Mungbean yellow mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000845225.1 |
| Release date | 2015/2/12 |
| Submitter | Gutierrez,C., Morinaga,T., Ikegami,M., Miura,K. |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
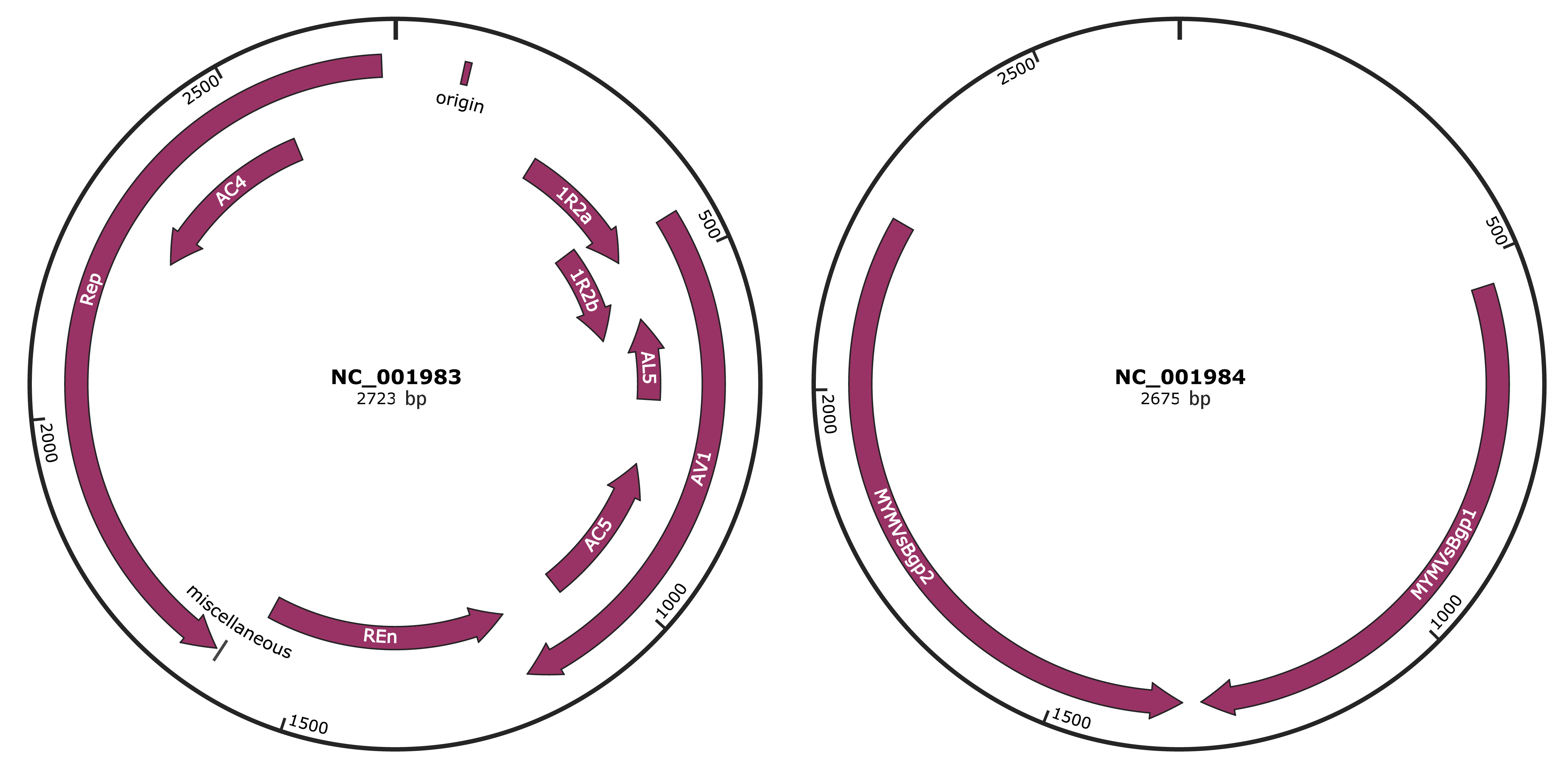
JBrowse
Genome
NC_001983
NC_001984
Gene Information
| NCBI Accession | NP_077085.1 |
|---|---|
| Location | 242-466 |
| Gene Name | 1R2a |
| Protein Name | 1R2a |
| Coding Region | ATGTGGGATCCATTGGTGAACGACTTTCCCAAATCGTTACATGGTTTCCGTTGTATGCTTGCCATTAAGTATTTACAATACATTCAGGCGAATTATCCCTCTAATTCTCTTGGTTACGTGTATTTAACAGAGTTAATACAGGTTTTACGTATACGGAAACATGCCAAAGCGGAATTACGATCACCGCCTTCTCTACCCCGATGTCGAATGTGCGGAGGAGGCTGA |
| Protein Sequence | MWDPLVNDFPKSLHGFRCMLAIKYLQYIQANYPSNSLGYVYLTELIQVLRIRKHAKAELRSPPSLPRCRMCGGG |
| NCBI Accession | NP_077086.1 |
|---|---|
| Location | 402-593 |
| Gene Name | 1R2b |
| Protein Name | pre-coat protein |
| Coding Region | ATGCCAAAGCGGAATTACGATCACCGCCTTCTCTACCCCGATGTCGAATGTGCGGAGGAGGCTGATCTTCGACACCCCGCTTTCCTTACCTGCCACTGCGGGAAGTGTCCCTGCCAGCGCGAAAAGGAGGAGGTGGACCAACCGACCCATGTGGAGGAAACCGAGATATTATCGGTTATACCGCTCTCCTGA |
| Protein Sequence | MPKRNYDHRLLYPDVECAEEADLRHPAFLTCHCGKCPCQREKEEVDQPTHVEETEILSVIPLS |
| NCBI Accession | NP_077087.1 |
|---|---|
| Location | 442-1176 |
| Gene Name | AV1 |
| Protein Name | COAT PROTEIN |
| Coding Region | ATGTCGAATGTGCGGAGGAGGCTGATCTTCGACACCCCGCTTTCCTTACCTGCCACTGCGGGAAGTGTCCCTGCCAGCGCGAAAAGGAGGAGGTGGACCAACCGACCCATGTGGAGGAAACCGAGATATTATCGGTTATACCGCTCTCCTGATGTCCCACGTGGTTGTGAAGGACCTTGTAAGGTCCAATCCTTCGAGGCGAAACATGATATTTCGCATCTCGGTAAGGTCATATGTGTCACTGATGTGACACGAGGCAATGGCATCACTCACAGAGTTGGGAAACGATTTTGTGTTAAGTCTATCTGGGTTACAGGCAAAATCTGGATGGATGAGAACATCAAGACAAAGAATCACACTAATACTGTGATGTTCAAGTTAGTGCGTGACAGACGTCCATTTGGCACGCCACAAGACTTTGGTCAAGTGTTCAACATGTATGACAATGAACCCAGTACTGCTACTGTGAAGAACGATCTTCGTGATCGTTATCAGGTCGTGCGTAAGTTTCAAGCCACAGTTACTGGTGGCCAGTATGCGAGCAAGGAGCAAGCCATAGTTAGTAAATTTTATCGTGTTAACAATTATGTTGTTTACAACCACCAAGAGGCAGCGAAGTATGAAAATCATACTGAGAATGCTTTGTTATTGTATATGGCATGTACTCATGCATCAAATCCTGTGTATGCAACACTAAAAATTCGGATCTATTTTTATGATTCGATTTCAAATTAA |
