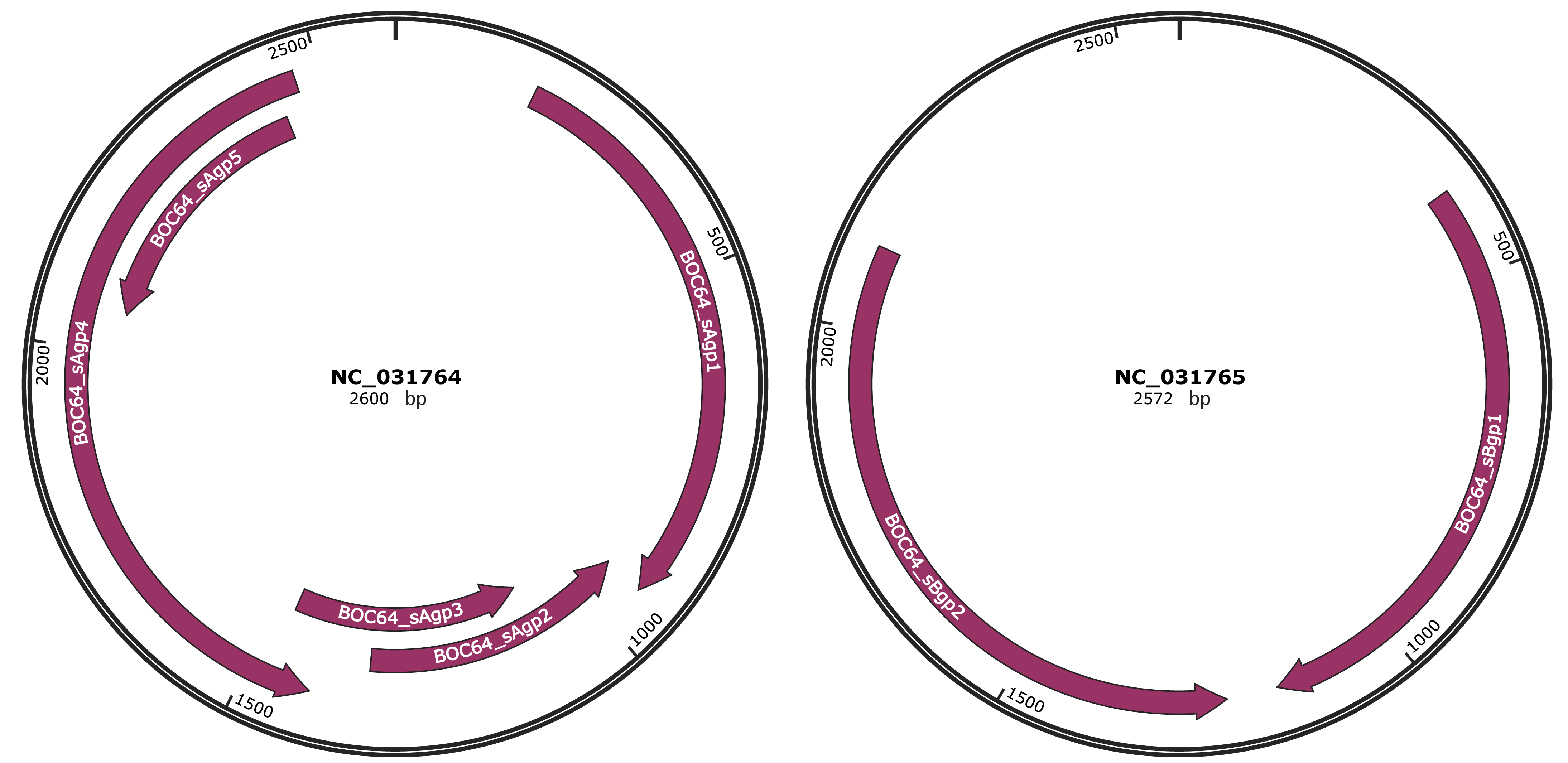
Genomic Organization
JBrowse
Genome
NC_031764
NC_031765
Gene Information
| NCBI Accession | YP_009316180.1 |
|---|---|
| Location | 186-941 |
| Protein Name | AV1 |
| Coding Region | ATGCCTAAGCGGGATGCCCCATGGCGCTCGATGGCGGGAACCTCAAAGGTTAGTCGCAATGCCAATTACTCTCCTCGTTCAGGCAGTGGCCCAAAGTTAAATAGGGCCTCTGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTTAGGACTCCTGATGTCCCACGAGGATGTGAAGGCCCGTGTAAGGTACAGTCCTACGAACAGCGTCACGACATATCCCATGTTGGCAAGGTAATGTGTATCTCTGATGTCACACGTGGTAATGGTATCACCCACCGTGTCGGCAAGCGTTTCTGTGTTAAGTCTGTGTATATCCTAGGCAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCCGAGACCGTAGACCGTATGGAACTCCCATGGACTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACAGCTACGGTTAAGAACGATCTCCGCGATCGTTACCAGGTCATGCATAAGTTCTATGGGAAGGTGACAGGTGGACAATATGCCAGCAATGAACAGGCAATCGTCAAGCGTTTCTGGAAGGTCAACAACCACGTTGTCTACAACCATCAAGAGGCTGGCAAATATGAGAATCACACGGAGAACGCCTTGTTATTGTACATGGCATGTACCCATGCATCTAACCCCGTCTATGCAACTCTCAAGATTCGGATCTATTTTTACGATTCGATTTTGAATTAA |
| Protein Sequence | MPKRDAPWRSMAGTSKVSRNANYSPRSGSGPKLNRASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
| NCBI Accession | YP_009316181.1 |
|---|---|
| Location | 938-1336 |
| Protein Name | AC3 |
| Coding Region | ATGGATTCACGCACAGGGGAGTTCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTATATTTCAAGATAATTCAAGTAGAGGACCTGCGATATACGATGACCAGGGTATATCACGTGCAAATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACAGTATCCCTGACAGCTTCTGGGTTGACTTATTTAAATAGGTTTAGACATTTAGTCCTCATGTATTTAGATCAGTTAGGCGTAATTTCTATTAACAATGTCATTAGAGCTGTTCGATTCGCAACAGACAGGGTTTATGTATCTCATGTACTGGAAAATCATTCAATAAAATATAAATTTTATTAA |
| Protein Sequence | MDSRTGEFITARQAENGVYIWEIENPLYFKIIQVEDLRYTMTRVYHVQIRFNHNLRRALHLHKAYLNFQVWTVSLTASGLTYLNRFRHLVLMYLDQLGVISINNVIRAVRFATDRVYVSHVLENHSIKYKFY |
| NCBI Accession | YP_009316182.1 |
|---|---|
| Location | 1083-1472 |
| Protein Name | AC2 |
