Okra mottle virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000875625.1 |
| Isolate | Brazil |
| Release date | 2015/2/13 |
| Submitter | Aranha,S.A., Inoue-Nagata,A.K. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
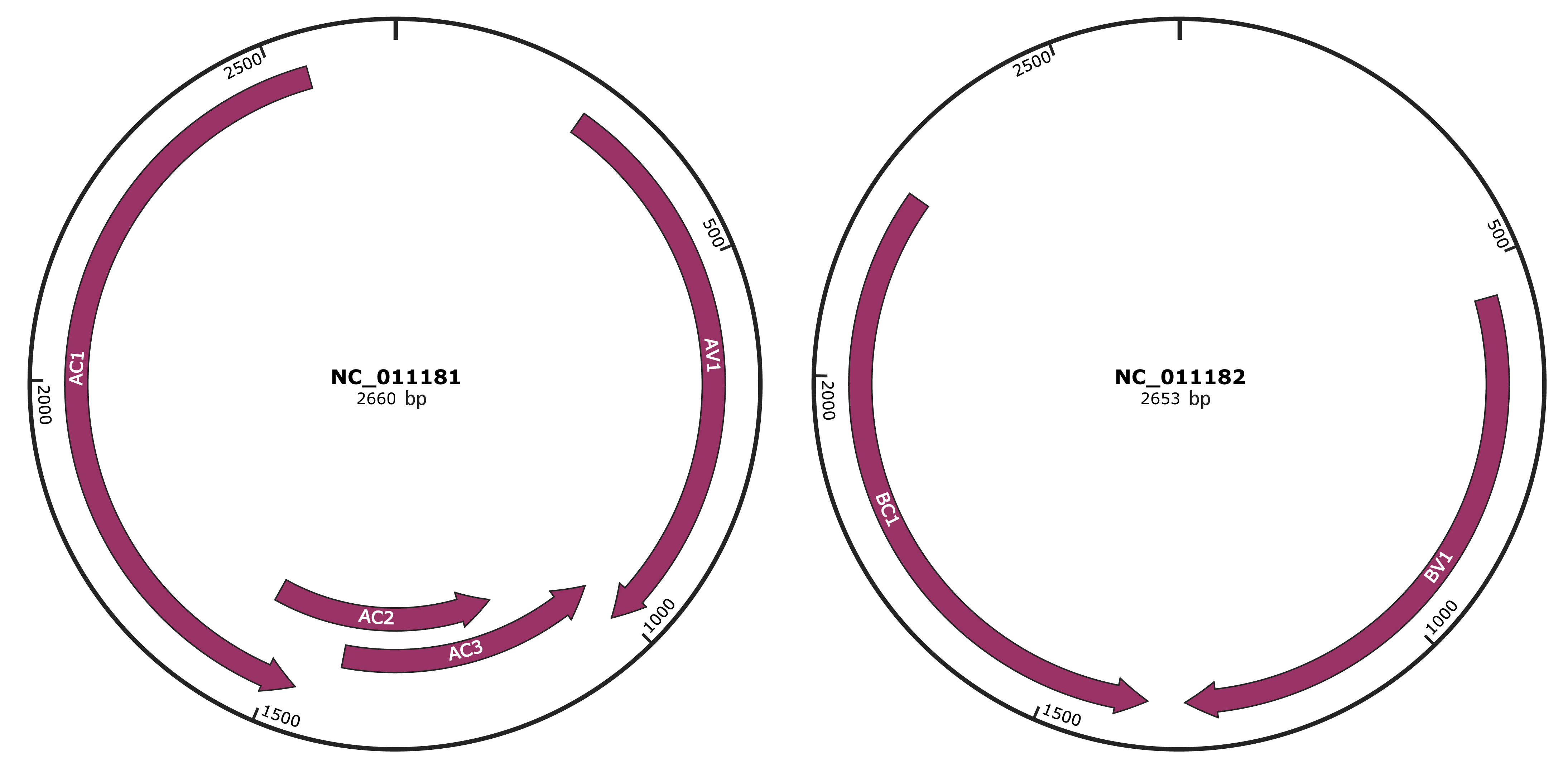
JBrowse
Genome
NC_011181
NC_011182
Gene Information
| NCBI Accession | YP_002154617.1 |
|---|---|
| Location | 259-1014 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCCAAGCGGGATCCCTCATGGCGCCAGATGGCGGGAACCTCAAAGGTTAGCCGCACTACCAACTTTTCCCCTCGTGGAGGTGGAGGCCCAAAGTACAACAAGGCCTCGGAGTGGGTTCACAGGCCTATGTATAGGAAGCCCAGGATATACAGGATGATAAGGACTCCTGATGTTCCAAGAGGCTGTGAAGGGCCCTGCAAGGTTCAATCCTACGAGCAGCGTCACGACATCTCACATGTCGGGAAGGTCATGTGCATATCTGATGTCACACGTGGCAATGGTATAACCCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTACATTTTAGGGAAGATATGGATGGACGAGAACATCAAGCTCAAGAACCACACGAACAGTGTCATATTCTGGTTGGTCAGAGACCGTAGACCGTATGGTACCCCTATGGAGTTTGGCCAGGTGTTTAACATGTTTGACAACGAGCCCAGCACTGCTACGGTGAAGAACGATCTCCGTGATCGTTATCAAGTCATGCACAAGTTCTATGCCAAGGTCACTGGTGGTCAATATGCCAGCAACGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTACAATCACCAGGAGGCTGGGAAGTATGAGAATCACACGGAGAATGCTCTGTTACTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGGATCTATTTCTACGATTCGATCACGAATTAA |
| Protein Sequence | MPKRDPSWRQMAGTSKVSRTTNFSPRGGGGPKYNKASEWVHRPMYRKPRIYRMIRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVIFWLVRDRRPYGTPMEFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_002154618.1 |
|---|---|
| Location | 1011-1409 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACCGGGGAATTCATAACTGCACCTCAGACAGAGAATGGCGTCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATATACAACCTAGAGGATCTACCGTACACGAGAACCAGAATATACCACATACAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCCTACCTCAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGACGACATATTTAGCTAGGTTTAAGATGCTAGTCATGATGTACTTAGACCAATTAGGTGTAATTGCCATTAATAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAGGCCATATGTCAGTTATGTACTCGAAAATCATTCAATAAAATTCAAACTTTATTAA |
| Protein Sequence | MDSRTGEFITAPQTENGVYIWEVPNPLYFKIYNLEDLPYTRTRIYHIQIRFNHNLRRALGLHKAYLNFQVWTTSLTASGTTYLARFKMLVMMYLDQLGVIAINNVIRAVRFATDRPYVSYVLENHSIKFKLY |
| NCBI Accession | YP_002154619.1 |
|---|---|
| Location | 1156-1545 |