| Protein Sequence | MSNVRRRLIFDTPLSLPATAGSVPASAKRRRWTNRPMWRKPRYYRLYRSPDVPRGCEGPCKVQSFEAKHDISHLGKVICVTDVTRGNGITHRVGKRFCVKSIWVTGKIWMDENIKTKNHTNTVMFKLVRDRRPFGTPQDFGQVFNMYDNEPSTATVKNDLRDRYQVVRKFQATVTGGQYASKEQAIVSKFYRVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
| NCBI Accession | NP_077088.1 |
|---|---|
| Location | 570-707 |
| Gene Name | AL5 |
| Protein Name | unknown ORF |
| Coding Region | ATGCCATTGCCTCGTGTCACATCAGTGACACATATGACCTTACCGAGATGCGAAATATCATGTTTCGCCTCGAAGGATTGGACCTTACAAGGTCCTTCACAACCACGTGGGACATCAGGAGAGCGGTATAACCGATAA |
| Protein Sequence | MPLPRVTSVTHMTLPRCEISCFASKDWTLQGPSQPRGTSGERYNR |
| NCBI Accession | NP_077089.1 |
|---|---|
| Location | 820-1071 |
| Gene Name | AC5 |
| Protein Name | AC5 |
| Coding Region | ATGATTTTCATACTTCGCTGCCTCTTGGTGGTTGTAAACAACATAATTGTTAACACGATAAAATTTACTAACTATGGCTTGCTCCTTGCTCGCATACTGGCCACCAGTAACTGTGGCTTGAAACTTACGCACGACCTGATAACGATCACGAAGATCGTTCTTCACAGTAGCAGTACTGGGTTCATTGTCATACATGTTGAACACTTGACCAAAGTCTTGTGGCGTGCCAAATGGACGTCTGTCACGCACTAA |
| Protein Sequence | MIFILRCLLVVVNNIIVNTIKFTNYGLLLARILATSNCGLKLTHDLITITKIVLHSSSTGFIVIHVEHLTKVLWRAKWTSVTH |
| NCBI Accession | NP_077090.1 |
|---|---|
| Location | 1173-1577 |
| Gene Name | REn |
| Protein Name | AC3 PROTEIN |
| Coding Region | ATGGATTTTCGCACCGGGGACAACATCACTGCAGCTCAACTCAGGAATGGCGTCTTTACTTGGGAGGTGCGAAATCCCCTCTCTTTCAAGATCATGCAGCACCGTCTAATTCGTCCAGAATCCCAGATGTATGTGACCCAAATACGGATCATGTTCAACCACGGGTTGAAGAAAGCACTGCTGATGCACAAATGCTTCCTGGATCTGAAGCTCTACCATTATTTGACGGCGACTTCTGGGATGATATTATCAATTTTTAGTAGACAATTATTTAGATATTTAAATAATTTAGGCGTCATTAGCATAGGCAATGTATTACAAGGCGCCTCACATATCCTGTATGAAAAACTCCACCATGTGGAGGATGTAAGCTTTACGCATAATGTTCAATACAAAATTTATTAA |
| Protein Sequence | MDFRTGDNITAAQLRNGVFTWEVRNPLSFKIMQHRLIRPESQMYVTQIRIMFNHGLKKALLMHKCFLDLKLYHYLTATSGMILSIFSRQLFRYLNNLGVISIGNVLQGASHILYEKLHHVEDVSFTHNVQYKIY |
| NCBI Accession | NP_077091.1 |
|---|---|
| Location | 1620-2705 |
| Gene Name | Rep |
| Protein Name | AC1 PROTEIN |