| Coding Region | ATGCGATCTTCATCACCCTCGAATCCCCCCTCTATCAAGATAGCACACAGACAGGCTAAGAGGCGTGCGATCAGACGACGACGCATTGACTTGCAGTGCGGGTGCTCCATTTACTTCCACATAGGCTGCACGGGACATGGATTCACGCACAGGGGAGTTCATCACTGCACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTATATTTCAAGATAATTCAAGTAGAGGACCTGCGATATACGATGACCAGGGTATATCACGTGCAAATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACAGTATCCCTGACAGCTTCTGGGTTGACTTATTTAAATAG |
| Protein Sequence | MRSSSPSNPPSIKIAHRQAKRRAIRRRRIDLQCGCSIYFHIGCTGHGFTHRGVHHCTSGREWRVYLGDRKSPIFQDNSSRGPAIYDDQGISRANTVQPQPEESVASPQSLPELPSLDSIPDSFWVDLFK |
| NCBI Accession | YP_009316183.1 |
|---|---|
| Location | 1414-2469 |
| Protein Name | AC1 |
| Coding Region | ATGCCACCGCCTAGGAAATTCAGAGTGAATGCCAAGAACTATTTCCTCACTTATCCACAATGCTCTCTTACTAAAGCAGAAGTACTTTCCCAAATTCAACACATTAAAACCCCAGTTAATAAGAAGTTCATCAAGGTCTCCAGGGAATTACACGAAAATGGGGAGCCTCATCTCCACGTCCTCATCCAGTTCGAAGGGAAATACCAATGCCAGAATAACAGATTCTTCGATCTGGTCTCCCCAACTAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGTCGAGCTCCGACGTCAAGTCTTACATCGACAAGGACGGAGACACAGTTGAATGGGGACAGTTCCAGATCGACGGCAGGTCTGCTAGAGGAGGTCAGCAGTCTACTAACGACACATATGCCAAGGCGTTGAATGCAGGATCAGCAGAGGCTGCCCTGCAAATAATAAAGGAAGAACAACCGCAACATTTCTTCCTTCAGCATCACAACCTGGTTGCTAACGCAACCAGAATATTCCAAAAGGCTCCTGAACCGTGGGTTCCTCCGTTTCCACTCTCCTCCTTCACTAACGTGCCCGACGAGATGCAAGAGTGGGCAGATAGTTATTTTTCTTTGAGTCCAGCTGCGCGGCCGGAAAGACCTATTAGTATCATCGTCGAAGGTGATTCTAGGACGGGGAAGACGATGTGGGCACGTGCGTTAGGCCCACATAATTATCTCAGTGGACACCTAGACTTCAATTCCCGGGTTTTCTCAGACGAAGTGGAGTATAACGTAATAGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGATAGGGGCTCAAAAGATGTGGCAGTCAAATTGCAAGTACGGTAAGCCAGTCCTTATTAAAGGGGGGATTCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAAGCGGAAAATGCATCGCTCAGAAACTGGACGTTAAAGAATGCGATCTTCATCACCCTCGAATCCCCCCTCTATCAAGATAGCACACAGACAGGCTAA |
| Protein Sequence | MPPPRKFRVNAKNYFLTYPQCSLTKAEVLSQIQHIKTPVNKKFIKVSRELHENGEPHLHVLIQFEGKYQCQNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTVEWGQFQIDGRSARGGQQSTNDTYAKALNAGSAEAALQIIKEEQPQHFFLQHHNLVANATRIFQKAPEPWVPPFPLSSFTNVPDEMQEWADSYFSLSPAARPERPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVFSDEVEYNVIDDVAPHYLKLKHWKELIGAQKMWQSNCKYGKPVLIKGGIPSIVLCNPGEGASYKDFLNKAENASLRNWTLKNAIFITLESPLYQDSTQTG |
