Okra yellow mosaic Mexico virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000889735.1 |
| Isolate | Mexico: Morelos |
| Release date | 2015/2/22 |
| Submitter | De La Torre-Almaraz,R., Monsalvo-Reyes,A., Ambriz-Granados,S., Arguello-Astorga,G.R., Monsalvo-Reyes,R., De la Torre-Almaraz,R., Mauricio-Castillo,J.A. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
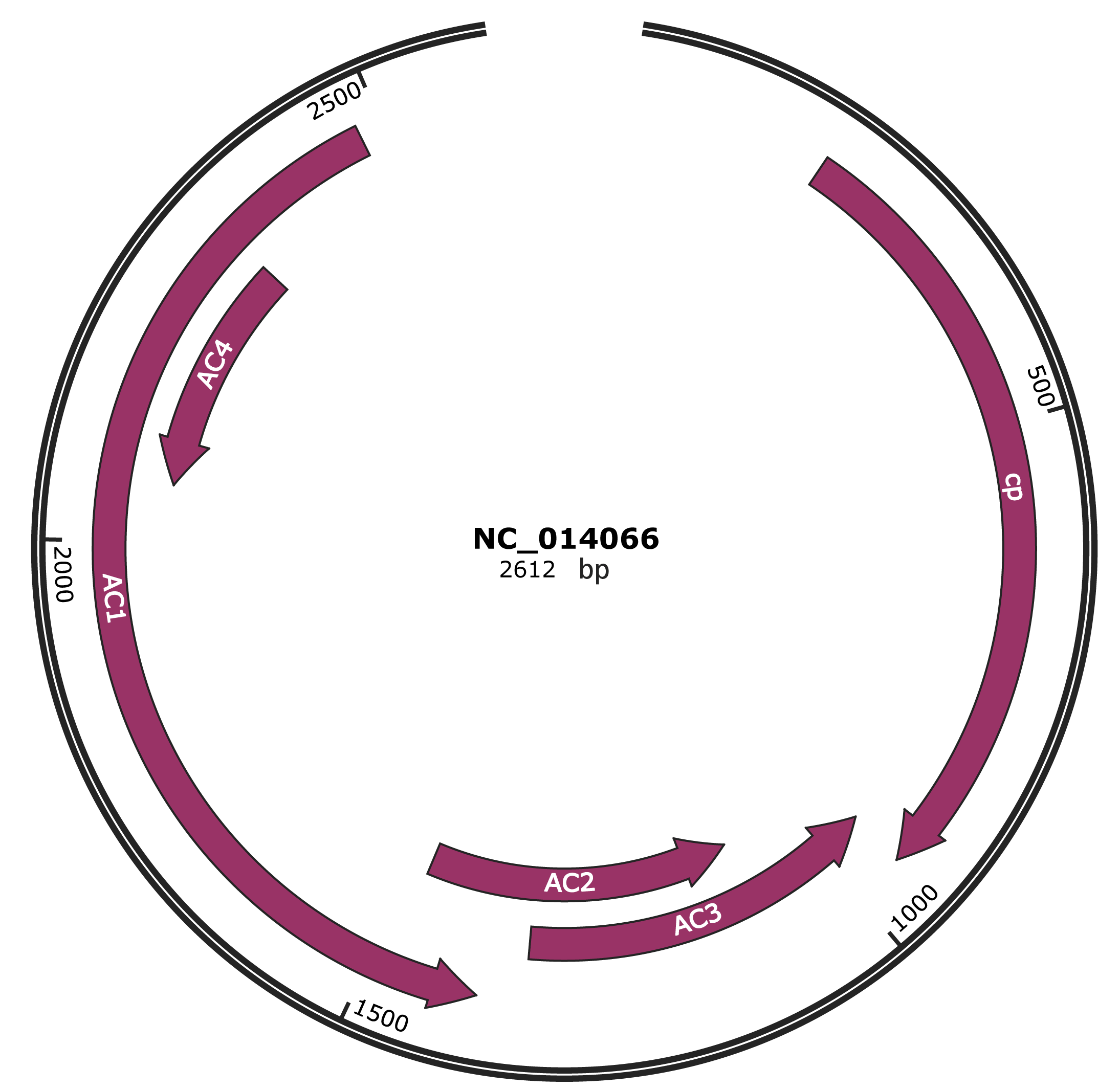
Genomic Organization
JBrowse
Genome
NC_014066
Gene Information
| NCBI Accession | YP_003587818.1 |
|---|---|
| Location | 194-949 |
| Gene Name | cp |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGCGATCTCCCATGGCGCTCGATCGCGGGAACCTCAAAGGTGAGCCGCAATGCTAATTATTCTCCTCGTGCAGGAAGTGGGCCAAGAGTTAACAAGGCCTCTGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACAATGAGAACGCCCGACGTGCCAAGAGGCTGTGAAGGGCCTTGCAAGGTCCAGTCCTTTGAACAGCGTCATGATGTCTCTCACGTGGGTAAGGTCATTTGTATATCTGATGTGACACGTGGTAATGGTATCACTCACCGTGTAGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATCCTCGGTAAGATCTGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCAGGGATCGTAGACCGTATGGCACGCCCATGGATTTCGGGCAAGTGTTCAACATGTTCGACAACGAGCCTAGCACTGCCACGGTGAAGAACGACCTACGCGACCGCTACCAGGTGATGCACAAGTTTTACGGCAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCGATAGTCAAGCGCTTCTGGAAGGTCAACAATCATGTGGTGTACAACCACCAGGAAGCTGGCAAGTACGAGAATCACACGGAGAATGCTTTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTATATGCAACGCTTAAGATTCGGATCTACTTCTACGATTCGATCATGAATTAA |
| Protein Sequence | MPKRDLPWRSIAGTSKVSRNANYSPRAGSGPRVNKASEWVNRPMYRKPRIYRTMRTPDVPRGCEGPCKVQSFEQRHDVSHVGKVICISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_003587819.1 |
|---|---|
| Location | 946-1344 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAGAGCGAGAATGGCGTCTATATCTGGGAGATAGAAAATCCCCTGTATTTCAAGATGTACCGAGTAGAAGATCCACTATACACGAGGACCAGAGTATACCACGTACAAATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAGGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGACTTATTTAGCTAGGTTTATGCACTTAGTTAATTTGTATTTAGATCGATTAGGCGTAATTTCACTTAACAATGTAATCAGAGCTGTTCGTTTCGCAACGGATAGATCTTATGTAAATTATGTGCTGGAAAATCATTCAATAAAATTTAAACTTTATTAA |