| Coding Region | ATGCCTAGACTCGGTCGTTTTGCTATAAACGCAAAGAACTATTTCCTCACTTATCCCCGTTGTCCTCTTAGAAAGGAGGACGCTCTTGAAGAACTCTTAGCGTTATCAACGCCTGTCAACAAGAAGTTCATCCGAGTCTGTCGTGAACTTCATGAAGATGGAGAACCTCATCTCCATGTTCTGCTTCAATTCGAAGGGAAGTTCCAAACGAAGAACGAAAGGTTCTTCGACCTGGTTTCCTCAACCAGATCAGCACATTACCATCCGAACGTTCAGGCAGCTAAAAGCGCATCAGATGTTAAGTCATACATGGACAAAGACGGAGACGTCGTTGACCATGGAAGTTTCCAAGTCGATGGCAGATCAGCTAGAGGAGGTAAACAGTCTGCCAACGACGCTTATGCCGAGGCACTCAACAGTGGATCCAAGTTACAGGCCCTCAATATACTGAGGGAGAAGGCTCCTAAAGATTATATTTTACAATTTCATAATTTAAATTGTAATTTGTCACGGATTTTTTCAGATGAAGTTCCACTTTACGTGTCACCTTATAGCTTATCAGCATTTGACAAAGTCCCAAGTTACATTTCTTCATGGGCTTCAGAAAATGTTAGACATCCCGCTGCGCCGGAAAGACCGATTAGCATTGTGATTGAAGGCGATAGTCGCACGGGTAAAACAATGTGGGCACGTGCGTTAGGTCCTCACAATTATCTTTGCGGCCACTTGGATCTTAACAGTAAGATCTATTCCAACGATGCTTGGTATAACGTCATTGATGACGTCGATCCCCATTATTTGAAACATTTCAAAGAATTCATGGGCGCGCAAAGAGACTGGCAATCTAACGTCAAGTACGGGAAGCCCACTCATATTAAAGGTGGTATCCCCACCATCTTTTTATGCAATCCTGGACCAAAATCCTCTTATAAAGAGTACTTGGACGAGGCTGATAATACAGCACTCAAATTGTGGGCTTCAAAGAATGCGGAATTCTACACCCTCAAAGAACCACTTTTCTCCTCCGTCGATCAAAGCGCAACACAAGGTTGCCAAGAAGCGAGCAATTCGACGCTCTCGAATTGA |
| Protein Sequence | MPRLGRFAINAKNYFLTYPRCPLRKEDALEELLALSTPVNKKFIRVCRELHEDGEPHLHVLLQFEGKFQTKNERFFDLVSSTRSAHYHPNVQAAKSASDVKSYMDKDGDVVDHGSFQVDGRSARGGKQSANDAYAEALNSGSKLQALNILREKAPKDYILQFHNLNCNLSRIFSDEVPLYVSPYSLSAFDKVPSYISSWASENVRHPAAPERPISIVIEGDSRTGKTMWARALGPHNYLCGHLDLNSKIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNVKYGKPTHIKGGIPTIFLCNPGPKSSYKEYLDEADNTALKLWASKNAEFYTLKEPLFSSVDQSATQGCQEASNSTLSN |
| NCBI Accession | NP_077092.1 |
|---|---|
| Location | 2255-2554 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGAAGATGGAGAACCTCATCTCCATGTTCTGCTTCAATTCGAAGGGAAGTTCCAAACGAAGAACGAAAGGTTCTTCGACCTGGTTTCCTCAACCAGATCAGCACATTACCATCCGAACGTTCAGGCAGCTAAAAGCGCATCAGATGTTAAGTCATACATGGACAAAGACGGAGACGTCGTTGACCATGGAAGTTTCCAAGTCGATGGCAGATCAGCTAGAGGAGGTAAACAGTCTGCCAACGACGCTTATGCCGAGGCACTCAACAGTGGATCCAAGTTACAGGCCCTCAATATACTGA |
| Protein Sequence | MKMENLISMFCFNSKGSSKRRTKGSSTWFPQPDQHITIRTFRQLKAHQMLSHTWTKTETSLTMEVSKSMADQLEEVNSLPTTLMPRHSTVDPSYRPSIY |