| NCBI Accession | YP_009316184.1 |
|---|---|
| Location | 2055-2441 |
| Protein Name | AC4 |
| Coding Region | ATGCCAAGAACTATTTCCTCACTTATCCACAATGCTCTCTTACTAAAGCAGAAGTACTTTCCCAAATTCAACACATTAAAACCCCAGTTAATAAGAAGTTCATCAAGGTCTCCAGGGAATTACACGAAAATGGGGAGCCTCATCTCCACGTCCTCATCCAGTTCGAAGGGAAATACCAATGCCAGAATAACAGATTCTTCGATCTGGTCTCCCCAACTAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGTCGAGCTCCGACGTCAAGTCTTACATCGACAAGGACGGAGACACAGTTGAATGGGGACAGTTCCAGATCGACGGCAGGTCTGCTAGAGGAGGTCAGCAGTCTACTAACGACACATATGCCAAGGCGTTGA |
| Protein Sequence | MPRTISSLIHNALLLKQKYFPKFNTLKPQLIRSSSRSPGNYTKMGSLISTSSSSSKGNTNARITDSSIWSPQLGQHISIRTFRELSRAPTSSLTSTRTETQLNGDSSRSTAGLLEEVSSLLTTHMPRR |
| NCBI Accession | YP_009316185.1 |
|---|---|
| Location | 388-1158 |
| Protein Name | BV1 |
| Coding Region | ATGTATCCCTCGAGGAATAAACGTGGTTTGTCCTTCACCCCACGTCGATTTTATGCTCGAAACACTGTGTTCAACCGCCCGCATTCTGGAAAACGTCAAGCCTGGAAACGTCGAGGTGCCAATTCAAACAAGTCGGATGATGAGCCCAGAATGTCGTCCCAACGCATACATGAGAATCAGTATGGGCCAGAATTCGTTATGCCCCATAACCAAGCCATTTCTACGTTTATCAGCTACCCATGCGTTGGTAAGACCGAGCCCAACCGAAGTAGGTCCTATATTAAGTTGAAACGACTCCGTTTCAAGGGTACTGTGAAGATTGAACGTGTTCAACCAGATATGAACATGGATGGTTCTACCCCCAAAGTGGAAGGAGTGTTTACTCTCGTGGTGGTTATGGATCGCAAACCCCACCTGGGTGCATCTGGGTGTCTGCATACATTCGACGAGCTGTTCGGTGCAAGGATCCATAGCCATGGTAACCTGAGCATAACCCCCTCTCTGAAAGACCGTTTCTACATACGACACGTATTCAAACGTGTATTGTCCGTGGAGAAGGATACGATGATGGTCGACGTGGAAGGATCTACAACGCTCTCTAACAGGCGTTTTAATTGCTGGTCCACATTCAAGGATCTTGATCATGACTCATGCAACGGTGTTTATGATAACATTAGCAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCAGATACTGTGTCTAAGGCATCAACATTTGTATCGTTTGACCTTGATTATATAGGTTGA |
| Protein Sequence | MYPSRNKRGLSFTPRRFYARNTVFNRPHSGKRQAWKRRGANSNKSDDEPRMSSQRIHENQYGPEFVMPHNQAISTFISYPCVGKTEPNRSRSYIKLKRLRFKGTVKIERVQPDMNMDGSTPKVEGVFTLVVVMDRKPHLGASGCLHTFDELFGARIHSHGNLSITPSLKDRFYIRHVFKRVLSVEKDTMMVDVEGSTTLSNRRFNCWSTFKDLDHDSCNGVYDNISKNALLVYYCWMSDTVSKASTFVSFDLDYIG |
| NCBI Accession | YP_009316186.1 |
