Merremia mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000867165.1 |
| Isolate | Puerto Rico |
| Release date | 2015/2/13 |
| Submitter | Brown,J.K., Idris,A.M., Torres-Jerez,I., Banks,G.K., Wyatt,S.D., Baumann,K., Bird,J. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
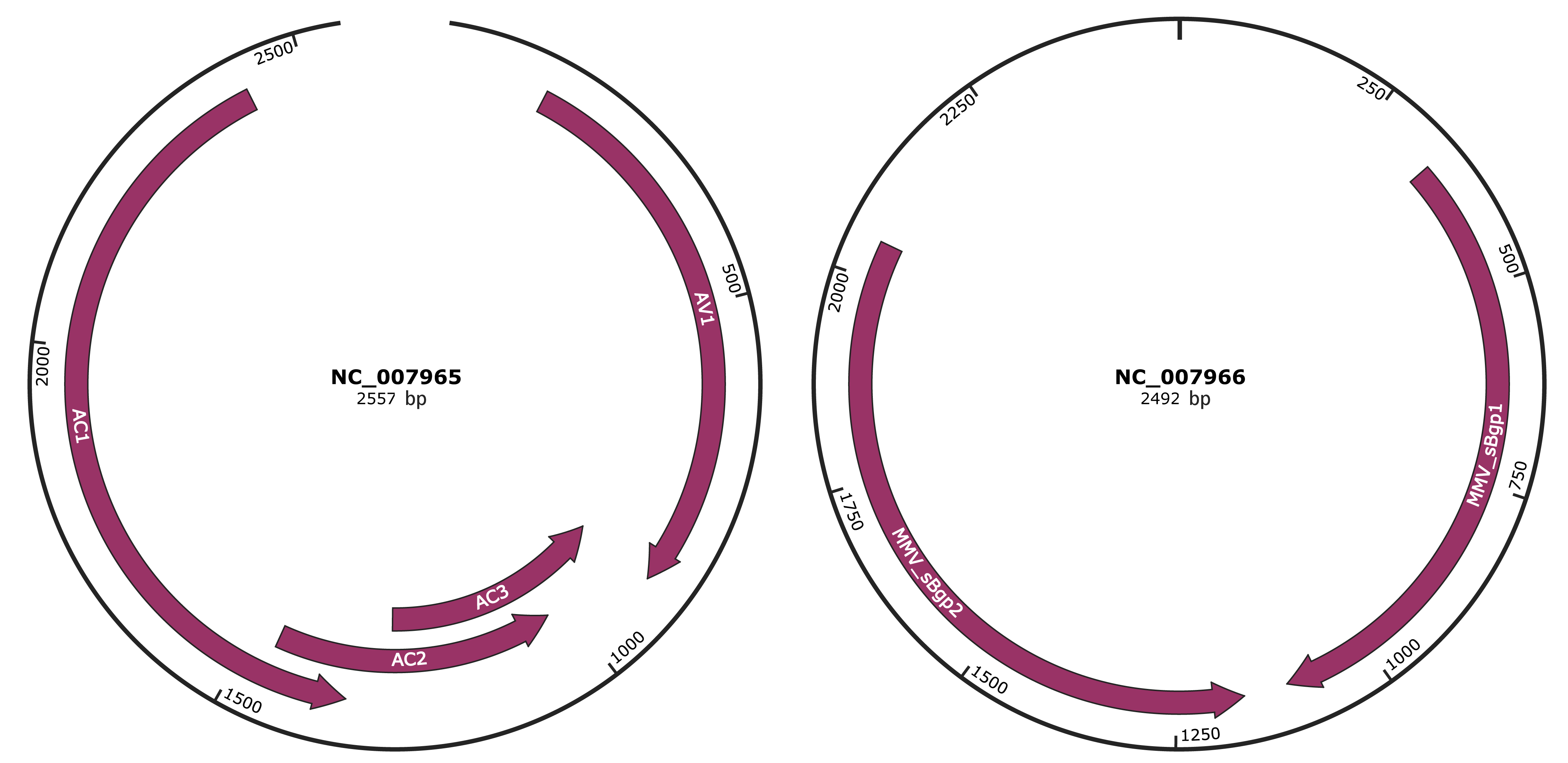
JBrowse
Genome
NC_007965
NC_007966
Gene Information
| NCBI Accession | YP_579167.1 |
|---|---|
| Location | 142-888 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGGTTAAGAGGGACGCCCCATGGCGTTTAATGGCGGGGACCACTAAAGTTAGTCGCAACGCCAATTTCTCGCCACGTGGAGGTATGGGCCCTAAGGCCGCTGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGAATTTATCGCACTTTGAGAGGGCCTGATGTTCCTAAAGGTTGTGAAGGCCCATGTAAGGTACAGTCTTTCGAGCAGCGTCATGATATTTCTCATGTTGGTAAGGTAATCTGTATATCCGATGTAACTCGTGGTAACGGTATTACCCACCGTGTTGGCAAGCGTTTTTGTGTGAAGTCTGTGTATATTCTAGGTAAAATATGGATGGATGAGAACATAAAGCTGAAGAACCACACGAACAGCGTCATGTTTTGGTTGATTCGTGACAGGAGACCCTATGGTACCCCTATGGATTTTGGTCAGGTGTTTAACATGTATGACAATGAGCCGAGTACTGCTACCGTCAAGAACGATCTTCGCGATCGATTTCAAGTCATGCATAGGTTCTATGCCAAAGTAACTGGTGGTCAGTATGCCAGTAACGAGCAGGCATTGGTTCGGCGATTTTGGAAGGTTAACAACTACGTCGTGTATAACCATCAGGAAGCAGGAAAATACGAGAATCACACGGAGAATGCTCTGTTATTGTATATGGCATCTACTCATGCTTCTAATCCTGTGTATGCTACCTTGAAAATTCGTAGTTATTTTTATGACTCCATTTCGAATTAA |
| Protein Sequence | MVKRDAPWRLMAGTTKVSRNANFSPRGGMGPKAAAWVNRPMYRKPRIYRTLRGPDVPKGCEGPCKVQSFEQRHDISHVGKVICISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLIRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRFQVMHRFYAKVTGGQYASNEQALVRRFWKVNNYVVYNHQEAGKYENHTENALLLYMASTHASNPVYATLKIRSYFYDSISN |
| NCBI Accession | YP_579168.1 |
|---|---|
| Location | 885-1283 |
| Gene Name | AC3 |
| Protein Name | AC3 |
