Merremia mosaic Puerto Rico virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000892695.1 |
| Isolate | Puerto Rico |
| Release date | 2015/2/22 |
| Submitter | Idris,A.M., Brown,J.K. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
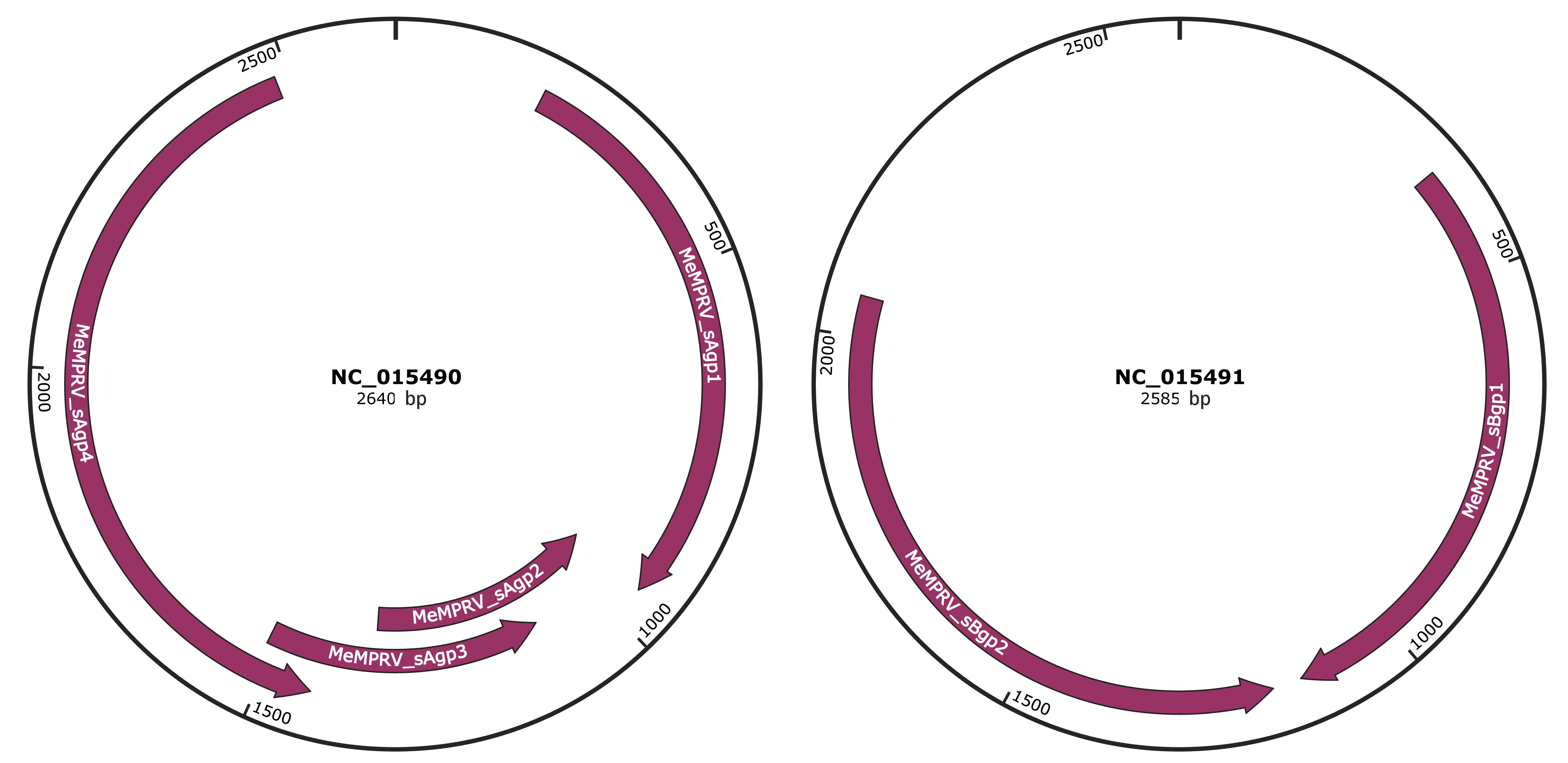
Genomic Organization
JBrowse
Genome
NC_015490
NC_015491
Gene Information
| NCBI Accession | YP_004429242.1 |
|---|---|
| Location | 200-955 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCGTGGCGTTCTATGGCGGGAACCTCCAAGGTTAGTCGAAACGCCAATTATTCTCCTGGTGGATCATCTGGCCCAAAATCCAACAGGGCCAATACTTGGGTTAATAGGCCCATGTACAGGAAGCCCAGGATATATCGGATGTATAGGACCCCCGATGTTCCAAGAGGCTGTGAAGGCCCATGTAAGGTGCAATCCTTTGAGCAACGCCATGATATCTCACATGTTGGCAAGGTGATGTGTATATCCGACGTGACACGTGGGAACGGTATAACTCACCGTGTTGGTAAGCGTTTTTGTGTTAAGTCCGTGTACATACTAGGCAAGATATGGATGGACGAGAACATCAAGTTGAAGAACCACACCAATAGTGTTATGTTTTGGTTAGTTAGGGATAGGAGACCATATGGCACTCCCATGGATTTTGGGCAAGTGTTTAATATGTTTGACAATGAGCCTAGTACTGCTACGGTCAAGAATGATCTCCGTGATCGTTTTCAAGTCATGCACAAATTTTATGCCAAGGTTACAGGTGGACAATATGCTAGTAATGAGCAGGCGATTGTTAAGCGTTTCTGGAAGGTGAACAGTCATGTTGTTTATAACCACCAGGAAGCCGCTAAGTACGAAAATCATACGGAGAATGCTCTATTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCTACTTTGAAAATTCGGATCTATTTTTATGATTCGATAATGAATTAA |
| Protein Sequence | MPKRDAPWRSMAGTSKVSRNANYSPGGSSGPKSNRANTWVNRPMYRKPRIYRMYRTPDVPRGCEGPCKVQSFEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQAIVKRFWKVNSHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | YP_004429243.1 |
|---|---|
| Location | 952-1350 |
| Protein Name | REn |
| Coding Region | ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCAACGAGTGGCGTTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAAATAATCAGGGTGGACCGTCCAATGTTCACCCACAGCAGAGTGTTCCACATACAAATTCGCGCCAACCACAACCTCAGGAAAGCGTTGGATCTCCACAAAGCCTACTTCAATTTCCAAGTCTGGACGACTTTGACGACAGCTTCTGGGCAGATTTATTTAAGTAGATTCAAATTTCTTGTTATGAAATTCTTAGACAATTTAGGGGTTATTTCAGTTAATAATGTAATTAGAGCTGTCTCATATGCAACGGACAGACAATATGTAAATGATGTACTTGAACAACATGAAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTGEPITAAQATSGVFIWEVPNPLYFKIIRVDRPMFTHSRVFHIQIRANHNLRKALDLHKAYFNFQVWTTLTTASGQIYLSRFKFLVMKFLDNLGVISVNNVIRAVSYATDRQYVNDVLEQHEIKFKFY |
