Melon chlorotic mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000887515.1 |
| Isolate | Venezuela |
| Release date | 2015/2/22 |
| Submitter | Romay,G., Chirinos,D., Geraud-Pouey,F., Desbiez,C., Geraud,F. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
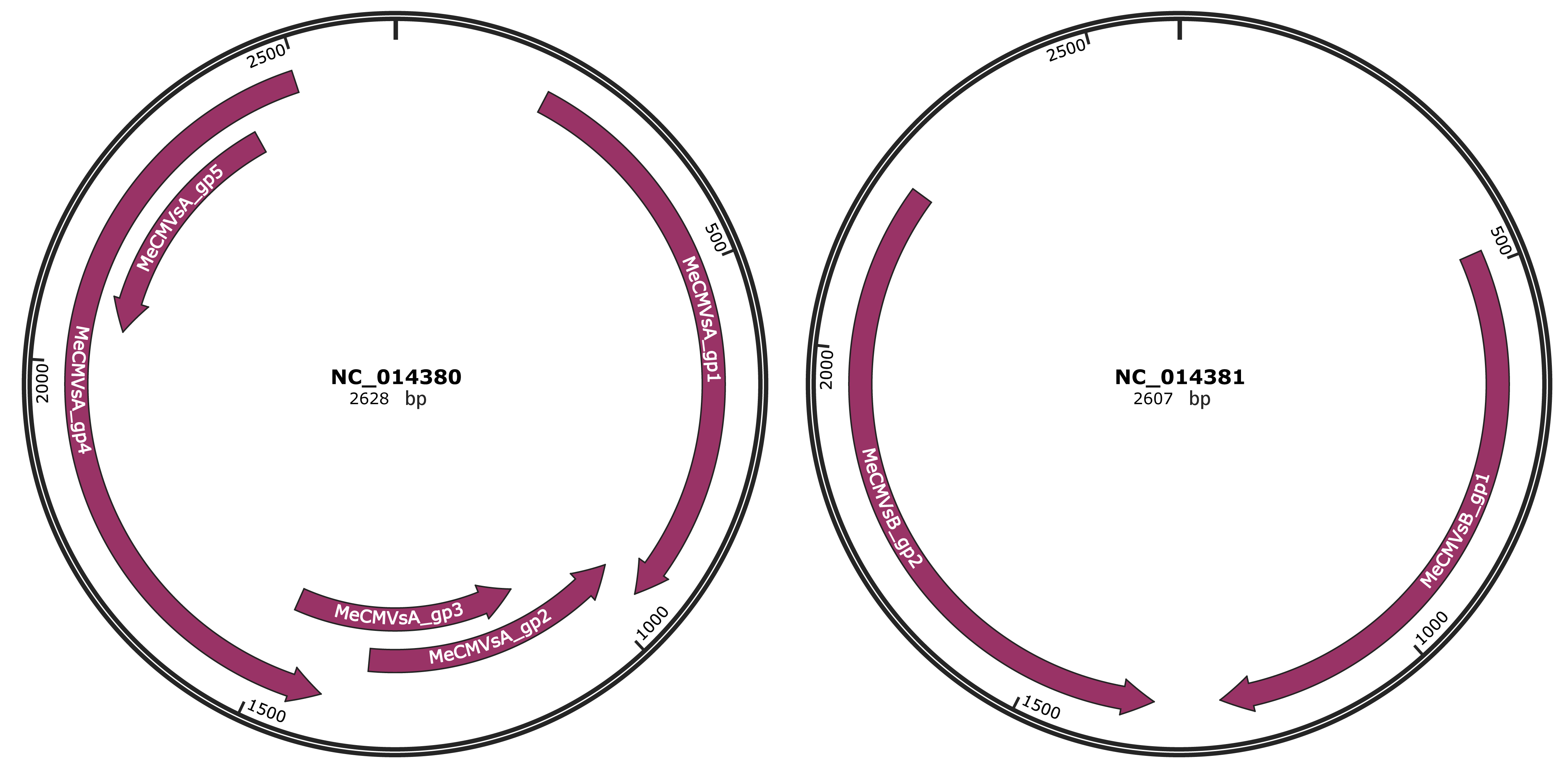
JBrowse
Genome
NC_014380
NC_014381
Gene Information
| NCBI Accession | YP_003828904.1 |
|---|---|
| Location | 203-958 |
| Protein Name | AV1 |
| Coding Region | ATGGTGAAGCGCGATGCTCCATGGCGGATGATGGCGGGGACCGCAAAGGTATCTCGATCTGCGAATTATTCTCCGCGTGCAGGTTTGGGCCCCAAATTTGACAAGGCCCATGCCTGGGTAAACCGGCCTATGTACAGAAAGCCCAGGATCTACCGGACGTTGAGAGGTGCCGACGTTCCCAAAGGATGTGAAGGCCCTTGTAAGGTTCAGTCTTACGAACAGCGTCATGATATTTCTCATGTTGGGAAGGTTATGTGCATTTCTGACGTTACTCGTGGTAACGGTATTACTCATCGTGTTGGTAAACGTTTTTGTGTTAAGTCTGTATATATTATAGGTAAGGTTTGGATGGACGATAACATCAAGTTGAAGAACCACACCAATAGCGTTATGTTTTGGTTAGTCAGAGATCGGCGACCGTATGGCACCCCCATGGAATTTGGGCAAGTGTTCAACATGTACGATAACGAGCCTAGTACTGCAACGATCAAGAACGATCTGCGTGATCGTTTTCAAGTCATGCATCGGTTTTATTCTAAGGTGACCGGGGGACAATATGCGAGCAACGAGCAAGCTCTCGTCCGGCGTTTTTGGAAGGTTAACAACTACGTCGTCTACAATCATCAGGAAGCCGCTAAATACGAGAATCATACCGAGAATGCTTTGTTATTGTATATGGCATGTACTCATGCTTCTAACCCTGTGTATGCGACATTGAAAATTCGGATCTATTTTTACGATTCGATAACAAATTAA |
| Protein Sequence | MVKRDAPWRMMAGTAKVSRSANYSPRAGLGPKFDKAHAWVNRPMYRKPRIYRTLRGADVPKGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYIIGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMEFGQVFNMYDNEPSTATIKNDLRDRFQVMHRFYSKVTGGQYASNEQALVRRFWKVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_003828905.1 |
|---|---|
| Location | 955-1353 |
| Protein Name | AC3 |
| Coding Region | ATGGATTCACGCACGGGGGAGAGCATCACTGTCTATCAGGCAGAGAATTCCGTTTTTATCTGGACGGTTCCAAATCCCCTGTTTTTCAAAATATACCACGTCGAACAACCGATATACACAAGAACCAGAATTTACCACATACAAATCAGGTTCAACCACAACTTGAGGAAGGCACTGGATCTACACCAAGCTTTTCTCAACTTCCAAATCTGGACGACTTCACTGACAGCTTCTGGGACGACTTATTTAAATAGGTTTAAACATGTTGTAATGCATTACTTGAACATGTTAGGGGTTATCGGTCTGAATAATGTTGTAAGGGCTGTTCGTTTCGCCACAAACAGAAAATATGTAACAGATGTACTTGAGAATCATGTAATAAAATTCAAGTTTTATTAA |
