Mimosa yellow leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000870825.1 |
| Isolate |
Viet Nam: Binhduong |
| Release date |
2015/2/13 |
| Submitter |
Ha,C., Coombs,S., Revill,P., Harding,R., Vu,M., Dale,J., Ha,C.V., Revill,P.A., Harding,R.M., Vu,M.T., Dale,J.L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
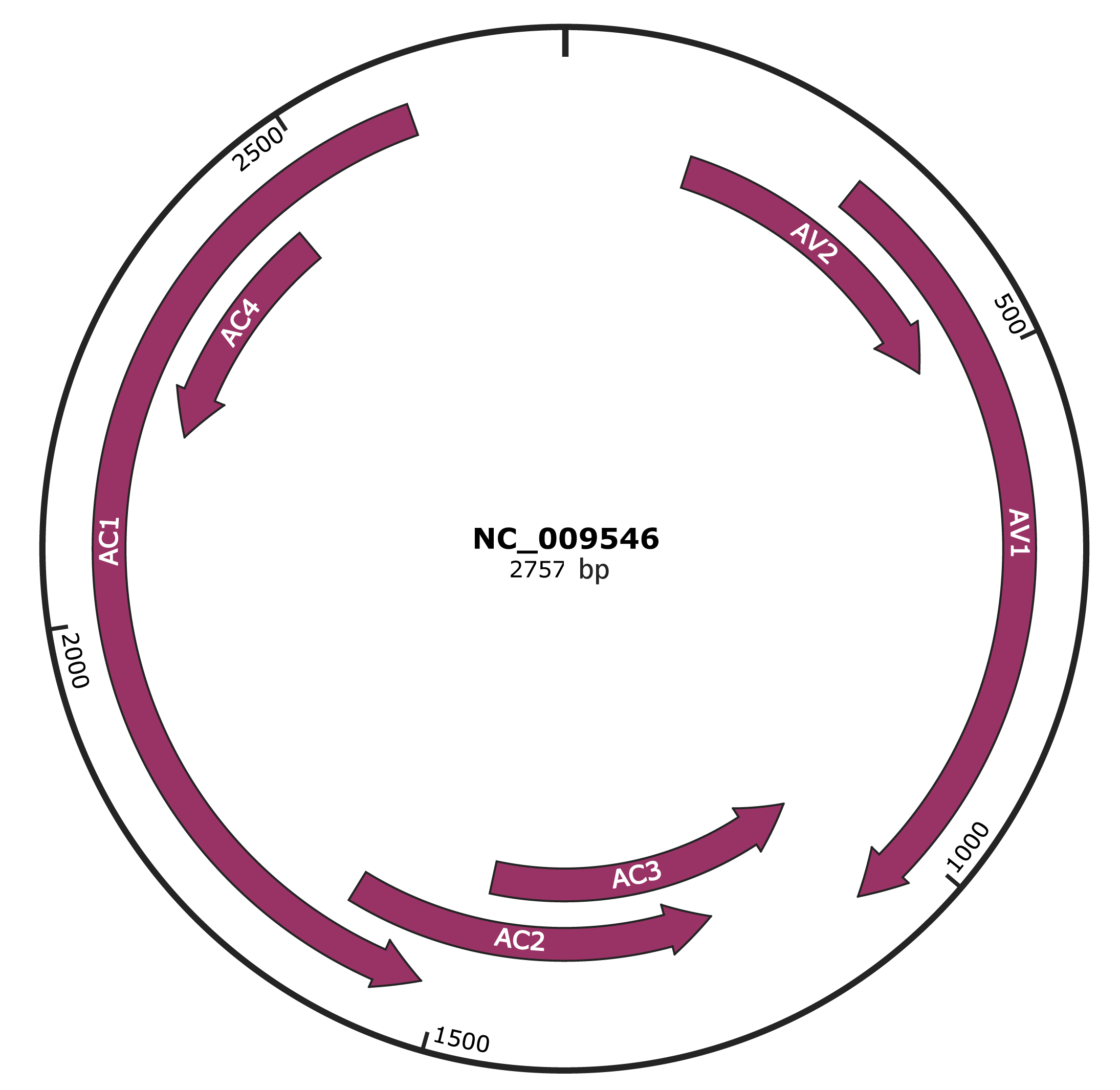
JBrowse
Genome
ACCGGATGGCCGCGAAAAATTAAAAAAAGTGGTGGCCCCCGCCACTAAGAAATGTCCGCCACTCAGAACTCTCCCTCAAAGCTTATTTAGTACGTTCCCGCTCTATTTAAACTTGGTCCCCAAGTTTAAATTCAAACATGTGGGATCCACTGTTGAATGAGTTTCCTGAAACCGTACACGGTTTTAGGTGTATGTTAGCGATTAAATATTTGCAATTAGTAGAAGATACATACTCTCCTGATACATTAGGGTACGATCTGCTTCGTGATTTAATTTCAGTTATTCGTGCTAAGGATTATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACGCCCGCCTCCAAAGTTCGTCGCCGATCGAACTTCGACAGCCCATATGCCAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAAAGGAGGTCATGGGTGAATCGGCCCATGTACAGAAAGCCCAGAATGTACAGGATGTACAAAAGCCCTGATGTCCCTCGTGGCTGTGAAGGCCCATGTAAGGTCCAATCTTATGAACAGCGTCATGATGTGGCCCATGTAGGTAAGGTAATTTGTGTGTCGGATGTCACCCGTGGGAATGGGTTGACTCATCGTGTTGGGAAGAGGTTCTGTGTCAAGTCCATTTATGTTTTGGGAAAAATATGGATGGATGAAAACATTAAGACCAAGAATCACACGAATACTGTGATGTTTTTTTTAGTTCGTGATAGGAGACCATTTGGTACTCCACAGGATTTTGGTCAGGTTTTTAACATGTATGATAACGAGCCTAGCACTGCTACTGTGAAGAACGACAACAGGGATCGCTTTCAAGTTCTACGGCGTTTTCAGGCGACTGTTACGGGTGGTCAATATGCAAGTAAGGAGCAGGCGATAGTTAGGAAATTTATGAAGGTGAACAATCATGTGACGTATAATCATCAAGAAGCTGCGAAGTATGACAATCATACTGAGAATGCTCTTTTATTGTATATGGCATGTACTCATGCCAGTAACCCAGTGTATGCTACTTTGAAGATCAGGATCTATTTCTATGATTCTGTTCAGAATTAATAAAGATTGAATTTTATTATATGAGAATGTGTTACATACTCTGTGTTTTCCAATACATCCCATAATACATGATTACATGCTCTAATTACATTGTTAATACTAATTACACCCAAATTATCTAAATATTTCATACATTGAACTCTAAATACTCTTAAGAAACGCCAAGTCTGAGGTTGTAAGCGAGTCCAGATTTGGAAGATTAGAAAACATTTGTGTATCCCCAACGCTTTCCTCAGGTTGTGGTTGAACTGGACCTGGACTGTTATGATGTCGTGGTTCCTCAGAAATGGCCTGTCGTGGTGCTGGGTCACTTTGAAATAGAGGGGATTGTTGATTGTCCAGATATATACGCCATTCTCGGCTTGAGCTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGCGATGCGCAGTTAATTCCAAAATAGTATGAGCATCCACAGGGAAGATCAACTCGACGCCTCCGAATTGGCCTCTTCTTGGCTATGTTGTGCTGGACTTTGATTGGTACCTGAGTACAATGGCTCCGTGAGGGTGATGAATTCCGCATTCTTCAATGCCCAGTCCTTTAAAGCTGAATTCTTTTCTTCGTCCAAGTACTCTTTATATGATGATGTTGGGCCTGGATTGCAGAGGAAGATAGTTGGGATTCCACCTTTAATTTGAATTGGTTTCCCGTACTTAGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTTAGGTAGTGGGGGTCTACGTCATCTATGACGTTGTACCATGCATCATTGCTGTACACCTTTGGGCTTAAACCAAGGTGCCCACATAAATAATTATGTGGACCCAATGACCTGGCCCACATTGTCTTGCCGGTACGACTATCACCCTCTATTACAATACTTTGAGGTCTCCACGGCCGCGCAGCGGCATCCCTCACATTCTCAGAGACCCAGACTTCAAGTTCTTCTGGAACTTGATCGAAAGAAGAAGAAAGAAAAGGACAAACGAAAACCTCCAAAGGAGGTGCAAAAATCCTATCTAAATTGGCGTTTAAATTATGAAATTGAAAAATATAATCTTTTGGGAGTTTCTCCCTTATTATGTTTAATGCTGCTTCCTTAGTAGCTGCATTTAACGCCTCTGCGCAAGCGTCGTTAGCATTCTGGCAGCCTCCCCTAGCACTTCTTCCGTCGATCTGGAAATCTCCCCATTCGATTGTGTCCCCGTCCTTGTCGATATAGGACTTGACGTCGGAACTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAATCTGTTATTCGTGCAGACGAATTTCCCTTCGAACTGGAGTAACACGTGGAGATGAGGGCTCCCATCTTCGTGAAGCTCTCTGCAGATTTTGATATATTTTTTGTTGGTTGGGGTTTGTATATTTTGTAATTGGGAAAGTGCCTCTTCTTTAGTTAGAGAGCACTGTGGATAAGTGAGGAAGTAGTTTTTAGCAGAAATTCTAAAACGTTTGGGCGGAGCCATTTGACTTGGTCAATTGGTGACAATCCAACTTGCCAAATGAATTGGTGACTGGTGACAATTTATACTTGTCACCAAATGGCATTCTCGTAATTGTCAAAGAAATTCAAAATTCAAATTTGAAATCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_001285730.1
|
|
Location
|
138-488 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCACTGTTGAATGAGTTTCCTGAAACCGTACACGGTTTTAGGTGTATGTTAGCGATTAAATATTTGCAATTAGTAGAAGATACATACTCTCCTGATACATTAGGGTACGATCTGCTTCGTGATTTAATTTCAGTTATTCGTGCTAAGGATTATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACGCCCGCCTCCAAAGTTCGTCGCCGATCGAACTTCGACAGCCCATATGCCAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAAAGGAGGTCATGGGTGAATCGGCCCATGTACAGAAAGCCCAGAATGTACAGGATGTACAAAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQLVEDTYSPDTLGYDLLRDLISVIRAKDYVEASRRYSHFHARLQSSSPIELRQPICQPCCCPHCPRHKQKEVMGESAHVQKAQNVQDVQKP |
|
NCBI Accession
|
YP_001285731.1
|
|
Location
|
298-1071 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP protein |
|
Coding Region
|
ATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACGCCCGCCTCCAAAGTTCGTCGCCGATCGAACTTCGACAGCCCATATGCCAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAAAGGAGGTCATGGGTGAATCGGCCCATGTACAGAAAGCCCAGAATGTACAGGATGTACAAAAGCCCTGATGTCCCTCGTGGCTGTGAAGGCCCATGTAAGGTCCAATCTTATGAACAGCGTCATGATGTGGCCCATGTAGGTAAGGTAATTTGTGTGTCGGATGTCACCCGTGGGAATGGGTTGACTCATCGTGTTGGGAAGAGGTTCTGTGTCAAGTCCATTTATGTTTTGGGAAAAATATGGATGGATGAAAACATTAAGACCAAGAATCACACGAATACTGTGATGTTTTTTTTAGTTCGTGATAGGAGACCATTTGGTACTCCACAGGATTTTGGTCAGGTTTTTAACATGTATGATAACGAGCCTAGCACTGCTACTGTGAAGAACGACAACAGGGATCGCTTTCAAGTTCTACGGCGTTTTCAGGCGACTGTTACGGGTGGTCAATATGCAAGTAAGGAGCAGGCGATAGTTAGGAAATTTATGAAGGTGAACAATCATGTGACGTATAATCATCAAGAAGCTGCGAAGTATGACAATCATACTGAGAATGCTCTTTTATTGTATATGGCATGTACTCATGCCAGTAACCCAGTGTATGCTACTTTGAAGATCAGGATCTATTTCTATGATTCTGTTCAGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRSNFDSPYASRAAAPTVLVTNKRRSWVNRPMYRKPRMYRMYKSPDVPRGCEGPCKVQSYEQRHDVAHVGKVICVSDVTRGNGLTHRVGKRFCVKSIYVLGKIWMDENIKTKNHTNTVMFFLVRDRRPFGTPQDFGQVFNMYDNEPSTATVKNDNRDRFQVLRRFQATVTGGQYASKEQAIVRKFMKVNNHVTYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSVQN |
|
NCBI Accession
|
YP_001285732.1
|
|
Location
|
1068-1472 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAAGCCGAGAATGGCGTATATATCTGGACAATCAACAATCCCCTCTATTTCAAAGTGACCCAGCACCACGACAGGCCATTTCTGAGGAACCACGACATCATAACAGTCCAGGTCCAGTTCAACCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAATCTTCCAAATCTGGACTCGCTTACAACCTCAGACTTGGCGTTTCTTAAGAGTATTTAGAGTTCAATGTATGAAATATTTAGATAATTTGGGTGTAATTAGTATTAACAATGTAATTAGAGCATGTAATCATGTATTATGGGATGTATTGGAAAACACAGAGTATGTAACACATTCTCATATAATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAAQAENGVYIWTINNPLYFKVTQHHDRPFLRNHDIITVQVQFNHNLRKALGIHKCFLIFQIWTRLQPQTWRFLRVFRVQCMKYLDNLGVISINNVIRACNHVLWDVLENTEYVTHSHIIKFNLY |
|
NCBI Accession
|
YP_001285733.1
|
|
Location
|
1213-1620 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP protein |
|
Coding Region
|
ATGCGGAATTCATCACCCTCACGGAGCCATTGTACTCAGGTACCAATCAAAGTCCAGCACAACATAGCCAAGAAGAGGCCAATTCGGAGGCGTCGAGTTGATCTTCCCTGTGGATGCTCATACTATTTTGGAATTAACTGCGCATCGCATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAAGCCGAGAATGGCGTATATATCTGGACAATCAACAATCCCCTCTATTTCAAAGTGACCCAGCACCACGACAGGCCATTTCTGAGGAACCACGACATCATAACAGTCCAGGTCCAGTTCAACCACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAATCTTCCAAATCTGGACTCGCTTACAACCTCAGACTTGGCGTTTCTTAAGAGTATTTAG |
|
Protein Sequence
|
MRNSSPSRSHCTQVPIKVQHNIAKKRPIRRRRVDLPCGCSYYFGINCASHGFTHRGTHHCSSSREWRIYLDNQQSPLFQSDPAPRQAISEEPRHHNSPGPVQPQPEESVGDTQMFSNLPNLDSLTTSDLAFLKSI |