| NCBI Accession | NP_620377.1 |
|---|---|
| Location | 538-1308 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTACAACCGTAACATACGAACCCCAGTGAAATTACGTAGAAGTAATTTCGGGCACAGATGGAGTTCTTTAACTCCGTCAACGAGTCGATTAAGACCGAGTAAATTAAATGTTTCAAGGAAACTAGGATACGACCGTATTGATCGTGAATTTCGCAAAAATTCCATTGTTGAGGTTCAACATGGAAGCCATATGTCCTTGGACAAGAACACAGACATTTCATCTTTTGTTCAGTATCCTACTCGTGGTATTAATCGTGAATGGTCGTTCGAGGATTACATCAAGTTATTAAACCTTGATGTATCTGGTGTTATCAACGTAAACGCTACTGGCAGTGATCATACAATGGAATCTGGTGACAAAATGAACGGGCTATTCGTGTTATCTATCCTGTTGGACAAGAAACCGTATTTACCAGATGGTGTGAATACGATACCATCCTTTGCCGAATTATTCGGTCCTTATGCTGCTGCCTACGCAAATATGCATTTGCTGGATACTCAAAAGCAGCGATTTAAGGTCCTGGGACCAATTAAGAAATATTGTTCCTGTACTTCTGGAGCAATATATGCTCCATTAAAATTAAGGCTGAGATTGTCGAAGCCAAAGTGTCCTTTGTGGACTACGTTTAAGGACCCTGATCTTGGGAACTGCGGTGGAAATTATAAAAATATTTCCAAGAACGCTATTGTAATAAGCTATGCATTTATCTCTATGCATAGCCTTCATGTGGAACCATATGTTCAATTTGAACTACAATACATTGGATAA |
| Protein Sequence | MYNRNIRTPVKLRRSNFGHRWSSLTPSTSRLRPSKLNVSRKLGYDRIDREFRKNSIVEVQHGSHMSLDKNTDISSFVQYPTRGINREWSFEDYIKLLNLDVSGVINVNATGSDHTMESGDKMNGLFVLSILLDKKPYLPDGVNTIPSFAELFGPYAAAYANMHLLDTQKQRFKVLGPIKKYCSCTSGAIYAPLKLRLRLSKPKCPLWTTFKDPDLGNCGGNYKNISKNAIVISYAFISMHSLHVEPYVQFELQYIG |
| NCBI Accession | NP_620378.1 |
|---|---|
| Location | 1334-2230 |
| Protein Name | movement protein |
| Coding Region | ATGGAGAATTATTCAGGGGTGGTTGTAAACAACAAGTATGTAGAAACAAAGAGTTGCGAATACAGGCTGACGAACAACGAGATGCCTATCAAATTACAATTCCCTTCTTATTTGGAACAGAAAACTGTCCAAATAATGGGCAAATGCATGAAGGTTGACCATGCCGTTATTGAATACCGAAATCAAGTCCCCTTTAACGCCAAGGGGACCGTAGTGGTCACTATACGTGACACAAGACTCAGTTACGAACAAGCAGCACAGGCTGCGTTCACATTCCCAATAGCATGTAACGTCGATCTCCATTATTTCTCATCATCCTTTTTTTCTTTAAAGGATGAGACTCCATGGGAAATAGTTTACAAGGTCGAAGACTCCAATGTGATCGACGGGACAACATTTGCCCAGATTAAGGCGAAGCTGAAATTGTCGTCAGCCAAACACTCAACAGACATTAGATTCAAACCTCCGACAATAAATATATTGTCCAAGGACTACAACGAAAACTGTGTGTACTTTTGGTCTGTTGAGAAGCCTAAGCCCATTAGGCGGTTGCTGAATCCTGGACCCAACCAGGATCCCTATTCAATAAATGGACAAAGGCCCATTATGCTACAGCCTGGAGAGACTTGGGCTACAAGGTCCAGTATTGGGCGCAGTAGTTCTATGCGGTTGACGTCCACGGAAAGATTGGGCCTAACCAATAATGGGAGTACGTCCGAGGCAGAATATCCACTAAGACATTTGCATAAATTACCGGAGTCGTCTCTAGACCCCGGAGACTCAATTTCTCAAGCTCAATCGAATTCAATGAGTCGCAAGGACATAGAGGACATCATAGAGTCAACAATTAGCAAATGTCTAATAACACAGAGATCTAATGCAAACAAAGCTCTTTAA |
