Ocimum yellow vein virus
Basic Information
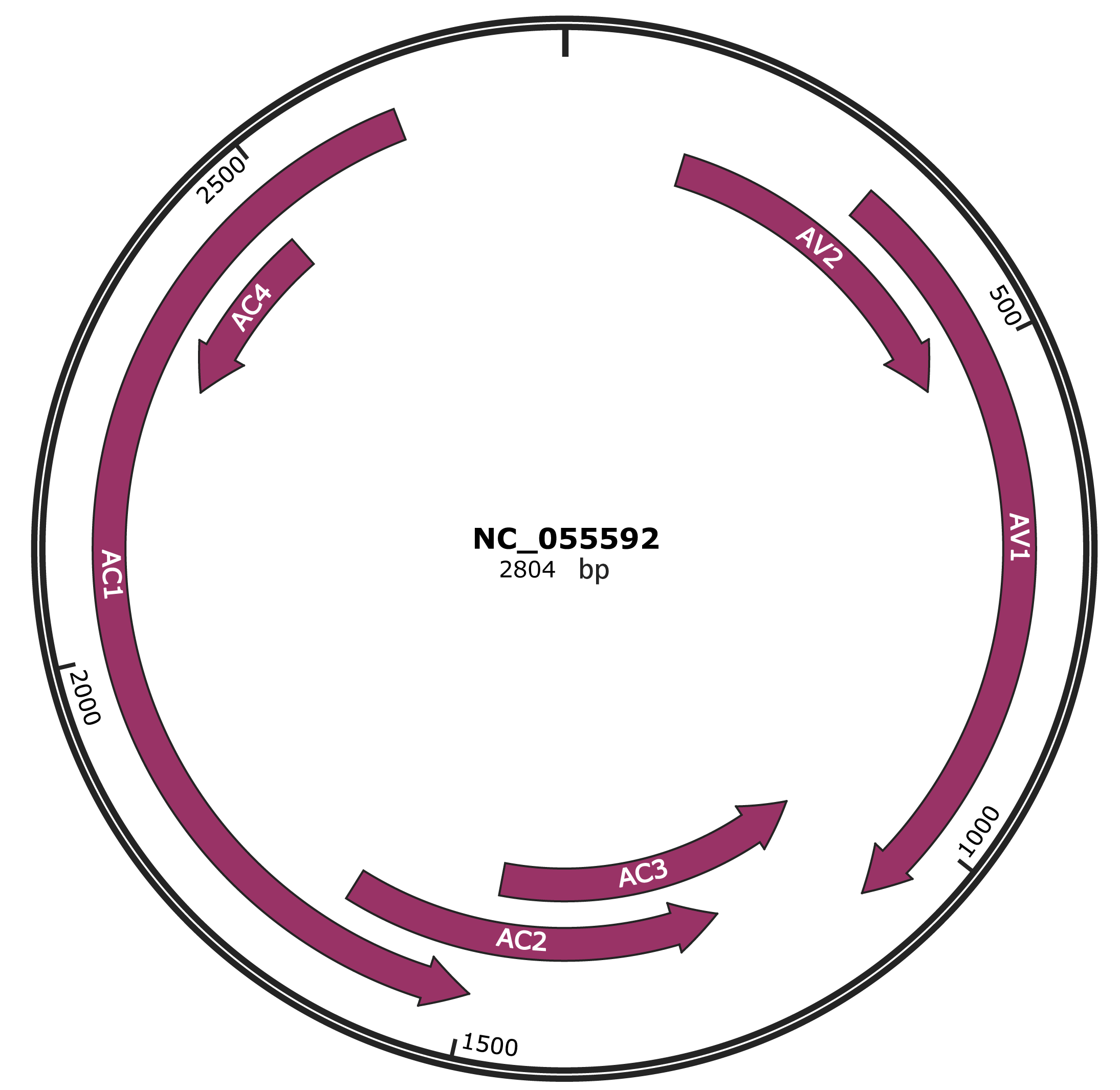
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCCCGCCCCGCCCGCATCGACGCCCCCTTCTCGCGCGTGTCTCCCACATCGAACACGTGGCGCTCTATATGCGTGTTTTACGTTGTTTGTTATTGTATATGTATTTTATTAGTGAAGTACGATGTCTTCGTATTTAGGAACGATGTGGGACCCCTTGGAGAATGAGTTCCCGGAGACCGTCCATGGTTTTCGGTGTATGCTAGCCGTGAAATATCTTCTGTTGGTGGAGTCTACGTATGAACCTGATACCCTAGGTCGTGAGCTCATACGCGATCTCATACGTTGTTTGCGTGCTTCGTCTTATAATGAAGCGTCCTGGAGATATAGTAATTTCCACACCCGTTTCCAAGGTTCGTCGTCGTCTGAATTTCGACAGCCCGTATTCCGCCCGTGTACCTGCCAACACTGTCCGTATTTCCAGAAAACGAATATGGGCCTCTCGTCCTATGTACAGAAAGCCCAAGATATACCGGATGTACAGAAGCCCGGATGTTCCAAAGGGTTGTGAAGGTCCGTGTAAGGTCCAGTCGTATGAGGCCCGTCATGATGTCAAGCATACTGGAACTGTTTTGTGTTGTTCTGATGTTACACGTGGTACTGGTTTGACTCACCGTGTTGGTAAGAGATTTACTATTAAGTCAATTTACATTCTGGGCAAGATTTGGATGGATGAGAATATTAAGAAGAAGAATCATACGAACATCGTCATGTTCTATCTTGTTCGTGATCGACGACCGTCTGACAAACCTTATGAATTTGGTTCTGTATTTAATATGTTTGATAATGAGCCTGCTACGGCGACAGTTAAGATGGATCATAGGGATAGGTTTCAGGTACTTCATAAATTTTATGCTTGGGTTACTGGTGGTGAATATGGTTCTAAAGAGCAGGCTATGGTACGGAGGTTTCGGAAGATATATCATCCTGTGGTGTACAACAATCAAGAGGCTGCTGAATATAAGAATCATCAGGAGAATGCGTTATTATTGTATATGGCTTGTACTCATGCTTCAAATCCTGTATATGCGACTCTTAAATGTCGTATTTATTTCTATGACAGTGTATCGAATTAATAAAATTTGAATTTTATATCATGATCTTCTTGCACTTCAATTGTGCCTTCCAATACATTATACAGTACATGTTCTGCAGCTCTAATACAAATATTTAAGCTAATAGCACCCAACTGGTTTACATATTTAATAAACTGATATTTAAATACTCTTAAGAAATGCGATGTCTGAGGTTGTAAACGAGTGAAGATCTTGAAGTTCAGAAAACACTTCAGAATCCCCAACGCCTTCTTGAGGTTGTGGTTGAATCTGACTTGGACCACTACTATGTCGTGTCCCGTCCGGAATGGTCTGCTGTGGTGGTATAAAATTTTGAAATATAGGGGATTCGGTACGTCGGAGATATAGACGCCATTCATTGACTGAGCTGCAGTGATATTCTCCCCTGTGCGAGAATCCATGATTATGGCAGTCAATGCTCAGATAGTAGCTGCAACCGCACCGGAGATCTATTCTCTTCCTCCTGATTGTCGTTCGCTTCGTCTGCTTGGCTATCTTGTGTTGTACCTTGATTGGAACTTGTGGTGGTGGAATATAAGGGACTCTCGAGGGTGAAGAACTTGGCATTCTTTTCAGCCCAGGCCTTTAGCTGTGCATTCTTCTCCTCATTCAAATATGATTTATAAGAAGAATTATGACCTGGATTGCAGAGGAAGATAGTGGGAATGCCACCTTTAATTTGAATTGGTTTCCCGTATTTTGTGTTGCTTTGCCAATCCCTTTGGGCGCCCATCAACTCTTTAAAGTGCTTTAGGTAGTGGGGGTCAACATCATCAATAATGTTGTACCATGCTGAATTTGAAAATACCTTTGGGGATAAGTCGAGGTGTCCACACAGGTAATTATGTGGACCCAGACTCCGCGCCCAAATAGTCTTGCCGGTACGACTATCTCCCTCTATGACTGCTGATATTGGTCTCCATGGCCGCGCAGCGGAATCCTTGATATTTTCGTGAACCCATTGTGTTATCTCTTCAGGCACGTTGCTGTAAGTTGCATTAGCATATGGACTCACGTAAGGAGGAGGTGGAACTTGGAATATCCTCTCGAGATTTGCTTTCAGATTATGATATTGGAATATGTAATCCTTCGGCAGTTTTTCTCTGATTATTGCGAGTGCCGCATCTGCTGTATTTGCATTTAATGCATCTGCACATGCATCGTTTGCATTTTGGCAACCGCCTCTGGCACTTCGTCCATCTACCTGGAATTCTCCCCATTTGAGTGTATCGCCGTCCTTCTCGATGTATGATTTAACGTCCGAGCTTGATTTAACTCCCTGAATGTTCGGATGGTAATGTGATCCCCTGCCTGTGGCCTTAAGATCGAAGAATCTGTTATTCGTGCATGTGAGTTTGCCTTCGAATTGAATGAGAATATGGAGGTGAGGTTGCCCATCTTCGTGAAGCTCTCTGGCAATTTCAATGAATTTTTTATTCGTCTGTGTTTCAATTGCACGAATTTGGGCGAGAGCTTCTTCTTTAGAGAGGGGACATTTTGGATATGTGAGGAAATAATTTTTGGCTTGAATTTTGAAGCGACGTGGAGGAGCCATTTATAGAGAGAGAATGTCTCCAATTGCTTTTCAGCTGAAGTCTCCATTGTATTGGAGACAATATATAGTGTCTCCAAATGGCATTATGGTAATTTTAAAAAGTAATAGGCTCCTTTCAAATCTAGTCGTACACGTGGGCTCATATGCGGCCATCCGTTTAATATT
Gene Information
|
NCBI Accession
|
YP_010087824.1
|
|
Location
|
133-519 |
|
Gene Name
|
AV2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGTCTTCGTATTTAGGAACGATGTGGGACCCCTTGGAGAATGAGTTCCCGGAGACCGTCCATGGTTTTCGGTGTATGCTAGCCGTGAAATATCTTCTGTTGGTGGAGTCTACGTATGAACCTGATACCCTAGGTCGTGAGCTCATACGCGATCTCATACGTTGTTTGCGTGCTTCGTCTTATAATGAAGCGTCCTGGAGATATAGTAATTTCCACACCCGTTTCCAAGGTTCGTCGTCGTCTGAATTTCGACAGCCCGTATTCCGCCCGTGTACCTGCCAACACTGTCCGTATTTCCAGAAAACGAATATGGGCCTCTCGTCCTATGTACAGAAAGCCCAAGATATACCGGATGTACAGAAGCCCGGATGTTCCAAAGGGTTGTGA |