|
NCBI Accession
|
YP_001285734.1
|
|
Location
|
1520-2608 |
|
Gene Name
|
AC1 |
|
Protein Name
|
rep protein |
|
Coding Region
|
ATGGCTCCGCCCAAACGTTTTAGAATTTCTGCTAAAAACTACTTCCTCACTTATCCACAGTGCTCTCTAACTAAAGAAGAGGCACTTTCCCAATTACAAAATATACAAACCCCAACCAACAAAAAATATATCAAAATCTGCAGAGAGCTTCACGAAGATGGGAGCCCTCATCTCCACGTGTTACTCCAGTTCGAAGGGAAATTCGTCTGCACGAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGTTCCGACGTCAAGTCCTATATCGACAAGGACGGGGACACAATCGAATGGGGAGATTTCCAGATCGACGGAAGAAGTGCTAGGGGAGGCTGCCAGAATGCTAACGACGCTTGCGCAGAGGCGTTAAATGCAGCTACTAAGGAAGCAGCATTAAACATAATAAGGGAGAAACTCCCAAAAGATTATATTTTTCAATTTCATAATTTAAACGCCAATTTAGATAGGATTTTTGCACCTCCTTTGGAGGTTTTCGTTTGTCCTTTTCTTTCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGTCTGGGTCTCTGAGAATGTGAGGGATGCCGCTGCGCGGCCGTGGAGACCTCAAAGTATTGTAATAGAGGGTGATAGTCGTACCGGCAAGACAATGTGGGCCAGGTCATTGGGTCCACATAATTATTTATGTGGGCACCTTGGTTTAAGCCCAAAGGTGTACAGCAATGATGCATGGTACAACGTCATAGATGACGTAGACCCCCACTACCTAAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACTAAGTACGGGAAACCAATTCAAATTAAAGGTGGAATCCCAACTATCTTCCTCTGCAATCCAGGCCCAACATCATCATATAAAGAGTACTTGGACGAAGAAAAGAATTCAGCTTTAAAGGACTGGGCATTGAAGAATGCGGAATTCATCACCCTCACGGAGCCATTGTACTCAGGTACCAATCAAAGTCCAGCACAACATAGCCAAGAAGAGGCCAATTCGGAGGCGTCGAGTTGA |
|
Protein Sequence
|
MAPPKRFRISAKNYFLTYPQCSLTKEEALSQLQNIQTPTNKKYIKICRELHEDGSPHLHVLLQFEGKFVCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGDFQIDGRSARGGCQNANDACAEALNAATKEAALNIIREKLPKDYIFQFHNLNANLDRIFAPPLEVFVCPFLSSSFDQVPEELEVWVSENVRDAAARPWRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLGLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEEKNSALKDWALKNAEFITLTEPLYSGTNQSPAQHSQEEANSEASS |
|
NCBI Accession
|
YP_001285735.1
|
|
Location
|
2194-2451 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAGCCCTCATCTCCACGTGTTACTCCAGTTCGAAGGGAAATTCGTCTGCACGAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGTTCCGACGTCAAGTCCTATATCGACAAGGACGGGGACACAATCGAATGGGGAGATTTCCAGATCGACGGAAGAAGTGCTAGGGGAGGCTGCCAGAATGCTAACGACGCTTGCGCAGAGGCGTTAA |
|
Protein Sequence
|
MGALISTCYSSSKGNSSARITDSSTWYPQPGQHISIRTFRELNPVPTSSPISTRTGTQSNGEISRSTEEVLGEAARMLTTLAQRR |