Ocimum mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_018589045.1 |
| Isolate | Uganda |
| Release date | 2021/6/1 |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
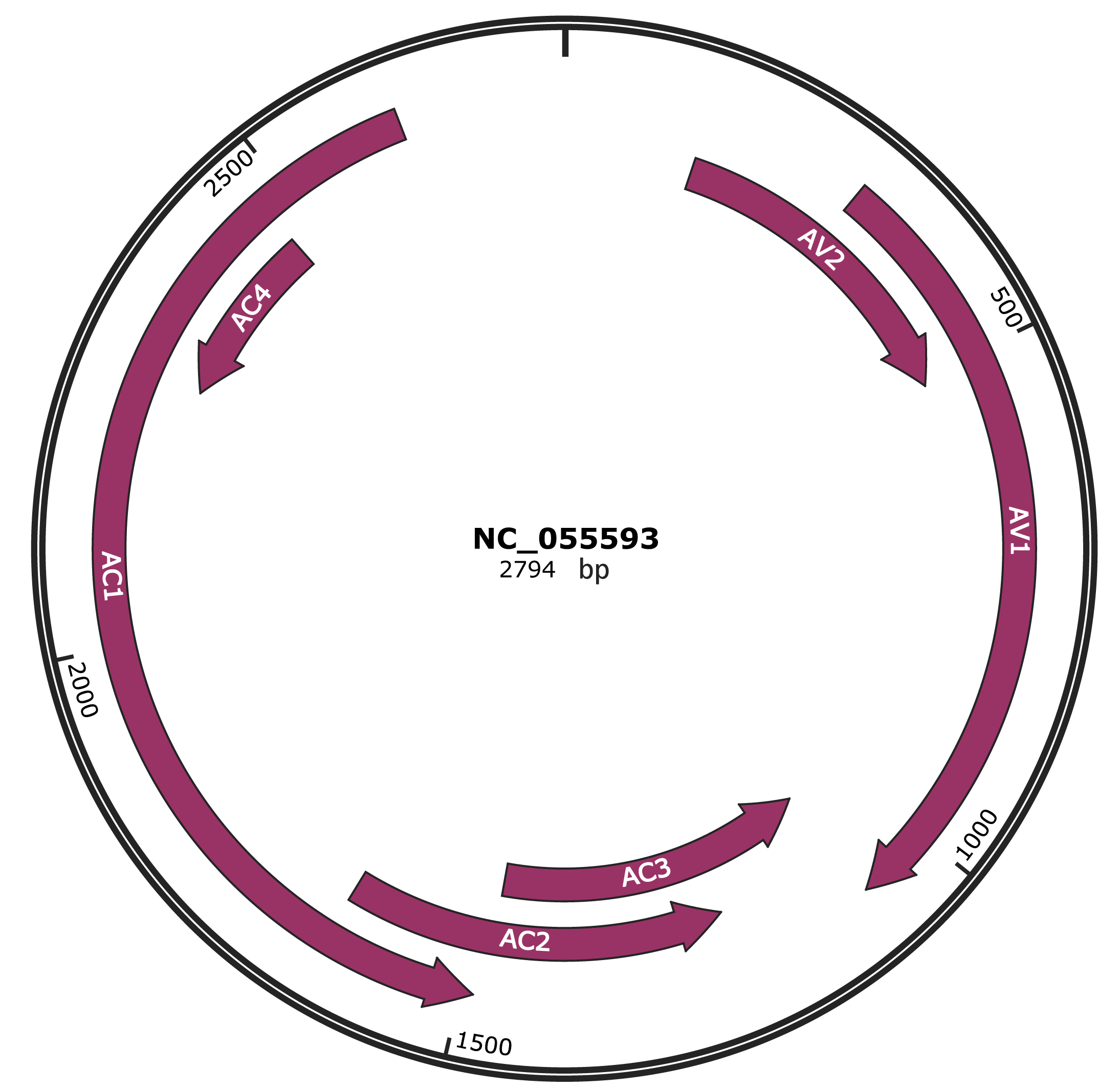
Genomic Organization
JBrowse
Genome
NC_055593
Gene Information
| NCBI Accession | YP_010087830.1 |
|---|---|
| Location | 145-510 |
| Gene Name | AV2 |
| Protein Name | precoat protein |
| Coding Region | ATGTGGGACCCCTTGGAGAATGAATTCCCGGATACCGTTCATGGATTCCGGTGTATGCTCGCCGTCAAATATCTTCTTCTGGTGGAGTCTAAGTATGAGCCGGATACTCTAGGTCGTGATCTCATACGTGATCTTATACGTTGTTTGCGTGCATCGAGTTATAATGAAGCGTCCTGGAGATATAGTAATTTCCACACCCGCTTCCAAAGTTCGGCGTCGTCTGAATTTCGACAGCCCATACTCCGCCCGTGTACCTGTCAGCACTGTCCGTACTTCCAGAAGACGAATATGGGCCTCGCGTCCTATGTACAGAAAGCCCAAGATATACCGGATTTACAGAAGCCCGGATGTTCCAAAGGGCTGTGA |
| Protein Sequence | MWDPLENEFPDTVHGFRCMLAVKYLLLVESKYEPDTLGRDLIRDLIRCLRASSYNEASWRYSNFHTRFQSSASSEFRQPILRPCTCQHCPYFQKTNMGLASYVQKAQDIPDLQKPGCSKGL |
| NCBI Accession | YP_010087831.1 |
|---|---|
| Location | 308-1075 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGAAGCGTCCTGGAGATATAGTAATTTCCACACCCGCTTCCAAAGTTCGGCGTCGTCTGAATTTCGACAGCCCATACTCCGCCCGTGTACCTGTCAGCACTGTCCGTACTTCCAGAAGACGAATATGGGCCTCGCGTCCTATGTACAGAAAGCCCAAGATATACCGGATTTACAGAAGCCCGGATGTTCCAAAGGGCTGTGAAGGTCCGTGTAAAGTTCAATCTTATGAGGCCCGTCATGATGTAAAGCATACTGGTACTGTATTATGTTGCTCCGACGTTACACGTGGTAGTGGTTTGACTCACCGCGTTGGTAAGAGGTTTACTATCAAGTCTATTTACATATTGGGTAAGATCTGGATGGATGAGAATATCAAGAAGAAGAATCACACTAATATTGTCATGTTTTATCTTGTTCGGGATCGTCGGCCGTCTGATAAACCTTATGAATTTGGTTCTGTGTTTAACATGTTTGACAATGAGCCGGCTACTGCGACAGTGAAGATGGATCATCGGGATAGGTTTCAGGTTTTGCATAAGTTTTATGGTTGGGTTACCGGTGGTGAATACGCGTCTAAAGAGCAGGCGATGATTAGGAGGTTTTATAAGATATATCATCCTGTGGTGTACAACAATCAAGAGGGTGCTGAATACAAGAATCATCAGGAGAACGCTTTGTTATTGTATATGGCTTGTACTCATGCTTCTAATCCTGTGTACGCGACTCTTAAATGTCGCATATATTTTTATGACAGTGTGTCGAATTAA |