| Coding Region | ATGGATTCACGCACAGGGGAACCCATCACTGCTCATCAAGCAATGAATGGCGTTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAATCCAAGTGGAGGAGCCAATATACACCACAACCAGAATATACACCATCCAAATACGGTTCAACTACAACCTGAGGAAGGCGTTGAGTCTACACAAAGCATACCTGAACTTCCAAATCTGGACGACATCAGTTCAAGCTTCTGGGACGACATATTTAAATAGATTTAAAGATTTAGTTTTAATGTATTTAGATCAATTAGGTGTTGTTTCGCTTAACAATGTCATTAGAGCTGTTCGTTTCGCAACGGATAAACCATATGTAAATTGTGTGCTCGAAAGACATTCAATAAAATTTAATCTTTATTAA |
| Protein Sequence | MDSRTGEPITAHQAMNGVFIWEVPNPLYFKIIQVEEPIYTTTRIYTIQIRFNYNLRKALSLHKAYLNFQIWTTSVQASGTTYLNRFKDLVLMYLDQLGVVSLNNVIRAVRFATDKPYVNCVLERHSIKFNLY |
| NCBI Accession | YP_579169.1 |
|---|---|
| Location | 1030-1461 |
| Gene Name | AC2 |
| Protein Name | AC2 |
| Coding Region | ATGAAAACGCATCTCTCAGAGCGTGGACGATCCACAATGCAAAATTCATCTTCCTCAACTCCCCCCTCTATCAAAGCACAGCACAGGAGAGCGAAGAGATCCAAATCTGTCATTAGACGGAGAAGGTTAGACCTGGACTGTGGCTGTTCAATTTACGTACACATCAACTGCAGAAACCATGGATTCACGCACAGGGGAACCCATCACTGCTCATCAAGCAATGAATGGCGTTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAATCCAAGTGGAGGAGCCAATATACACCACAACCAGAATATACACCATCCAAATACGGTTCAACTACAACCTGAGGAAGGCGTTGAGTCTACACAAAGCATACCTGAACTTCCAAATCTGGACGACATCAGTTCAAGCTTCTGGGACGACATATTTAAATAG |
| Protein Sequence | MKTHLSERGRSTMQNSSSSTPPSIKAQHRRAKRSKSVIRRRRLDLDCGCSIYVHINCRNHGFTHRGTHHCSSSNEWRFYLGGSKSPLFQDNPSGGANIHHNQNIHHPNTVQLQPEEGVESTQSIPELPNLDDISSSFWDDIFK |
| NCBI Accession | YP_579170.1 |
|---|---|
| Location | 1346-2422 |
| Gene Name | AC1 |
| Protein Name | AC1 |
| Coding Region | ATGCCACGGAAGGGTTCATTCTCAATAAAAGCCAAAAACTATTTCCTCACATACCCTATATGTTCATTAGCCAAAGAAGAAGCACTGTCCCAAATCAAAGCTCTGCACACCCCTGTAAACAAAAAATTCATCAAGATCTGTAGAGAGCTTCACGATAATGGGGAACCTCATCTTCATGTGCTTATCCAGTTCGAAGGAAAATACAACTGCACGAATAACAGATTCTTCGATTTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGAGATACAATTGAATGGGGACAATTCCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAGTCTTCTAACGATACATACGCAAAGGCGTTAAACGCAGCTTCTGCAGAGGAAGCACTGCAAATAATAAAGGAGGAACAACCACAACACTTCTTTCTTCAACATCACAATCTCGTTGCGAACGCAACAAGAATATTTCAGAAGTCTCCAGAACCATGGGTTCCTCCGTTTCAACTCTCCTCCTTCACGAACGTTCCAGATGAGATGCAAGAATGGGCAGACAACTACTTTGGGAGGGGTGCCGCTGCGCGGGCAGATAGACCGATAAGTATCATCATCGAAGGAGATAGTCGAACTGGAAAAACAATGTGGGCCCGTTCATTAGGTAAACATAATTATCTTAGTGGACATCTTGACTTTAATGGCAGAGTCTATTCGAATGACGTCGAATATAACGTCATTGATGACATAAGCCCTAATTATTTGAAATTAAAGCATTGGAAAGAATTGATAGGGGCCCAAAAGGACTGGCAGTCCAACTGTAAATACGGGAAGCCAGTTCAAACTAAAGGAGGAATACCCTCAATCGTGCTGTGCAATCCAGGAGAGGGGGCTAGCTATAAAGACTTCCTCGATAAAGATGAAAACGCATCTCTCAGAGCGTGGACGATCCACAATGCAAAATTCATCTTCCTCAACTCCCCCCTCTATCAAAGCACAGCACAGGAGAGCGAAGAGATCCAAATCTGTCATTAG |
| Protein Sequence | MPRKGSFSIKAKNYFLTYPICSLAKEEALSQIKALHTPVNKKFIKICRELHDNGEPHLHVLIQFEGKYNCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGQFQIDGRSARGGQQSSNDTYAKALNAASAEEALQIIKEEQPQHFFLQHHNLVANATRIFQKSPEPWVPPFQLSSFTNVPDEMQEWADNYFGRGAAARADRPISIIIEGDSRTGKTMWARSLGKHNYLSGHLDFNGRVYSNDVEYNVIDDISPNYLKLKHWKELIGAQKDWQSNCKYGKPVQTKGGIPSIVLCNPGEGASYKDFLDKDENASLRAWTIHNAKFIFLNSPLYQSTAQESEEIQICH |
| NCBI Accession | YP_579171.1 |
|---|---|
| Location | 339-1109 |
| Protein Name | BV1 protein |
| Coding Region | ATGTATTCTTTTAGATATAGACCGTATCATTTTAATTATCGGAAACGATTTTACACACGTACGCAAGTGTCTAAACGGGTAGCCCCGTTTAAACGAGCTGATGTGAAATGTCGAACGAGGCAGACGACTATCGTTCATGATGAGACTAAGATGTCTTCGCAGCGCATTCATGAGAACCAATTTGGTCCAGAGTTTGTGATGACACATAACTCCGCCATATCCACTTTCATTAATTATCCTACTTTGAGTAAGACCGAGCCTAACAGAAGCAGATCTTACATTAAGTTGAAACGCTTGCGGTTTAAGGGTACTGTTAAAATTGAGCGTGTGTATGCGGATATGAACATGGATGGTTTGAACCCTAAAGTTGAAGGGGTATTCACTCTTGCTGTTGTAGTTGACCGAAAACCTCATTTAAAGCCATCTGGATGTCTGCATACATTTGATGAGGTATTTGGTGCACGGATTCACAGTCATGGTACGTTAGCCATTACTCCGTCACTGACAGATCGTTACTACATTCGCCATGTGTTTAAACGTGTAATGTCTGTTGAGAAGGATACTGCCATGGTTGATGTGGAAGGATCGATGTCTCTCTCTAATAAGCGTTTTAATTGTTGGGCTACGTTTAAGGATCTTGATCATGAATCTTGTAAGGGTGTTTATGACAATATTAGCAAAAACGCCTTGTTAATTTATTATTGTTGGATGTCTGATGTACCATCTAAGGCATCGTCATTTGTATCATTTGATTTGGATTATGTTGGCTAA |
| Protein Sequence | MYSFRYRPYHFNYRKRFYTRTQVSKRVAPFKRADVKCRTRQTTIVHDETKMSSQRIHENQFGPEFVMTHNSAISTFINYPTLSKTEPNRSRSYIKLKRLRFKGTVKIERVYADMNMDGLNPKVEGVFTLAVVVDRKPHLKPSGCLHTFDEVFGARIHSHGTLAITPSLTDRYYIRHVFKRVMSVEKDTAMVDVEGSMSLSNKRFNCWATFKDLDHESCKGVYDNISKNALLIYYCWMSDVPSKASSFVSFDLDYVG |
| NCBI Accession | YP_579172.1 |
|---|---|
| Location | 1165-2046 |
| Protein Name | BC1 protein |
| Coding Region | ATGGATGCTCAATTGGTTAATCCTCCAAGTGCCTTTAATTATATAGAATCTCACAGAGACGAATATCAGCTATCTCATGATTTAACTGAGATAATACTGCACTTTCCGTCAGCAGCGGCTCAATTATCAGCAAGATTAAGTCGCAGTTGTATGAAAATAGATCACTGCGTCATAGAATACAGGCAACAGGTACCGATAAACGCAATAGGTACTGTAATTGTGGAGATCCACGACAGAAGGATGACGGATAACGAATCATTACAAGCATCATGGACGTTCCCAATCAGATGCAACATAGACCTTCATTACTTTTCCTCGTCTTTCTTCTCACTGAAAGACCCAATCCCGTGGAAACTATACTACAGAGTCTGTGATTCAAACATACACCAACGAACACATTTCGCCAAGTTCAAAGGGAAACTAAAACTGTCGACAGCGAAACATTCTGTAGATATCCCATTCAGAGCTCCGGCGGTGAAGATCCTGTCTAAGCAATTTTCCGAGAAGGATGTCGATTTCTCACATGTGGGCTACGGGAGATGGGAAAGAAAAATGATCCGGTCAATCTCAATGGCAAGAATTGGGCTACCAAGCCCAATAGAATTATTACCAGGCGAGTCATGGGCCTCAAGAAGCACAATCGGTATAGGCCAAACGGACACAGATTCGGAACTGGAAAATGCAATACACCCATACAGGCAACTCAATCGTCTGGGAACCAGTGCGTTGGATCCAGGTGATTCTGCTTCAATCGTAGGGGCTTCAAGGGCCCAATCCAATATAACAATGTCAATGGCCCAATTAAATGATCTTGTACGATCAACGGTCCATGAGTGTATTAATAGTAATTGTACACCGGCTCAGCCGAAATCGTTAAAATAG |