|
Protein Sequence
|
MSSYLGTMWDPLENEFPETVHGFRCMLAVKYLLLVESTYEPDTLGRELIRDLIRCLRASSYNEASWRYSNFHTRFQGSSSSEFRQPVFRPCTCQHCPYFQKTNMGLSSYVQKAQDIPDVQKPGCSKGL |
|
NCBI Accession
|
YP_010087825.1
|
|
Location
|
317-1084 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGAAGCGTCCTGGAGATATAGTAATTTCCACACCCGTTTCCAAGGTTCGTCGTCGTCTGAATTTCGACAGCCCGTATTCCGCCCGTGTACCTGCCAACACTGTCCGTATTTCCAGAAAACGAATATGGGCCTCTCGTCCTATGTACAGAAAGCCCAAGATATACCGGATGTACAGAAGCCCGGATGTTCCAAAGGGTTGTGAAGGTCCGTGTAAGGTCCAGTCGTATGAGGCCCGTCATGATGTCAAGCATACTGGAACTGTTTTGTGTTGTTCTGATGTTACACGTGGTACTGGTTTGACTCACCGTGTTGGTAAGAGATTTACTATTAAGTCAATTTACATTCTGGGCAAGATTTGGATGGATGAGAATATTAAGAAGAAGAATCATACGAACATCGTCATGTTCTATCTTGTTCGTGATCGACGACCGTCTGACAAACCTTATGAATTTGGTTCTGTATTTAATATGTTTGATAATGAGCCTGCTACGGCGACAGTTAAGATGGATCATAGGGATAGGTTTCAGGTACTTCATAAATTTTATGCTTGGGTTACTGGTGGTGAATATGGTTCTAAAGAGCAGGCTATGGTACGGAGGTTTCGGAAGATATATCATCCTGTGGTGTACAACAATCAAGAGGCTGCTGAATATAAGAATCATCAGGAGAATGCGTTATTATTGTATATGGCTTGTACTCATGCTTCAAATCCTGTATATGCGACTCTTAAATGTCGTATTTATTTCTATGACAGTGTATCGAATTAA |
|
Protein Sequence
|
MKRPGDIVISTPVSKVRRRLNFDSPYSARVPANTVRISRKRIWASRPMYRKPKIYRMYRSPDVPKGCEGPCKVQSYEARHDVKHTGTVLCCSDVTRGTGLTHRVGKRFTIKSIYILGKIWMDENIKKKNHTNIVMFYLVRDRRPSDKPYEFGSVFNMFDNEPATATVKMDHRDRFQVLHKFYAWVTGGEYGSKEQAMVRRFRKIYHPVVYNNQEAAEYKNHQENALLLYMACTHASNPVYATLKCRIYFYDSVSN |
|
NCBI Accession
|
YP_010087826.1
|
|
Location
|