| Protein Sequence | MDSRTGELITAPQSENGVYIWEIENPLYFKMYRVEDPLYTRTRVYHVQIRFNHNLRRALHLHKAYLNFQVWTTSMTASGSTYLARFMHLVNLYLDRLGVISLNNVIRAVRFATDRSYVNYVLENHSIKFKLY |
| NCBI Accession | YP_003587820.1 |
|---|---|
| Location | 1091-1480 |
| Gene Name | AC2 |
| Protein Name | transcription activator protein |
| Coding Region | ATGCGCTCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCACACAGGCAAGCCAAGAGGAGAGCCATCAGGAGGAGGCGGATTGATCTGGAGTGCGGGTGCTCCATATACTTACACATAGGCTGTACGGGTCATGGATTCACGCACAGGGGAACTCATCACTGCACCTCAGAGCGAGAATGGCGTCTATATCTGGGAGATAGAAAATCCCCTGTATTTCAAGATGTACCGAGTAGAAGATCCACTATACACGAGGACCAGAGTATACCACGTACAAATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAGGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGACTTATTTAGCTAG |
| Protein Sequence | MRSSSPSHPPSIKTAHRQAKRRAIRRRRIDLECGCSIYLHIGCTGHGFTHRGTHHCTSEREWRLYLGDRKSPVFQDVPSRRSTIHEDQSIPRTNTVQPQPEESVASPQGLPELPSLDDIDDSFWVDLFS |
| NCBI Accession | YP_003587821.1 |
|---|---|
| Location | 1392-2477 |
| Gene Name | AC1 |
| Protein Name | replication initiator protein |
| Coding Region | ATGCCACCGCCTAAACGATTTCAGATAAATCAGAAAAACTATTTCCTCACATATCCACAGTGTTCTCTTACAAAAGAAGAGGCACTTTCCCAATTACAAAACCTAAACACTCCGGTCAACAAGAAATTCATCAAAATCTGCAGAGAACTTCACGAAGATGGGCAACCTCATCTGCACGTCCTTATCCAGTTCGAGGGGAAATACAGATGCACGAATAACAGATTCTTCGACCTGGTGTCCCCAAGTCGGTCAGCACATTTCCATCCGAACATTCAGGGAACTAAATCCAGCTCCGACGTCAAATCCTATATCGACAAGGACGGAGATACAATCGAATGGGGAGAATTTCAGATCGACGGCAGATCTGCTAGAGGAGGCCAGCAATCAGCTAACGATACATATGCCAAGGCGTTGAATGCATCGTCGGCGGAGGAAGCGCTGCGTATTATCAAAGAAGAACAACCGCAACATTTCTTCCTTCAGCACCACAACCTCGTCGCCAACGCCACCAAAATATTCCAAAAGGCTCCGGAACCATGGGTCCCTCCGTTTCAACTCTCCTCGTTCACTAACGTGCCTGACGAGATGCAAGAGTGGGTCGATGAATATTTTGGAAGGGATCCCGCTGCGCGGCCTGAGAGACCAGTTAGTATCATCGTTGAAGGTGATTCGAGGACCGGAAAGACAATGTGGGCACGTGCGCTAGGCCCACATAACTACCTCAGTGGACACCTGGACTTCAACCCACGAGTCTATTCAAACGAAGTGGAGTATAACGTCATTGACGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGATCGGGGCCCAAAAGGATTGGCAGTCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGAGGTATCCCATCAATCGTGCTTTGCAATCCAGGTGAGGGTGCAAGCTATAAAGATTTCCTCGACAAAGAGGAAAACGCATCACTCAGGAACTGGACCATCAAGAATGCGCTCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCACACAGGCAAGCCAAGAGGAGAGCCATCAGGAGGAGGCGGATTGA |