| Protein Sequence | MDSRTGESITVYQAENSVFIWTVPNPLFFKIYHVEQPIYTRTRIYHIQIRFNHNLRKALDLHQAFLNFQIWTTSLTASGTTYLNRFKHVVMHYLNMLGVIGLNNVVRAVRFATNRKYVTDVLENHVIKFKFY |
| NCBI Accession | YP_003828906.1 |
|---|---|
| Location | 1100-1489 |
| Protein Name | AC2 |
| Coding Region | ATGCTAACTTCGTCTTCCTCAACGCCCCCCTCTATCAAGACGAAGCACAGAATAGCCAAGAAGAAGGGCGTTCGTAGAAGGCGCATTGACCTAAACTGCGGCTGTTCAATTTTCGTACATATTGCCTGCGCAGAAAATGGATTCACGCACGGGGGAGAGCATCACTGTCTATCAGGCAGAGAATTCCGTTTTTATCTGGACGGTTCCAAATCCCCTGTTTTTCAAAATATACCACGTCGAACAACCGATATACACAAGAACCAGAATTTACCACATACAAATCAGGTTCAACCACAACTTGAGGAAGGCACTGGATCTACACCAAGCTTTTCTCAACTTCCAAATCTGGACGACTTCACTGACAGCTTCTGGGACGACTTATTTAAATAG |
| Protein Sequence | MLTSSSSTPPSIKTKHRIAKKKGVRRRRIDLNCGCSIFVHIACAENGFTHGGEHHCLSGREFRFYLDGSKSPVFQNIPRRTTDIHKNQNLPHTNQVQPQLEEGTGSTPSFSQLPNLDDFTDSFWDDLFK |
| NCBI Accession | YP_003828907.1 |
|---|---|
| Location | 1413-2495 |
| Protein Name | AC1 |
| Coding Region | ATGCCTAGAAGTCCTAAATCATTTCGGGTCGCAGCAAAAAACATTTTCTTAACATATCCTCAGTGCGACATCCCAAAGGATGAAGCTCTTAAGATGCTTCAAGAACTGGCATGGACAGTTGTCAAACCGAAATATATCAGAGTCGCAAGAGAGGAACACTCCGACGGCTCTCCACACCTACACTGTCTCATACAGTTATCCGGAAAGTCGAACATCAAGAATGCAAGATTTTTCGACCTTACTCACCCCAGAAGGTCTGCCTGTTTTCACCCAAACATTCAGGCAGCCAAAGACTCCAACGCCGTCAAGAATTACATCACCAAAGAAGGTGATTATTGTGAATCCGGCGAATATAAGGTGTCTGGGGGTACAAAGTCCAATAAAGACGACGTGTTCCATAATGCCATCAATGCCGGAACTGCAGAAGAGGCTCTCGCAATTATAAAAGCGGGTGATCCAAAAACATTTGTTGTAAATTATCATAATGTTAAAGCCAACATCGAGCGCCTCTTCCAAAAGGATGAGGATCCATGGGTTCCTCCATTTCAGTTGTCGTCGTTCAACAACGTTCCACAAGAGATGAAAGACTGGGTCGATGAGAATGTAACCGCTGCGCGGGCCGCTTGTATGACCCCTGCGGGGCCGGTAAGACCTAGAAGTATAATCATAGAGGGTGATAGTCGTACGGGCAAGACAATGTGGGCTCGTGCTATAGGTCCGCATAATTATTTAAGTGGTCATCTCGACTTCAATGCTAGGGTTTACTCTAATAATGTGATGTATAACGTCATCGATGACGTTGGACCGCAATATCTAAAGTTAAAGCATTGGAAAGAATTGATTGGGGCCCAAAGAGACTGGCAATCCAACTGTAAGTACGGAAAGCCGGTTAAAATTAAAGGCGGCATCCCATCAATCGTGCTGTGCAATCCAGGGGATGGGGCCAGTTATAAAGCATTTCTTGACAAAGAGGAAAATGCATCTCTAAGAGCGTGGACGTTAAAAAATGCTAACTTCGTCTTCCTCAACGCCCCCCTCTATCAAGACGAAGCACAGAATAGCCAAGAAGAAGGGCGTTCGTAG |
| Protein Sequence | MPRSPKSFRVAAKNIFLTYPQCDIPKDEALKMLQELAWTVVKPKYIRVAREEHSDGSPHLHCLIQLSGKSNIKNARFFDLTHPRRSACFHPNIQAAKDSNAVKNYITKEGDYCESGEYKVSGGTKSNKDDVFHNAINAGTAEEALAIIKAGDPKTFVVNYHNVKANIERLFQKDEDPWVPPFQLSSFNNVPQEMKDWVDENVTAARAACMTPAGPVRPRSIIIEGDSRTGKTMWARAIGPHNYLSGHLDFNARVYSNNVMYNVIDDVGPQYLKLKHWKELIGAQRDWQSNCKYGKPVKIKGGIPSIVLCNPGDGASYKAFLDKEENASLRAWTLKNANFVFLNAPLYQDEAQNSQEEGRS |
| NCBI Accession | YP_003828908.1 |
|---|---|
| Location | 2051-2416 |
| Protein Name | AC4 |
| Coding Region | ATGAAGCTCTTAAGATGCTTCAAGAACTGGCATGGACAGTTGTCAAACCGAAATATATCAGAGTCGCAAGAGAGGAACACTCCGACGGCTCTCCACACCTACACTGTCTCATACAGTTATCCGGAAAGTCGAACATCAAGAATGCAAGATTTTTCGACCTTACTCACCCCAGAAGGTCTGCCTGTTTTCACCCAAACATTCAGGCAGCCAAAGACTCCAACGCCGTCAAGAATTACATCACCAAAGAAGGTGATTATTGTGAATCCGGCGAATATAAGGTGTCTGGGGGTACAAAGTCCAATAAAGACGACGTGTTCCATAATGCCATCAATGCCGGAACTGCAGAAGAGGCTCTCGCAATTATAA |
| Protein Sequence | MKLLRCFKNWHGQLSNRNISESQERNTPTALHTYTVSYSYPESRTSRMQDFSTLLTPEGLPVFTQTFRQPKTPTPSRITSPKKVIIVNPANIRCLGVQSPIKTTCSIMPSMPELQKRLSQL |
| NCBI Accession | YP_003828909.1 |
|---|---|
| Location | 480-1250 |
| Protein Name | BV1 |
| Coding Region | ATGTACGCAATCAAGAACAGAAGAGTTTGGTATTCTACACATCGTCGGGGTTATGGACAACGTAGTTATAATAAACGTACATATTCTGGTAAGCGTACCGATTGGAAACGCCGTCCAATTATTCCTAATAATTCCAGCGATGATACTAGGATTGTTTCCCAACGTATCCACGAAGATCAATTTGGACCGGAGTTTGTGATCCCACATAATACGGCTCTATCAACCTTTTTGACAATGCCGAGTATTGTGAAACTTCAACCTAACCGTTCTAGGGATTACATTAAATTAAAACGACTCCGTTATAAAGGTACGCTTAAGATCGAGAGTGTTAATGCTGATGTGAACATGGGTTGTGTCAATTCTAAGATTGACGGAGTGTTTTCTCTGGTTATTGTGATTGACCGTAAACCTCATCTTAACGGATCTGGACGTCTACATACATTTGATGAACTATTTGGCGCAAGGATTCACAGTCATGGGAATCTATCTATAGCACCAGCAATGAAAGAGCGTTATTACATACGACACGTGTTCAAGCGCGTTTTGTCCACTGAGAAGGACAGTTTGATGACTGATATTGAGGGAAGCGCATTATTGTCTAATAGGCGCTTTAGTTGTTGGTCTGCGTTTAATGATGTAGACAGAGAATCATGTAACGGCGTTTACGCTAACATTAACAAGAACGCAATTTTGATTTATTACTGTTGGATGTCCGATGCTATTACGAAGGCATCCACATTTGTATCGTTTGATTTGGATTATTGTGGCTGA |
| Protein Sequence | MYAIKNRRVWYSTHRRGYGQRSYNKRTYSGKRTDWKRRPIIPNNSSDDTRIVSQRIHEDQFGPEFVIPHNTALSTFLTMPSIVKLQPNRSRDYIKLKRLRYKGTLKIESVNADVNMGCVNSKIDGVFSLVIVIDRKPHLNGSGRLHTFDELFGARIHSHGNLSIAPAMKERYYIRHVFKRVLSTEKDSLMTDIEGSALLSNRRFSCWSAFNDVDRESCNGVYANINKNAILIYYCWMSDAITKASTFVSFDLDYCG |
| NCBI Accession | YP_003828910.1 |
|---|---|
| Location | 1337-2218 |
| Protein Name | BC2 |
| Coding Region | ATGAATTCTAAATTGGCTGATCCTCCTAATGCCTTTAACTATATCGAGTCGAATCGTGATGAATATCAGTTATCGCATGATTTAACCCAAATCGTGTTGCAATTTCCGTCGACCACGGCTCAAATAAGTGCTAGACTGACGAGAAGCTGTATGAAAATCGACCACTGCGTCGTAGAATACAGGCAACAAGTGCCGATCAACGCGTCGGGAACGGTTATCGTCGAAATCCACGACAAGCGGATGACGGACGATCAATCCTTACAAGCGTCCTGGACGTTCCCGATCAGATGCAACATAGATCTCCACTATTTCTCTTCTTCTTTCTTTTCGCTGAAAGACCCAATACCATGGGTGCTGTACTACAGAGTTAGCGACTCAAATGTTCATCATGGTACGCATTTCGCCAAGTTCAAGGGAAAACTGAAATTATCGACGGCGAAACATTCCGTTGATATACCGTTCCGGGCACCGACGGTAAAGATATTATCGAAACTGTTTTCCGCAAAAGACGTCGATTTCAGCCACGTCGGATACGGTAAATGGGAACGAAAGCTCGTCAGGTCAATGTCAACATGTCGGCAAGGTCTTCTTGGACCAATCGATCTAAGGCCCGGTGAATCATGGGCTAGTAGAAGTACTTTGGGCCCAGCCCAATCCATTACGGAGTCAGATGATGCAGAGGAATTGCATCCATACAGAGAGCTACATAGATTAAACACGCCCATTCTAGACCCGGGAGAGTCGGCATCAATAGTAGGAATGCAAAGGACGCAATCGAACATAACGCTGTCACTATCACAGTTAAATGATATCGTAAGATCAACCGTGCAGGAGTGTATTAAGAGTAACTGTACCCCAAATGACCCCAAATCTTTAAATTAA |
