Okra enation leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000887915.1 |
| Isolate | India: Munthal, Haryana |
| Release date | 2015/2/22 |
| Submitter | Venkataravanappa,V., Lakshminarayana Reddy,C.N., Jalali,S., Krishna Reddy,M., Lakshiminarayanareddy,C.N., Devaraju, Swaranalatha,P., Krishnareddy,M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
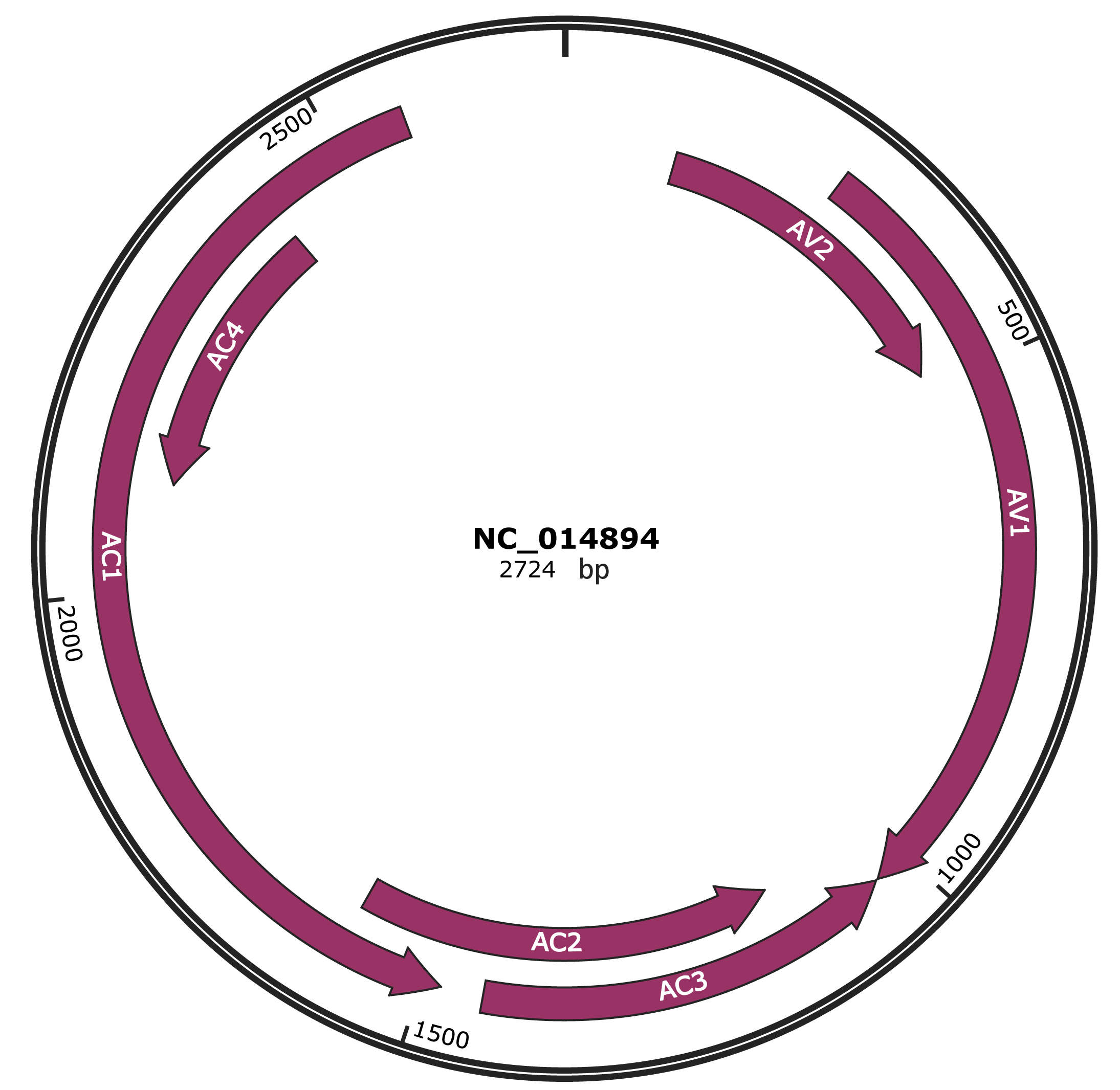
Genomic Organization
JBrowse
Genome
NC_014894
Gene Information
| NCBI Accession | YP_004123717.1 |
|---|---|
| Location | 121-486 |
| Gene Name | AV2 |
| Protein Name | precoat protein |
| Coding Region | ATGTGGGATCCATTGTTAAACGAGTTCCCTGAGACGGTTCACGGGTTTCGTTGCATGCTTGCTATTAAATATCTTCAACAACTGTCTGAGGAATACTCTCCTGATACGGTTGGGTACGATCTAATTCGCGATCTAATTTCTATTTTACGTTGTAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCGTATTCAACCCGTGCAGTTGCCCCCACTGTCCGCGTCACAAAATCACGAATGTGGGCCAACAGACCCATGTACCGGAAGCCCAGAATGTACAGGATATACAGAAGCCCGGATGTTCCAAGAGGATGTGA |
| Protein Sequence | MWDPLLNEFPETVHGFRCMLAIKYLQQLSEEYSPDTVGYDLIRDLISILRCRNYVEASCRYRHFYPRVEGASSTELRQPVFNPCSCPHCPRHKITNVGQQTHVPEAQNVQDIQKPGCSKRM |
| NCBI Accession | YP_004123718.1 |
|---|---|
| Location | 281-1033 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCGTATTCAACCCGTGCAGTTGCCCCCACTGTCCGCGTCACAAAATCACGAATGTGGGCCAACAGACCCATGTACCGGAAGCCCAGAATGTACAGGATATACAGAAGCCCGGATGTTCCAAGAGGATGTGAAGGCCCATGTAAGGTGCAGTCTTTTGATGCGAAGAACGATATTGGTCACATGGGTAAGGTTATCTGTCTATCTGATGTTACTAGGGGTATTGGGCTGACCCATCGAGTAGGGAAACGTTTTTGCGTGAAGTCATTGATTTGCAGGGAGAACATCAAGACCAAGAACCATACGAATTCGGTGATGTTTTGGATCGTGAGAGACAGGCGTCCTACAGGCACCCCCTACGATTTCCAGCAAGTGTTCAATGTTTATGACAACGAGCCTTCTACGGCTACTGTAAAGAACGACCAGCGTGATCGATTCCAGGTTTTGAGGAGGTTTCAGGCGACAGTTACAGGAGGACAGTATGCTTGTAAGGAACAAGTTCCAATTAGGAAATTCTATCGTGTTAACAATTACGTGGTGTATAATCACCAGGAAGCTGGGAAGTATGAAAATCACACTGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACTTTGAAAGTTAGGAGTTACTTCTACGATTCTGTAACGAATTAA |