| Protein Sequence | MENYSGVVVNNKYVETKSCEYRLTNNEMPIKLQFPSYLEQKTVQIMGKCMKVDHAVIEYRNQVPFNAKGTVVVTIRDTRLSYEQAAQAAFTFPIACNVDLHYFSSSFFSLKDETPWEIVYKVEDSNVIDGTTFAQIKAKLKLSSAKHSTDIRFKPPTINILSKDYNENCVYFWSVEKPKPIRRLLNPGPNQDPYSINGQRPIMLQPGETWATRSSIGRSSSMRLTSTERLGLTNNGSTSEAEYPLRHLHKLPESSLDPGDSISQAQSNSMSRKDIEDIIESTISKCLITQRSNANKAL |
References More References in PubMed
| 1 |
Chowdary VT, et al. Mol Biol Rep. 2022 Sep;49(9):8587-8595. doi: 10.1007/s11033-022-07691-9. Epub 2022 Jun 19. PMID: 35718827 |
|---|---|
| 2 |
Mishra GP, et al. Front Plant Sci. 2020 Jun 24;11:918. doi: 10.3389/fpls.2020.00918. eCollection 2020. PMID: 32670329 |
| 3 |
NMR-Based Metabolomic Profiling of Mungbean Infected with Mungbean Yellow Mosaic India Virus. Maravi DK, et al. Appl Biochem Biotechnol. 2022 Dec;194(12):5808-5826. doi: 10.1007/s12010-022-04074-5. Epub 2022 Jul 12. PMID: 35819689 |
| 4 |
Balasubramaniam M, et al. Front Plant Sci. 2024 Aug 2;15:1401526. doi: 10.3389/fpls.2024.1401526. eCollection 2024. PMID: 39157510 |
| 5 |
Sivalingam PN, et al. 3 Biotech. 2022 Jan;12(1):29. doi: 10.1007/s13205-021-03088-w. Epub 2021 Dec 27. PMID: 35036277 |
| 6 |
Dhobale KV, et al. Appl Biochem Biotechnol. 2023 Aug;195(8):5158-5179. doi: 10.1007/s12010-023-04402-3. Epub 2023 Feb 28. PMID: 36853442 |
| 7 |
Dokka N, et al. Plant Dis. 2023 Oct;107(10):2924-2928. doi: 10.1094/PDIS-06-22-1473-SC. Epub 2023 Oct 11. PMID: 36890129 |
| 8 |
Chowdary VT, et al. Virusdisease. 2022 Mar;33(1):119-121. doi: 10.1007/s13337-021-00749-5. Epub 2022 Jan 27. PMID: 35493751 |
| 9 |
Sudha M, et al. Pathogens. 2022 Jan 30;11(2):190. doi: 10.3390/pathogens11020190. PMID: 35215133 |
| 10 |
Exogenous delivery of dsRNA for management of mungbean yellow mosaic virus on blackgram. Kamesh Krishnamoorthy K, et al. Planta. 2023 Oct 7;258(5):94. doi: 10.1007/s00425-023-04253-6. PMID: 37804329 |