|---|---|
| Location | 1225-2106 |
| Protein Name | BC1 |
| Coding Region | ATGGATTCTCAGTTAGTAAATCCTCCAAGTGCCTTTAACTACATAGAGTCCCATCGGGACGAGTACCAGCTTTCTCATGACCTAACTGAGATAATTATGCAATTCCCGTCGACGGCGTCTCAGTTAACAGCCAGACTCAGTCGGAGTTGCATGAAAATAGACCACTGCGTCATAGAGTACCGACAACAGGTTCCAATTAACGCGACGGGATCTGTTATAGTGGAGATTCATGACAAGAGAATGACCGACAACGAGTCTTTGCAGGCGTCGTGGACTTTTCCGATCAGATGCAACATAGATCTCCACTATTTCTCATCTTCCTTCTTTTCCCTCAAAGATCCTATTCCTTGGAAACTCTATTACAGAGTTTGTGATACGAATGTTCATCAGAGGACCCACTTCGCCAAGTTCAAAGGGAAATTGAAACTATCCACGGCTAAACACTCCGTAGATATCCCCTTCCGGGCACCGACGGTTAAGATCTTGTCCAAACAGTTCACCGACAAAGACGTGGATTTCTCCCACGTGGACTATGGGAGATGGGAAAGGAAGATAATAAGGTCCGCATCCATGTCCAGGATTGGGCTTCCGGGCCCAATTGAAATAAAGCCAGGAGAGTCGTGGGCTTCAAGGAGTACAGTTGGGCTAAGTAATTCGGATGCGGACTCGGAGGTGGAGAACGCAATGCATCCATATAGACATCTCAGTAGGCTGGGAACGAGCGTGTTAGACCCAGGGGAGTCTGCTTCGATTGTAGGAGCCCAGCGAGCCGAATCCAACATTACTATGACAGTGGGCCAGTTGAACGAGCTTGTTCGATCCACTGTACAAGAATGTATTAATAGTAATTGTAAGGCTACTCAGCCCAAATCACTACAATAA |
| Protein Sequence | MDSQLVNPPSAFNYIESHRDEYQLSHDLTEIIMQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKIIRSASMSRIGLPGPIEIKPGESWASRSTVGLSNSDADSEVENAMHPYRHLSRLGTSVLDPGESASIVGAQRAESNITMTVGQLNELVRSTVQECINSNCKATQPKSLQ |
References More References in PubMed
| 1 |
Melo AM, et al. Arch Virol. 2016 Sep;161(9):2605-8. doi: 10.1007/s00705-016-2919-3. Epub 2016 Jun 8. PMID: 27278930 |
|---|---|
| 2 |
Genomics insight on passion fruit viral disease complexity. Munguti F, et al. Microbiol Spectr. 2025 Oct 7;13(10):e0034425. doi: 10.1128/spectrum.00344-25. Epub 2025 Aug 29. PMID: 40879375 |
| 3 |
Chen S, et al. Virol J. 2018 Nov 1;15(1):168. doi: 10.1186/s12985-018-1084-6. PMID: 30382859 |
| 4 |
A new species of Neohydatothrips (Thysanoptera: Thripidae) from India. Rachana RR. Zootaxa. 2021 Jan 28;4920(2):zootaxa.4920.2.10. doi: 10.11646/zootaxa.4920.2.10. PMID: 33756672 |
| 5 |
Vaca-Vaca JC, et al. Arch Virol. 2017 Feb;162(2):573-576. doi: 10.1007/s00705-016-3098-y. Epub 2016 Oct 14. PMID: 27743253 |