| Protein Sequence | MSKRPADIVISTPASKVRRRLNFDSPYSTRAVAPTVRVTKSRMWANRPMYRKPRMYRIYRSPDVPRGCEGPCKVQSFDAKNDIGHMGKVICLSDVTRGIGLTHRVGKRFCVKSLICRENIKTKNHTNSVMFWIVRDRRPTGTPYDFQQVFNVYDNEPSTATVKNDQRDRFQVLRRFQATVTGGQYACKEQVPIRKFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKVRSYFYDSVTN |
| NCBI Accession | YP_004123719.1 |
|---|---|
| Location | 1036-1440 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCTCGCACAGGGGAACGCATCACTGCAGCTCATACAAGGAATGGCGTCTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCCTCAGCCACGACGACCGTCCATTCACGACGAACATGGACATAATAAAAATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTTCCGAATCTGGACGACCTTACACCCTCAGACTGGTCTTTTCTTAAGGGTATTAAAAACCCAAGTCCTCAAGTATCTCAACAATCTAGGTGTAATCTCAATTAATTTAGTAATTAAGGCTGTAGAACACGTATTGTACAATGTAATTCAACAAACAATGTATGTGGATCAATATTCAGATATAAAATTCGATCTTTATTAA |
| Protein Sequence | MDSRTGERITAAHTRNGVFIWEVPNPLYFKILSHDDRPFTTNMDIIKIRIQFNYNLRRALGVHKCFLTFRIWTTLHPQTGLFLRVLKTQVLKYLNNLGVISINLVIKAVEHVLYNVIQQTMYVDQYSDIKFDLY |
| NCBI Accession | YP_004123720.1 |
|---|---|
| Location | 1133-1585 |
| Gene Name | AC2 |
| Protein Name | transcription activator protein |
| Coding Region | ATGCGATCTTCGTCACCCTTGAAGGACCATTGTACTCAGGTACCAATCAAAGTACAGCACAGGGAAGCGAAGAGAGCGCACAGGAGGAAGAGAGTAGATCTTGAATGCGGGTGTTCTTATTATCTATCCATTAACTGCTTCAACCATGGATTCTCGCACAGGGGAACGCATCACTGCAGCTCATACAAGGAATGGCGTCTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCCTCAGCCACGACGACCGTCCATTCACGACGAACATGGACATAATAAAAATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTTCCGAATCTGGACGACCTTACACCCTCAGACTGGTCTTTTCTTAAGGGTATTAAAAACCCAAGTCCTCAAGTATCTCAACAATCTAGGTGTAATCTCAATTAA |
| Protein Sequence | MRSSSPLKDHCTQVPIKVQHREAKRAHRRKRVDLECGCSYYLSINCFNHGFSHRGTHHCSSYKEWRLYLGGSKSPLFQDPQPRRPSIHDEHGHNKNQDPIQLQPSESSGSAQVFSDLPNLDDLTPSDWSFLKGIKNPSPQVSQQSRCNLN |