| NCBI Accession | YP_004429244.1 |
|---|---|
| Location | 1097-1513 |
| Protein Name | TrAP |
| Coding Region | ATGACTGGGCAAAGAAAAACGCCGTCTTCGTCACCATTGAGGAACCACTCTACTCCACCGTCAATCAAACCTCGTCATAGATTCGCAAAGAGGCAGACGAGACGTAAAAGAATTGATCTGCAGTGCGGTTGTTCATATTACCTACACATTAACTGCAGCAACCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCAACGAGTGGCGTTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAAAATAATCAGGGTGGACCGTCCAATGTTCACCCACAGCAGAGTGTTCCACATACAAATTCGCGCCAACCACAACCTCAGGAAAGCGTTGGATCTCCACAAAGCCTACTTCAATTTCCAAGTCTGGACGACTTTGACGACAGCTTCTGGGCAGATTTATTTAAGTAG |
| Protein Sequence | MTGQRKTPSSSPLRNHSTPPSIKPRHRFAKRQTRRKRIDLQCGCSYYLHINCSNHGFTHRGTHHCSSSNEWRFYLGGSKSPLFQNNQGGPSNVHPQQSVPHTNSRQPQPQESVGSPQSLLQFPSLDDFDDSFWADLFK |
| NCBI Accession | YP_004429245.1 |
|---|---|
| Location | 1434-2483 |
| Protein Name | Rep |
| Coding Region | ATGCCATCAGTTCAGCGTTTTAGAATAAATGCCAAGAATTATTTCATTACATACCCCAAGTGCTCTCTAACCAAAGAAGAGGCACTTTCCCAATTACAAAACCTAAACACTCCTGTCAACAAGAAGTTCATCAAAATATGCAGAGAACTCCACGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGGAAATACCAGTGCAAGAATAACAGATTCTTCGACTTGGTTTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAGTCTAGCTCCGACGTCAAGTCCTACATCGACAAAGACGGAGATACAATCGAATGGGGACAATTTCAAATCGACGGCAGATCTGCTAGAGGAGGTCAGCAATCTGCTAACGACACATATGCGACGGCGTTGAATTCATCTTCTGCAGAAGAGGCGATGCAGATCATTAAGGAACAACAACCACAACATTTCGTCCTCCAATATCACAATCTGGTTTCAAATATAACGAAAATATTCCATAAACCTCCGGAACCATGGGTTCCTCCATTTCAAATGTCCACGTTCATTAATGTACCGGAAATAATGATGAAGTGGGTCGACGATAATATTTCCGATGCCGCTGCGCGGCCGTTGAGACCTATATCAATCATTGTTGAAGGACCATCAAGAACGGGCAAAACAATATGGGCCCGTAGCCTGGGCCCTCACAATTATCTATGTGGACATATAGATCTCAACCCGAGGATATACTCCAATGATGCATGGTATAACGTCATCGATGACGTAGATCCGCATTATCTCAAGCACTTTAAAGAATTCATGGGGGCCCAGAGGGATTGGCCATCAAACTGCAAATACGGAAAGCCAATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCTGGCCCCCATTCATCATATAAGGAGTATCTCGGAGAGGAAAAAAACAAAACACTCAATGACTGGGCAAAGAAAAACGCCGTCTTCGTCACCATTGAGGAACCACTCTACTCCACCGTCAATCAAACCTCGTCATAG |
| Protein Sequence | MPSVQRFRINAKNYFITYPKCSLTKEEALSQLQNLNTPVNKKFIKICRELHENGEPHLHVLIQFEGKYQCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGQFQIDGRSARGGQQSANDTYATALNSSSAEEAMQIIKEQQPQHFVLQYHNLVSNITKIFHKPPEPWVPPFQMSTFINVPEIMMKWVDDNISDAAARPLRPISIIVEGPSRTGKTIWARSLGPHNYLCGHIDLNPRIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWPSNCKYGKPIQIKGGIPTIFLCNPGPHSSYKEYLGEEKNKTLNDWAKKNAVFVTIEEPLYSTVNQTSS |
| NCBI Accession | YP_004429246.1 |
|---|---|
| Location | 361-1131 |
| Protein Name | movement protein |
| Coding Region | ATGTATTTGCTAAGATATAGACGTGGAACATCTTACTCACAACGACGATATAATACAGGTAATAATGTGTTTAAACGTGTATCATATGTTAAACGTAAGGATGGTAAGCGTCGATCGAGTCATGGAAATAATGTTCATGAAGATGGGAAGATGACGTCTCAACGCATACATGAAAATCAGTATGGGCCTGAATTTGTGATGTCTCAAAATTCAGCGTTATCCACATTCATTACTTTTCCTCATTTGGGGAAGACTCAACCTAATCGGTGCAGGTCATATATTAAGCTGAAACGGCTTCGTTTTAAAGGAACTGTTAAGATTGAACGTGTTCATGCGGATTTGAACATGGATGGTTTGCTCCCTAAGATTGAAGGTGTATTTTCCCTTGTAATTGTGGTGGATCGCAAACCCCATTTGAATGCTTCTGGATGTTTGCACTCATTTGACGAATTATTTGGTGCAAGGATCAACAGCCACGGGAATTTAGCTATTATCTCAGCTTTGAAAGATCGTTTTTATGTTCGTCATGTATTGAAACGTGTGTTGTCCGTGGAGAAAGACAGTACGATGATGGACCTGGAAGGATCGATCTTTTTTTCTAATAGGCGTTTTAATTGTTGGTCAAGTTTTAAAGATAATGACCATGATTCATGTAATGGTGTTTATGACAATATTAGCAAAAACGCCATATTAGTTTATTATTGTTGGATGTCGGATGTAATGTCTAAGGCATCAACATTTGTATCGTTCGACCTTGATTATGTTGGGTGA |
| Protein Sequence | MYLLRYRRGTSYSQRRYNTGNNVFKRVSYVKRKDGKRRSSHGNNVHEDGKMTSQRIHENQYGPEFVMSQNSALSTFITFPHLGKTQPNRCRSYIKLKRLRFKGTVKIERVHADLNMDGLLPKIEGVFSLVIVVDRKPHLNASGCLHSFDELFGARINSHGNLAIISALKDRFYVRHVLKRVLSVEKDSTMMDLEGSIFFSNRRFNCWSSFKDNDHDSCNGVYDNISKNAILVYYCWMSDVMSKASTFVSFDLDYVG |
| NCBI Accession | YP_004429247.1 |
|---|---|