| Protein Sequence | MNSKLADPPNAFNYIESNRDEYQLSHDLTQIVLQFPSTTAQISARLTRSCMKIDHCVVEYRQQVPINASGTVIVEIHDKRMTDDQSLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWVLYYRVSDSNVHHGTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKLFSAKDVDFSHVGYGKWERKLVRSMSTCRQGLLGPIDLRPGESWASRSTLGPAQSITESDDAEELHPYRELHRLNTPILDPGESASIVGMQRTQSNITLSLSQLNDIVRSTVQECIKSNCTPNDPKSLN |
References More References in PubMed
| 1 |
Resistance Against Melon Chlorotic Mosaic Virus and Tomato Leaf Curl New Delhi Virus in Melon. Romay G, et al. Plant Dis. 2019 Nov;103(11):2913-2919. doi: 10.1094/PDIS-02-19-0298-RE. Epub 2019 Aug 20. PMID: 31436474 |
|---|---|
| 2 |
First Report of Cucumber mosaic virus on Melon in Bosnia and Herzegovina. Trkulja V, et al. Plant Dis. 2013 Aug;97(8):1124. doi: 10.1094/PDIS-02-13-0135-PDN. PMID: 30722492 |
| 3 |
Lecoq H, et al. Plant Dis. 2011 Feb;95(2):153-157. doi: 10.1094/PDIS-06-10-0447. PMID: 30743409 |
| 4 |
Brown JK, et al. Plant Dis. 2001 Sep;85(9):1027. doi: 10.1094/PDIS.2001.85.9.1027C. PMID: 30823088 |
| 5 |
García-Rodríguez DA, et al. PeerJ. 2023 Mar 22;11:e15047. doi: 10.7717/peerj.15047. eCollection 2023. PMID: 36974135 |
| 6 |
Kang YC, et al. Phytopathology. 2024 Apr;114(4):813-822. doi: 10.1094/PHYTO-07-23-0227-R. Epub 2024 Apr 10. PMID: 37913633 |
| 7 |
First Report of Moroccan watermelon mosaic virus in Zucchini Crops in Greece. Malandraki I, et al. Plant Dis. 2014 May;98(5):702. doi: 10.1094/PDIS-10-13-1100-PDN. PMID: 30708553 |
| 8 |
Idris AM, et al. J Virol. 2008 Feb;82(4):1959-67. doi: 10.1128/JVI.01992-07. Epub 2007 Dec 5. PMID: 18057231 |
| 9 |
Occurrence of Ourmia melon virus in the Guilan Province of Northern Iran. Gholamalizadeh R, et al. Plant Dis. 2008 Jul;92(7):1135. doi: 10.1094/PDIS-92-7-1135C. PMID: 30769509 |
| 10 |
Che H, et al. Viruses. 2023 Jun 19;15(6):1396. doi: 10.3390/v15061396. PMID: 37376695 |