| Protein Sequence | MDAQLVNPPSAFNYIESHRDEYQLSHDLTEIILHFPSAAAQLSARLSRSCMKIDHCVIEYRQQVPINAIGTVIVEIHDRRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDSNIHQRTHFAKFKGKLKLSTAKHSVDIPFRAPAVKILSKQFSEKDVDFSHVGYGRWERKMIRSISMARIGLPSPIELLPGESWASRSTIGIGQTDTDSELENAIHPYRQLNRLGTSALDPGDSASIVGASRAQSNITMSMAQLNDLVRSTVHECINSNCTPAQPKSLK |
References More References in PubMed
| 1 |
Idris AM, et al. Virusdisease. 2019 Mar;30(1):84-94. doi: 10.1007/s13337-017-0412-6. Epub 2018 Feb 23. PMID: 31143835 |
|---|---|
| 2 |
Tropical Whitefly IPM Project. Morales FJ. Adv Virus Res. 2007;69:249-311. doi: 10.1016/S0065-3527(06)69006-4. PMID: 17222696 |
| 3 |
Next-Generation Sequencing and Genome Editing in Plant Virology. Hadidi A, et al. Front Microbiol. 2016 Aug 26;7:1325. doi: 10.3389/fmicb.2016.01325. eCollection 2016. PMID: 27617007 |
| 4 |
Mgbechi-Ezeri JU, et al. Plant Dis. 2008 Dec;92(12):1709. doi: 10.1094/PDIS-92-12-1709B. PMID: 30764308 |
| 5 |
Cardin L, et al. Plant Dis. 2009 Feb;93(2):201. doi: 10.1094/PDIS-93-2-0201B. PMID: 30764126 |
| 6 |
Targeting of SPCSV-RNase3 via CRISPR-Cas13 confers resistance against sweet potato virus disease. Yu Y, et al. Mol Plant Pathol. 2022 Jan;23(1):104-117. doi: 10.1111/mpp.13146. Epub 2021 Oct 11. PMID: 34633749 |
| 7 |
Whitefly transmission of sweet potato viruses. Valverde RA, et al. Virus Res. 2004 Mar;100(1):123-8. doi: 10.1016/j.virusres.2003.12.020. PMID: 15036843 |
| 8 |
Sweet potato viromes in eight different geographical regions in Korea and two different cultivars. Jo Y, et al. Sci Rep. 2020 Feb 13;10(1):2588. doi: 10.1038/s41598-020-59518-x. PMID: 32054944 |
| 9 |
Fiallo-Olivé E, et al. Arch Virol. 2014 Jul;159(7):1857-60. doi: 10.1007/s00705-014-1996-4. Epub 2014 Jan 25. PMID: 24463954 |
| 10 |
Wei KJ, et al. Virol J. 2024 Sep 19;21(1):222. doi: 10.1186/s12985-024-02500-0. PMID: 39300471 |