| Location | 1170-2051 |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGGATTCTCAGTTAGCAAATCCTCCAAATGCCTTTAATTACATAGAATCCAATAGGGATGAATATCAGCTGTCTCATGATCTAACTGAGATAGTCCTTCAATTTCCTTCAACTGCATCTCAATTAACAGCTAGACTTAGTCGTAGCTGCATGAAAATAGACCATTGTGTCATCGAGTACAGGCAACAAGTACCCATAAACGCAACTGGTACAGTTATTGTGGAGATCCATGACAAAAGGATGATTGACAACGAATCCTTACAAGCGTCATGGACATTTCCAATTAGATGCAACATAGATCTCCACTATTTTTCATCGTCCTTTTTCTCGCTAAAAGACCCAATTCCATGGAAGCTGTATTACAGGGTTAGCGACACAAATGTCCACCACAGAACGCATTTTGCCAAGTTCAAGGGAAAATGGAAGTTGTCCACGGCGAAACATTCGGTGGATATCCCATTCCGGGCACCGACGGTCAAAATACTATCCAAACAATTCTCGCATAAAGATGTGGATTTTACACATGTGGACTACGGACGATGGGAACGGAAAACGTTGAGGTCCACATCAATATCAAGAGTTGGGTTACCCGGCCCAATTGAATTAAGACCAGGTGAATCGTGGGCTTCAAAGAGTACAATTGGGCTAGCCCACACAGATACTGATTCAGAGTTGGACAACGCGTTACACCCCTATAAAGAACTAAATCGTTTGGGAGCAAGCGTCCTAGACCCAGGAGATTCAGCATCACAAGCCGGGTTACAACGGGCCCAATCAAACATTACAATGTCAATGGCCCAATTAAACGAGTTAGTTAGGACAACGGTCCATGAATGTATAAACACAAACTGTAATTCCAATCCGCCTAAATCTTTGAAATAA |
| Protein Sequence | MDSQLANPPNAFNYIESNRDEYQLSHDLTEIVLQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMIDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHHRTHFAKFKGKWKLSTAKHSVDIPFRAPTVKILSKQFSHKDVDFTHVDYGRWERKTLRSTSISRVGLPGPIELRPGESWASKSTIGLAHTDTDSELDNALHPYKELNRLGASVLDPGDSASQAGLQRAQSNITMSMAQLNELVRTTVHECINTNCNSNPPKSLK |
References More References in PubMed
| 1 |
Idris AM, et al. Virusdisease. 2019 Mar;30(1):84-94. doi: 10.1007/s13337-017-0412-6. Epub 2018 Feb 23. PMID: 31143835 |
|---|---|
| 2 |
Introduction of the Exotic Tomato yellow leaf curl virus-Israel in Tomato to Puerto Rico. Bird J, et al. Plant Dis. 2001 Sep;85(9):1028. doi: 10.1094/PDIS.2001.85.9.1028B. PMID: 30823090 |
| 3 |
Molecular Identification of the Viruses Associated with Sweetpotato Diseases in Cote d'Ivoire. Tapily EHH, et al. Viruses. 2025 Nov 12;17(11):1494. doi: 10.3390/v17111494. PMID: 41305515 |
| 4 |
Melgarejo TA, et al. Phytopathology. 2019 Aug;109(8):1464-1474. doi: 10.1094/PHYTO-02-19-0061-R. Epub 2019 Jul 11. PMID: 30995160 |