1081-1485 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCTCGCACAGGGGAGAATATCACTGCAGCTCAGTCAATGAATGGCGTCTATATCTCCGACGTACCGAATCCCCTATATTTCAAAATTTTATACCACCACAGCAGACCATTCCGGACGGGACACGACATAGTAGTGGTCCAAGTCAGATTCAACCACAACCTCAAGAAGGCGTTGGGGATTCTGAAGTGTTTTCTGAACTTCAAGATCTTCACTCGTTTACAACCTCAGACATCGCATTTCTTAAGAGTATTTAAATATCAGTTTATTAAATATGTAAACCAGTTGGGTGCTATTAGCTTAAATATTTGTATTAGAGCTGCAGAACATGTACTGTATAATGTATTGGAAGGCACAATTGAAGTGCAAGAAGATCATGATATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGENITAAQSMNGVYISDVPNPLYFKILYHHSRPFRTGHDIVVVQVRFNHNLKKALGILKCFLNFKIFTRLQPQTSHFLRVFKYQFIKYVNQLGAISLNICIRAAEHVLYNVLEGTIEVQEDHDIKFKFY |
|
NCBI Accession
|
YP_010087827.1
|
|
Location
|
1226-1651 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCCAAGTTCTTCACCCTCGAGAGTCCCTTATATTCCACCACCACAAGTTCCAATCAAGGTACAACACAAGATAGCCAAGCAGACGAAGCGAACGACAATCAGGAGGAAGAGAATAGATCTCCGGTGCGGTTGCAGCTACTATCTGAGCATTGACTGCCATAATCATGGATTCTCGCACAGGGGAGAATATCACTGCAGCTCAGTCAATGAATGGCGTCTATATCTCCGACGTACCGAATCCCCTATATTTCAAAATTTTATACCACCACAGCAGACCATTCCGGACGGGACACGACATAGTAGTGGTCCAAGTCAGATTCAACCACAACCTCAAGAAGGCGTTGGGGATTCTGAAGTGTTTTCTGAACTTCAAGATCTTCACTCGTTTACAACCTCAGACATCGCATTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MPSSSPSRVPYIPPPQVPIKVQHKIAKQTKRTTIRRKRIDLRCGCSYYLSIDCHNHGFSHRGEYHCSSVNEWRLYLRRTESPIFQNFIPPQQTIPDGTRHSSGPSQIQPQPQEGVGDSEVFSELQDLHSFTTSDIAFLKSI |
|
NCBI Accession
|
YP_010087828.1
|
|
Location
|
1497-2639 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGGCTCCTCCACGTCGCTTCAAAATTCAAGCCAAAAATTATTTCCTCACATATCCAAAATGTCCCCTCTCTAAAGAAGAAGCTCTCGCCCAAATTCGTGCAATTGAAACACAGACGAATAAAAAATTCATTGAAATTGCCAGAGAGCTTCACGAAGATGGGCAACCTCACCTCCATATTCTCATTCAATTCGAAGGCAAACTCACATGCACGAATAACAGATTCTTCGATCTTAAGGCCACAGGCAGGGGATCACATTACCATCCGAACATTCAGGGAGTTAAATCAAGCTCGGACGTTAAATCATACATCGAGAAGGACGGCGATACACTCAAATGGGGAGAATTCCAGGTAGATGGACGAAGTGCCAGAGGCGGTTGCCAAAATGCAAACGATGCATGTGCAGATGCATTAAATGCAAATACAGCAGATGCGGCACTCGCAATAATCAGAGAAAAACTGCCGAAGGATTACATATTCCAATATCATAATCTGAAAGCAAATCTCGAGAGGATATTCCAAGTTCCACCTCCTCCTTACGTGAGTCCATATGCTAATGCAACTTACAGCAACGTGCCTGAAGAGATAACACAATGGGTTCACGAAAATATCAAGGATTCCGCTGCGCGGCCATGGAGACCAATATCAGCAGTCATAGAGGGAGATAGTCGTACCGGCAAGACTATTTGGGCGCGGAGTCTGGGTCCACATAATTACCTGTGTGGACACCTCGACTTATCCCCAAAGGTATTTTCAAATTCAGCATGGTACAACATTATTGATGATGTTGACCCCCACTACCTAAAGCACTTTAAAGAGTTGATGGGCGCCCAAAGGGATTGGCAAAGCAACACAAAATACGGGAAACCAATTCAAATTAAAGGTGGCATTCCCACTATCTTCCTCTGCAATCCAGGTCATAATTCTTCTTATAAATCATATTTGAATGAGGAGAAGAATGCACAGCTAAAGGCCTGGGCTGAAAAGAATGCCAAGTTCTTCACCCTCGAGAGTCCCTTATATTCCACCACCACAAGTTCCAATCAAGGTACAACACAAGATAGCCAAGCAGACGAAGCGAACGACAATCAGGAGGAAGAGAATAGATCTCCGGTGCGGTTGCAGCTACTATCTGAGCATTGA |
|
Protein Sequence
|
MAPPRRFKIQAKNYFLTYPKCPLSKEEALAQIRAIETQTNKKFIEIARELHEDGQPHLHILIQFEGKLTCTNNRFFDLKATGRGSHYHPNIQGVKSSSDVKSYIEKDGDTLKWGEFQVDGRSARGGCQNANDACADALNANTADAALAIIREKLPKDYIFQYHNLKANLERIFQVPPPPYVSPYANATYSNVPEEITQWVHENIKDSAARPWRPISAVIEGDSRTGKTIWARSLGPHNYLCGHLDLSPKVFSNSAWYNIIDDVDPHYLKHFKELMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGHNSSYKSYLNEEKNAQLKAWAEKNAKFFTLESPLYSTTTSSNQGTTQDSQADEANDNQEEENRSPVRLQLLSEH |
|
NCBI Accession
|
YP_010087829.1
|
|
Location
|
2285-2482 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAACCTCACCTCCATATTCTCATTCAATTCGAAGGCAAACTCACATGCACGAATAACAGATTCTTCGATCTTAAGGCCACAGGCAGGGGATCACATTACCATCCGAACATTCAGGGAGTTAAATCAAGCTCGGACGTTAAATCATACATCGAGAAGGACGGCGATACACTCAAATGGGGAGAATTCCAGGTAG |
|
Protein Sequence
|
MGNLTSIFSFNSKANSHARITDSSILRPQAGDHITIRTFRELNQARTLNHTSRRTAIHSNGENSR |