| Protein Sequence | MKRPGDIVISTPASKVRRRLNFDSPYSARVPVSTVRTSRRRIWASRPMYRKPKIYRIYRSPDVPKGCEGPCKVQSYEARHDVKHTGTVLCCSDVTRGSGLTHRVGKRFTIKSIYILGKIWMDENIKKKNHTNIVMFYLVRDRRPSDKPYEFGSVFNMFDNEPATATVKMDHRDRFQVLHKFYGWVTGGEYASKEQAMIRRFYKIYHPVVYNNQEGAEYKNHQENALLLYMACTHASNPVYATLKCRIYFYDSVSN |
| NCBI Accession | YP_010087832.1 |
|---|---|
| Location | 1072-1476 |
| Gene Name | AC3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCTCGCACAGGGGAGAATATCACTGCAGCTCAGTCAATGAGTGGCGTCTATACCTCCGACGTGCCGAATCCCCTATATTTCAAAATTCTATACCACCACAGCAGACCATTCCAGACGGGACACGACATAATTGTGGTCCAAGTCAGATTCAACCACAACCTCAAGAAGGCGTTGGGGATTCTGAAGTGTTTTCTGACCTTCAAGATCTTCACTCGTTTACAACCTCAGACATCGCATTTCTTAAGAGTATTTAGATATCAGTTCATGAAATATGTAAACCAATTAGGGGCTATTAGCTTAAATATTTGTATTAGATCTGCTGATCATGTATTGTACAATGTAATGCAAGGCACAATTGAAGTGCAAGAAGATCATGATATAAAATTCAAAATTTATTAA |
| Protein Sequence | MDSRTGENITAAQSMSGVYTSDVPNPLYFKILYHHSRPFQTGHDIIVVQVRFNHNLKKALGILKCFLTFKIFTRLQPQTSHFLRVFRYQFMKYVNQLGAISLNICIRSADHVLYNVMQGTIEVQEDHDIKFKIY |
| NCBI Accession | YP_010087833.1 |
|---|---|
| Location | 1217-1642 |
| Gene Name | AC2 |
| Protein Name | transactivator protein |
| Coding Region | ATGCCAAGTTCTTCACCCTCGAGAGTCCCCTATACTCCAATTCAGCAGGTACCAATCAAGGTACAACACAAGATAGCCAAGCAGACCAAGCGTACAACAATCAGGCGGAAGAGGATAGATCTCCGGTGCGGTTGCAGCTATTTTCTGAGCATTGACTGCCACAACCATGGATTCTCGCACAGGGGAGAATATCACTGCAGCTCAGTCAATGAGTGGCGTCTATACCTCCGACGTGCCGAATCCCCTATATTTCAAAATTCTATACCACCACAGCAGACCATTCCAGACGGGACACGACATAATTGTGGTCCAAGTCAGATTCAACCACAACCTCAAGAAGGCGTTGGGGATTCTGAAGTGTTTTCTGACCTTCAAGATCTTCACTCGTTTACAACCTCAGACATCGCATTTCTTAAGAGTATTTAG |
| Protein Sequence | MPSSSPSRVPYTPIQQVPIKVQHKIAKQTKRTTIRRKRIDLRCGCSYFLSIDCHNHGFSHRGEYHCSSVNEWRLYLRRAESPIFQNSIPPQQTIPDGTRHNCGPSQIQPQPQEGVGDSEVFSDLQDLHSFTTSDIAFLKSI |
| NCBI Accession | YP_010087834.1 |
|---|---|