| Protein Sequence | MPPPKRFQINQKNYFLTYPQCSLTKEEALSQLQNLNTPVNKKFIKICRELHEDGQPHLHVLIQFEGKYRCTNNRFFDLVSPSRSAHFHPNIQGTKSSSDVKSYIDKDGDTIEWGEFQIDGRSARGGQQSANDTYAKALNASSAEEALRIIKEEQPQHFFLQHHNLVANATKIFQKAPEPWVPPFQLSSFTNVPDEMQEWVDEYFGRDPAARPERPVSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNPRVYSNEVEYNVIDDVAPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENASLRNWTIKNALFITLTSALYQDSTQASQEESHQEEAD |
| NCBI Accession | YP_003587822.1 |
|---|---|
| Location | 2063-2320 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGCAACCTCATCTGCACGTCCTTATCCAGTTCGAGGGGAAATACAGATGCACGAATAACAGATTCTTCGACCTGGTGTCCCCAAGTCGGTCAGCACATTTCCATCCGAACATTCAGGGAACTAAATCCAGCTCCGACGTCAAATCCTATATCGACAAGGACGGAGATACAATCGAATGGGGAGAATTTCAGATCGACGGCAGATCTGCTAGAGGAGGCCAGCAATCAGCTAACGATACATATGCCAAGGCGTTGA |
| Protein Sequence | MGNLICTSLSSSRGNTDARITDSSTWCPQVGQHISIRTFRELNPAPTSNPISTRTEIQSNGENFRSTADLLEEASNQLTIHMPRR |
References More References in PubMed
| 1 |
First Report of Okra yellow mosaic Mexico virus in Okra in the United States. Hernandez-Zepeda C, et al. Plant Dis. 2010 Jul;94(7):924. doi: 10.1094/PDIS-94-7-0924B. PMID: 30743573 |
|---|---|
| 2 |
De La Torre-Almaraz R, et al. Plant Dis. 2006 Mar;90(3):378. doi: 10.1094/PD-90-0378B. PMID: 30786574 |
| 3 |
Sandra N, et al. Front Plant Sci. 2024 May 14;15:1376284. doi: 10.3389/fpls.2024.1376284. eCollection 2024. PMID: 38807782 |
| 4 |
First Report of a Geminivirus Inducing Yellow Mottle in Okra (Abelmoschus esculentus) in Mexico. De La Torre-Almaráz R, et al. Plant Dis. 2003 Feb;87(2):202. doi: 10.1094/PDIS.2003.87.2.202B. PMID: 30812935 |
| 5 |
García-Rodríguez DA, et al. PeerJ. 2023 Mar 22;11:e15047. doi: 10.7717/peerj.15047. eCollection 2023. PMID: 36974135 |
| 6 |
Hernández-Zepeda C, et al. Virus Genes. 2007 Oct;35(2):369-77. doi: 10.1007/s11262-007-0080-5. Epub 2007 Feb 15. PMID: 17638064 |
| 7 |
Hernández-Zepeda C, et al. Virus Genes. 2007 Dec;35(3):825-33. doi: 10.1007/s11262-007-0149-1. Epub 2007 Aug 8. PMID: 17682933 |