| Gene Name | AC2 |
| Protein Name | transactivation protein |
| Coding Region | ATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACCGAGACACAGGATTGCCAAGAAGAGAGCCATCAGGCGTAGACGAGTGGACCTAGAGTGCGGCTGCTCGATATACGTCCACTTCAACTGCAACGGCCATGGATTCACGCACCGGGGAATTCATAACTGCACCTCAGACAGAGAATGGCGTCTATATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATATACAACCTAGAGGATCTACCGTACACGAGAACCAGAATATACCACATACAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCCTACCTCAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGACGACATATTTAGCTAG |
| Protein Sequence | MLNSSSSTPPSIKPRHRIAKKRAIRRRRVDLECGCSIYVHFNCNGHGFTHRGIHNCTSDREWRLYLGGSKSPLFQDIQPRGSTVHENQNIPHTDKVQPQPQESIGSPQGLPQLPSLDDFSDSFWDDIFS |
| NCBI Accession | YP_002154620.1 |
|---|---|
| Location | 1466-2545 |
| Gene Name | AC1 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCATCCAAACCACGTCGTTTTAGACTCCAAGCTAAAAACATTTTCCTTACTTATCCACAGTGCTCTCTTACAAAAGAGGAGGCACTTTCCCAATTGCAAGCTATTCAATTACCCTCTAATAAGAAATTCATCAAGATTTGCAGAGAGCTTCACGAAAATGGGGAACCTCACCTCCACGTCCTGTTGCAATTGGAAGGAAAGGTCCAAATCACAAATAACAGATTGTTCGACCTGGTTTCCCCAACAAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCTTACATCGACAAAGATGGAGATACAGTAGAATGGGGTGACTTCCAGGTCGACGGAAGGAGTTCTAGGGGAGGCCAACAGACAGCTAATGACGCTGCAGCTGAGGCGTTAAACGCTCCTGATAAACAGACGGCTCTTCAGTTAATTCGGGAAAAATTGCCAGAGAAATATCTTTTTCAGTTTCATAATTTAAATTCTAATTTAGATAGAATTTTCTCAAAGGCTCCGGAGCCGTGGGTTCCTCCGTTTAACCTCTCCTCCTTCACTAACGTTCCCGACGAGATGCAAGAGTGGGCCGATGAATATTTTGGGAGAGGTTCCGCTGCGCGGCCATTCAGACCTATGAGTTTGATAGTCGAAGGTGATTCAAGGACAGGGAAGACGATGTGGGCTCGTGCGTTAGGCCCACATAATTACTTGAGTGGTCATCTGGACTTCAATTCTAAGGTTTACTCGAACGAAGTGGAATACAACGTCATTGACGATGTCACACCGCAATATCTAAAGTTAAAGCACTGGAAGGAATTGATTGGTGCTCAAAAAGACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGTGGCATCCCATCAATCGTGCTGTGCAATCCTGGAGAGGGGGCTAGCTATAAAGACTTCCTAGACAAGGAGGAAAATGCAGCTCTGAAATCGTGGACACTCCACAATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAACCGAGACACAGGATTGCCAAGAAGAGAGCCATCAGGCGTAG |
| Protein Sequence | MPSKPRRFRLQAKNIFLTYPQCSLTKEEALSQLQAIQLPSNKKFIKICRELHENGEPHLHVLLQLEGKVQITNNRLFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTVEWGDFQVDGRSSRGGQQTANDAAAEALNAPDKQTALQLIREKLPEKYLFQFHNLNSNLDRIFSKAPEPWVPPFNLSSFTNVPDEMQEWADEYFGRGSAARPFRPMSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVYSNEVEYNVIDDVTPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKEENAALKSWTLHNAKFIFLDAPLYQTETQDCQEESHQA |
| NCBI Accession | YP_002154621.1 |
|---|---|
| Location | 549-1319 |
| Gene Name | BV1 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTTTCCCATTAGGTATAGACGTGGTTGGTCGTCTAATCAGCGACGAGGTTACACACGTAATCCCGTGTTTAAGCGTTATTATGTAGCTAAACGAAGTGATTTCAAGCGACGACCCAGTAATACTAACAAGGCCCAAGAAGATGGCAAGATGTCTACTCAACGTATACACGAGAACCAGTTTGGGCCTGAATTTGTAATGGGCCACAACTCAGCCATTTCAACGTTTATTACATTTCCTAGCCTCGGTAAGACCGAGCCTAACCGAACCAGGTCCTATGTCAAGCTAAAACGACTCCGTTTTAAGGGTACTGTGAAGATTGAACGTGTTTACAATGACGTCATCATGGATGGTTCAACCCCAAAGATTGAAGGAGTCTTTTCCCTCGTGGTCGTGGTAGATCGTAAACCCCACTTGGGATCATCTGGGTGTCTGCACACGTTTGACGAGTTATTCGGTGCCAGGATCCACAGTCATGGCAATCTGGCTATAACACCCTCCCTGAAAGACCGCTTTTACATTCGACACGTGTTCAAACGTGTGTTATCTGTGGAGAAAGACACTTTGATGGTTGATCTTGAAGGGACTACATACCTCTCTAACAGGCGTTTTAATTGTTGGTCAACGTTTAAGGATATTGACCGTGAATCATGTAACGGTGTTTATGCAAACATAAGCAAGAACGCCCTGTTAGTTTACTACTGTTGGATGTCGGACTCGTCGTCCAAGGCATCGACATTTGTATCATATGATCTCGATTACATCGGTTAA |
| Protein Sequence | MFPIRYRRGWSSNQRRGYTRNPVFKRYYVAKRSDFKRRPSNTNKAQEDGKMSTQRIHENQFGPEFVMGHNSAISTFITFPSLGKTEPNRTRSYVKLKRLRFKGTVKIERVYNDVIMDGSTPKIEGVFSLVVVVDRKPHLGSSGCLHTFDELFGARIHSHGNLAITPSLKDRFYIRHVFKRVLSVEKDTLMVDLEGTTYLSNRRFNCWSTFKDIDRESCNGVYANISKNALLVYYCWMSDSSSKASTFVSYDLDYIG |
| NCBI Accession | YP_002154622.1 |
|---|---|
| Location | 1369-2250 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGGTTCTCAGTTAGTTAATCCACCCAATGCCTTTAATTATATAGAATCTCAGCGTGATGAGTATCAGCTTTCTCATGACCTAACTGAGATCGTTCTGCAGTTTCCTTCTGCGGCGGCTCAGATAAGCGCCAGGCTCAGTCGCAGCTGTATGAAGATAGACCACTGCGTCATAGAATACAGGCAACAGGTACCCATAAACGCCACAGGTTCCGTCATCGTGGAGATCCACGACAAGAGAATGACGGACAATGAATCGTTACAGGCGTCCTGGACATTCCCGATCAGGTGCAACATAGATCTCCACTACTTTTCATGCTCGTTCTTCTCCCTGAAAGACCCAATTCCCTGGAAATTGTATTACAGAGTGAGCGACACGAATGTTCACCAGAGAACGCACTTCGCGAAATTCAAGGGGAAGCTAAAGCTGTCAACGGCGAAACATTCCGTCGACATTCCTTTCCGAGCACCGACGGTGAAGATCTTATCTAAACAGTTCACAGATAGAGACGTAGATTTCAGCCACGTGGGCTATGGGAAATGGGAAAGGAAATTGATCCGATCCGCATCCACAGTCAAGTATGGGCTCCCAAGCCCAATAACCATTGATCCAGGTGAGACATGGGCTTCACGCAGTACCATAGGGATCGGTCAATCGAGCACCGAGTCAGAGGTAGAGAACGCAACACACCCATATAGAGGGCTCCATAAACTGGGCACCAGCATGTTGGACCCAGGTGACTCGGCTTCCATAGTTGCTGCGAGAAGGGCCGAATCGCATATAACCATGTCCGAGGCACAATTAAACGACCTAGTGAGGAGTGCGGTCCAGGAGTGTATTAAAACAAATTGTATTCCCCCACAGCCCAAATCATTAAGTTAA |