| NCBI Accession | YP_004123721.1 |
|---|---|
| Location | 1482-2570 |
| Gene Name | AC1 |
| Protein Name | replicase |
| Coding Region | ATGCCTCCTAAGCGGTTCCTTATTAATTCCAAAAATTATTTCCTCACTTATCCCAAGTGCTCTCTCACAAGAGAAGAAGCACTTTCCCAAATCAAGAATTTCCAAACCCCCACTTCAAAAAAATATATTAAAATCTGCAGAGAACTTCATGAAAATGGGGAACCTCATCTGCACGTGCTCATCCAGATCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAATCCTACATCGACAAGGACGGGGACACTCTCGAGTGGGGAGAGTTTCAGATCGACGGACGATCTGCTAGAGGGGGACAACAGACAGCCAACGACGCTTACGCCGCAGCGCTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAGTTAGCTCCAAAAGATTATGTATTACAATTCCATAATTTAAATGCTAATTTAGATAGGATTTTTACACCTCCTGTGGAGGTTTATGTTTCTCCTTTTTCTTCTTCTTCTTTTGATCAAGTTCCGGAAGAACTTGAGGAATGGGCTGCCGAGAACGTTGTCGACGCCGCTGCGCGGCCACTTAGACCACAAAGTATAGTGATTGAGGGAGATAGTCGTACCGGGAAGACGATGTGGGCTAGATCACTGGGTCCACATAACTATTTGTGTGGGCATCTAGACCTTAGTCCAAAGATCTACAGTAACGAGGCCTGGTATAACGTCATTGATGACGTAGATCCCCACTTCCTCAAACACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAATCCAACACAAAGTACGGAAAGCCAGTTCAAATTAAAGGCGGCATACCAACAATCTTCCTCTGCAATCCTGGTCCCAACAGCAGTTATAAAGAGTTCTTAGACGAGGATAAGAACTCAGCACTAAAGAACTGGGCAGTGAAAAATGCGATCTTCGTCACCCTTGAAGGACCATTGTACTCAGGTACCAATCAAAGTACAGCACAGGGAAGCGAAGAGAGCGCACAGGAGGAAGAGAGTAGATCTTGA |
| Protein Sequence | MPPKRFLINSKNYFLTYPKCSLTREEALSQIKNFQTPTSKKYIKICRELHENGEPHLHVLIQIEGKYKCQNQRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIKELAPKDYVLQFHNLNANLDRIFTPPVEVYVSPFSSSSFDQVPEELEEWAAENVVDAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKIYSNEAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEDKNSALKNWAVKNAIFVTLEGPLYSGTNQSTAQGSEESAQEEESRS |
| NCBI Accession | YP_004123722.1 |
|---|---|