| Location | 1488-2630 |
| Gene Name | AC1 |
| Protein Name | replication associated protein |
| Coding Region | ATGGCTCCTCCACGTCGCTTCAAAATTCAAGCCAAAAATTACTTCCTCACATATCCCAAATGTTCCCTCTCTAAAGAAGAAGCCCTCACTCAAATTCGTGCAATTGAAACACACACGAATAAAAAATTCATAGAAATTGCCAGAGAGCTTCACGAAGATGGGCAACCTCATCTCCACATTCTCATTCAATTCGAAGGTAAATTCACATGCACGAATAACCGATTCTTCGATCTTCAAGCCACAACCAGGGGAACACATTACCATCCGAACATTCAGGGAGTTAAATCAAGCTCAGATGTCAAATCATACATTGAGAAGGACGGAGACACACTCAAATGGGGAGAATTCCAAGTAGATGGTAGAAGTGCAAGAGGAGGTTGTCAAAATGCAAATGATGCATGTGCTGATGCATTAAATGCTAACTCGGCAGAAGCAGCACTCGCAATAATTCGAGAAAAACTGCCGAAGGATTACATATTCCAATACCACAATCTGAAAGCAAATCTCGAGAAAATCTTCCAGTTGCCACCTGTTCCATATGTAAGTCCATATGCTAATGCAACATTCAACAATGTGCCTGAAGAAATAAGGAATTGGGTTGACGAAAATGTTAAGGATTCCGCTGCGCGGCCGTGGAGACCAATCTCAATCGTAATAGAGGGGGATAGTCGTACCGGCAAAACTATTTGGGCGCGGGGATTGGGTCCCCATAATTATCTATGTGGGCACCTCGATCTATCCCCAAAGGTATTTTCAAATTCAGCATGGTACAACATTATTGATGATGTTGACCCCCACTACCTAAAGCATTTTAAAGAGTTGATGGGGGCCCAACGTGATTGGCAAAGCAACACAAAGTACGGGAAACCAATTCAAATTAAAGGTGGCATTCCCACTATCTTCTTATGCAATCCAGGTCATAATTCTTCTTATAAATCATATCTGAATGAGGATAAGAATGAGCAGCTAAAGGCCTGGGCTGAAAAGAATGCCAAGTTCTTCACCCTCGAGAGTCCCCTATACTCCAATTCAGCAGGTACCAATCAAGGTACAACACAAGATAGCCAAGCAGACCAAGCGTACAACAATCAGGCGGAAGAGGATAGATCTCCGGTGCGGTTGCAGCTATTTTCTGAGCATTGA |
| Protein Sequence | MAPPRRFKIQAKNYFLTYPKCSLSKEEALTQIRAIETHTNKKFIEIARELHEDGQPHLHILIQFEGKFTCTNNRFFDLQATTRGTHYHPNIQGVKSSSDVKSYIEKDGDTLKWGEFQVDGRSARGGCQNANDACADALNANSAEAALAIIREKLPKDYIFQYHNLKANLEKIFQLPPVPYVSPYANATFNNVPEEIRNWVDENVKDSAARPWRPISIVIEGDSRTGKTIWARGLGPHNYLCGHLDLSPKVFSNSAWYNIIDDVDPHYLKHFKELMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGHNSSYKSYLNEDKNEQLKAWAEKNAKFFTLESPLYSNSAGTNQGTTQDSQADQAYNNQAEEDRSPVRLQLFSEH |
| NCBI Accession | YP_010087835.1 |
|---|---|
| Location | 2276-2473 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGCAACCTCATCTCCACATTCTCATTCAATTCGAAGGTAAATTCACATGCACGAATAACCGATTCTTCGATCTTCAAGCCACAACCAGGGGAACACATTACCATCCGAACATTCAGGGAGTTAAATCAAGCTCAGATGTCAAATCATACATTGAGAAGGACGGAGACACACTCAAATGGGGAGAATTCCAAGTAG |
| Protein Sequence | MGNLISTFSFNSKVNSHARITDSSIFKPQPGEHITIRTFRELNQAQMSNHTLRRTETHSNGENSK |
References More References in PubMed
| 1 |
Abdelkhalek A, et al. Plants (Basel). 2022 Oct 13;11(20):2707. doi: 10.3390/plants11202707. PMID: 36297731 |
|---|---|
| 2 |
Ekpiken EE, et al. Virusdisease. 2021 Jun;32(2):375-377. doi: 10.1007/s13337-021-00662-x. Epub 2021 Apr 7. PMID: 34423102 |
| 3 |
First Report of Alfalfa mosaic virus Infecting Basil (Ocimum basilicum) in California. Wintermantel WM, et al. Plant Dis. 2012 Feb;96(2):295. doi: 10.1094/PDIS-06-11-0516. PMID: 30731822 |
| 4 |
First Record of Alfalfa mosaic virus in Teucrium fruticans in Italy. Parrella G, et al. Plant Dis. 2012 Feb;96(2):294. doi: 10.1094/PDIS-08-11-0674. PMID: 30731813 |
| 5 |
First Report of a Disease of Peony Caused by Alfalfa mosaic virus. Bellardi MG, et al. Plant Dis. 2003 Jan;87(1):99. doi: 10.1094/PDIS.2003.87.1.99C. PMID: 30812714 |
| 6 |
Cardin L, et al. Plant Dis. 2009 Feb;93(2):201. doi: 10.1094/PDIS-93-2-0201B. PMID: 30764126 |
| 7 |
Roggero P, et al. Plant Dis. 2000 Oct;84(10):1152. doi: 10.1094/PDIS.2000.84.10.1152D. PMID: 30831916 |
| 8 |
Araujia sericifera New Host of Alfalfa mosaic virus in Italy. Parrella G, et al. Plant Dis. 2013 Oct;97(10):1387. doi: 10.1094/PDIS-03-13-0300-PDN. PMID: 30722152 |
| 9 |
Natural Infection of Field-Grown Borage (Borago officinalis) by Alfalfa mosaic virus in Spain. Mallor C, et al. Plant Dis. 2002 Jun;86(6):698. doi: 10.1094/PDIS.2002.86.6.698A. PMID: 30823267 |
| 10 |
Parrella G, et al. Plant Dis. 2010 Jul;94(7):924. doi: 10.1094/PDIS-94-7-0924A. PMID: 30743579 |