| Protein Sequence | MGSQLVNPPNAFNYIESQRDEYQLSHDLTEIVLQFPSAAAQISARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSCSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDRDVDFSHVGYGKWERKLIRSASTVKYGLPSPITIDPGETWASRSTIGIGQSSTESEVENATHPYRGLHKLGTSMLDPGDSASIVAARRAESHITMSEAQLNDLVRSAVQECIKTNCIPPQPKSLS |
References More References in PubMed
| 1 |
Ability of Non-Hosts and Cucurbitaceous Weeds to Transmit Cucumber Green Mottle Mosaic Virus. Lovelock DA, et al. Viruses. 2023 Mar 4;15(3):683. doi: 10.3390/v15030683. PMID: 36992392 |
|---|---|
| 2 |
De La Torre-Almaraz R, et al. Plant Dis. 2006 Mar;90(3):378. doi: 10.1094/PD-90-0378B. PMID: 30786574 |
| 3 |
Further evidence reveals that okra mottle virus arose from a double recombination event. Albuquerque LC, et al. Arch Virol. 2013 Jan;158(1):181-6. doi: 10.1007/s00705-012-1458-9. Epub 2012 Sep 1. PMID: 22941555 |
| 4 |
First Report of a Geminivirus Inducing Yellow Mottle in Okra (Abelmoschus esculentus) in Mexico. De La Torre-Almaráz R, et al. Plant Dis. 2003 Feb;87(2):202. doi: 10.1094/PDIS.2003.87.2.202B. PMID: 30812935 |
| 5 |
Complete nucleotide sequence and experimental host range of Okra mosaic virus. Stephan D, et al. Virus Genes. 2008 Feb;36(1):231-40. doi: 10.1007/s11262-007-0181-1. Epub 2007 Nov 30. PMID: 18049886 |
| 6 |
First Report of Tomato mosaic virus on Hibiscus rosa-sinensis in China. Huang JG, et al. Plant Dis. 2004 Jun;88(6):683. doi: 10.1094/PDIS.2004.88.6.683C. PMID: 30812606 |
| 7 |
Hernández-Zepeda C, et al. Virus Genes. 2007 Dec;35(3):825-33. doi: 10.1007/s11262-007-0149-1. Epub 2007 Aug 8. PMID: 17682933 |
| 8 |
Three distinct begomoviruses associated with soybean in central Brazil. Fernandes FR, et al. Arch Virol. 2009;154(9):1567-70. doi: 10.1007/s00705-009-0463-0. Epub 2009 Jul 28. PMID: 19636495 |
| 9 |
Daliyamol, et al. Virusdisease. 2019 Jun;30(2):227-236. doi: 10.1007/s13337-018-0500-2. Epub 2018 Nov 27. PMID: 31179361 |
| 10 |
Paul HL, et al. Intervirology. 1980;13(2):99-109. doi: 10.1159/000149114. PMID: 7372445 |