| Location | 2114-2416 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGGAACCTCATCTGCACGTGCTCATCCAGATCGAGGGGAAATACAAGTGCCAGAATCAGCGATTCTTCGACCTGGTCTCCCCAAGCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAATCCTACATCGACAAGGACGGGGACACTCTCGAGTGGGGAGAGTTTCAGATCGACGGACGATCTGCTAGAGGGGGACAACAGACAGCCAACGACGCTTACGCCGCAGCGCTTAACGCAGGCAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAGTTAG |
| Protein Sequence | MGNLICTCSSRSRGNTSARISDSSTWSPQAGQHISIRTYRELNPAPTSNPTSTRTGTLSSGESFRSTDDLLEGDNRQPTTLTPQRLTQAVSQRLLESLRS |
References More References in PubMed
| 1 |
Kumar A, et al. Arch Microbiol. 2024 Nov 14;206(12):468. doi: 10.1007/s00203-024-04176-0. PMID: 39542900 |
|---|---|
| 2 |
Khan ZA, et al. Virus Genes. 2024 Aug;60(4):412-422. doi: 10.1007/s11262-024-02074-7. Epub 2024 May 10. PMID: 38727968 |
| 3 |
Emmanuel CJ, et al. 3 Biotech. 2020 Dec;10(12):506. doi: 10.1007/s13205-020-02502-z. Epub 2020 Nov 4. PMID: 33184593 |
| 4 |
Singh AK, et al. Plant Dis. 2021 Sep;105(9):2595-2600. doi: 10.1094/PDIS-12-20-2655-RE. Epub 2021 Oct 28. PMID: 33393356 |
| 5 |
Gupta K, et al. J Virol Methods. 2022 Feb;300:114413. doi: 10.1016/j.jviromet.2021.114413. Epub 2021 Dec 10. PMID: 34902462 |
| 6 |
Infectivity of okra enation leaf curl virus and the role of its V2 protein in pathogenicity. Saeed F, et al. Virus Res. 2018 Aug 15;255:90-94. doi: 10.1016/j.virusres.2018.07.007. Epub 2018 Jul 18. PMID: 30009848 |
| 7 |
Kumar A, et al. Physiol Mol Biol Plants. 2025 May;31(5):767-783. doi: 10.1007/s12298-025-01578-2. Epub 2025 Apr 11. PMID: 40568483 |
| 8 |
Alagu K, et al. 3 Biotech. 2025 Jul;15(7):198. doi: 10.1007/s13205-025-04359-6. Epub 2025 May 30. PMID: 40454372 |
| 9 |
First report of an alphasatellite associated with Okra enation leaf curl virus. Chandran SA, et al. Virus Genes. 2013 Jun;46(3):585-7. doi: 10.1007/s11262-013-0898-y. Epub 2013 Mar 10. PMID: 23475199 |
| 10 |
Yadav Y, et al. J Genet. 2020;99:84. PMID: 33361636 |